基于RF-CPSO-LSSVM 的日线损率置信区间预测研究
2020-08-08
(国网浙江海宁市供电有限公司,浙江 海宁 314400)
0 引言
低压配电网线损是国家电网有限公司经济效益考核的重要指标。电网线损的计算通常由两部分组成,一部分是理论线损;另一部分是管理线损[1-3]。其中理论线损指的是电力在输送过程中,由电力设备造成的电力损失,也称为技术线损;管理线损指的是在技术层面之外的电力损失,包括设备故障、采集故障、窃电等造成的电力损失。因此,对理论线损的研究能够反映电力网的真实线损水平,为电力企业的线损治理工作提供理论支撑。
理论线损的计算通常需要综合考虑负荷情况、运行方式和拓扑情况等数据,对电网的数据基础要求高。传统的计算方法有潮流算法、积分电流法和等值电阻法[4-5],这些算法能够精确计算电力网的电力损失。
然而,在实际的生产环境中,数据缺失较为严重,因此有学者提出了基于统计学的计算方法,如使用回归算法、聚类算法、神经网络算法和支持向量机[6-8]等。文献[9]针对10 kV 配电网理论线损预测提出了一种基于PSO(粒子群算法)优化BPNN(BP 神经网络)的方法,全局搜索BP 神经网络的权值和阈值来构建PSO-BPNN 线损评估模型,进而对测试样本集线损进行预测;文献[10]提出一种基于FOA-SVR(系统聚类和果蝇优化支持向量回归机)的配电网理论线损计算方法,将样本数据聚类分成相似的群组,主要使用果蝇优化算法,训练寻找最优的计算参数,以得到最优结果。虽然上述算法能准确地估计台区的线损,但是均需要几个月的长期数据,对于长期数据缺失严重的部分台区则不适用[11-13]。
本文分析了国内外理论线损率预测目前的研究现状,在此基础上,运用RF 算法对造成理论线损的特征进行筛选,采用CPSO(混沌粒子群)算法对LSSVM(最小二乘支持向量机)算法的惩罚因子C,g 进行参数寻优,得到不确定性理论线损预测模型。通过计算求得理论线损率的置信区间概率预测。
1 随机森林特征选择
使用RF(随机森林)算法进行特征选择时,当一个影响预测准确率的重要特征加入噪声后,RF的分类准确率将显著降低。在筛选预测模型时,应用该方法寻找的输入向量中,使用MDG(平均基尼指数下降)来评价变量重要性,计算公式如下:

式中:n 为树个数;err00B 为带外数据的误差;t为节点数;p(k/t)为节点t 中目标变量为第k 个的概率。根据式(2)计算每棵树的GI 值,平均所有树的结果得到MDG 值。
本文则采用MDG 作为特征重要性指标,对于模型来说该数值越大,则该特征重要性越高;反之则越低。将特征重要性进行倒序排序,再选取排名较高的特征作为特征选择入模。
2 CPSO-LSSVM 预测算法优化
2.1 LSSVM 算法
使用LSSVM 模型最小二乘线性函数作为损失函数,在特定的非线性映射空间中构造最优决策函数,具体实现如下。
给定集合{(xi,yi),i=1,2,…,m},其中,xi(xi∈Rd)为第i 个训练样本的输入向量;为对应输出值。在高维特征中建立线性回归函数:

式中:φ(x)为非线性映射函数;w为权值向量;b为偏置。
利用结构风险最小化原则,选择损失函数为误差的二次项,LSSVM 问题可表示为:

式中:C 为惩罚因子;ei为误差变量;ξ 为松弛变量。式(4)、式(5)引入lagrange 乘子αi,得:

随后利用最小二乘法求解回归系数α 和偏置b,从而得到LSSVM 预测函数:

虽然最小二乘法能构造最优决策函数,但是该算法依旧存在2 个超参数C 和g 待优化,C 越大,经验风险越小,结构风险越大,容易出现过拟合;C 越小,模型复杂度越低,容易出现欠拟合;g 越大,支持向量越少;g 值越小,支持向量越多。因此,需要用CPSO 算法对这2 个参数进行寻优。
2.2 CPSO 参数优化
利用CPSO 优化算法选择粒子提升种群收敛速度,避免局部最优早熟,提高全局搜索能力[14-15]。
混沌粒子产生在待优化C 和g 的约束范围内。在训练集样本中使用交叉验证方法训练LSSVM模型,训练集的另一部分样本用于测试模型精度。通过测试交叉验证误差得到粒子适应度函数,并使用混沌粒子群搜索参数约束范围内的最佳粒子,再确定LSSVM 的回归模型。
CPSO-LSSVM 预测算法优化步骤如下:
(1)将样本集分为k 个互不相交的子集,每个子集的代销大致相等。
(2)混沌初始化。利用Logistic 迭代公式得到混沌粒子,将混沌粒子zi的各个分量载波到优化变量的取值范围。
(3)计算各个粒子的适应度值。
(4)从初始群体中选择性能较好的解作为初始解,随机产生初始速度。
(5)更新粒子速度,采用自适应调整的策略,随着迭代的进行,线性减少w的数值。
(6)产生混沌扰动u1=(u11,u12,u1n),u1j=4(1-u0),j=1,2,…,n,将u1各个分量载波到混沌扰动范围[-β,β]内,扰动量Δx=(Δx1,Δx2,Δxn),Δxj=-β+2βu1j。
(7)更新粒子位置,更新公式为:

(8)计算第i 个粒子的适应度fi,若粒子的适应度优于原来的最优位置的适应度,设置当前适应度为最优位置的适应度pbestfi,设置当前位置为最优值pBestk。
(9)是否达到最大迭代次数,如果是则继续步骤(11);反之,重复步骤(8),(9)。
(10)根据各个粒子最优位置的最优值pBestk,从而找出全局最优位置的适应度pBestfk和全局最优位置的位置gBestk。
(11)输出全局最优位置的适应度和全局最优位置gBestk。
通过上述算法步骤,则可得到最优的LSSVM模型的2 个超参数C 和g,从而得到最优的回归模型。
3 基于RF-CPSO-LSSVM 的日线损率置信区间预测算法
基于RF-CPSO-LSSVM 的日线损率置信区间预测一共包括7 个流程,分别是数据清洗、数据归一化、RF 算法特征选择、CPSO-LSSVM 模型训练、日线损率预测、设置置信度及置信区间和日线损率区间估计,算法流程如图1 所示。

图1 RF-CPSO-LSSVM 日线损率置信区间预测算法流程
3.1 数据预处理
3.1.1 数据清洗
数据清洗包括数据去重、异常值剔除和缺失值填充3 个步骤。数据去重是为了保证样本的单一性,防止重复样本造成模型干扰;异常值剔除是为了防止极端数据产生数据倾斜,干扰模型的鲁棒性;缺失值填充是为了防止样本的浪费,因此对缺失值进行填充,以提升模型的泛化能力。
3.1.2 数据归一化
由于原始数据的各维度之间的量纲不同,未经过预处理的数据直接进入模型会增加模型的扰动性,因此需要对数据进行归一化处理:

式中:i 为样本集中第i 个样本;j 为样本集中第j个维度;xi,j为归一化前的第i 个样本的第j 维数据的数值;xmin,j为归一化前第j 维数据的最小值;xmax,j为归一化前第j 维数据的最大值;为归一化后的第i 个样本的第j 维数据的数值。
3.2 RF 算法特征选择
设配电网中有n 个节点,q 个电源点(负荷等效为负电源),节点电压方程为:

式中:U 为配电网中各节点的电压;I 为各电源节点的电流;Z为网络中节点的阻抗矩阵。若配电网支路l 的首末节点为i 和j,线路导纳为yij,则支路l 的损耗功率为:

由式(11)可知,线路的损耗与网架的整体拓扑结构和每个电源点的功率有关。因此,综合节点注入的电能Cs=(c1s,c2s,…,cqs)与拓扑参数特征向量Cl=(cy1,cy2,…,cyl0)共同组成的特征向量为CB=(c1s,c2s,…,cqs,cy1,cy2,…,cyl0)。对于存在数据缺失的情况,建立采集向量A=(a1,a2,…,cn),A为0、1 离散向量,其中0 代表采集失败;1 代表采集成功。欧氏距离是常用的相似度度量指标,则第i 天和第j 天的距离计算公式为:

式中:Ai和CBi分别为第i 天的采集向量和特征向量;Aj和CBj分别为第j 天的采集向量和特征向量;Aij为第i 天和第j 天的采集向量交集;⊙运算为2 个向量逐个元素相乘,其运算过程为:

利用配电网的拓扑数据和节点注入电能数据共同构成特征向量,并且考虑到采集缺失的情况,构建了采集向量,综合计算求取2 天特征向量的欧式距离(距离值越小,则表明这2 天配电网的用电行为特征越相近)。
随后,通过RF 算法对特征的重要性进行倒序排序,并计算特征的累计贡献率:
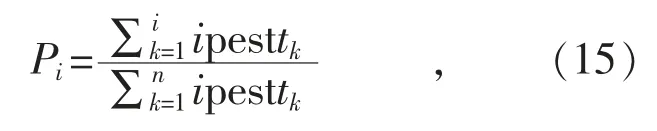
式中:n 为特征总数;Pi为前i 个特征的累计贡献率;ipesttk为第k 个特征的特征重要性数值;为前i 个特征的特征重要性总和;ipesttk为n 个特征的特征重要性总和。
为了保证模型的稳定性和鲁棒性,选取累计贡献率大于95%的特征入模。
3.3 CPSO-LSSVM 回归模型
设置CPSO 寻优算法的参数,包括迭代次数、种群规模、惯性权重、飞行速度上下限和混沌扰动范围。
在评价某一参数组[C,g]的LSSVM 模型时,选用RMSE(均方根误差)作为目标函数,该数值越小,回归效果越好;反之,则回归效果越差,即模型越差。RMSE 计算公式为:

式中:yi为第i 个样本的真实标签;为第i 个样本的预测标签。
通过算法迭代,输出最佳参数组[CBest,gBest]所对应的模型。
3.4 日线损率置信区间估计
在获得最佳模型后,对当天所有的台区进行预测线损率,并设置数据置信度为μ,可以求得置信区间为[σmaxmin,σmaxmax]。置信区间的区域划分如图2 所示。
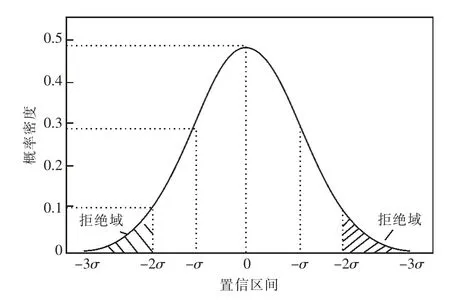
图2 置信区间的区域划分
表1 列出了3 个典型置信度下的误差范围。

表1 3 个典型置信度下的误差范围
由表1 可知,置信度越小,则误差范围越小,即预测区间越精确;反之,则预测区间的误差越大,结果误差越大。
4 案例分析
当前大部分台区的拓扑数据缺失,因此无法使用传统的算法进行理论线损计算,但是负荷数据和档案数据保存较好,如浙江省某地级市下属台区负荷数据的缺失率2.3%、采集成功率99%,理论线损在近一年内皆小于7%。选取现场作业人员人工核查数据质量较好且长期线损稳定的浙江省某地级市162 个台区进行建模。随机选取时间尺度为2019 年11 月1 日—2019 年12 月1 日。根据文献[11]研究得出样本的特征维度日供电量、日用电量、变压器总容量、平均负载率、平均电流不平衡度、变压器的TA 变比和平均功率因数共7 个维度对理论线损影响较大,所以本文也采用这7 个特征维度,将2019 年11 月1 日—2019 年11 月30 日的数据作为训练集,2019 年12 月共计30 天的数据作为测试集。
4.1 数据预处理
首先,进行数据去重,将原始样本量从3 316条降为3 100 条;其次,对数据进行归一化;最后,将2019 年11 月1—30 日的数据作为训练集,2019 年12 月共计30 天的数据作为预测集。
4.2 RF 算法特征选择
4.2.1 RF 超参数设置
先设置RF 算法的超参数,具体设置如表2所示。

表2 RF 算法超参数设置
表2 中,n_estimators 为树的棵树,设置为100;max_depth 为树的深度,设置为5;min_sam ple_leaf 为叶子节点所需的最小样本数,设置为31;criterion 为评价标准,设置为‘gini’。
4.2.2 累计贡献率曲线
用RF 算法对特征进行筛选,在完成特征重要性的倒序排序后,计算特征的累计贡献率,并绘制累计贡献率曲线,如图3 所示。
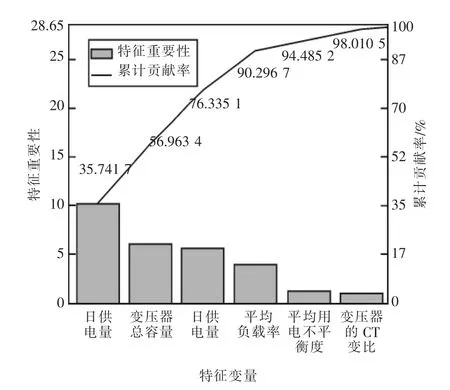
图3 累计贡献率曲线
由图3 可知,当使用日供电量、变压器总容量、日用电量和平均负载率这4 个变量时,累计贡献率达到90.296 7%,因此本文选择这4 个变量作为模型的特征。
4.3 CPSO-LSSVM 预测及结果分析
4.3.1 CPSO 优化算法参数设置
设置CPSO 优化算法的主要参数,各参数的具体数值如表3 所示。

表3 CPSO 优化算法主要参数设置
4.3.2 模型效果分析
在经过300 次迭代后,得到最优LSSVM 模型,且惩罚因子C=3.64,惩罚因子g=0.78。
本文选取LSSVM,PSO-LSSVM 和APSOLSSVM 作为对比算法,并且评价指标选取MSE(均方误差)、RMSE 和MAPE(平均绝对误差百分比)对本文算法的准确性进行验证,各算法的预测曲线如图4 所示。

图4 各算法预测曲线对比
由图4 可知,各算法预测结果较为精确,偏差较小。各算法的MSE,RMSE 和MAPE 的结果如表4 所示。

表4 算法效果对比
由表4 可知,本文算法的MSE 为0.052 6,RMSE 为0.066 5,MAPE 为0.124 2;3 项指标皆小于其他3 个算法,因此基于RF-CPSO-LSSVM的日线损率置信区间预测的改进效果明显。
4.4 理论线损率置信区间估计
绘制置信度在60%~99%之间的理论线损率的置信区间预测,如图5 所示。

图5 各置信度下的理论线损率置信区间预测
由图5 可知,当置信度为99%时,100 个样本中有97 个处于置信区间内;当置信度为95%时,则有99 个样本处于置信区间内;当置信度大于90%时,则全部样本均在置信区间内。因此,在90%的置信度下的模型能够较好地预测次日理论线损率的置信区间。
5 结语
针对当前台区拓扑数据不全所造成的传统理论线损计算方法不适用的现状,本文采用RF 算法对特征的重要性进行排序,并计算各特征的累计贡献率对特征进行筛选;利用CPSO 算法对LSSVM 算法的惩罚因子C,g 进行参数寻优以获得最佳预测模型;选取95%置信度下的理论线损置信区间作为预测结果,为理论线损率的预测提供一种新方法。
