数据驱动下公共图书馆用户信息服务闭环系统研究
2020-08-11郭春淼
顾 婷 郭春淼
(云南大学历史与档案学院 云南昆明 650091 )
1 引言
2015年9月,国务院印发的《促进大数据发展行动纲要》中提出,“大数据”已经上升为国家级的发展战略。经过四年的发展,大数据已逐渐向各行各业、各个领域延伸,云计算、人工智能、区块链、5G等新技术的发展也与大数据密不可分,共同改变了人类生活的各个领域。2018年4月,工信部总工程师张峰指出,目前,全球大数据进入到加速发展时期,数据总量逐年增长50%。Jim Gray博士[1]谈到,目前我们正步入数据密集型的第四范式,关于大数据驱动的研究主要是面向个体化、全样本的发现和预测研究。2018年米加宁等人[2]认为,“大数据”作为第四研究范式,破除了传统社会科学目标弱化、学科学派对立、数据质量良莠不齐和统计偏误的四大局限性,给现今的社会科学研究奠定了更高的数据起点和更广阔的方法论。
数据驱动是指通过移动互联网或者其他的相关软件为手段采集海量的数据,将数据进行组织,在形成信息以后,对有用的信息进行整合和凝练,在数据的基础上经过训练和拟合形成自动化的决策模型。换言之,数据驱动是由数据激发信息的过程或活动,不是仅凭直觉或个人经验形成信息的简单范式。数据驱动包括三个特征:海量的数据、自动化的业务和强大的模型支持自动化决策。
虽然关于数据驱动下图书馆的研究已成为近年来图情领域的研究热点之一,甚至有些图书馆宣称已经实现了数据驱动,但是大部分的图书馆只是以数据为中心进行决策,并非真正地实现了图书馆的数据驱动。
2 文献综述
2.1 数据驱动的研究
2013年,田野、祝忠明[3]提出了一种关联数据驱动的数字图书推荐模型,给用户提供了跨数据源的信息推荐服务。首先,将图书馆的内部数据和外部相关的关联数据相结合,再根据图书馆信息资源各自的特征,构建出用户社会关系和数字图书两大语义本体知识库;其次,时时观察用户对图书浏览的频率和频次,针对不同的用户采取不同的推荐手段,最终实现用户推荐服务的全方位覆盖。
2018年,洪亮等人[4]以大数据驱动为主要视角, 以图书馆的业务流程为导向,提供了图书馆智慧信息服务体系建构的思路,构建出大数据驱动下图书馆智慧信息服务体系。
2019年,曹树金等人[5]谈到,图书馆大数据系统的构建结构包括:多来源的数据采集层、数据预处理与存储层、精准化的数据分析建模层和支持精准化的管理与服务的应用层等自下而上的四个层次,以求为读者提供精准化的服务。同年,杭哲、李芙蓉[6]在基于关联数据技术建构参考咨询服务新模式的基础上,通过关联数据来实现图书馆信息资源的精准化、结构化以及关联化的数据整合, 优化已有模式中的各个环节,增加统计分析模块,用以改善虚拟的咨询服务方式,提高图书馆参考咨询的服务质量。
2.2 公共图书馆的研究
2008年,王学熙[7]对我国公共图书馆服务体系的基本特征和现状进行了分析,提出公共图书馆具有形态性、公益性和社会性等特征,阐述了五种不同的公共图书馆服务体系建设模式。
2012年,李岩等人[8],从需求导向的角度出发,在了解和分析信息需求、服务要素以及服务方式的基础上,构建出框架结构全面地描述和提出健康信息服务多元化服务模式,为我国公共图书馆共享现有的服务经验与成果、加强和规划未来的服务提供参考。
2016年,王敏[9]将大数据与小数据进行对比,研究了小数据思维在公共图书馆信息服务上应用的重要性,从小数据的服务原则、服务流程和服务措施三个方面,提出了公共图书馆信息的服务模式。
综上所述,虽然数据驱动下公共图书馆的研究已经有了一定成果,但当前大多数的公共图书馆即使在服务模式和服务创新等方面展开了非常深入的尝试,也提出了数据驱动图书馆系统模型的构建,但仍然存在一定的问题。本文在发现和分析问题的基础上,为公共图书馆数据驱动下的信息服务发展提出相应的解决措施。
3 数据驱动下公共图书馆用户信息服务问题
3.1 数据孤岛化问题
在大数据时代,以大量数据为基础的现代化图书馆会比传统图书馆更为科学、高效[10]。但是研究发现,数据孤岛化问题一直是图书馆实现数据驱动的最大难题,这一难题使得公共图书馆的“数据驱动”变为空谈。
首先是数据拥有者之间存在孤岛化问题。大数据时代的到来,使得其在各个学科领域形成了全方位渗透,学科间跨界融合不断加深,用户所求的信息服务往往需要跨学科的数据,但是由于商业领域信息不对称性带来的巨大经济效益,政府领域数据存在较大的安全隐患,科研领域数据往往分散在各个研究者的手中,所以大量数据仍然集中在政府、互联网企业、数据商和各个科研机构手中。近年来,全国各级政府贯彻执行国务院颁布的《促进大数据发展行动纲要》,初步搭建了各级政府的大数据平台系统,但是在商业、数据商、个人数据等方面,由于缺乏统一的共享机制,导致这些数据拥有者之间形成一个个“数据孤岛”,在采集数据方面有一定的难度。就公共图书馆而言,各个省市公共图书馆大多仍是独立采购资源,独立管理资源,独立提供信息检索服务。
其次是数据系统处理流程存在孤岛化问题。由于数据系统在环节间没有形成自动化对接、数据跨系统且图书馆员缺位的情况下,环节与环节之间存在不同的断裂处。当一个环节结束或出错,该系统便失去了对流程的掌控,导致图书馆无法为用户提供更好的数据服务。目前而言,虽然在大数据利用方面,图书馆标榜以用户为中心,以数据为驱动,但大多数图书馆尤其是公共图书馆尚未形成数据驱动的闭环,仍需要人力的操纵和决策,而且数据决策难免会掺杂个人意志;只要用户信息服务系统在某一环节的节点缺位和失误,数据流程就会产生断裂或错误的风险,这对公共图书馆产生的大量数据无疑是一种资源浪费。
3.2 数据使用问题
传统的数据库是利用单个服务器来实现储存和处理信息的需求,但是当数据量增大时,一台服务器无法满足信息处理的需求,这就需要增加更多的服务器,然而随着近年来数据急剧增加、分区复杂化、服务器的故障率和服务器费用提高,无形中给公共图书馆的数据信息服务造成极大的压力。海量数据不仅考验着公共图书馆如何进行储存,还考验着图书馆如何对数据进行高效、快速、实时的处理。当今社会,数据量庞大、分布广、格式多、真假混杂,且每时每刻都在急速增加。在数据驱动的背景下,公共图书馆亟需使用更先进的技术方法来进行数据管理。满足上述需求的数据库不仅需要巨大的储存空间、较低的费用,还要能够高效地进行数据处理、分析以及提供相应的数据服务。这些需求已经远远超出用来处理结构化、关系型数据的传统数据库能够处理的范围。
3.3 系统无法收集有效反馈数据问题
根据专家学者在数据驱动方面的研究[11],构建的公共图书馆的大数据体系框架,大致分为四个层次:数据采集层→数据处理和集成层→数据建模和分析层→数据服务层→用户(如图1所示)。但是由于这个系统缺少数据反馈层,使得系统无法收集反馈数据,从而无法自动进行系统的评估并进行系统优化和迭代升级。新的情况和需求发生时,仅仅依靠图书馆员的个人经验来处理,造成信息资源使用完毕后无法对未来的使用提供有用数据。用户为什么使用该信息资源、使用时做了什么操作、是否解决了问题、使用该资源的用户群体有无类似条件、能否为后来使用者提供借鉴等等,这些都是可以供系统优化、提高服务的宝贵的数据。因此,就需要一个不仅能对数据进行实时采集,对数据进行自动处理、分析和输出使用,还要对系统进行评估和反馈、对分析方法和模型进行优化的系统(如图2所示)。
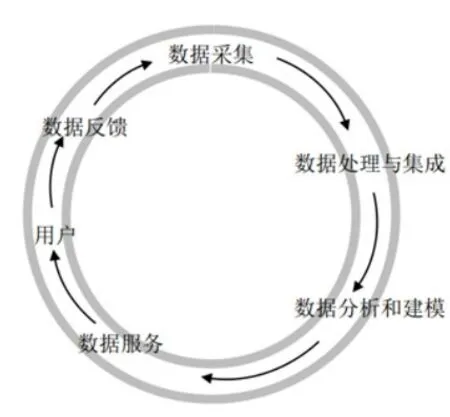
图2 持续不断的数据驱动闭环系统
基于数据驱动闭环系统,笔者刻画出具体的数据驱动图书馆系统处理流程(如图3所示)。公共图书馆通过对线上、线下及第三方数据进行采集,将采集到的数据进行处理与集成之后,建立相应的用户标签和数据模型,对数据进行可视化分析,可视化分析结果提供给用户形成图书馆的数据服务,用户又将数据反馈给图书馆,形成一个良性的闭环结构。
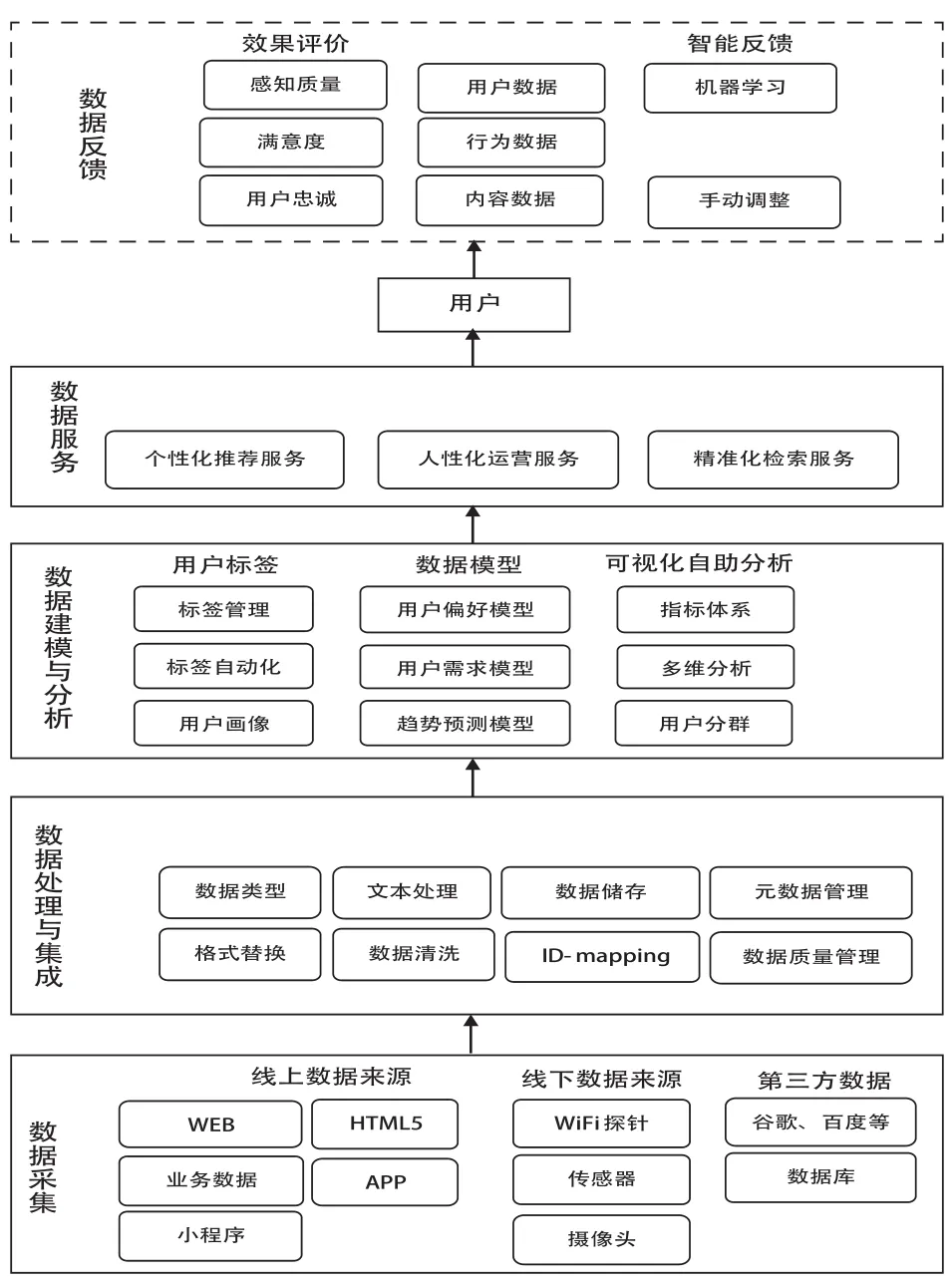
图3 数据驱动图书馆系统处理流程
4 数据驱动下提高公共图书馆用户信息服务水平的策略
4.1 积极响应和协助建设大数据共享平台
2017年8月,文化部印发的《“十三五”时期公共数字文化建设规划》中提出,要大力推动全国文化信息资源共享工程的进程。在政府的大力支持下,公共图书馆应该牢牢抓住机遇,积极投身于信息资源的共享工程中去。各级公共图书馆首先应当进行数据资源整合,打破公共图书馆之间的数据界限,与政府合作,研究出统一的框架。其次,要将公共图书馆独立采购、独立管理、独立服务的模式改为由统一的数据格式、技术标准组成的数据共享平台,并且能够接入政府信息资源共享系统,激励和引导各类数据持有者加入信息资源共享平台。再次,要对数据进行融合,通过数据清洗、噪点消除、缺点补充等技术处理,生成ID储存于统一的数据资源中心。最后,由于数据资源中心里涉及到国际、企业、机构和个人的信息安全和隐私,所以在对数据共享、开发时,应制定严格的制度管理规定,对数据设立安全等级,对数据的管理和使用形成规范化管理,尤其是对USB、打印设备等外接设备,要防止数据感染和泄露。
公共图书馆是独立于数据利益相关者外的第三方机构,所以对数据应承担监管者的角色,对数据的归属提供证明,保护数据提供者的权益。公共图书馆还应定期召开数据共享技术大会,邀请各类馆员和专家学者探讨新技术、新成果和发展建议,为数据共享平台建言献策,从而解决公共图书馆存在的数据孤岛问题。
4.2 采用分布式文件系统
Hadoop框架是一个能够对海量数据信息进行分布式处理的软件框架,形成了扩充力强、成本低廉、效率高以及可靠性强等特点,目前已成为许多大型公司、科研机构等用于处理大数据的主流工具。Hadoop以HDFS(储存)和MapReduce(计算)为核心。其中,HDFS可以协同多台服务器共同实现海量数据存储的目标。而MapReduce则是对离线大数据进行处理,它的计算过程被封装得很好,用户只需使用简单的map和reduce函数就可以对数据信息加以处理,将数据集的大规模操作分发给网络上的各个节点,每个节点进行周期性的工作反馈,直到任务结束,由此实现数据处理的可靠性。通过使用Hadoop框架,公共图书馆就能解决数据驱动背景下产生的数据使用问题,对公共图书馆的数据信息进行有效存储和处理,打通数据使用的各个环节,提高公共图书馆数据信息的利用效率,提高公共图书馆的用户服务水平。
4.3 构建数据反馈层
数据反馈是实现公共图书馆数据信息系统闭环的关键部分。数据驱动环境下,传统的解析方法不足以满足数据反馈的需求。因此,在系统面向用户的服务结束之后,对系统使用效果构建评估优化模型就显得至关重要。本文设计了公共图书馆基于分群标签闭环系统的反馈系统(如图4所示)。
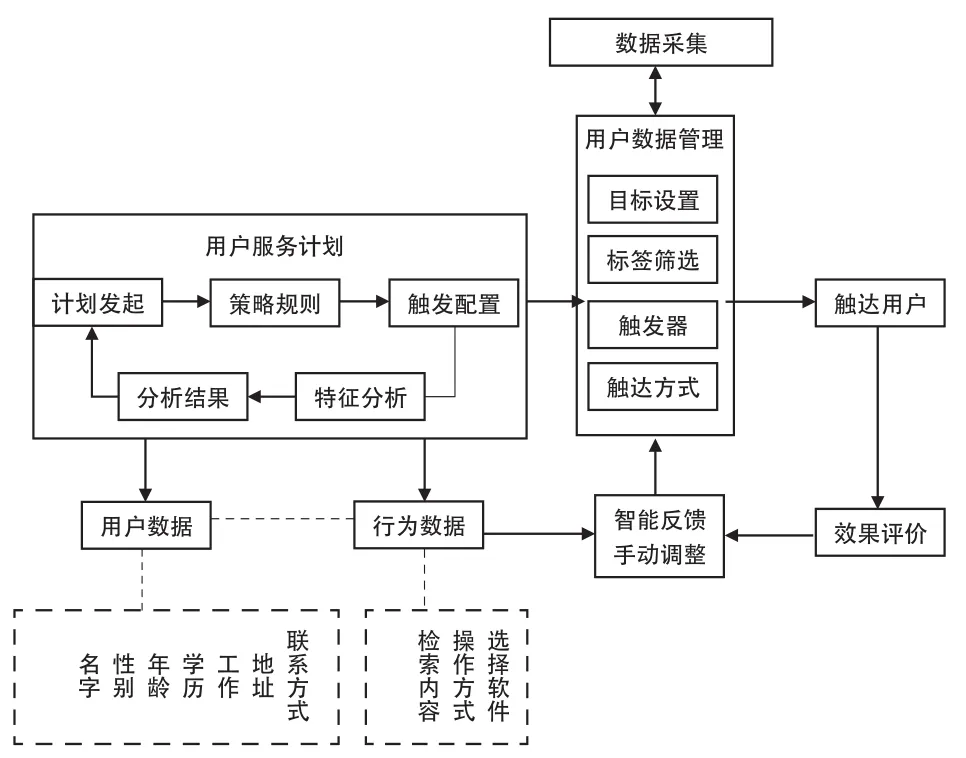
图4 数据反馈层模型框架
闭环(闭环结构),也称为“反馈控制系统”,是把系统输出量的测量值与其期望的给定值做比较,从而产生的偏差信号,通过调节控制此偏差信号,让输出值无限趋近于期望值。在公共图书馆信息服务闭环中,该系统将自动收集公共图书馆的各项数据,按照数据模型进行分析处理,服务于用户,然后收集反馈数据,对新的数据进行自动分析,图书馆员只需对现有数据和期望数据进行比较,调整偏差使之接近与符合期望值,形成一个闭环。数据驱动只有在实现闭环的情况下才能更好地完成数据的自动流通,将大数据融合进图书馆信息服务系统的全流程并形成闭环,不仅将图书馆员从海量的数据中解放出来,也解决了信息服务周期长、效率低的问题,提高了图书馆信息服务的水平。
(1)用户服务。首先根据公共图书馆已有的信息属性,将信息按属性进行分类,构建信息特征矩阵,其后根据用户注册的信息以及历史行为数据,建构出用户目标矩阵,再针对用户目标矩阵,生成相应的向量以及向量距离近的相邻用户,用当前用户目标矩阵和相邻用户的目标信息进行对比,融合后形成新的用户服务矩阵,构建用户画像。根据用户画像制定特殊的信息服务,然后将数据挖掘的结果通过直方图、词云图和关系图谱等进行可视化展示,得出结果后加入用户的数据信息反馈,并根据用户的数据信息反馈做出系统改进和优化。
(2)效果评价。ASCI美国顾客满意度指数模型具有模型设计简洁、顾客满意界定和表示变量设计合理的优点。本文在借鉴ASCI的基础上,构建了公共图书馆信息服务用户的满意模型(如图5所示),设立了用户期望、感知质量、用户满意度、用户抱怨以及用户忠诚五个变量。
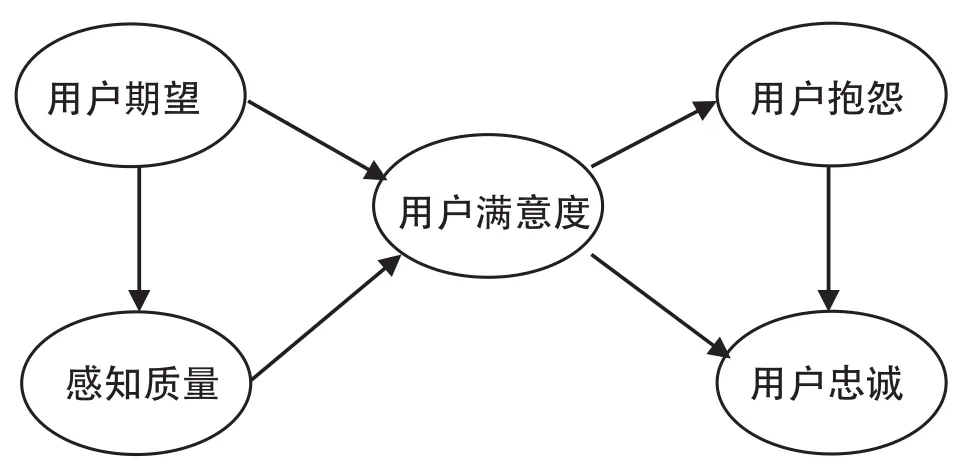
图5 公共图书馆信息服务用户满意度模型
(3)智能反馈。平均绝对误差(Mean Absolute Error,MAE)是推荐算法领域常用的评价,用它作为评价标准,将所有单个信息服务预测评分和用户真实评分做差,求出差的绝对值的平均。平均绝对差可以避免误差相互抵消,用来反映算法的合理性。根据服务评价、用户数据和行为数据是否满足期望值,进行算法和数据用户优化,得到反馈数据,然后将反馈数据发送给数据采集环节。
当用户使用系统时,根据用户信息和历史行为按策略规则构成用户服务矩阵生成触发配置;不同的触发配置在触发器中有不同的触发方式,根据触发条件的方式进行标签筛选,并根据标签提供相应的信息服务,比如个性化推荐、需求猜测等服务;服务完成之后,系统弹出服务评价界面,通过设置的选项和留言收集用户评价,自动分析触发效果,智能反馈到用户服务系统进行算法优化和数据存储,工作人员也可以根据期望进行手动调节,形成自动化、精细化的公共图书馆用户信息服务闭环。
5 结语
数据驱动环境下,数据密集型范式改变了传统研究方法,也推动了图书情报领域的方法论变革。在数据信息日益密集的情况下,给用户提供效率高、精准化、服务优的信息服务系统也越来越重要。本文通过总结图书馆在大数据环境下的系统处理流程研究的基础上,指出了系统处理流程存在的不足之处,提出了公共图书馆信息服务闭环系统的概念,分析了系统实现的条件和系统的构建思路,从而提高公共图书馆的用户信息服务水平和质量。
