基于聚类再回归方法的光伏发电量短期预测
2020-08-08
(国网浙江省电力有限公司嘉兴供电公司,浙江 嘉兴 314000)
0 引言
随着光伏发电的应用推广,大规模分布式光伏接入对电网的冲击越来越不容忽视,所以对地区光伏出力的统计与预测显得尤为重要。由于受辐照强度、光伏组件温度、天气类型等随机因素的影响,光伏发电量和输出功率的变化随机性、波动性大[1]。对此,基于机器学习分析地区光伏电站历史数据(发电量、环境温度、太阳辐射量等)之间的相关性,建立模型预测该地区的光伏发电量,既有利于制定短期内的用电分配计划,又能为电网长期安全稳定运行提供数据依据。
机器学习在光伏发电量预测的应用已有不少研究成果,从预测模型类型上可分为单一模型和组合模型。文献[1]应用灰色理论建立单一模型,重点关注对光伏系统出力的拟合,省去多种非主导的影响因素,计算得到简化。神经网络在随机非线性问题的处理上较有优势,但自身收敛速度较慢,容易陷于局部极值。文献[7]建立了灰色神经网络组合模型,相比于灰色理论或神经网络的单一模型,该组合模型在相对偏差较大的数值预测上表现得更为准确。总体上,使用单一模型[3-6]时,步骤较少,方法较易于实现,但是其预测效果相对较差;使用组合模型[7-10]时,其结果有较高的可信度,但是建模过程复杂,输入因子繁多,不便于投入实际应用中。
基于上述研究,本文提出的预测模型设计要求为:在保证较高预测精度的前提下,预测方法应简单可行,输入因子易于获得,能较好应对天气变化的影响。为此,以嘉兴地区为例,对电量数据及气象数据进行分析,从中找出内在规律,发现最为相关的因素作为输入因子,建立光伏发电量预测模型。
本文使用SPSS 进行光伏发电量与不同气象因子间的相关性分析,选用Python 的statsmodels,scikit-learn,matplotlib 等进行线性回归分析及数据可视化处理,进而从一些评价指标或输出图表中清晰直观地看到变量之间的关系,综合得出确切的结论,再依据此结论建立光伏发电量预测模型。
1 逐日光伏发电量分析与预测
1.1 相关性分析
影响光伏发电系统输出的影响因素主要可分为两类:一类是光伏发电系统的自身特性(如光伏电站所在位置、光伏组件安装角度、光伏电池转换效率等);另一类是外部气象因素(如天气类型、辐照强度、日照时长、气温等)[11]。在众多因素并存的情况下,确定对光伏发电量影响程度最大的因素十分关键。对于一个已建成并投入运行的光伏发电电站来说,其光伏组件安装角度及组合形式、光伏电池面积及转换效率等光伏发电系统自身特性产生的影响基本保持不变,故可不加以考虑。
选择Pearson 相关系数,用以分析两个连续性变量之间的相关性,其计算公式如式(1)所示:

式中:X 和Y 为2 个连续性变量;rxy为X 和Y 的Pearson 相关系数。
Pearson 相关系数实质上就是X 和Y 两组数的协方差除以X 的标准差和Y 的标准差,其取值范围为[-1,1]。若Pearson 相关系数rxy>0,则两个变量正相关;若rxy<0,则两个变量负相关。且rxy的绝对值越大,这2 个变量的线性相关程度越大,判断标准如表1 所示。

表1 Pearson 相关系数rxy 的判断标准
应用式(1),将浙江嘉兴某光伏电站一年的日均发电量与日均辐照强度数据导入SPSS,选取Pearson 相关性分析,得到Pearson 相关系数rxy。由表2 可知,各季度发电量与辐照强度的Pearson 相关系数rxy均大于0.9,说明光伏发电量与辐照强度之间呈高度线性正相关。

表2 发电量与辐照强度间Pearson 相关性分析
再对日均发电量与日均气温分析,由表3 可知,其Pearson 相关系数rxy在各季度均小于0.8,且在冬季出现负相关,说明光伏发电量与日均气温的相关性总体较低。

表3 发电量与气温间Pearson 相关性分析
1.2 回归分析
回归在机器学习中属于监督学习的范畴。回归的目的是根据输入的n 维连续性变量x 求出回归方程,进而预测出目标变量y 的数值,由此也可以把回归看作是将实函数在样本点附近加以近似的有监督的函数近似问题[12]。多元线性回归模型的一般形式为:

式中:j 为解释变量的数目;βj为回归系数;Xj为变量。
回归模型最常用的是普通最小二乘法,其原则是使所有观察值的残差平方和达到最小。最小二乘法计算较简便,但对异常值十分敏感。使用交叉验证法,取样本中一部分用于学习,剩余部分用于测试验证,可以对模型的泛化误差较为准确评估[12]。划分训练集与测试集时,要求训练集占样本总集比例大于50%。
为比较选用不同季度的数据库训练逐日光伏发电量预测模型的预测效果,对浙江嘉兴某并网电压为380 V 和装机容量为100 kW 的光伏电站建立各季度的一元线性回归模型和二元线性回归模型,并计算均方根误差。
在剔除异常值后,引用交叉验证将处理后数据按3:1 的比例随机划分,分别用于学习和测验。取随机数种子为1,所得均方根误差如表4所示,其中,因变量Y 为逐日光伏发电量;自变量X1为日均辐照强度;自变量X2为日均气温。
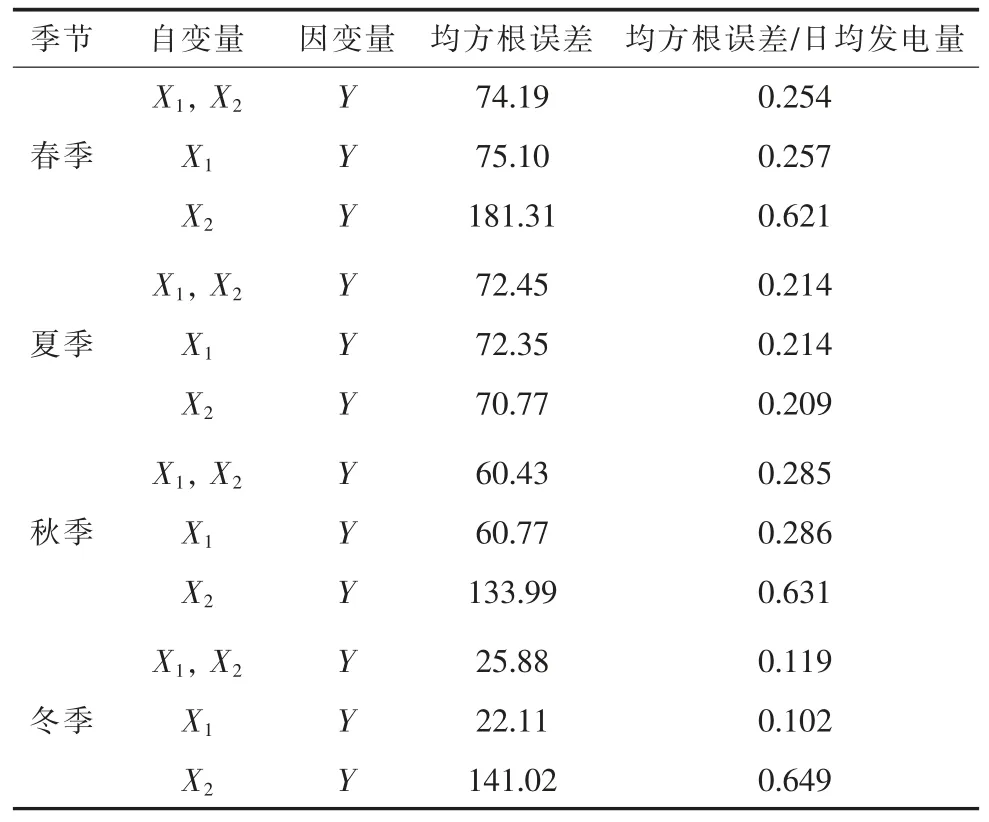
表4 各季节光伏发电量回归分析
由表4 可知,对同一站点,冬季的预测误差最小,其次是夏季,春秋季的预测误差最大,其原因是春秋季的天气在一天之内变化较大,导致光伏发电量波动较大,与气象因素之间的关系较难用线性描绘;而冬季天气相对稳定,一天之内天气类型变化多次的情况较少,最适于采用线性回归预测。
移除气温特征,仅关于辐照强度作一元线性回归得到的均方根误差,与关于气温和辐照强度作二元线性回归得到的均方根误差数值相近,而仅关于气温作一元线性回归则使得均方根误差数值显著增大,说明在建立逐日光伏发电量预测模型时可去除日均气温,仅取日均辐照强度作为输入,使该模型在保证预测精度的前提下更加简化。
对比并网电压为10 kV 和装机容量为2 009 kW 的其他光伏电站分析结果,发现变化规律一致,说明处于同一地区的光伏电站具有相近的光伏发电特性,设计的预测模型可适用于同一地区所有光伏电站。
1.3 逐日光伏发电量预测模型
设计输入为预测日当日平均辐照强度、输出为预测日光伏发电量预测值的线性回归模型。图1 为逐日光伏发电量预测模型的框架。在输入历史数据之后,按季节进行分类,再把每种类的数据分别进行回归获得各季子模型,合并子模型即得到了完整一年光伏发电量预测模型。

图1 逐日光伏发电量预测框架
由此,预测光伏发电量的工作重心可主要放在预测日辐照强度的数值获取上。然而,由于我国大部分地区(包括浙江嘉兴)的气象站对于太阳辐射的观测起步较晚,观测数据积累不足,尚不具备预测太阳辐照强度的能力,所以在天气预报中无法获得辐照强度数值。
基于以上原因,多数地区要实现对逐日光伏发电量的预测,需依靠现有的天气预报信息较为准确地预测出日均辐照强度,即分析辐照强度与其他气象因素之间的关系,并利用天气预报中已有的信息获得日均辐照强度预测值。
2 逐时辐照强度分析与预测
2.1 不同天气的气象数据分析
本文选取了晴天、多云、雨天这3 种天气类型的24 h 辐照强度进行描绘,如图2 所示,晴天的辐照强度基本呈正态分布;多云时天气变化难以揣测,辐照强度的变化波动较大;雨天的辐照强度曲线整体较平缓。可见辐照强度大小一定程度上取决于云量多少,无云时辐照强度更有规律,有云时辐照强度的随机性较强。
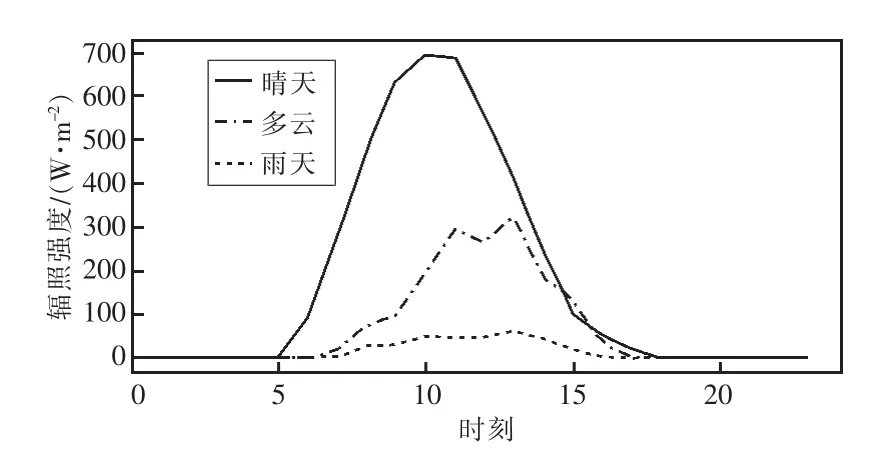
图2 不同天气下的辐照强度

图3 不同天气下的温度变化
图3 为与图2 对应的3 种天气类型的24 h温度变化,晴天的全日温度变化较大,一天中温度上升最快的时段与辐照强度最大值出现的时段基本吻合;多云天气的全日温度变化规律与晴天类似,但不如晴天的变化显著;雨天的温差在0值附近波动,说明一天之中的温度变化不大。
天气类型对辐照强度的大小及变化规律的影响十分显著,进而间接影响了光伏发电量的变化。不同天气类型下的温度变化规律也有较大差异,并且这种差异性可以与不同天气的辐照强度变化特征相匹配。
2.2 聚类分析
本文提出一种假设:室外气温变化与辐照强度之间具有密切关系,并且在不同天气类型下气温与太阳辐射的随动性关系具有不同特征,由此可利用聚类对气象数据进行天气类型的细分。通过K-means 算法对日类型划分,即可针对不同天气类型的样本各自搭建辐照强度预测的子模型。
聚类分析可以帮助研究者按照其选定的聚类簇数对样本进行分型,使得性质相似的样本尽可能聚在同一类别内,即实现了“物以类聚”。Kmeans 算法以欧氏距离作为相似性评价指标,是一种简单高效的经典聚类算法,欧氏距离的公式如下:

式中:xi和xj为两个样本;d(xi,xj)为xi和xj的欧氏距离。d(xi,xj)的值越小,说明样本xi和xj的相似度越高;d(xi,xj)的值越大,说明样本xi和xj的差异度越高。
K-means 聚类算法采用误差平方和准则函数作为评价聚类性能好坏的标准之一,确保了聚类结果的可靠有效,误差平方和准则函数公式如下:
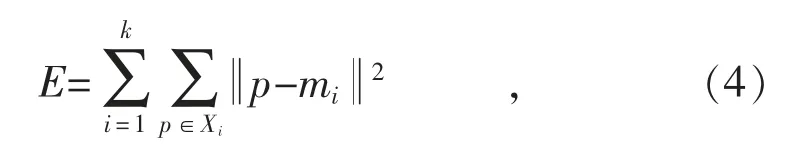
式中:k 为类别数;Xi为第i 类聚类中心域的样本集合;mi是第i 个聚类中心。
为了验证所提出的假设,这里采用K-means聚类算法对浙江嘉兴某月日照时段(7:00—16:00)的每时段辐照强度与温差的关系进行绘制并分析,聚类簇数k 指定由2 取到10 并运行多次输出聚类散点图。图4 为11 时取聚类簇数k 为4所绘出的聚类散点图,部分数据点标记了历史记录的当日天气类型。
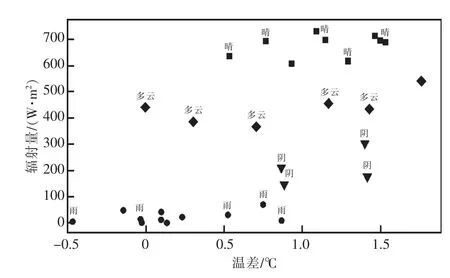
图4 不同时刻辐照强度与温差的关系
由聚类结果可以得出,通过K-means 聚类算法能够实现对气象数据细分为具有晴天特征、多云特征、阴天特征、雨(雪)天特征的4 个类型,再分别建立逐时辐照强度预测的子模型,从而完善了依据每日天气预报信息(天气类型、逐时气温、日照时间)来预测逐日光伏发电量的方案。
2.3 逐时辐照强度预测模型
依据聚类分析,可设计输入为预测日的日照时段的逐时温差预测值、输出为预测日的逐时辐照强度预测值的线性回归模型。图5 为逐时辐照强度预测模型的框架。首先用K-means 聚类算法对一个季度的每时段气象数据进行细分并加上标签A,B,C,D 分别对应雨(雪)天、阴天、多云、晴天,再对聚类分型后的样本训练得到4 个子模型,最后合并得到某一季度的逐时辐照强度预测模型。

图5 逐时辐照强度预测框架
3 基于天气预报的光伏发电量预测
3.1 基于天气预报的聚类再回归预测方案
在一定预测精度下,建立仅利用天气预报信息作为输入的光伏发电量预测模型,提出一种基于天气预报的聚类再回归预测方案,如图6 所示。

图6 光伏系统发电量短期预测整体方案流程
3.2 算例结果分析
为了验证上述基于天气预报的光伏发电量预测方案的可行性,本文以冬季为例,使用Python实现聚类算法对气象数据分型和回归模型的训练。逐日光伏发电量预测模型的训练集和测试集分别取浙江嘉兴某并网电压为380 V 和装机容量为100 kW 的光伏电站从2016 年12 月—2017 年2 月历史发电量数据、2015 年12 月—2016 年2月历史发电量数据以及对应的当地气象数据,逐时辐照强度预测模型的训练集和测试集也取同样的气象数据。在剔除出错的观测记录后,确定样本容量,其中训练集取73,测试集取40,满足训练集占样本总集比例大于50%的要求。
工程算例中增加无聚类识别天气类型的光伏发电量短期预测方案(方案2)与聚类再回归的光伏发电量短期预测方案(方案1)作为对比,用以分析天气类型分类对光伏发电短期预测的预测精度提升效果。
引入RMSE(均方根误差)和MAPE(平均绝对误差百分比)对预测方案进行性能评估。RMSE反映整个方案预测数值的离散情况,当RMSE 增大时,表示该方案的数值离散程度上升。MAPE则衡量整个方案的预测能力,其数值越大,说明预测值与实测值差别越大,即预测效果越差。误差指标的计算式如下:

式中:Gobs,i为光伏发电量实测值;Gpred,i为光伏发电量预测值;n 为测试集样本数。
预测结果见图7 和图8,可见方案1 的光伏发电量预测值明显比方案2 的预测值更加贴近实测值,且变化趋势也与实测值基本保持一致。方案1 的预测曲线成功显示了突变情况,而方案2的预测曲线显然无法适应大幅度的光伏发电量变化。

图7 聚类再回归的光伏发电量预测值对比实测值

图8 无聚类的光伏发电量预测值对比实测值
经计算,方案1 的RMSE 为40.6,MAPE 为51.3%;方 案2 的RMSE 为106.8,MAPE 为135.1%。可见利用K-means 聚类算法进行天气类型细分能够大幅度降低预测误差。算例结果表明,相比不使用聚类算法的预测方案,聚类再回归的光伏发电量预测的RMSE 降低了62%,MAPE降低到原值的38%,显著提升了预测精度。
3.3 方案评价及改进方向
鉴于线性回归模型对于随机性大的光伏出力适应性较差,后期改进中可尝试将方案中的预测模型用其他机器学习模型替代,比较不同模型的预测效果。在K-means 聚类算法部分,可考虑的改进方法有:引入肘部法则帮助确定最佳的聚类簇数k 值;更换聚类散点图的坐标变量,即尝试用太阳辐照强度与其他天气预报中的气象因子进行聚类;寻找更优性能的聚类算法取代K-means算法。另外,也可以适当增加输入量,观察预测结果的误差是否会进一步减小。
4 结论
本文所提出的基于天气预报的聚类再回归光伏发电量预测方案无需辐照强度作为输入,仅需要获取预测日的天气预报,易于实现,控制了预测成本。针对天气变化不规则性加剧导致光伏发电出力随机性加强、波动性增大的情况,采用K-means 聚类算法识别样本数据的天气特征并分类,大大提高了预测精度,进一步增强了预测模型在天气突变时对光伏发电量变化趋势的判断能力。
基于天气预报的聚类再回归光伏发电量预测方案可用于预测某一地区内并网的光伏电站总发电量,对于优化电力系统调度、提升电网安全稳定水平具有重要意义。
