基于遗传模拟退火算法的药品零售大数据关联规则挖掘
2020-08-11卞显福
盛 魁,马 健,曹 岩,卞显福
(1.亳州职业技术学院 信息工程系,安徽 亳州 236800;2.安徽中医药科学院 亳州中医药研究所,安徽 亳州 236800;3.中国科学技术大学 软件学院,安徽 合肥 230051)
随着大数据、云计算、物联网、移动互联网等信息技术爆发式发展,药品零售企业积累大量的数据。目前,这些数据只用在销售统计和药品库存管理上,对数据相关性分析和预测分析等深层次运用较少,使得这些有价值的资源却成为企业信息存储的负担。如何从这些海量数据中挖掘出有价值的药品关联知识,实现药品的精准销售和个性推荐成为当前人们研究的热点。关联规则挖掘是一种有效的数据挖掘方法,它可以从大量的数据信息中发现隐藏的、有价值的关联和规律[1]。大数据的关联规则挖掘流程包括源数据的获取、频繁项集提取、强关联规则提取和有价值关联规则提取,已应用于电力、金融、交通、医疗、零售等领域[2-3]。
本文从药品零售大数据本身出发完成知识发现,在遗传算法选择操作、交叉运算和变异运算中融入模拟退火算法,提出一种基于遗传模拟退火算法的关联规则挖掘改进算法,用以挖掘药品零售大数据之间关联和规律,有效地量化了药品之间的相关程度,为药品零售企业的经营决策提供支持,能够为企业带来更多潜在商业机会。
1 关联规则技术研究
1.1 关联规则挖掘
关联规则挖掘是从海量数据中发现事物之间可能存在的关联和相互关系,以揭示事物间内在的本质联系。设I={i1,i2,…,im}是所有数据项的集合,给定一个事务集合D,T={t1,t2,…tm}为D中的一个事务,即T⊆I。若项集A⊆I且A⊆T,则事务T包含项集A,关联规则是形如A⟹B的蕴含式,其中A⊂I,B⊂I,且A∩B=φ。一般用支持度(support)和置信度(confidence)来衡量一个关联规则,支持度表示关联规则出现的频度,表达式为:support(A⟹B)=P(A∪B),置信度则表示关联规则的强度,表达式为:confidence(A⟹B)=P(A|B)。如果规则不但满足support(A⟹B)>supportmin,而且满足confidence(A⟹B)>confidencemin,则称规则A⟹B为强关联规则。关联规则挖掘是要在事务集合中找出全部强规则。
1.2 关联规则挖掘方法
常用的关联规则挖掘算法有Apriori算法、FP-growth算法、Eclat算法、神经网络法、决策树法、粗糙集和遗传算法等,但在具体应用时会根据实际问题需求对现有挖掘算法进行融合或改进,有针对性的进行数据分析和挖掘[4]。
(1)Apriori算法
Apriori算法是一种宽度优先算法,算法简单、易实现,不需要构建新的数据结构。当数据库中的数据量较大时,需要对数据库多次扫描数而产生大量频繁项集,导致算法效率不高[5]。
(2)FP-growth算法
FP-growth算法采用分而治之的策略,算法对数据库仅需扫描两次且不需要产生候选集,在效率上优于Apriori算法。但算法构建项头表、FP-tree和条件FP-tree等数据结构需要消耗大量存储空间,影响挖掘效率[6]。
(3)Eclat算法
Eclat算法是一种深度优先搜索的算法,算法对数据库不需要重复多次遍扫描,通过交集操作求频繁项集。但算法无法对产生的候选集做剪枝操作,生成大量的候选项集,并且算法在运行的过程中,会消耗大量存储空间[7]。
(4)遗传算法
遗传算法(Genetic Algorithm, GA)是基于达尔文进化论的自适应全局优化概率搜索算法,通过选择、交叉、变异等遗传运算达到优化的目的。GA算法具有良好的全局搜索特性,但算法在进化过程中容易出现早熟现象。遗传算法已在机器学习、人工智能、信号处理、组合优化和自适应控制和等领域得到广泛的应用。
(5)模拟退火算法
模拟退火算法(Simulated Annealing Algorithm, SA)是基于蒙特卡洛思想设计的随机寻优迭代求解算法,在问题求解中引入热力学的退火平衡模型,能够实现搜索全局最优解。SA算法在较小的范围内具有寻优速度快、收敛精度高等特点,但是寻优的结果受初始值的影响较大。模拟退火算法已在生产调度、机器学习、控制工程、信号处理、神经网络等领域得到了广泛应用。
2 基于GA-SA算法的关联规则挖掘设计
2.1 挖掘算法设计思想
为了克服GA算法局部搜索能力差、早熟收敛,且易陷入局部最优解的缺点,将SA算法融入GA算法中,形成一种高效的GA-SA算法,实现对药品零售大数据关联规则挖掘。GA-SA算法以GA算法为主体,SA算法为其辅助,在SA算法选择操作、交叉运算和变异运算中融入SA算法,从而提高算法的效率。通过GA算法寻找一批优良的群体,利用SA算法抑制群体陷入局部最优,进一步调整优化种群,减少消耗进而筛选得到有用规则。挖掘流程如图1所示。
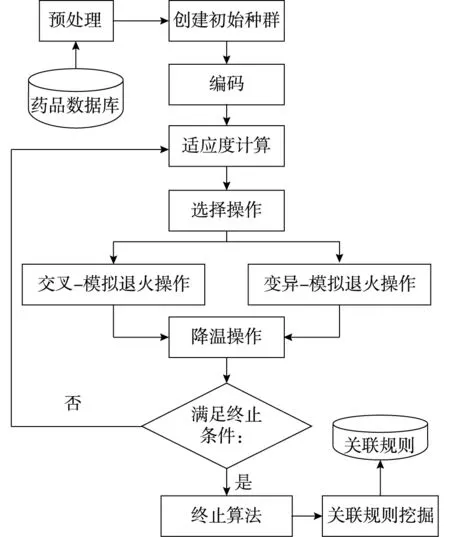
图1 GA-SA算法的关联规则挖掘流程图
2.2 GA-SA算法的设计
(1)编码方法的设计
关联规则编码是设计GA-SA算法时的一个关键步骤。为了便于交叉、变异和选择算子的操作,采用实数编码方法对个体进行编码。假设个体的长度为N,定义实数数组A[N]与其对应,字段的属性值与数组A[i](i∈[1,N])的元素值一一对应,如果此属性与其他的属性无关联则A[i]的值为0。
(2)适应度函数设计
适应度函数是GA-SA算法进化过程的驱动力,也是群体进化过程中用到的唯一信息。采用可信度和支持度表示适应度函数,适应度函数表达式为:
(1)
其中,ws+wc=1,ws≥0,wc≥0,supportmin表示支持度的阈值,confidencemin表示可信度的阈值。
(3)选择操作
选择操作是为了提高全局收敛性和计算效率,避免基因缺失。采用最佳个体保存法进行选择操作,保证交叉和变异操作不能破坏进化过程中某一代的最优解。在当前种群P={x1,x2,…,xn}中,个体xi被选中进入下一代的概率为:
(2)
其中,f(xi)是个体xi的适应度函数。Tk为进化到第k代时的退火温度。
(4)交叉退火和变异退火操作
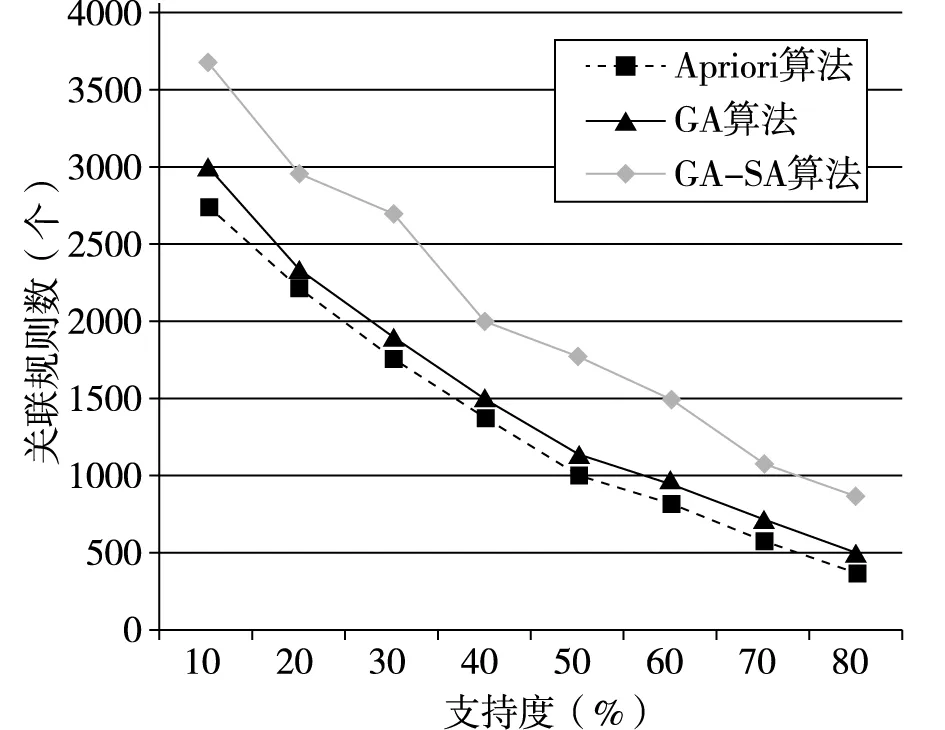
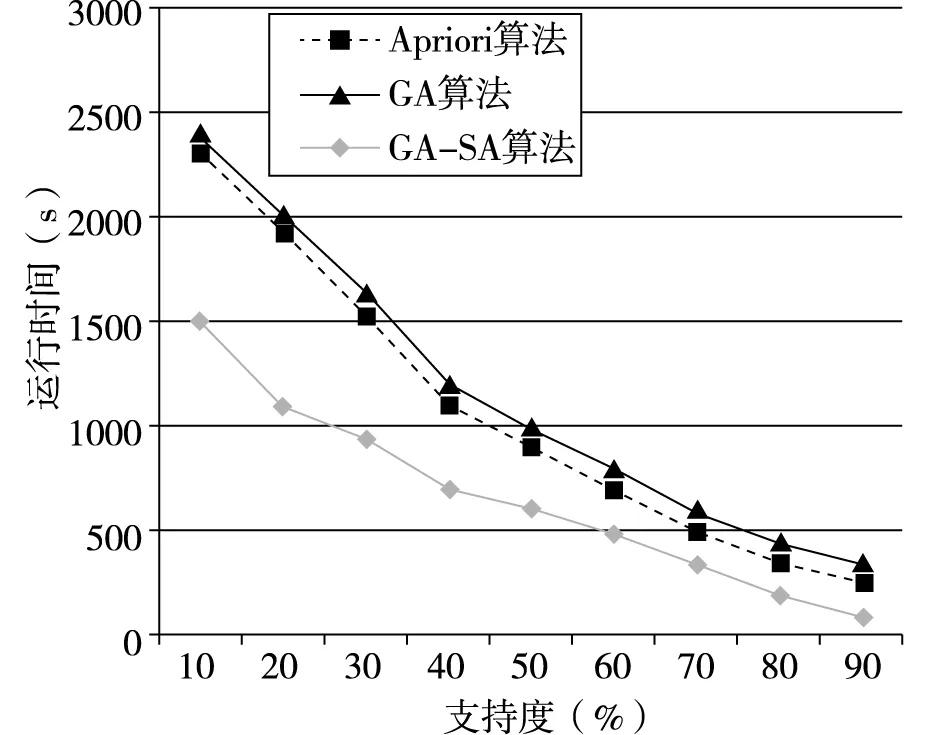
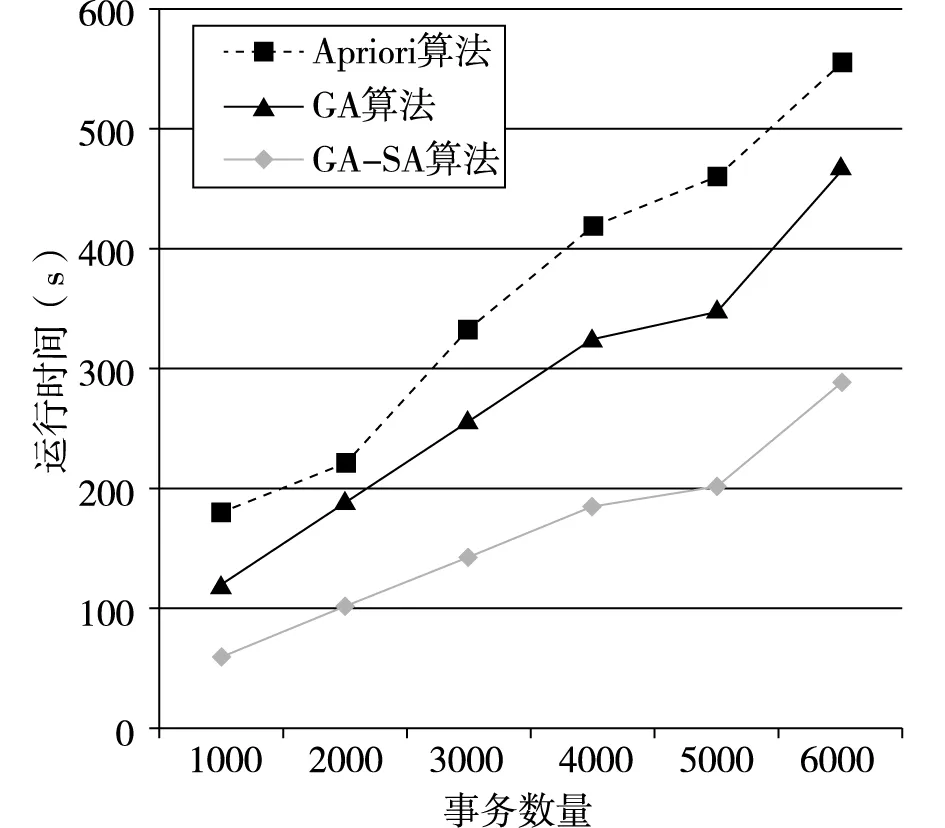
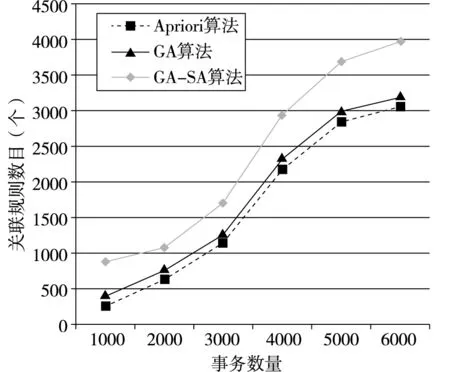
变异退火操作GA-SA算法中生成新个体的主要手段。为了不会影响算法的效率,本文采用单点交的方法。p1、p2按照预定交叉概率,交叉生成新子代c1、c2,计算f(ci)、f(pi)(i=1,2)的值,同时实施模拟退火操作[8],如果f(ci)>f(pi),则用ci代替pi;如果f(ci) (5)降温操作 采用有限的非齐次马尔可夫链序列[9]实现降温操作,温度变化表达: (3) 本文开发环境为Python,版本为Python3.6,IED为Pycharm和Anaconda,运行平台为windows 10,算法用Python语言实现。 实验数据来自亳州某连锁零售药店21家门店2018年5月1日到2018年10月1日6个月的数据,数据库包括药品信息表、药品类别和门店的销售表三类原始数据表格682000条记录。 (1)药品信息表。包括药品编码、药品名称、规格、类别、药品属性、产地、原价、单价、条形码等。 (2)药品类别表。包括商品的药品编号、药品名称、类别码和类别名称(如心脑血管类,胃肠类等)、药品属性(中成药、西药、中药饮片)等。 (3)门店的销售表,包括流水号、门店号、购买药品序号、日期、药品编码、购买数量、销售价格等。 获取的原始数据含有一些“脏数据”,低质量的“脏数据”将会导致低质量的挖掘结果。数据处理主要包括“脏数据”(不完整的数据、有明显错误的数据以及重复数据)的剔除和处理。数据预处理的过程主要有: (1)数据清洗 根据数据分析的任务选择任务所需的数据对象和属性,对缺失数据、重复数据和异常数据等不规整的数据进行清洗。针对脏数据,应用Python编写程序对原始数据进行处理,清除挖掘中不需要的数据信息,保存药品数据的原始特征。 (2)数据集成 数据挖掘只需要导入需要的数据,这就需要针对终端零售数据存储在关系数据库中的不同表结构中,提取药品信息表、药品类别和门店的销售表所需的数据列数据,如药品名称、类别名称、销售时间、销售数量等数据进行处理,提取所需的数据列数据。对原始数据682000条记录,经过数据清洗和去重等处理后有561357条记录为有效记录。 Step1.初始化控制参数。群体规模M,最大遗传代数MAX,初始种群P,交叉概率Pc,变异概率Pm,初始退火温度T0,终止温度Tend,最小支持度supportmin和最小置信度confidencemin。 Step2.适应度函数计算。根据公式(1)计算当前种群P中的每个体适应度值。 Step3.选择操作。根据公式(2)对全部个体都进行了选择操作。 Step4.交叉退火操作。按照本文GA-SA算法设计进行交叉退火操作。 Step5.变异退火操作。方法同Step4。 Step6.降温操作。根据公式(3)进行降温操作。 Step7.算法终止。判断遗传代数是否达到给定到最大遗传代数或降温温度是否达到终止温度,如果达不到转Step2;否则结束算法。 Step8.关联规则挖掘与提取。 初始种群规模为40,最大的迭代次数MAX=30,交叉概率为0.9,变异概率为0.05;最小置信度为0.6,最小支持度设定为0.01,初始温度为50000,退火终止温度为15;温度可以下降的最大次数M=1000。 采用GA-SA算法的关联规则挖掘算法对预处理后的数据进行分析,最终得到关联规则7715条,发现部分关联规则如图2所示。 图2 药品和药品关联规则结果 从图2中可以看出,以“抗感冒药⟹抗病毒药”规则为例,在购买不同种类的消费者中,购买抗感冒药类药品同时购买了抗病毒药,感冒大部分是由病毒引起的,毒性感染导致的鼻塞、流涕、打喷嚏等症状,从医学角度看,需要理抗病毒药如双黄连口服液或者抗病毒片等药品进行联合治疗,规则与实际用药情况基本相符。 规则“肠胃疾病类⟹营养保健类”表明,消费者在购买肠胃疾病类药品的时候购买营养保健类药品的机率比较大。在购买奥美拉唑肠溶胶囊、硫糖铝片、正露丸等肠胃道用药的同时还会买类似复方阿胶、六味地黄丸、维生素类的药品。从医学角度看,由于肠胃消化不好的顾客通常体质比较弱,在治疗肠胃需要服用营养保健增加肠胃道消化,符合一定用药的规律。 规则“高血压类⟹心脑血管用药”表明,购买高血压类药品的消费者,同时也可能购买心脑血管用药的药品。患者长时间服用硝苯地平缓释片、卡托普利片和替米沙坦降压药会导致扩张血管,配合服用阿司匹林肠溶片、复方丹参片和脑洛通胶囊,增加血管弹性,预防脑溢血,调解血脂,改善血液粘稠度,规则与实际用药情况基本一致。 为了验证GA-SA算法的性能,从事务数目和支持度两方面分别与Apriori算法和GA算法进行比较,算法采用Python实现。不同事务数目下算法性能比较结果如图3和图4图所示;不同支持度下算法性能比较结果如图5和图6图所示。 图6 不同支持度下算法挖掘规则数目比较 图5 不同支持度下算法运行时间比较 图3 不同事务数目下算法运行时间比较 图4 不同事务数目下算法挖掘规则数目比较 通过图3和图4可以看出,在事务数据量不断增加的情况下,运行时间都在增加,但GA-SA算法相比Apriori算法和GA算法挖掘速率略微快些,说明GA-SA算法在处理大规模数据集时,运行较快,性能较好。相同的事务数据量下,GA-SA算法挖掘出的规则数更多。 通过图5和图6可以看出,三种算法的性能都受支持度的影响,同一支持度下GA-SA算法挖掘关联规则运行时间最短,但挖掘的关联规则数目最多。 通过上面两种情况下的比较,证明了GA-SA算法不论在运行时间还是在挖掘规则数目上都要优于Apriori算法和GA算法,说明了GA-SA算法在挖掘关联规则方面具有较高的运行效率和较全面的关联规则。 本文以遗传算法为主导,模拟退火算法作为其辅助,提出了一种新颖的GA-SA算法挖掘关联规则算法,对药品零售大数据进行分析,能够挖掘出隐藏在药品零售大数据之中有价值的知识与信息,并自动计算出药品之间的支持度与置信度,有效地度量了药品之间的影响程度,为药品零售企业决策提供了参考依据,并通过与Apriori算法和GA算法进行对比,证明了GA-SA算法的有效性。药品零售大数据的挖掘研究仍具有很大的空间,如何设计更准确的算法实现药品销售预测和智能采购,将是我们下一步研究的内容。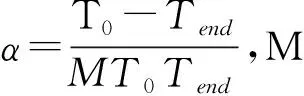
3 基于GA-SA算法的关联规则挖掘
3.1 数据采集
3.2 数据预处理
3.3 算法步骤
4 挖掘结果与算法性能分析
4.1 关联规则挖掘

4.2 算法性能分析
结语
