功能型复合深度网络的图像超分辨率重建*
2020-08-12唐家军胡雪影
唐家军,刘 辉,胡雪影
1.昆明理工大学 信息工程与自动化学院,昆明 650000
2.中国科学院 云南天文台,昆明 650000
3.河南理工大学 计算机学院,河南 焦作 454150
1 引言
单图像超分辨率(single image super resolution,SISR)重建[1-3]旨在将低分辨率(low resolution,LR)图像在算法层面转换提升为接近高分辨率(high reso-lution,HR)图像的超分辨率(super-resolution,SR)图像。相较于低分辨率图像,高分辨率图像具有更高像素密度、更多细节信息、更细腻的画质,在医疗影像、卫星遥感、公共安全、视频监控等领域都有广泛的应用需求。获取高分辨率图像最直接的方法是采用高分辨率的采像设备。但实际应用过程中,由于制作工艺和工程成本的制约,很多场景不适宜采用具有高分辨率功能的设备进行图像信号的采集。并且图像感兴趣区域可能很小,放大观看的过程可能含有干扰噪声。通过超分辨率重建技术来获取HR图像具有高的研究价值与应用需求。
研究中,一般将低分辨率成像模型表示为:

其中,ILR为低分辨率图像;IHR为高分辨率图像;D为下采样算子;B为模糊算子;n为加性噪声。图像超分辨率重建是上式的逆运算。
由于D、B、n都为不确定因子,单张LR 图像可能对应着多种HR 图像预测结果,因此图像超分辨率重建是不适定的逆问题。SISR 就是要利用一幅图像中包含的信息以及从样本图像中得到的视觉先验,识别重要的视觉线索,填充细节,并尽可能忠实和美观地呈现。
为实现计算机视觉技术自动由低分辨率图像重建出高分辨率图像,研究者们已经提出多种SISR 方法。主要有传统的SISR 方法[4-7]和深度学习方法[8]。虽然传统的SISR方法及其改进方法[9-10]在SR任务已取得不错的表现,但其主要是基于经验算法实现,在高分辨重建过程中会遗漏大量的图像高频信息且需要一定人为干预,最终结果性能与实际应用需求有着较大差距。
由于出色的性能,深度学习方法已成为模式识别与人工智能领域的研究热点。其中的卷积网络(ConvNet)[11]近年来在大规模图像和视频识别分类[12]等方面取得了巨大的成功。Dong 等人提出的三层神经网络SRCNN[13](super-resolution convolutional neural network)成功将卷积神经网络(CNN)运用到SISR 问题中,以端到端的方式学习从LR 到HR 的映射,不需要传统SR 方法使用的任何工程特性,并且获得比传统方法更先进的性能。Kim 等人结合递归学习[14]、残差学习[15]提出的DRCN[16]、VDSR[17]通过增加网络深度的方式提升图像重建性能。Mao 等人提出的具有对称结构编解码网络REDNet[18]对SR 过程产生的噪声有抑制作用,能恢复出更加干净的图片。对抗神经网络[19]的兴起使Christian 等人提出的SRGAN[20](super resolution generative adversarial net-works)及其改进型ESRGAN[21]取得了逼真视觉效果。杨娟等人[22]在生成对抗网络为主体框架的网络模型中,以融合感知损失的方式提高对低分辨率图像的特征重构能力,高度还原图像缺失的高频语义信息。RCAN[23](residual channel attention networks)通过在卷积网络引入注意力机制,通过考虑卷积特征通道之间的相互依赖性来自适应地重新缩放通道方式的特征。李云飞等人[24]提出一种多通道卷积的图像超分辨率算法MCSR(multi-channel convolution super resolution)。引入多通道映射提取更加丰富的特征,使用多层3×3 等小卷积核代替单层9×9 等大卷积核,更加有效地利用特征,增强模型的超分辨率重构效果。深度SR 方法优秀的性能现今也应用到了特定的图像中[25-26]。
然而,上述方法将深度学习技术成功引入到解决SISR 问题中时,也存在一定的局限性。SRCNN存在着依赖于小图像区域上下文,训练收敛慢,网络只适用于单尺度的缺陷。DRCN 由于使用递归循环导致网络存储量大,训练时间长,不便于实际应用。VDSR 切实解决了SRCNN 存在的问题,效果也较为显著,但网络的简单链式堆叠在泛化与鲁棒性存在风险。REDNet 的卷积与反卷积堆叠会出现振铃效应与棋盘效应。而SRGAN 与ESRGAN 是采用对抗的方式生成SR图像,破坏了SR图像与HR图像像素间的对应关系。
针对上述方法存在的弊端,本文提出了一种用于图像超分辨率重建的复合深度网络方法,该方法联结两个具有辅助功能的不同子网络,赋予子网络不同的职能:特征细节提取、特征去噪。通过结合两个子网络的深层特征与LR 图像的初始特征重建出低噪声、高视觉效果的SR图像。
与前述SISR方法相比,本文主要贡献如下:
(1)提出一种用于图像超分辨率重建的复合深度神经网络。借助辅助子神经网络解决单图像超分辨率过程产生的噪声问题。
(2)通过配置复合网络中子网络之间的联结方式、权值占比,探究发现单一网络对于图像超分辨率重建效果的作用。
(3)在训练过程添加用于前向传导梯度的辅助重建层,避免出现网络梯度问题,实际测试时,额外的辅助重建层被去掉。
(4)使用远程跳跃连接,加速网络训练,提升图像重建效果。
2 相关工作
本章重点介绍了与本文最相关的三项工作:子网络联结块、辅助重建层、残差学习。
2.1 子网络联结块
图1 通过仅具有4 个卷积层的简化网络结构说明了这些网络联结方式。其中为了清晰起见,省略了激活函数Relu[27]。
图1(a)联结方式1采用SRResNet(SRGAN的生成网络部分)中不同特征处理方式,将不同特征直接累加求和。赋予特征不同权重,能达到优质特征互补,提升重建效果。图1(b)联结方式2 则是借鉴SRDenseNet[28],SRDenseNet 在稠密块中将每一层的特征都输入给之后的所有层,使所有层的特征通道并联叠加,而不是像ResNet[13]直接相加。这样的结构使整个网络具有减轻梯度消失问题、支持特征复用的优点。
2.2 辅助重建层
辅助层(输出中间层)是Szegedy 等人在Google-Net[29]中提出的。GoogleNet 考虑到对于深度相对较大的网络,反向传播梯度有效通过所有层的能力是一个挑战。在这个任务上,更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的。
GoogleNet 将辅助分类器添加到网络中间层,期望较低阶段分类器的判别力。而本文则通过将辅助重建层添加到网络中间层,提高较低阶段重建器的重建能力,同时辅助解决梯度问题。
这些辅助重建器采用较小卷积网络(1×1 卷积核)的形式,放置在子网络尾部。在训练期间,辅助重建层的损失以权重占比(权重是0.3)加到网络的整体损失上。在测试时,这些辅助重建网络将被丢弃。

Fig.1 Network combination block图1 网络联结块
2.3 残差学习
对于SISR 问题,输入的LR 图像与输出的SR 图像具有密集相关性。即LR 图像的低频信息与HR图像的低频信息相近,只是缺乏高频部分的信息映射。这种映射关系不仅学习困难,而且学习效率低。并且输入图像在网络计算中携带传输大量的细节信息,如果深层卷积网络存在多重卷积递归,会产生严重图像特征细节丢失与训练梯度问题(梯度消失/爆炸等[30])。鉴于此,本文设置残差学习快速解决这个问题。残差学习如图2所示。

Fig.2 Residual learning:building block图2 残差学习:残差块
残差学习由He 等人[15]提出,通过将图1 结构叠加在一起构建一个非常深的152 层网络ResNet,ResNet 在2015 年 的ILSVRC(imageNet large scale visual recognition challenge)分类比赛中获得了第一名。由于ResNet 中的残差学习是在每一个叠层中采用的,其中的残差单元以链式堆叠,因此该策略是局部残差学习的一种形式。
而全局残差学习策略:输出的结果=低分辨率输入(经过插值变成目标尺寸的低分辨率图像)+网络学习到的残差。基于全局学习策略采用多条非堆叠式的中远距跳跃连接可将低维图像特征直接传输到网络中后层,协助梯度的反向传播,加快训练进程,提高结果性能。
3 复合网络的图像超分辨率重建
在本章中,详细介绍了本文提出的网络模型体系结构。具体的说,本文在网络结构中采用残差学习,通过将全卷积子网络与编解码子网络置入网络结构构建复合网络模型。并且在子网络尾端引入辅助重建层(图3 中黑色虚线框),这进一步提升了学习性能。下面将逐步展示网络模型的更多细节。
3.1 网络架构
考虑到模型的输入与输出大小不同,本文采用与SRCNN相同的图像预处理策略,使用双三次线性插值下采样得到网络的低分辨率输入图像。网络架构如图3 所示。模型由三部分组成:初始特征提取、子网络结构和重建。

Fig.3 Network architecture图3 网络架构
初始特征提取从输入的低分辨率图像中提取图像低级特征,并将每个特征表示为高维向量,合并为初始特征图组;然后将初始特征图组分别输入两个子网络,子网络进行高维细节提取与噪声的抑制、消除任务;重建部分中将两个子网络输出的高维特征进行加权合并,并在最终的卷积层中结合初始特征(图3紫色实线)重建输出超分辨率图像ISR。
3.1.1 初始特征提取
传统图像恢复中,图像特征提取的一种策略是先将图像块进行密集提取[31],之后用一组预先训练的基底(如PCA(principal component analysis)[32]、DCT(discrete cosine transform)[33]等)来表示。而在卷积神经网络,此部分基础功能可纳入到网络的优化中,卷积操作自动提取图像特征并表示。形式上,特征提取网络表示为操作F1:

其中,输入X为经过插值变成目标尺寸的低分辨率图像,W1和b1分别表示卷积权值和偏置,W1表示64 个大小为3×3×c(c为LR 图像通道数)的卷积核。“⊗”表示卷积运算,运算添加0 边界,步长为1,使输入、输出特征尺寸保持一致,防止产生边界降秩。使用Relu(max(0,*))[27]用于卷积特征激活。
3.1.2 子网络结构
该部分结构中,特征提取阶段提取到的初始特征被分别送至两个子网络中进行高维特征运算与非线性映射。具体地说:在子网络1 中,进行细节学习与清晰化重现;在子网络2 中,进行特征图像的去噪任务。
(1)子网络1。对于SR 图像细节学习重建,本文受到Kim 等人[17]的启发使用非常深的卷积网络。配置如图3 红色虚线框1 所示。使用N层卷积层(本文N为10),所有卷积层皆是同一类型:64 个大小为3×3×64 的卷积核,卷积核在3×3 的空间区域上运行,跨越64 个特征通道,添加0 边界,卷积步长为1。第一层输入图像初始特征,中间层进行高维特征提取与非线性映射,最后一层高维特征与初始特征相加输出。表示为公式:

(2)子网络2。该部分网络借鉴REDNet[18]卷积与反卷积次第使用,形成一个对称的网络结构,每个卷积层都有对应的反卷积层。卷积层用来获取图像特征的抽象内容,保留了主要的图像内信息;反卷积层则用来放大特征尺寸并且恢复图像特征细节信息。在达到良好去噪效果的同时较好地保留图像内容。配置如图3 红色虚线框2 所示。使用M层(本文M为10)的编解码结构,并使用了残差学习局部跳跃连接加快训练过程并提升训练效果。

为保证两个子网络输出特征尺寸相同,子网络2 中所有卷积层采用与子网络1 相同策略:卷积层统一采用64 个大小为3×3×64 的卷积核。在式(6)中:输入为提取的初始特征,W2,m-2和b2,m-2为卷积权值与偏置大小。不添加0 边界且卷积步长为2,单卷积层输出尺寸变为输入尺寸的一半。式(7)中W2,m-2和b2,m-2为反卷积权值与偏置,“⊙”表示反卷积运算;式(6)与式(7)互为逆过程。
式(8)则是一个局部跳跃连接[11],正如残差学习的设计初衷,跳跃连接可以解决网络层数较深的情况下梯度消失的问题,同时有助于梯度的反向传播,加快训练过程。式(9)进行子网络的最终输出。卷积层逐渐减小特征图的大小,反卷积层再逐渐增大特征图的大小,同时采用跳跃连接加快训练过程,保持子网络最终输入、输出特征尺寸一致,同时保证在设备计算能力有限情况下的测试效率。获得去除噪声的特征图。
3.1.3 网络联结与图像重建
该部分结构主要功能是输入特征图组,输出目标图像ISR。首先第一层卷积层将前面子网络输出的H1,n与H2,m乘以一定的权值α、β(α+β=1)直接相加,作为重建部分的输入。之后通过简单卷积运算,将子网络中辅助信息混合,以提升重建效果:

特征图组重建为高分辨图像过程可看作特征提取阶段的逆运算。在传统的方法中,此过程通常平均化重叠高分辨率特征图以产生最终的完整图像。可将输入特征图相应位置看作高分辨图像对应像素不同维度的矢量形式。受此启发,本文定义了一个卷积层来生成最终的超分辨率图像。

式(12)是一个远程跳跃连接,将式(2)得到的初始图像特征与式(11)子网络得到的高维特征相加,加快训练速度;式(13)为重建高分辨率图像表达式,Y为输出的高分辨率目标图像为c个大小为3×3×64 的卷积核,c代表着图像通道数量。b4表示卷积偏置。期望在重建网络卷积中,卷积核作为一个反作用基底,将特征图投影到图像域中,重建高分辨率图像。
上述三种由不同的功能驱动的操作,都与卷积网络具有一致的形式。将这三个操作复合在一起,构建一个具有细节学习、噪声消除功能的复合深度卷积神经网络(如图3),用于图像超分辨率重建。在此模型中,所有的权重值和偏置都要进行训练优化以获得最优值。
3.2 训练
训练的目的是通过优化网络找到模型的最佳参数,训练出最优网络,使获得的超分辨率图像无限接近于高分辨率原图像。
3.2.1 损失函数(优化目标)
目前的图像恢复任务中主要使用的还是L2 损失函数(均方误差(mean squared error,MSE)),因为使用L2 损失函数的网络往往对PSNR 有针对性的提升。但是L2 指标与人类感知的图像质量相关性较差,例如其假设噪声与图像的局部区域无关。而在有些情况下,L1 损失函数(平均绝对误差(mean absolute error,MAE))获得的图像质量会更好。式(14)与式(15)分别为L1 损失(MAE)与L2 损失(MSE)的数学表达式。

其中,P、T分别表示预测图像与真实图像,H、W分别为图像的高度和宽度。
同L2 损失函数相比,L1 损失函数不会过度惩罚两张图的差异,因此它们具有不同的收敛属性。并且Zhao 等人[36]证明了L1 与L2 切换使用,不仅可以加速训练损失的收敛,还能提升图像预测结果。本文采用相同方式:先使用L1 损失函数加速训练收敛,防止陷入局部最小;训练后期再使用L2 损失函数寻找训练最优值点,提升预测结果稳定性。
3.2.2 网络参数设置
在训练开始之前,需要初始化网络参数以供后续更新。本文从平均值为0、标准偏差为0.001(偏差为0)的正太分布中随机抽取数值,初始化每层的卷积核权重W,而偏置b则全部置0。设置学习率为0.000 1。使用Adam优化方法[37]更新权重矩阵,以将损失函数数值降至最低。其参数更新公式为:

其中,β1设为0.9,β2设为0.999 9,ε设为10-8,学习率η为0.001。mt为梯度的第一时刻平均值,vt为梯度的第二时刻方差值。
使用tensorflow 框架来实现本文提出的模型,用NVIDIA 1080Ti GPU 加速训练过程并观察到优异的性能。训练所有实验达到100 轮次(每轮1 000 次迭代,迭代批次大小64)后停止学习。前50 轮使用L1损失函数,后50轮使用L2 损失函数。
4 实验分析与结果
在本章中,首先描述用于训练和测试本文提出方法的数据集;然后对本文提出方法进行定性定量实验分析,评估本文所提方法的特性与性能,得到最优的SISR 方法;最后在多个数据集上将本文方法与几种最先进的SISR方法进行比较分析。
4.1 数据集
按照文献[15,19]中对SRCNN、VDSR 等实验数据集的设置,使用相同的含有291 幅图像的训练集,其中91 幅图像来自Yang 等人[5]的T91 数据集,200幅图像为公开自然图像数据集BSD200[38]。SRCNN等已证明海量数据有益于深度卷积模型的训练,并且由于网络采用全卷积结构,输入图像的大小可以是任意的。在SRCNN 中训练图像被裁剪成33×33大小,裁剪步幅为14。而VDSR 则将图像裁剪的大小设为41×41,同时其在文献中证明了大的裁剪图可以增大卷积感受野,有助于重建效果的提升。因此,本文将291 幅训练集图像分别进行逆时针旋转90°、倒置、镜像翻转操作,从而得到含有1 164 幅图像的扩充训练集。同时在数据集图像上裁剪64×64大小的子图,裁剪步长设为16。
对于测试数据集,本文使用通用的基准测试[6,13]图像数据集Set5[39](5 幅图像)、Set14[40](14 幅图像)、BSD100[31](100 幅图像),以及由Huang 等人提供的城市图像Urban100数据集[7](100幅图像)。
本文中评价了3 个尺度因子,包括X2、X3 和X4。输入的ILR是先进行双三次下采样,再对下采样图像进行一定比例的双三次插值上采样,并添加少量高斯随机噪声获得的。
4.2 定性与定量分析
4.2.1 复合网络联结方式分析对比
经过探究分析,本文使用简单子网络结构,设计了两种不同的子网络联结方式,即图1 所示。通过调整不同联结方式中单个子网络的权值占比(α为子网络1 的权重值,子网络2 的权重值则为1-α),以PSNR 与SSIM 为分析评价指标,得到如图4 所示结果(指标对比:数值越高,性能越好)。
由图4 可以发现,联结方式1 相比联结方式2 可以获得更高的PSNR 与SSIM 分数值。而在联结方式1 中:当α=0.5,β=1-α=0.5 时,可以获得最高的结果分数。由此本文采用联结方式1,α=0.5,β=0.5的复合网络。
4.2.2 残差学习
网络在图2 基础上使用残差学习添加两种跳跃连接[16]。一种为局部特征连接,协助梯度的反向传播,加快训练进程。另一种则为远程跳跃连接,起到加快训练进程,提高结果性能作用。
为探究残差学习在网络中的功能作用,本文实验比较了两种网络:含有远程跳跃连接和非远程连接网络。实验在Set5 数据集上进行,放大因子为2。参数设置、学习速率调度机制与前文相同。
在表1 中,对比了含有远程跳跃连接和非远程连接网络的图像重建返回结果性能。从中可以看出:网络在收敛时,含有残差的网络表现出优越的性能。当训练完成时,含有远程跳跃连接的网络获得了更高的PSNR 与SSIM 分数。证明了含有残差学习的深度神经网络对图像超分辨率重建有益。

Table 1 Residual learning test表1 残差学习实验 dB
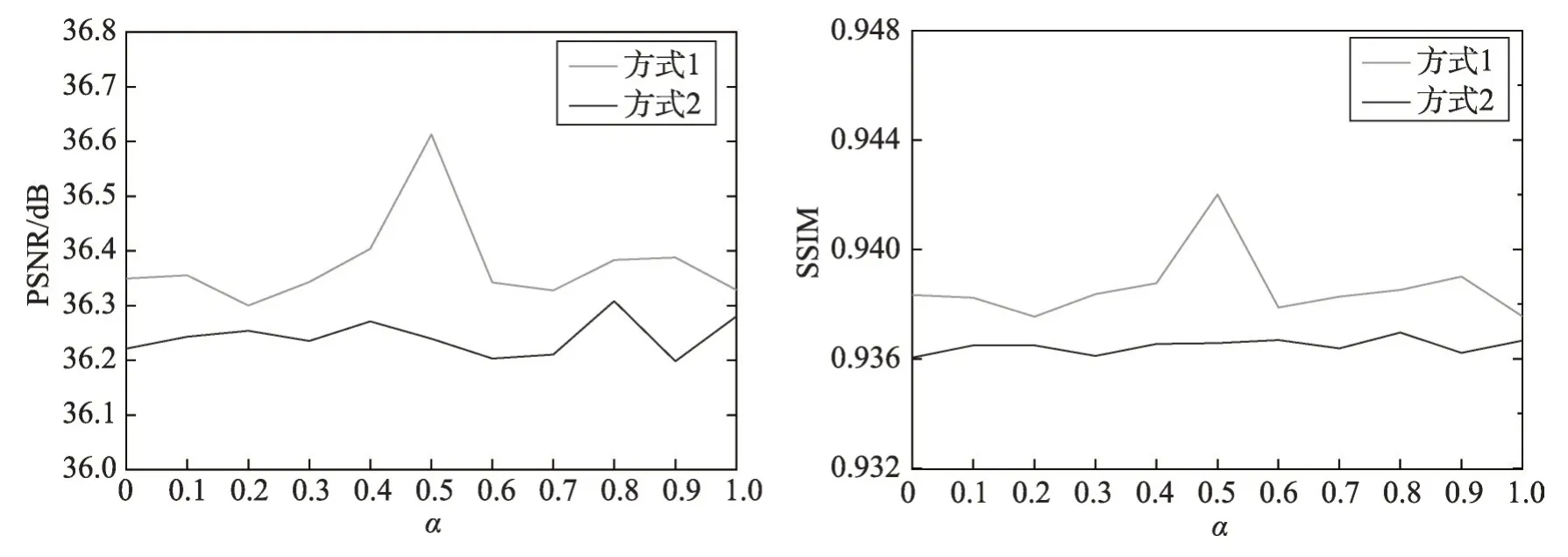
Fig.4 Analysis and comparison of combination modes图4 联结方式分析对比
4.3 与先进方法对比
4.3.1 客观对比
本文采用图4的网络结构,在Set5、Set14、BSD100和Urban100 测试数据集上,使用放大因子2、3、4 评估网络的性能,评测标准使用平均PSNR 和平均SSIM。对比的先进SR方法有:
Bicubic,像素插值方法[4];
SelfEx,变换自相似图像超分辨率方法[7];
SRCNN,简单的端到端卷积网络图像超分辨率重建方法[13];
VDSR,带有残差学习的深度全卷积图像超分辨率处理网络[17];
REDNet,由卷积层-反卷积层构成的对称的编解码框架,对图像超分辨与去噪表现出优异效果[18]。
在表2 中,显示了在多个测试数据集上使用不同放大因子基础下,本文所提方法与先进SR方法的比较。通过对比,本文所提SR方法相较于当前各先进SR 方法在PSNR 和SSIM 上均有提高。相较于高放大因子的LR图像,低放大因子下生成的低分辨率图像重建所需要的特征细节与网络结构要求稍低,过多的图像特征细节可能反向影响图像超分辨重建的效果,因此在Set5 与Set14 数据集中,放大因子为X2 超分辨结果稍差。本文所提方法在高放大因子重建的超分辨图像相对VDSR、REDNet 等网络表现出更加优异的性能结果。
由于网络采用了分支子网络结构,图像SR 过程为并行过程。数据在两个子网络中同步运行计算。对比具有相同层数的卷积网络,如VDSR/REDNet等串式堆叠网络能节省更多时间。
将本文方法以SRCNN为时间基准,在Set5数据集上,放大倍率为X2,在AMD 2700X CPU+NVIDIA 1080Ti GPU+32 GB RAM 硬件设备条件下。与具有相同层数的卷积神经网络进行单幅图像的平均处理运行时间对比,结果如表3 所示。从表中结果可以得出结论,本文所提方法相比于其他深度网络方法取得优异重建效果的同时极大程度上减少了运行时间,更满足实时性要求。
4.3.2 主观对比
分别在测试数据集Set14、BSD100、Urban100 选取复杂图像,分别使用本文提出方法与先进SR方法进行超分重建,对比主观视觉效果。图像的重建返回结果如图5~图7所示。
在图5 中,返回的是Set14 数据集008 图像放大因子为4 的超分辨重建结果,观测到本文方法在图像抗锯齿方面表现出优异效果;图6 中,返回的是BSD100 数据集043 图像在放大因子X4 的超分辨重建结果,本文方法在船顶部分重构出较为明显的船舱细节图,舱顶区域表现清晰,没有模糊感;而在图7返回了Urban100 数据集072 图像使用放大因子为X4 的超分辨重建结果,可以看到本文方法相较其他SR方法在线条部分恢复得更清晰与连续。

Table 2 Performance evaluation comparison of each advanced SR method表2 各先进SR方法测试集性能对比

Table 3 Comparison of average operation time of different SR methods表3 不同SR方法平均运行时间对比 ms
在视觉感官对比上,本文所获取的重建图片效果明显优于其他先进SR方法。

Fig.5 Comparison of visual effects of different SR methods for img008(Set14)图5 img008(Set14)不同SR方法重建视觉效果对比

Fig.6 Comparison of visual effects of different SR methods for img043(BSD100)图6 img043(BSD100)不同SR方法重建视觉效果对比

Fig.7 Comparison of visual effects of different SR methods for img072(Urban100)图7 img072(Urban100)不同SR方法重建视觉效果对比
5 结束语
本文为解决简单采用链式堆叠而成的单一网络存在的层间联系弱、网络关注点单一以及分层特征不能充分利用等问题,提出了用于图像超分辨重建的复合深度神经网络。对于超分辨过程的细节重建、噪声抑制等方面都有着非常显著的效果。本文首先探索了子网络不同联结方式对最终重建效果带来的影响,并选出最优异的联结方式;然后发现具有残差学习的网络比普通卷积网络收敛得更快并显著提升了重建性能;最终证明了本文提出网络方法的性能相比当前其他几种先进SR 方法具有更加优异的性能表现。实验中,对同一幅图像进行超分辨率重建时,与Bicubic、SelfEx 等传统算法相比,使用本文方法得到的图像更清晰,细节表现得更丰富;而与SRCNN、VDSR 及REDNet 等深度学习SR 图像重建算法相比,在图像纹理信息丰富的区域,使用本文方法得到的重建效果更好。
