基于BGRU和自注意力机制的情感分析
2020-08-10孙敏李旸庄正飞钱涛
孙敏,李旸,庄正飞,钱涛
(安徽农业大学信息与计算机学院,安徽合肥230036)
0 引言
生活在互联网技术快速发展的时代,使用互联网技术通过社交网络进行即时通讯、发布信息、表达情感等已是一种普遍现象。情感分析[1](sentiment analysis),又称倾向性分析,意见抽取(opinion extraction),意见挖掘(opinion mining),情感挖掘(sentiment mining),主观分析(subjec⁃tivity analysis),其主要任务就是对用户生成的文本内容进行分析,以此来判定文本中的情感极性:积极、中性或消极。
1990年,Elman[2]提出循环神经网络(recurrent neural networks,RNN)模型,RNN的输出取决于当前的输入和上一个节点输出的结果,可以学习上下文的语义信息,但容易出现梯度消失问题。为 了 解 决 此 问 题,1997年,Hochreiter等[3]提 出 长 短 时 记 忆(long short-term memory,LSTM)网络,LSTM通过加入“门”机制改善了RNN的梯度消失,但LSTM的结构复杂,导致训练时间长、参数较多等问题。Cho等[4]进一步将LSTM的单元状态和隐层状态进行合并,提出一种结构较为简单的门限循环单元(gated recurrent unit,GRU)网络模型。双向门限循环单元(bi⁃directional gated recurrent unit,BGRU)网络模型由一个单向向前传播的GRU和一个单向向后传播的GRU组成,输出结果由这两个GRU共同决定。刘洋[5]首先采用GRU对时间序列进行预测,再对其结果进行二阶指数平滑优化,提高时间序列预测的精度。李骁等[6]利用BGRU对互联网文本信息进行序列自动标注,可以快速、准确地提取输入序列的特定信息。2014年,GoogleMind团队首次提出采用内容注意力机制做图像分类,有效提高了图像识别精度[7]。随后,Bahdanau等[8]将注意力机制应用到自然语言处理(natural language processing,NLP)领域,使用注意力机制将源语言端每个词学到的表达和预测翻译的词联系起来,提高了翻译的准确率。2017年,谷歌提出自注意力机制(Self-Attention)并用于机器翻译取得了更好的翻译效果。自注意力机制依赖更少的参数,仅需关联单个序列的不同位置以计算序列的表示,更容易获取文本内部依赖关系,使模型能够更好地学习文本特征[9]。赵勤鲁等[10]使用LSTM-Attention网络模型实现文本特征提取。LSTM提取词语与词语以及句子与句子的特征信息,分层注意力机制关注重要的词语和句子,有效提取文本特征,准确率得到了一定的提升。田生伟等[11]采用注意力机制和双向长短时记忆(bidirectional long short-term memory,BLSTM)结合的方法对维吾尔语事件时序关系进行识别,该方法可以同时获取事件隐含语义信息和事件语义特征,融合事件内部结构特征后,实验证明了该方法在维吾尔语事件时序关系识别任务上的有效性。黄兆玮等[12]结合GRU和注意力机制进行远程监督关系抽取,采用GRU神经网络提取文本特征,然后在实体对上构建句子级的注意力机制,准确率、召回率和PR曲线都取得了比较显著的进步。王伟等[13]提出基于BGRU-Attention文本情感分类模型,先使用BGRU提取文本深层次信息的特征;再使用注意力机制分配相应的权重;最后进行情感分类,也验证了所提模型的有效性。吴小华等[14]提出使用自注意力机制和BLSTM对中文短文本进行情感分析。首先,对文本进行字向量化表示,采用BLSTM提取文本上下文语义特征信息,再通过自注意力机制动态调整特征权重,由softmax分类器得到情感类别。由于BLSTM结构较为复杂,导致模型的训练时间较长、参数较多等问题,因此本文将文本用Global Vector(GloVe)向量化,提出基于BGRU和自注意力机制的情感分析模型,实验结果证明了该方法的有效性。
1 基于BGRU和自注意力机制的情感分析模型
对于短文本t=(w1,w2,…,wn),其中wi为文本中的第i个字,短文本的情感分析实际上就是对短文本t进行特征的提取并对其进行分析,最终确定其所属的情感类别。一般情况下中性的情感意义并不大,所以本文主要把情感分为两个极性,即正向情感和负向情感,也称积极情感和消极情感。基于BGRU和自注意力机制的情感分析模型包括词向量输入层、双向门控循环网络层、自注意力层、sigmoid层,模型结构如图1所示。

图1基于BGRU和自注意力机制的情感分析模型结构Fig.1 Sentiment analysis model structure based on BGRU and self-attention mechanism
1.1 词向量输入层
利用深度学习方法进行文本分类的情感分析首先需要将文本进行向量化,即把文本用词向量的形式进行表示。常用的文本向量表示方法主要有基于向量空间模型、one-hot模型和Word2Vec模型。向量空间模型中词向量维度与词典中词的个数呈线性相关,如果词典中词数不断增多则会引起维度灾难;one-hot的向量表示很简单但忽略了词与词语义的相关性;Word2Vec模型中包括两种构建词向量的方法,都是基于局部上下文信息的方法,分别为CBOW和Skip-Gram。Global Vector融合了矩阵分解的全局统计信息和局部上下文信息的优势,不仅可以加快模型的训练速度,而且还可以控制词的相对权重。因此,本文使用Global Vector词向量训练方法。
1.2 双向门控循环网络层
标准的循环神经网络在处理文本时,只能向前传播获取当前文本的上文信息,没有考虑到下文信息对当前预测结果的影响。Schuster等[15]提出双向循环神经网络(bidrectional recurrent neural networks,BRNN)模型解决循环神经网络未考虑到下文信息对当前预测结果的影响,使用正反两个方向的RNN处理正反向的序列,最后将二者的输出连接到同一个输出层,在获取文本上文信息的同时获取文本的下文信息。将BRNN中的隐含层神经元换成GRU记忆神经单元,即可得到双向门控循环神经网络。给定一个n维输入(x1,x2,…,xn),其中xt(t=1,2,…,n)是词向量。在t时刻:BGRU的输出由两个相反方向的GRU共同组合决定。具体的计算公式如下:

1.3 自注意力层
注意力机制可以得到稀疏数据中的重要特征,其本质是一个query(Q)到一系列(key(K)-value(V))键值对的映射,首先将query和每个key通过点积、拼接或感知器等相似度函数计算得到权重;其次通过softmax函数对计算得出的权重进行归一化处理;最后将权重和与之相对应的value加权求和得出最后的Attention。当K=V=Q时,即自注意力机制,处理文本时会直接将一个句子中任意两个单词的联系通过一个计算步骤直接联系起来,获取句子内部的词依赖关系、句子的内部结构以及同一个句子中单词之间的一些句法特征或者语义特征,更有利于有效地获取远距离相互依赖的特征。除此之外,自注意力机制还可以增加计算的并行性。计算公式如下所示:
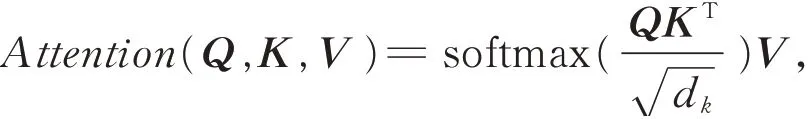
其中Q∈Rn是BGRU的n维输出向量是调节因子,一般为词向量的维度,主要避免因QKT内积结果过大导致softmax不是1就是0的情况。
1.4 模型训练
本文训练BGRU和自注意力的情感分析模型中的参数包括双向门限循环神经网络和自注意力机制中的全部参数。本模型使用的优化器是Adam,因为Adam优化器结合了RMSProp和AdaGrad二者的优点,还可以计算参数的自适应学习率。为了防止在训练过程中过拟合,在BGRU神经网络之后加入Dropout函数,通过在每一次的迭代中随机丢弃部分训练参数来提高模型的泛化能力。本模型使用Sigmoid函数进行分类:

其中j表示类别,文中主要分为积极和消极,取值是1或者0。θ为本文模型中的任意参数。训练模型的参数θ使用的损失函数是交叉熵损失函数。本文总样本为(X,Y)=((x1,y1),(x2,y2),…,(xi,yt),…,(xN,yN)),X为评论文本,Y为评论文本真实的标签,取值是0或者1。交叉熵损失函数的计算公式如下:

其中xi为评论文本,yt为评论文本的真实标签,yp为该评论文本属于积极类别的概率,N为样本总数。
2 实验过程
本文的实验在公开带有情感标签的电影评论IMDB数据集上,对本文提出的情感模型进行验证和分析。实验环境具体配置如表1所示。

表1实验环境配置Tab.1 Configuration of the experimental environment
2.1 实验数据
实验的数据主要来自于电影评论IMDB数据集,电影情感评论的标签主要分为两种0或者1,如果情感评论是积极的标记为1,情感评论是消极的标记为0。数据集的划分情况如表2所示。

表2数据集Tab.2 Data set
2.2 实验参数设置
实验参数的设置直接影响模型的分类效果,但实验中又有很多的超参数需要设置与调整,实验在每一次迭代完成之后,会根据准确率和损失率对所设置的超参数进行调整,经过多次实验以及多次迭代具体的参数设置见表3。

表3参数设置Tab.3 Parameter settings
2.3 实验评价标准
评价是实验中一个重要的环节,可以直接反映出模型的好坏,本实验在电影评论情感分析的样本上采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Measure作为评价情感分析结果好坏的标准。准确率评估的是对模型正确分类的能力;精确率评估的是查准率;召回率评估的是查全率;F1-Measure是综合评价指标。

其中TP表示积极分类预测为积极分类数;FN表示积极分类预测为消极分类数;FP表示消极分类预测为积极分类数;TN表示消极分类预测为消极分类数。
2.4 词向量维度的选择
词向量能够有效地反映词与词之间的关联度以及语义信息,理论上来说词向量维度越大越好,但实际应用中需要考虑实验的整体性能和整体代价,从而选出最合适的词向量维度。表4为不同词向量维度的模型实验结果,由表4可知,当词向量维度为50时,模型的整体性能最差,主要是因为词向量维度过小,使得词中包含的上下文相互影响的语义信息较少;当词向量维度为200时,模型的整体性能最好,训练的时间相对较小,主要是因为词中上下文的关联度比较大,包含更丰富的文本语义信息。因此本模型把词向量的维度设置成200。

表4不同词向量维度的模型实验结果Tab.4 Experimental results of models with different words vector dimensions
2.5 BGRU隐藏层节点数的选择
表5为不同节点数的模型实验结果,由表5可知,当BGRU隐含层节点数为50时,模型的准确率和F1-Measure最低,因为节点数过少不能够完全提取语义信息;当节点数由50增加到100时,模型的准确率和F1-Measure达到最大;随着节点数的继续增加,准确率和F1-Measure都呈现下降的趋势,说明当节点数不断增加时,模型的整体性能越来越差。所以,本实验中BGRU隐含层节点数选择为100。

表5不同节点数的模型实验结果Tab.5 Experimental results of models with different number of nodes
2.6 Dropout值的选择
Dropout主要是为了解决训练过程中产生的过拟合现象。在神经网络训练过程中以特定概率值随机丢弃一定数量的神经元,只让部分神经元参与模型的训练和参数的学习,保证模型在训练学习参数的过程中无法过度依赖于某些局部特征,能够提升模型的训练效率和泛化能力,不同Dropout值的模型实验结果如表6所示。当Dropout取值为0.5时,模型的准确率最高,整体性能最好。

表6不同Dropout值的模型实验结果Tab.6 Experimental results of models with different Dropout values
2.7 对比实验设置
本实验模型与以下几种常见模型进行对比分析。为了使对比的结果更具有可比性和准确性,所有模型词向量的输入都是GloVe200维,每个对比模型中的参数值选取都一样。
1)LSTM:LSTM在循环神经网络的基础上加入了门限控制。本文对比实验使用的是Zaremba等[16]描述的网络结构作为标准模型,并设置LSTM隐含层节点数为100。
2)BLSTM:采用Zaremba等[16]描述的LSTM网络来构建BLSTM网络模型,可以同时考虑上下文信息。本文设置BLSTM隐含层节点数为100。
3)BGRU:BGRU在BLSTM基础上减少“门”的数量,使结构更加简单。其中本文设置BGRU隐含层节点数为100。
4)Self-Attention:此模型只包含自注意力机制。
5)BGRU+Self-Attention:此模型主要将双向门限循环网络和自注意力机制并联对文本进行情感分析,其中设置BGRU隐含层节点数为100。
6)BGRU-Self-Attention:文本提出的将双向门限循环网络和自注意力机制以链式方式结合对文本进行情感分析,其中设置BGRU隐含层节点数为100。
3 实验结果
3.1 6种模型的评价指标
实验在测试集上计算出准确率、精确率、召回率和F1-Measure,具体模型实验结果见表7。

表7 6种模型的实验结果Tab.7 Experimental results of six models
由表7可知,本文提出的BGRU-Self-Attention模型的Accuracy、Precision、Recall和F1-Measure这4个评价指标分别为91.23%、91.21%、91.24%和91.23%,其中Accuracy和F1-Measure均优于其他的5种模型。通过LSTM和BLSTM对比的实验结果可知,在LSTM基础上增加了向后传播单元的BLSTM可以同时考虑上下文信息,因此得到的情感极性的分类更准确;通过对比BLSTM和BGRU的实验结果可知,减少了“门”数量的BGRU,使得模型结构相对简单,减少了训练的参数,分类的准确率也得到了一定的提升;通过对比BGRU+Self-Attention和BGRU-Self-Attention的结果可知,将BGRU和Self-Attention以并行的方式进行融合的结果要远远低于将BGRU和Self-Attention以链式方式进行融合,主要可能是因为分别利用BGRU和Self-Attention对文本上下文语义信息的获取和关注文本中词的重要程度,再将二者的特征进行融合,降低了文本中词与词之间的相似度,然而链式的融合方法是首先利用BGRU提取文本的上下文信息,对提取得到的信息再通过自注意力机制动态调整特征的权重,有利于模型快速抓住最重要的特征。通过对比BGRU+Self-Attention、BGRU-Self-Attention和任意的单个LSTM、BLSTM、BGRU和Self-Attention模型的结果可知,两种模型的组合在情感分析的任务中要比单个LSTM、BLSTM、BGRU和Self-Attention模型效果好,其原因在于组合模型利用双向循环神经网络提取序列化特征上下文的学习能力,自注意力机制动态调整特征的权重,更容易捕获句子中长距离的相互依赖的特征。
3.2 6种模型准确率与迭代次数的关系
选择IMDB数据集,参数设置参考表3(其中词向量维度为200,BGRU隐藏层节点数为100,Dropout值为0.5),6种模型准确率随迭代次数的变化见图2,由图2可知,随着迭代次数的增加,各个模型的准确率大体都在逐渐增加。除Self-Attention模型外,在第二次迭代时所有模型的准确率都达到86%以上。本文模型的曲线相对于其他5条曲线变化比较平稳、波动较小,验证集准确率的值处于较高的位置,尤其在第7次迭代后达到93%以上,说明本文模型在提取文本特征情感分析任务中表现更稳定。

图2 6种模型验证集准确率与迭代次数的关系Fig.2 Relationship of accuracy and iteration number of verification set for six models
3.3 6种模型损失率与迭代次数的关系
选择IMDB数据集,参数设置参考表3(其中词向量维度为200,BGRU隐藏层节点数为100,Dropout值为0.5),6种模型损失率随迭代次数的变化见图3,由图3可知,Self-Attention模型相对于其他的5种模型损失率变化波动最大而且极其不稳定;而本文所使用的模型损失率下降速度较快且很快到达了一个相对较低的稳定值,说明本文设计的模型取得了较好的收敛效果。

图3 6种模型验证集损失率与迭代次数的关系Fig.3 Relationship of loss rate and iteration number of verification set for six models
3.4 6种模型迭代时间与迭代次数的关系
迭代时间指的是完成一次实验所需要的时间。图4为迭代时间随迭代次数的变化曲线。总体来看各个模型的迭代时间没有很大的波动,整体时间呈平稳趋势。Self-Attentin模型和LSTM模型的迭代时间最短,主要原因是自注意力处理句子中的每个词时会和该句子中的所有词进行注意力计算,因此增加了计算的并行性。LSTM只提取一个方向的语义信息;BGRU是BLSTM的一种改进,减少“门”的数量,并把细胞状态和隐藏状态结合在一起,因此结构更加简单,训练参数减少,因此训练的时间也降低很多;本文提出模型的迭代时间高于BGRU和Self-Attention,因为BGRU会提取文本的上下文语义信息,之后再将提取得到的信息用自注意力获取远距离相互依赖的特征,训练时间肯定比单个模型训练时间长。

图4 6种模型迭代时间与迭代次数的关系Fig.4 Relationship of iteration time and iteration number for six models
4 结语
本文提出一种基于BGRU和自注意力机制的情感分析方法,该方法首先用GloVe将文本转换为词向量,即对文本进行向量化表示之后通过双向门限循环网络获取上下文的语义特征信息,然后引入自注意力机制对提取得到的特征进行重要程度动态调整,从而提高模型对文本类别的分类能力,在IMDB数据集上实验证明了基于BGRU和自注意力机制算法在文本情感分类方面的有效性。尽管本模型在IMDB数据集上的准确率、综合评价指标较高,损失率较低,但是如果数据集的数量比较大,准确率和综合评价指标可能会有所下降,同时训练的时间有所增加,且GRU等序列模型属于递归模型,并行能力相对较弱,后续研究将就这两方面做出改进。
