改进的卷积神经网络在肺部图像上的分割应用*
2020-08-12钱宝鑫肖志勇
钱宝鑫,肖志勇,宋 威
江南大学 人工智能与计算机学院,江苏 无锡 214122
1 引言
据统计,目前中国肺癌的发病率正以每年26.9%的速度增长,到2025年,仅中国每年死于肺癌的人数就将接近100万,肺部疾病已对居民的生命健康构成巨大威胁[1]。研究表明,肺部疾病越早发现并及时接受治疗可以有效降低肺癌患者的死亡率。CT成像技术是医学影像技术中检查肺部疾病的有效影像学手段,从肺部CT图像中提取肺实质可以帮助医生诊断和评估肺部疾病。当前,将医学图像处理技术应用于肺部疾病辅助诊断,对于实现医生更快、更准确地检测患者肺部疾病具有重要意义。
医学图像分割是指对医学图像中的器官和病灶(如肿瘤)进行提取。医学图像分割的本质就是按照灰度、纹理等图像特征,根据同一区域特征的相似性和邻域特征的不同将感兴趣区域分割出来,从而为临床医学提供可靠的信息。然而,由于肺部CT图像组织结构复杂,主要包括肺实质和肺实质以外的空气、支气管、水、骨骼、检查床等部分,导致肺部CT图像噪声强,因而从CT图像中提取肺实质成为肺部疾病诊断研究的重要步骤。
传统的医学图像分割方法主要分为以下三种[2]。(1)手动分割方法,这种方法是由专家手动分割,主观性强、容易出错、耗时且不适合大规模的研究。(2)半自动分割方法,由于不同类型的CT图像或不同的数据集具有不同的特征和参数阈值,很难对其进行统一推广。(3)传统的自动分割方法主要分为以下几种:①基于阈值的分割[3],该方法设置阈值间隔,创建二进制分区,此方法速度较快,但没有考虑到图像像素点的空间分布,容易对噪声敏感,该方法对于灰度差异较小的图像分割效果不好。②基于区域的分割[4],此类方法快速且在细微的衰减变化下分割效果很好,但是它们存在一些缺陷,对有病理的边界分割效果较差。③基于聚类的分割[5],该方法将图像中灰度值差异较小的像素点聚合在一起分为同一类,通过聚类将图像划分为不同的区域,但是由于聚类算法对初始点的赋值比较敏感,分割结果会根据初始化的不同有差异。
如今,深度学习和卷积神经网络技术广泛应用于图像处理,并且在医学图像分割领域取得了很大的进展。Berkeley 团队[6]提出全卷积网络(fully con-volutional networks,FCN)方法用于图像语义分割,将图像级别的分类扩展到像素级别的分类,将卷积层代替分类网络框架中的全连接层,取得了良好分割的效果,成为深度学习在语义分割应用中的开山之作。Ronneberger等人[7]提出的U-Net网络,利用编码器与解码器之间的级联操作将图像高层信息与浅层信息融合,有效地避免了高层语义信息的丢失,在医学图像分割方面取得了良好的效果。Milletari等人[8]提出的V-Net 是基于体素的全卷积神经网络在三维医学图像上的分割应用,在编码的部分采用残差网络框架,在保证不断加深网络深度的同时,减少梯度消失或者梯度爆炸带来的风险。Zhao 等人[9]提出的金字塔场景解析网络(pyramid scene parsing network,PSPNet)是在FCN 算法的基础上通过特征融合引入更多的上下文信息,通过聚合不同区域的上下文信息,从而提高获取全局信息的能力。
在上述讨论的基础上,提出了一种新的基于编/解码模式的肺分割算法。受U-Net网络框架的启发,编码模块采用一个结合多尺度输入的残差网络为基础层,很好地解决了深度神经网络的退化问题,通过给四个级联分支注入多尺度的图像来捕获更广泛和更深层次的语义特征。在编码和解码模块之间,采用一个由空洞卷积驱动的空间金字塔池化代替传统U-Net网络的池化层,通过使用不同膨胀系数的空洞卷积,从编码模块提取目标多尺度特征。最后是解码模块,在保留级联操作的同时,利用注意力机制的控制单元加强有效信息的权重,从而提高分割精度。
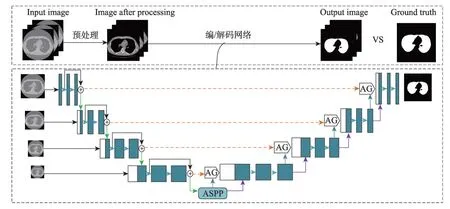
Fig.1 Flow diagram of experiment图1 实验流程图
本文的实验流程图如图1 所示。首先对图像进行预处理,接着将训练样本送入模型中训练,得到最优分割模型;再将测试样本送到已经训练好的模型中测试,得出分割结果。本文提出的编/解码模式的肺分割算法,输入的是肺CT 扫描切片,输出的是一个二值化图像,模型通过识别每个像素是前景还是背景来预测显示肺的位置,以真实标签为金标准对测试结果进行评估,来判断本文算法的性能。
2 相关工作
2.1 残差网络
对于神经网络来说,网络层数越深,所能学到的东西越多,但在某些情况下,网络层数越深反而会降低准确率,很容易出现梯度消失和梯度爆炸。残差网络(residual network,ResNet)[10]可以很好地缓解这一问题。普通卷积每两层增加一个捷径,构成一个残差块(residual block),多个残差块连接在一起构成一个残差网络,残差块如图2所示。
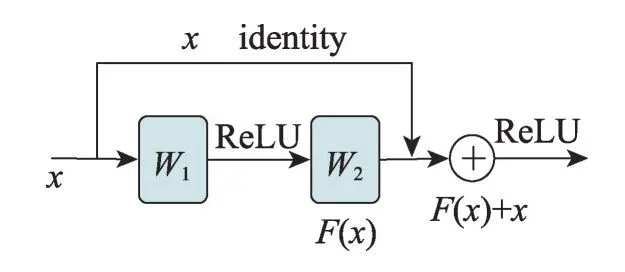
Fig.2 Residual block图2 残差块
图2 中,x表示输入,F(x)表示残差块在第二层激活函数之前的输出,即F(x)=W2σ(W1x),其中W1和W2分别表示第一层和第二层的权重,σ表示ReLU激活函数[11]。最后残差块的结构公式可定义如下:

将单元输入x与单元输出F(x)相加,然后利用ReLU激活函数输出。在前向传播时,输入数据可以从任意低层传向高层,由于包含一个恒等映射(iden-tity mapping),一定程度上可以解决网络退化问题。
2.2 空洞卷积
在卷积神经网络中,卷积核的尺寸越大,感受野也就越大,提取到的图像特征也就越多,但是一味地增加卷积核的尺寸会使模型参数增多,这样不利于模型的训练。空洞卷积(atrous convolution)[12]能够在不牺牲特征空间分辨率的同时扩大特征感受野。普通二维的卷积和空洞卷积的对比如图3所示。
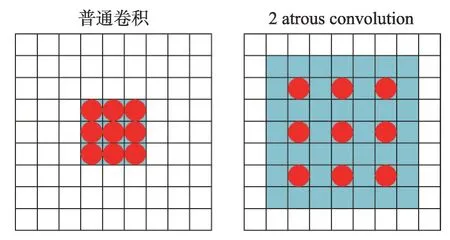
Fig.3 2D ordinary convolution and atrous convolution图3 二维普通卷积和空洞卷积
空洞卷积与普通卷积相比,就是在普通卷积核中加入膨胀系数,对原图像以膨胀系数(dilation rate)减1进行间隔采样。对于一个膨胀系数为d,原始卷积核大小为K的空洞卷积,空洞卷积实际大小K′的公式定义如下:

使用空洞卷积之后的卷积核尺寸变大,感受野也随之增大。空洞卷积不仅使感受野增大,获取了图像更多的特征信息,同时也不会造成模型参数增多,因此空洞卷积成为时下卷积神经网络中非常流行的卷积。
3 本文算法原理
3.1 网络模型
本文提出一种编/解码模式的肺分割算法,此网络结构主要包括三部分:编码模块、空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)和解码模块。网络结构如图4所示。
编码部分:医学图像中的器官切片尺度有着明显的差异,为解决多尺度下的目标分割问题,获得图像的多尺度信息,在编码模块中,本文连续使用4 个平均池化(average pooling)对输入图像进行池化操作形成形似金字塔的多尺度图像,在卷积深度增加时,利用级联操作向4 个级联分支分别注入多尺度的图像。编码模块包括4组卷积和4次下采样操作,与之对应的解码部分也包括4 组卷积和4 次上采样操作。为了在捕获深层次语义信息的同时解决深度神经网络的退化问题,受V-Net 网络框架的启发,编码模块每一层采用残差块为基础层,每一个残差块都包含两个3×3卷积操作,同时在每一层的卷积后面都加上批归一化层(batch normalization,BN)[13],每层残差块包含两组(3×3 conv+BN+ReLU)网络结构和一次跳跃连接,通过最大池化将特征映射输出到下一层,与此同时,金字塔第二张图像与上一层输出特征映射级联,送入到第二个残差块。每个深度都具有多尺度特征,因此多尺度图像可以集全局和局部的上下文信息,进一步增强不同深度语义信息的融合,以更好地利用U-Net的结构。
空洞空间金字塔池化:为获得输入特征映射的上下文多尺度信息,采用不同膨胀系数的空洞卷积获取多尺度特征映射,此时特征映射的大小发生了变化,为解决输入图片大小不一致造成的问题,采用空间金字塔池化(spatial pyramid pooling,SPP)[14]拼接形成特征映射。空洞空间金字塔池化(ASPP)[15]将SPP和深度可分离卷积[16]结合起来,采用深度可分离卷积将输入图像的通道与空间信息分开处理。本文采用ASPP 替代传统U-Net 网络编码的最后一层操作,ASPP网络结构如图5所示。
本文中,ASPP 要对上一层特征映射进行5 次卷积操作:第一次卷积,采用256 个普通的1×1 卷积核卷积特征映射,同时加入BN操作。为了在不增加参数规模的前提下,获得多尺度的特征映射。第二次到第四次卷积操作时使用深度可分离卷积。每一个深度可分离卷积网络结构形式可表示为Depthconv(3×3)+BN+Pointconv(1×1)+BN+ReLU。为了增加感受野,其中Depthconv采用膨胀系数分别是6,12,18的3×3 空洞卷积;Pointconv 采用的是普通的1×1 卷积,此操作不仅可以有效减少模型参数,同时也会加速模型收敛。不同采样率的ASPP 能有效地捕捉多尺度信息,但是随着采样率的增加,滤波器的有效权重逐渐变小,这时的3×3卷积核已经无法捕获整个图像上下文信息,而是退化为一个简单的1×1卷积核。为了克服这一问题,在进行第五次卷积操作时,需要先将原图大小降低为原来的1/16(此处16 为输出步长),接着进行一个全局均值池化,将特征映射送入输出通道数为256的1×1卷积核,再进行BN操作,最后利用双线性插值(bilinear upsampling)对低维特征映射进行上采样到原始大小。
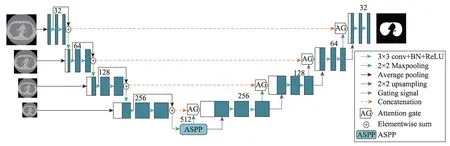
Fig.4 Structure of network图4 网络结构
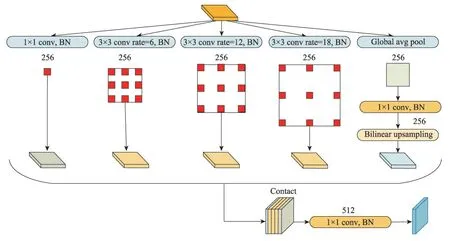
Fig.5 Structure of ASPP network图5 ASPP网络结构
为了获取特征映射之间的相关性,最后将提取到的5 个多尺度特征映射进行拼接;为了减少通道数,将拼接好的特征映射送入通道数为512的1×1卷积核,再进行BN 操作,将得到的特征映射送入到解码模块中。

Fig.6 Attention mechanism module图6 注意力机制模块
解码部分:神经网络在处理大量的输入信息时,模型会变得复杂,利用注意力机制(attention mecha-nism)[17]选择一些关键的信息加大权值分配,以此提高神经网络对目标区域的关注。在传统的U-Net 网络中,特征融合部分使用的是级联操作,浅层特征的位置信息比较多,但是学到的特征没有深层的高级,因此为获得包含目标区域的有意义输出,本文将注意力机制应用到处理肺部图像分割的算法中,采用注意力机制的解码模式。注意力机制模块如图6所示。
图6中,g为解码部分矩阵,xl为编码部分矩阵,Wg为门控信号,Wx为注意门。
首先上采样上一层的特征映射gi(Fg×Hg×Wg×Dg)进行1×1×1 卷积核运算得到下采样同层的特征映射进行1×1×1 卷积核运算得到。将g上采样的结果拼接到上文信息xl上,使用ReLU 作为激活函数,经过1×1×1 卷积核运算得到如下公式:

其中,b代表偏置项;ψ代表1×1×1卷积核;σ1代表激活函数ReLU。
最后利用Sigmoid激活函数,经过上采样得到注意力系数,注意力系数公式定义如下:

其中,σ2代表Sigmoid 激活函数,注意力系数α(取值范围0~1)不断将权重分配到目标区域,此时xl与注意力系数相乘,相乘结果会让不相关的区域的值变小,目标区域的值变大,从而提高分割精度。
3.2 损失函数
本文分割模型是基于编/解码模式的肺分割网络,需要训练模型来预测每个像素是前景还是背景,这是一个像素级二分类问题。分类问题中最常见的损失函数是二分类交叉熵损失函数(binary cross en-tropy,BCE)。BCE损失函数定义如下:
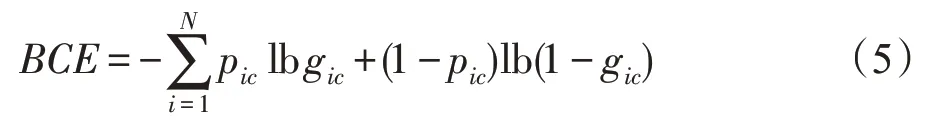
其中,gic∈{0,1}代表真实值(ground truth),pic∈{0,1}代表预测值(predicted value)。当gic与pic相等时,loss为0,否则loss为一个正数,概率相差越大,loss值就越大。
本文使用TL(Tversky loss)损失函数[18]来代替二分类交叉熵损失函数。相较于BCE、Tversky 相似度指数,它允许灵活地平衡假阴性和假阳性。Tversky loss损失函数定义如下:

其中,pic表示预测像素i属于病变c类的概率;表示预测像素i属于非病变类的概率;gic表示真实像素i属于病变c类的概率;表示真实像素i属于非病变类的概率。参数α和β分别控制假阴性和假阳性的比重,可以通过调参分给目标区域更多的权重以改善样本不平衡的情况,提高召回率。在下一章中,还将比较、分析使用二分类交叉熵损失函数和Tversky loss损失函数对模型的影响。
4 实验结果与分析
4.1 实验数据集
本文的数据集来自LUNA16 数据集(http://aca-demictorrents.com/collection/luna-lung-nodule-analysis-16---isbi-2016-challenge/)。LUNA16 数据集是最大公用肺结节数据集LIDC-IDRI的子集,LIDC-IDRI包括1 018个低剂量的肺部CT影像,LIDC-IDRI删除了切片厚度大于3 mm和肺结节小于3 mm的CT影像,剩下的样本构成了LUNA16 数据集。LUNA16 包括888 个低剂量肺部CT 影像(mhd 格式)数据,每个影像包含一系列胸腔的多个轴向切片。本文选取其中89 名患者,每个病人大约有100~750 张切片,最终形成13 465 张图像数据集,获得的图像分辨率为512×512,其中70%的样本用于训练集,30%用于测试集。
4.2 参数设置
本文的实验平台为Keras,实验的硬件环境为NVIDIA GTX1080Ti 单个GPU,Intel Corei7 处理器,软件环境为Keras2.2.4。使用he_normal 方法对权重进行初始化,采用Tversky loss作为损失函数,学习率设置为1E-4,采用Adam 优化器更新参数,训练与测试的batchsize取4。
4.3 评价指标
评价指标旨在衡量所提方案的性能,本文采用最常用的医学图像分割评价指标对算法性能进行评估,包括敏感性(sensitivity,SE)、相似性系数(dice similarity coefficient,DSC)、准确性(accuracy,ACC)和Jaccard指数(Jac)。各项评价指标定义如下:
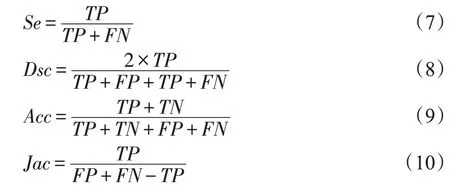
其中,TP(true positive)表示真阳性,它表示人工分割和算法分割公共区域的像素个数;FP(false positive)表示假阳性,它表示在算法分割区域内,在人工分割区域外的像素个数;TN(true negative)表示真阴性,它表示人工分割和算法分割外部公共区域的像素个数;FN(false negative)表示假阴性,它表示人工分割区域内,在算法分割区域外的像素个数。
4.4 实验结果
4.4.1 样本预处理对实验结果的影响
本文选用LUNA16 数据集的样本,在进行三维切片后,需要先把不含目标区域的切片去除,由于原始CT 图像存在噪声,因此在CT 图像输入网络前需要进行增强操作,以便加强前景与背景的区分度,对于标签图,需要将其二值化。处理之后的CT图像和标签图像如图7所示。

Fig.7 Image comparison before and after preprocessing图7 预处理前后图像对比
处理之后的图像较原始图像前景更加突出,干扰信息显著减少,二值化的切片也去除了包含支气管的像素,减少了无效区域的输入。预处理前后结果对比如表1所示。

Table 1 Comparison of segmentation results between preprocessed and unpreprocessed表1 预处理与未预处理的分割结果比较 %
从实验的结果来看,预处理的分割精度明显高于未经过预处理的分割精度。因此,在训练模型时首先要对样本进行合理的预处理。本文中预处理删除了不包含目标区域的图片,属于背景像素的数量显著减少,在一定程度上可以平衡正负样本,提高实验精度。
4.4.2 不同loss对实验结果的影响
由于此次实验选取的样本体积相差较大,因此在做器官切片时,存在大量包含小目标的切片,单张图像中目标像素占比较小,这样会导致正负样本数据不平衡,使网络训练较为困难。二分类交叉熵损失函数的一个局限性是它对假阳性(FP)和假阴性(FN)检测的权重相等,因此交叉熵损失函数不是最优的。为了证明使用Tversky loss作为损失函数能够有效提升分割性能,本文在最优网络框架中分别使用Tversky loss和二分类交叉熵损失函数进行对比实验。此处,假阴性检测的权重需要高于假阳性,因此Tversky loss 中参数相对应的设置α=0.7,β=0.3。使用不同的损失函数对分割结果的影响如表2所示。

Table 2 Comparison of segmentation results between different loss functions表2 不同损失函数的分割结果比较 %
从实验的结果来看,由于使用了Tversky loss 重新为假阴性和假阳性分配了权重,使目标区域的权值大于非目标区域的权值,此操作对敏感性指标(Se)产生了重要的影响,其他的评价指标也都高于使用二分类交叉熵损失函数的分割结果,说明采取Tversky loss作为损失函数的算法,可在不牺牲其他精度的情况下,有效提高敏感性指标,即召回率。
4.4.3 消融实验
为了说明本文多种改进策略可以有效提高算法的分割性能,本文做了3组对比实验来说明多尺度的图像输入、ASPP 和Attention 机制可以在不同程度上提高算法的分割性能。多种改进策略的分割算法比较如表3所示。
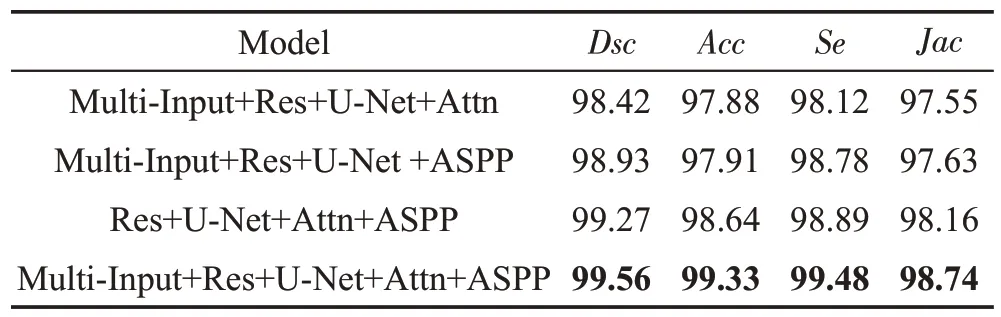
Table 3 Comparison of segmentation algorithms of several improved strategies表3 多种改进策略的分割算法比较 %
由表3 可以看出,加入ASPP 和Attention 机制的模型分割效果明显优于未加的模型,本文将ASPP运用到图像分割网络,能够有效减少连续下采样带来的信息损失,进一步强化分割效果。利用带有注意力机制的级联操作将高分辨率的局部特性与低分辨率的全局特性相结合,对产生的特征映射根据深层特征映射进行修正,从编码器中获取一些上文信息,加强目标区域的输出,从而提高了分割性能。
采用多尺度的图像输入的模型虽然比不上ASPP和Attention机制对分割效果做出的贡献,但是与下文提及的算法相比,在一定程度上也强化了分割效果。
4.4.4 与其他算法的比较
为更好地验证本文算法的性能,本文将提出的分割算法与传统的主动轮廓模型[19]和经典算法U-Net、V-Net进行比较,一些其他分割方法[20-22]也被纳入到比较中。不同分割算法的比较如表4所示。
从以上结果可以看出,本文算法在Dsc、Acc、Se和Jac的评估结果分别达到99.56%、99.33%、99.48%和98.74%,均优于其他方法。这说明本文提出的分割模型有利于肺分割。为了更直观地说明本文算法的准确性,本文随机选取了5 个样本A、B、C、D、E 在不同模型上的分割结果,如图8所示。

Table 4 Comparison of different segmentation algorithms表4 不同分割算法的比较 %
样本A 中原始CT 图像肺实质部分有些不清晰,无论是V-Net 还是Attn_U-Net,在像素模糊的部分分割效果都不是很好,本文算法的分割结果对比了图8中标签图像,不存在过分割的问题。
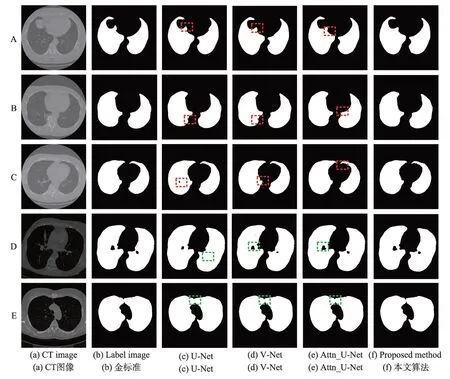
Fig.8 Segmentation results of different algorithms图8 不同算法的分割结果图
对于样本B 的分割,U-Net 和V-Net 在此样本的边缘处可以看到明显的斑点,如图8红色虚线框选中部分所示;Attn_U-Net 对于此样本的边界,分割不够圆滑,说明了加入ASPP的分割算法能够有效减少连续下采样带来的信息损失,进一步强化分割效果。
对于样本C 的分割,相比较本文提出的算法,U-Net 存在欠分割,V-Net 存在过分割的情况,如图8 红色虚线框选中部分所示,分割出的肺实质部分不够连续,存在一些空洞。
对于样本D的分割,传统的U-Net算法分割效果很差,未有效区分支气管和肺实质的像素,V-Net 分割效果要优于U-Net,说明加入了跳跃连接的分割模型在一定程度上可解决网络退化问题,对比加了注意力机制的Attn_U-Net 算法,可知注意力机制能有效增强模型分割效果,更加关注目标区域的输出。
样本E 中,由于左右肺距离比较接近,此样本是最难分割的,相比较本文提出的算法,其他算法分割都出现左右肺粘连现象,如图8绿色虚线框选中部分所示,而本文提出的算法能够有效解决粘连问题,分割出左右肺,更加体现了本文算法的分割性能。
为说明本文方法可以在不同的肺部图像上进行很好的分割,在Kaggle Data Science Bowl 2017(DSB2017)数据集上进行了实验(https://www.kaggle.com/c/data-science-bowl-2017)。DSB2017 是Lung Nodule Analysis在2017 年举行的比赛。比赛所提供的数据集由534个二维样本和各自的标签图像组成,用于肺分割。本文与采用同样数据集的CE-Net 方法[23]进行了比较,由于样本数量较少,本文进行了数据增强处理,实验结果如表5所示。
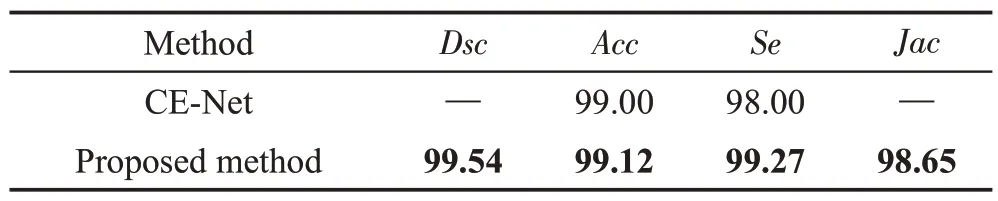
Table 5 Comparison of segmentation results between different methods表5 不同方法的分割结果比较 %
从分割的结果来看,本文算法在DSB2017 数据集上也取得了比较好的分割效果,更加说明本文算法性能好,泛化能力强,可以推广到分割不同的医学图像任务中。
5 结束语
本文提出了一种编/解码模式的肺分割算法。一方面在编码模块采用多尺度融合的编码方式,提高了模型对不同尺度特征的适应能力;另一方面采用ASPP,充分提取了上下文多尺度信息,最后通过注意力机制的级联网络结构,加强目标区域信息的捕捉,有效避免了在特征解码上冗余信息的获取。实验结果表明,本文方法能有效分割肺实质区域,与其他方法相比分割效果更好。除此以外,本文方法泛化性较强,可广泛应用到不同的医学图像分割任务中。从肺部CT图像中完整地分割出肺实质,对后续的肺结节检测提供了良好的研究基础,下一阶段的任务是根据这项工作的结果进行肺结节的检测。
