基于HDFS+HBase+Redis 的海量车辆小图片的存储与检索系统设计
2020-08-07郭东新张伟荆忠航
郭东新,张伟,2,荆忠航
(1.北京信息科技大学计算机学院,北京100101;2.北京信息科技大学,北京材料基因工程高精尖创新中心,北京100101)
0 引言
目前,交通和公安等部门在存储和查询海量车辆小图片时,随着访问需求和车辆信息的快速增长,对效率的要求越来越高。同时,在大数据平台中存储小图片时,由于每张车辆图片的大小均小于HDFS 的数据块大小(默认为64MB),而且小图片的数据量为大文件的几十倍,导致NameNode 内存瓶颈、MapReduce 性能降低和高存储时间三个方面[1-4]的问题出现。
因此,研究如何优化车辆小图片的存储,可以提高小图片的存储和读取效率,有助于交通和公安等部对于海量小文件存储优化的方法,国内外学者已经开展了研究,并提出了一系列操作和方法,主要分为改进系统结构、小文件合并和针对特定场景的小文件合并三种方式。
ElKafrawy P M[5]提出了一种新的结构HDFSX,管理主存储器的元数据。当元数据量达到阈值时,将其余元数据存储在闪存上,从而解决主存储器上元数据的内存瓶颈问题。Bok K[6]提出了一种分布式缓存方案,使用客户端和数据节点缓存元数据,从而有效地提高HDFS 中小文件的访问性能。Fu S[7]提出了一个扁平的轻量级文件系统(iFlatLFS),设计一个简单的元数据方案和一个扁平的存储体系结构进行管理小文件,从而显著减少了元数据的数量。上述方法通过改变系统结构,可以有效地解决小文件问题,但是需要改变文件系统或者在现有文件系统上增加额外的缓存节点,增加了系统的建设成本和复杂性。
郑通[8]提出了小文件合并为大文件进行存储的方案,同时建立了文件预取机制来提高文件读取速度。程晗[9]通过Redis 设置三类队列合并智慧医疗小文件,同时通过改进的AHP 算法进行系统负载预测判断。Sheoran S[10]提出了将小文件合并成MapFile 进行存储的方案。Cheng W[11]提出了一种基于索引机制的小文件合并存储方案,通过创建一个索引文件来保存小文件的索引信息。上述方法都是先将小文件合并成大文件,再存储大文件,有效地解决了内存瓶颈问题。但是合并小文件时没有考虑小文件间的关联关系,还可进一步提高文件读取速度。
马振[12]提出了变尺度堆栈算法VSSA 合并小文件,该算法以迭代的方法选取待合并队列中最大的小文件进行合并,充分地利用数据块存储空间。游小容[13]利用教育资源中小文件的前赴后继关系将小文件合并为大文件。Xiong L[14]利用时空范围合并时空数据小文件。Ahad M A[15]提出一种动态合并技术,根据小文件的大小和类型进行合并。Fan Y[16]设计了一个小文件处理系统SFPS,合并相似的小文件,可以减少小文件的数量和冗余数据。Nivedita V[17]根据用户访问的优先级建立小文件合并模型。上述方法都是先将特定场景的小文件合并成大文件,再进行存储,可以根据文件大小和数据间关联关系进行合并,不仅解决了内存瓶颈问题,还提高了文件读取速度。但是这种方式只能解决某一特定领域的小文件合并,适用性不高,而且,将合并索引文件与数据块一起存储,导致访问文件数据的速度不快。
综上可以发现,通过改进系统结构可以解决小文件存储的问题,但是增加了系统的建设成本和复杂性。通过合并小文件和特定场景下的小文件后再存储的两种方式不但有效地解决了内存瓶颈问题,而且提高了文件读取速度,但是只能解决某一特定领域的文件合并存储的问题,适用范围受限制。
因此,本文提出一种基于HDFS+HBase+Redis 的海量车辆小图片存储与检索系统。首先,针对小图片存储的问题提出一种基于关联关系的合并存储方法,先根据车牌号所属省份、车身颜色和车型的关联关系合并小图片,再存储到Redis 建立的临时队列中,待达到合并文件达到队列大小时存储至HDFS 中。然后,提出一种基于冗余策略的存储优化方法,将每一类的合并文件复制三份,分别存储在以车牌号所属省份为索引的存储区域、以车身颜色为索引的存储区域和以车型为索引的存储区域,并将索引信息存储在HBase中。最后,针对提出的海量车辆小图片的存储优化模型设计了一种合理的小图片检索流程。可以快速地定位车辆信息,整体了解实时的交通状况,及时引导车辆的正常行驶。
1 海量小图片存储问题分析
当大小为100KB 的小图片存储到默认数据块大小为64MB 的HDFS 中,小图片实际所占用的硬盘大小为100KB,并非64MB。因此,存储海量小图片并不会产生硬盘压力,但是,会增加HDFS 中NameNode 的内存消耗,而且,在读取小图片时会消耗大量时间。
通常,为了方便查找小图片存储在哪个数据块中,将小图片的文件名,数据块ID 和数据块存放位置组成元数据,存储在HDFS 的Namenode 中。一般情况下元数据的大小为250bytes,但是,如果数据块默认备份为三个副本数据块时,新备份的两个副本的元数据大小则为368bytes。
当n个小图片进行三备份后存储在HDFS 中,NameNode 的内存消耗如式(1)所示。随着小图片数量n的逐渐增加,NameNode 的内存消耗越来越大。

其中,a表示HDFS 没有存储数据时NameNode本身所占内存大小;b表示每个数据块的列表信息在NameNode 的内存消耗;B表示HDFS 中数据块大小;fi表示在HDFS 中存储的n个图片所占内存大小。
当小图片数据块进行一备份后存储在HDFS 中,读取n个内存大小为fi的小图片的总耗时如式(2)所示。随着小图片数量n的逐渐增加,访问NameNode 和DataNode 的次数越来越多,读取时间越来越长。

其中,Trequ表示NameNode 接收检索请求的时间消耗;Tquer表示NameNode 查询元数据的时间消耗;Tresu表示NameNode 返回目标元数据的时间消耗;Tacce表示用户在DataNode 中检索目标文件的消耗;Tdata表示DataNode 查询目标小图片的时间消耗;Tfile表示DataNode 返回目标小图片的时间消耗。
根据上述关于NameNode 的内存消耗和小图片读取时间的理论分析,可以发现,如果想解决海量小图片存储时产生的NameNode 内存消耗和小图片访问延迟的两个问题,需要减少NameNode 的元数据的个数,减少NameNode 的访问次数和降低DataNode 读取目标数据块的时间。
2 海量车辆小图片的存储方案
2.1 基于关联关系的合并存储
在Hadoop 大数据平台上存储海量的车辆小图片时,由于每张小图片的大小均小于HDFS 的数据块大小(64MB),则会出现NameNode 内存瓶颈,MapReduce处理性能降低和存储耗时太长等问题。现有的方法为了降低NameNode 内存占用较高的问题,一般采用先将小文件合并成大文件,再存储大文件的过程。该方法可以解决内存瓶颈问题,但是在合并时未考虑图片之间关联关系。
因此,本文提出了一种基于关联关系的合并存储方法。首先,建立初始临时队列,将存入一张初始图片。然后,判断待存储图片是否与其中一个临时队列中的初始图片具有相同的省份车牌号、相同的车身颜色和相同车型,若完全相同,则将待存储图片合并到临时队列中,否则新建一个临时队列,将待存储图片作为新建临时队列的初始图片,重复上述操作,直至所有的待存储图片上传至HDFS 进行存储。具体的操作步骤如下所示。
(1)初始时,使用Redis 建立一个临时队列q0,从小图片序列P={p0,p1,...,pn}中取出一张图片p0,进入队列q0中,作为队列q0的初始图片。
(2)从序列qi中取出小图片pi,然后判断每次取出的pi与现存所有临时队列中的初始图片是否具有相同省份的车牌号、相同车身颜色和相同车型,若pi与某一个临时队列qi中的初始图片具有相同省份的车牌号、相同车身颜色和相同车型,则pi进入临时队列qi中;否则,Redis 新建一个临时队列qj,pi进入临时队列qj中,作为队列qj的初始图片。
(3)当临时队列qi接收pi的等待时间超过设置的时间阈值,若超时,将队列qi中的合并文件上传至HDFS 进行存储。
(4)当pi进入临时队列qi后,判断队列中文件的总大小是否超过设置的HDFS 数据块大小,若超过,也将队列qi中的合并文件上传至HDFS 进行存储;否则,继续执行步骤(2)~(4),直至序列P为空;
(5)当序列P为空时,将所有临时队列中未达到数据块大小的合并文件上传至HDFS 进行存储。
2.2 基于冗余策略的存储优化
当合并文件上传至HDFS 后,随机地存储在HDFS中的存储区域。若查询红色车辆的信息,需要访问所有的存储区域,若查询轿车的信息,也需要访问所有的存储区域。所以,当车辆小图片的存储系统在某一时段进行大量查询请求时,大大增加了工作节点的任务数。因此,为了提高存储系统的吞吐率和降低系统负载,本文在不增加额外系统开销的前提下,利用Hadoop数据块的三备份机制,设计了一种基于冗余策略的存储优化模型,如图1 所示。
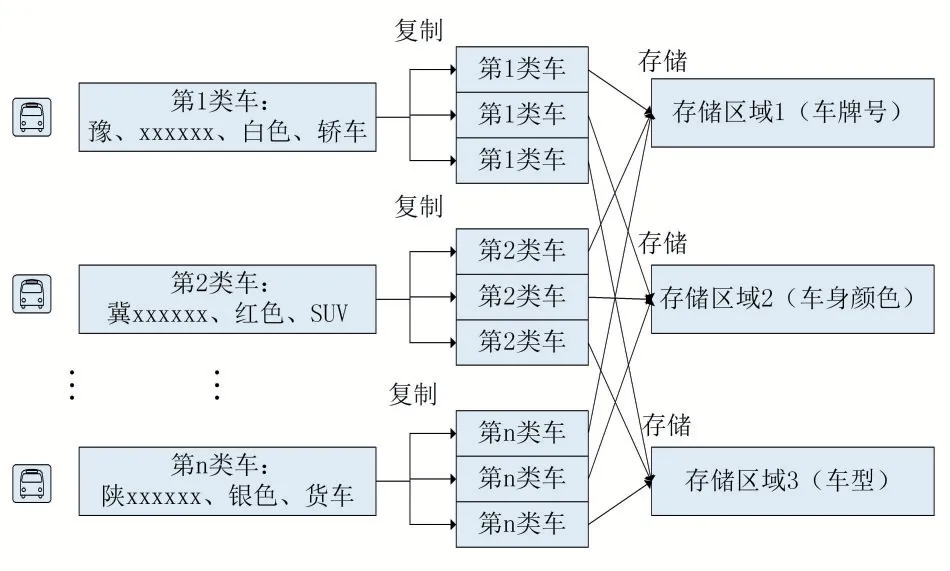
图1 基于冗余策略的存储优化模型
如图1 所示,首先,基于冗余策略的存储优化模型根据Hadoop 数据块的备份机制,将上传至HDFS 中的n 类车辆的合并文件数据块复制成三份,然后将每一类车辆的三份合并文件分别存储在以车牌号的索引的存储区域1、以车身颜色为索引的存储区域2 和以车型为索引的存储区域3。
2.3 合并存储的索引建立
当车辆小图片的合并文件在HDFS 中优化存储后,为了能够快速检索到合并文件中的车辆小图片,本文还提出了合并索引机制。将合并文件的三份数据块分别按照车牌号所属省份、车身颜色和车型建立三种索引信息,并将索引存储在HBase 中。然而,为了避免在HBase 中出现访问热点的问题,将车牌号所属省份和32 位随机hash 值组合作为车牌号索引信息的Rowkey 的命名格式,索引信息结构如表1 所示。将车身颜色和32 位随机hash 值组合作为车身颜色索引信息的Rowkey 的命名格式,索引信息结构如表2 所示。将车型和32 位随机hash 值组合作为车型索引信息的Rowkey 的命名格式,索引信息如表3 所示。
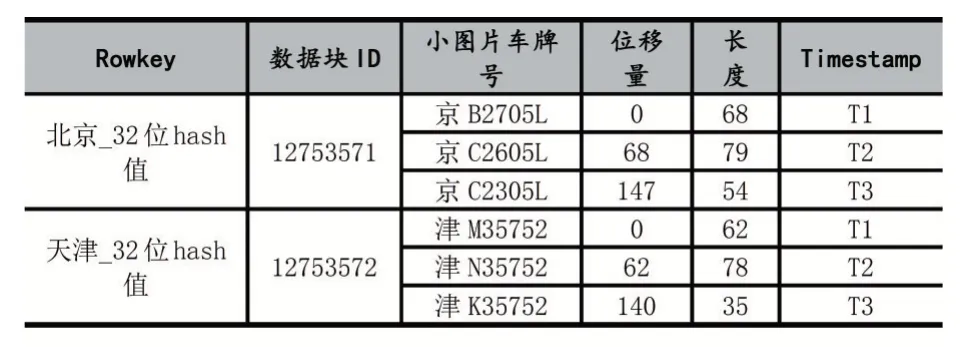
表1 车牌号所属省份的索引信息结构
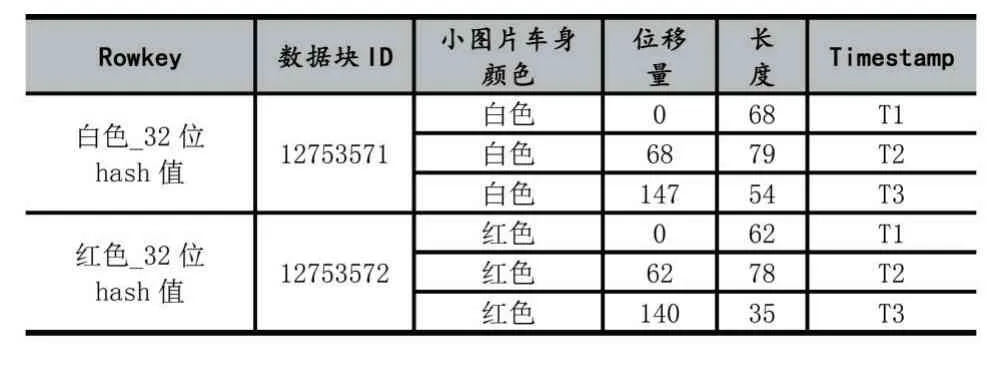
表2 车身颜色的索引信息结构

表3 车型索引信息结构
以表1 所示的车牌所属省份的索引信息结构为例,每个合并文件的Rowkey 为省份_32 位hash 值,每个Rowkey 记录了合并文件的数据块ID、每个小图片的车牌号、小图片在合并文件中的偏移量和长度。当用户需要获取某一个车牌号的小图片时,先根据车牌号所属省份在车牌号索引信息中查找到合并文件的索引记录,再根据索引记录中小图片的偏移量和长度找到小图片的存储位置,获取到小图片。
3 海量车辆小图片的检索方案
基于第2 章提出的海量车辆小图片的存储方案,本文给出了对应的车辆小图片的检索方案,检索流程图如图2 所示。具体的流程如下所示。
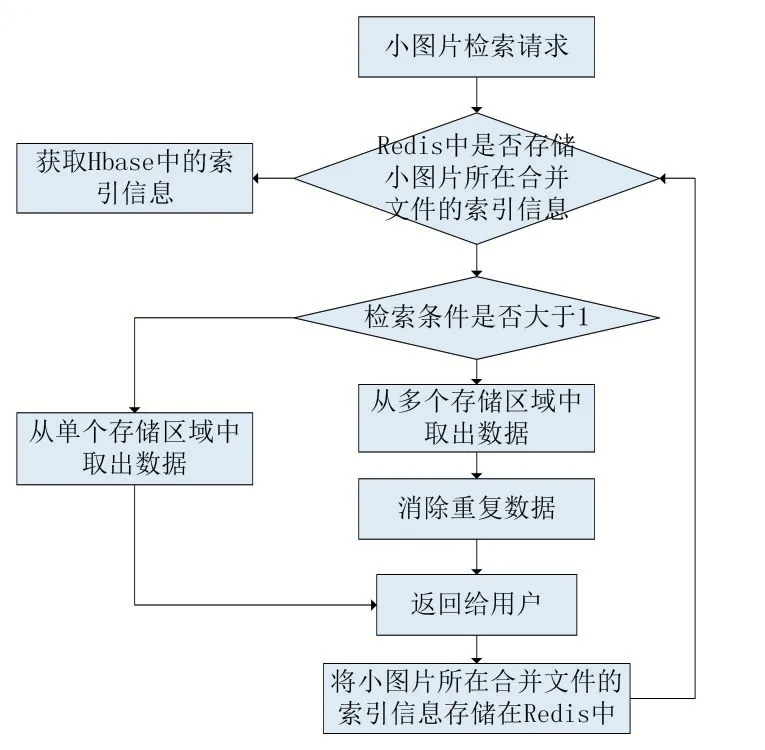
图2 车辆小图片的检索流程
(1)根据小图片的检索请求,从Redis 缓存的合并文件的索引中查询是否存在该小图片的合并文件,如果存在,获取合并文件的数据块ID 和元数据信息,直接访问DataNode,读取出小图片,将图片返回给用户。
(2)如果不存在的话,则开始判断检索请求的条件,如果检索条件的个数为1 的话,只需按照检索条件查询一个查询区域,获取小图片的存储地址。假设查找白色的车辆图片,则只需从以车身颜色为索引的存储区域筛选出白色车辆的数据块。
(3)如果检索条件的个数超过1 时,则按照检索条件分别从各自的存储区域查找数据。然后,对分别查找出来的数据进行去重操作:①当查询条件存在车牌号时,只按照车牌号去重;②当查询条件不存在车牌号时,则采用加速稳健特征算法(Speed Up Robust Feature,SURF)计算图片之间的相似度,如果两张图片的相似度达到阈值时,进行去重后获取到小图片。
(4)读取出去重后的图片,将图片返回给用户。
(5)根据数据预取机制将该合并文件的索引信息和元数据信息缓存在Redis 中。
4 实验
4.1 实验环境
本文搭建了一个实验平台,主要用于测试存储优化方案在存储小图片时的内存消耗变化和读取小图片的效率变化。实验平台的硬件配置是:8G 内存,4 核CPU和200G 的硬盘服务器。实验数据:小图片大小访问是30KB 到40KB。本文实验以HDFS 的NameNode 的内存占用、小图片数量和小图片读取的时间作为评价指标,将实验结果与原生HDFS 的实验结果进行对比。
对于本文提出的存储优化模型,小图片读取的时间包括小图片的合并时间t1和合并文件存入HDFS 的时间t2,考虑到合并文件中小图片的数据量S,因此本文提出的存储优化模型的小图片平均存储时间为T=(t1+t2)/S。对于原生HDFS 只直接存储小图片,不进行小图片的合并,因此,小图片的存储时间为存储时间t。
4.2 对比实验
第一组实验是为了验证本文提出的存储优化方案能够降低存储小图片的内存占用,与原生HDFS 在相同的实验环境下进行对比实验,分析随机读取小图片时NameNode 的内存占用情况,对比实验结果如图3 所示。

图3 内存占用对比图
从图3 中可以看出,当小图片数量不超过10000个时,本文提出的存储优化模型的优化效果并不明显,但是随着小图片的数据量不断的增加,存储优化模型比原生HDFS 能够明显降低NameNode 的内存占用。
第二组实验是为了验证本文提出的存储优化模型能够提高小图片的读取速率,与原生HDFS 在相同的实验环境下进行对比实验,分析小图片的存储时间,对比实验结果如图4 所示。
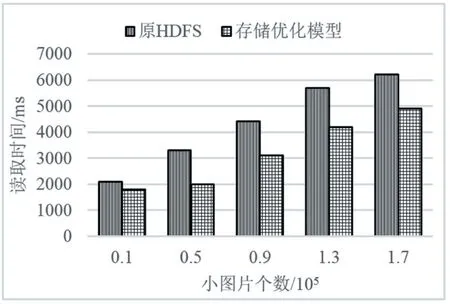
图4 小图片读取时间对比图
从图4 中可以看出,本文提出的存储优化模型能够在小图片读取时间上优于原有HDFS。虽然小图片的合并和索引建立两个过程消耗了一定的时间,但是,随着小图片的数量逐渐增加,建立索引优化了小文件的存储过程,两个操作消耗的时间相对于小图片的存储时间可以忽略不计。并且,先合并小图片再存储可以减少元数据的数据量,从而减少了存储小图片时检索HDFS 空闲块的时间。在读取小图片方面,本文提出的优化方案加入了基于Redis 预取相关小图片机制,将和正在访问的数据集有关的小图片元数据预取在内存中。因此,本文提出的存储优化模型能够很好的降低小图片的读取时间。
5 结语
为了降低海量车辆小图片存储的NameNode 内存消耗和提高小图片的读取时间,本文首先对这两个问题进行了理论分析,可以发现,随着小图片数量的逐渐增加,NameNode 的内存消耗越来越大,访问NameNode和DataNode 的次数越来越多,读取时间越来越长。然后提出一种基于关联关系的合并存储方法,根据车辆小图片的车牌号所属省份、车身颜色和车型的关联关系,合并具有相同信息的小图片。进一步又提出了基于冗余策略的存储优化,将合并文件的数据块进行三备份,按照顺序分别存储在以车牌号所属省份为索引的存储区域、以车身颜色为索引的存储区域和以车型为索引的存储区域。从而减少了NameNode 的访问次数。接着,将索引信息存储在HBase 中,并且在Rowkey 中添加了32 位的hash 值以避免访问热点问题的出现。最后,当检索条件的个数为1 和不为1 时,给出了对应的小图片检索流程。
对比实验结果表明,本文方法不但能够明显降低小图片在HDFS 中存储时的内存占用,而且读取小图片的时间更短。
