基于局部方向场散列的掌纹快速辨识方法
2020-08-06陈曦,于明,岳峰
陈 曦, 于 明, 岳 峰
(1. 河北工业大学电子信息工程学院,天津 300401;2.北京科学技术研究院北京市新技术应用研究所,北京 100089;3.河北工业大学人工智能与数据科学学院,天津 300401)
掌纹识别近年来备受研究者关注,并且提出了多种掌纹识别方法,包括基于纹理[1]、基于方向编码[2]、基于局部描述符[3]、基于深度神经网络[4-6]等。掌纹识别系统因其在安全性的可靠表现成为出入管控、身份鉴别等应用领域的理想解决方案。
掌纹识别系统通过比较查询掌纹与存储模板的相似度来进行身份辨识。研究发现系统识别的准确性和处理速度将会随着注册人数的上升而下降[7]。然而很多系统需要面向大规模人群进行身份辨识,因此加速识别过程不仅可以减少系统响应时间,而且可以通过采用更复杂的匹配算法,为提高识别精度提供可能性[8]。现有的快速掌纹识别方法可以大致分为层次匹配法、掌纹分类法和基于树形结构的识别方法和基于散列的识别方法。
层次匹配方法[9]通常会提取多种简单特征,然后以分层的方式快速搜索目标。因此,这类方法可以构建多层搜索结构,从而在单个层中排除较少候选目标。分层匹配方法的缺点是在搜索终止之前产生目标丢失的情况。
掌纹分类方法是指将掌纹分成几个类别,然后将输入图像与其对应类中的模板进行匹配[10]。这种方法的缺点是根据初始分类规则,可能会将查询掌纹和目标模板置于不同的类别中,从而无法成功进行匹配。因此,尽管这两种策略在加速识别过程方面都取得了不错的性能,但它们会造成明显的精度损失。
2009年,Yue等[11]提出了一种基于覆盖树的快速掌纹识别方法,随后通过优化树结构对其进行了改进[12]。结果表明,该方法可以显著加快识别过程,而且相对于传统的蛮力搜索,没有任何精度损失。但是由于在搜索过程中必须查询到注册者的至少一个模板,因此在搜索加速上受到一定限制。
受到模糊数据快速检索的启发,Yue等[13]提出了一种基于散列的快速掌纹识别方法主方向模式散列(POP hashing)。POP hashing设计了一种主方向模式(POP)作为散列函数,从而通过减少目标的搜索范围而加速识别过程。实验结果表明其在几乎不损失精度的前提下比蛮力搜索方式快十倍以上。此外,与序数编码(ordinal code),鲁棒线编码(RLOC)等方法的对比结果证明,POP Hashing在精度和速度上都优于这些方法。
为此,定义一种新的散列模式,称为局部方向场模式。并根据其设计了一种新的快速掌纹识别方法局部方向场编码(LOFP hashing)。在公共数据库的实验结果表明,LOFP hashing可以将POP hashing的识别速度显著提升3~10倍。
1 散列与基于散列的掌纹识别方法
散列是一种旨在对目标数据分块的技术,它通过散列函数为每个数据标定一个散列值,每个散列值对应若干数据。在搜索特定目标时,通过散列的方式可以将搜索空间从整个数据库转化成特定子空间中的数据,这样可以通过缩小搜索范围来提高搜索效率。图1为简化的数据散列示意图。
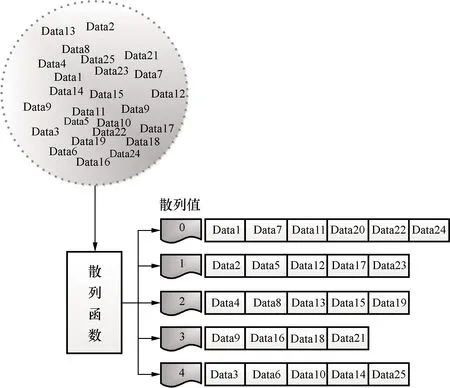
图1 数据散列过程示例Fig.1 An example of the hashing process
文献[13-14]证实,基于方向编码的掌纹识别技术可以通过散列的方式显著提升搜索效率。由于方法采用了类似的散列框架,因此将简要介绍文献[13]中快速掌纹识别方法POP hashing。
在预处理阶段,POP hashing首先提取掌纹图像的D=1 024个方向特征,并将特征所属的用户ID依次索引至散列表H。同时,还需要建立一个位移表S和尺度表O(tabO)。位移表S用于记录编号为1~1 024的特征在散列表H(tabH)的起始位置。尺度表O用于记录散列表H中每个位置所包含的用户ID数量。
在搜索阶段,该方法定义了一种散列函数,称为主方向模式(POP),它包含K个不邻接的主方向特征。主方向特征(POF)是指位于手掌三条主线位置的特征,POF的稳定性高、一致性强[15]。POP hashing通过一组Gabor滤波器对掌纹图像卷积后,将响应强度前10%的方向特征选为POF。然后,将每个POP在散列表H中进行搜索,当其K个POF检索到的用户ID有交集时,称为一次碰撞。查询样本与真实目标的碰撞称为真碰撞,否则称为假碰撞。POP hashing采用多碰撞策略,当候选目标的碰撞次数达到C,认为找到了疑似目标,将其与查询样本进行全匹配,并通过匹配得分判断是否成功命中目标。
随后,Yue等[14]改进了POP Hashing,提出了A-POP hashing算法。A-POP hashing在预处理阶段,仅用P=0.5D个响应强度较高的特征建立tabH,不仅减少了全匹配的次数,还可以减少约50%的存储空间。
综合速度与识别准确度,POP和A-POP hashing是面向大规模数据库的掌纹识别算法中最具优势的方法。
2 方法
由图1可知,有若干数据共享相同的散列值。同一散列值对应的数据量越多,假碰撞的概率越高,查找的复杂度越高。对于POP hashing,通过POP包含的K个方向特征以及阈值为C的多碰撞策略,可以将散列后的子空间大小,即共享相同散列值的模板数量限制在χ左右,如式(1)所示:
(1)
式(1)中:B为方向编码的数量,对于POP hashing,B=6;N为数据库中模板的总数。因此为了进一步降低查找复杂度,可以通过增加B、K或C来实现。然而,K或C的增加会造成识别准确率下降,因此它们的选择要平衡速度和精度。而且使用二维Gabor滤波器对图像卷积是一个复杂度较高的运算,因此通过增加滤波器数量来增加B并不可行。使用基于梯度的方向场来进行掌纹方向特征提取和POF筛选。
2.1 掌纹方向特征提取和POF筛选
基于梯度的方向场被广泛用于方向特征提取。相对于Gabor滤波器组,它可以在有限的时间耗费下得到每个位置连续而非离散的方向表达。基于梯度方向场在图像坐标(m,n)上的梯度强度δ和方向θ可以根据式(2)、式(3)得到:
(2)
(3)
式中:Gx(i,j)和Gy(i,j)分别为由Sobel滤波器与掌纹图像卷积得到的水平和垂直方向的梯度响应;W为滤波器的尺寸。由于基于梯度的方法容易受到噪声的影响,因此通过式(4),对得到的方向θ进行一致性评估,一致性权重φ是介于0~1的值,φ越高,θ的可靠性越强。
(4)
然后,通过对加权梯度强度κ=δφ进行降序排列来检测主方向特征POF。图2为随机选取两个手掌的不同样本,根据排序后κ前10%的方向特征选取的POF。从图2可以看出,检测出的POF基本都位于主线相关区域,而且不同样本间重合度很高。在100个掌的实际测试中,POF的位置重合度达71.2%,重合的POF具有相同方向编码的比例是92.4%。而在κ排序靠后10%的方向特征重合度为38.6%,重合点具有相同编码的比例仅为34.8%。因此,根据方法检测的POF具有很强的一致性。

图2 两个手掌不同样本检测的POFFig.2 POFs across the samples of two subjects
2.2 特征双编码方法
检测到POF后,需要对它们连续的特征方向θ进行离散化编码。传统方向编码方式有两个缺点。首先,绝大多数情况下θ会落在两个离散编码值之间的区域[16],也就是说,用单个编码表示连续方向并不精确。如图3(a)所示,当θ处于编码C3和C4之间的区域,无论哪个编码都无法精确表达θ;当θ处在编码边界时,编码存在不稳定的情况,称这种情况为边界漂移(boundary-shifting)。如图3(b)所示,fα和fβ表示两个方向特征,它们的连续方向表达分别为θ-ε和θ+ε,其中ε>0且足够小。若θ处于编码Cα和Cβ的边界,它们会被分别编码为Cα和Cβ。由于二者方向非常接近,因此更合理的方式是将它们编码为相同的值。
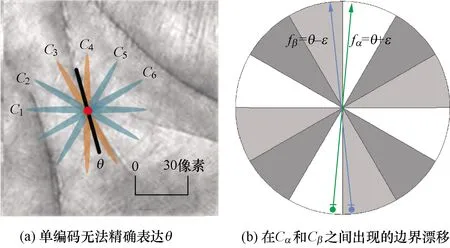
图3 传统编码方式存在的缺陷Fig.3 Disadvantages of single-orientation encoding method
根据式(1),为了降低目标搜索的复杂度,选取了相对于POP hashing更大的编码数量B=18。随着B的增长,每个离散编码可以表达的方向更为精确,因此图3(a)中的影响会降低。但是由于编码边界更为密集,因此图3(b)中边界漂移的情况会愈发频繁地出现。因此,提出一种称为方向场编码(OFC)的双编码方式,除了根据传统方式将θ编码为主导码Cd,还将其最近邻的码域所属的码值编为辅助码Ca。即α=(Cd,Ca),定义如式(5)所示:
(5)
根据这种方式,一副掌纹图像的所有P个POF被双编码为β={ap},p=1,2,…,P。对于任意两个编码Cα和Cβ,它们之间的距离被定义为γ,如式(6)所示。
γ(Cα,Cβ)=min(Cα-Cβ,B-Cα-Cβ)
(6)
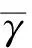
(7)
(8)
进一步,将每个编码表达为9层18位的比特码形式,如表1所示。那么式(5)中的两个编码可以改写为式(9)的形式。

表1 OFC的9层18位比特码Table 1 9-layer,18 bits representation of OFC
(9)
式(9)中:bl为第l层的18位比特码,而式(6)可以被重新表达为Hamming距离γ:
(10)
式(10)中:⊗表示逻辑异或操作,这样不仅可以方便编码在计算机当中存储,还能使编码距离的计算非常便捷[17-19]。
最终,两个OFC编码的匹配得分通过非线性距离度量方式计算。
(11)
2.3 局部方向场模式与LOFP Hashing
2.3.1 局部方向场模式
为了解决查询样本与模板没有精确配准的问题,搜索阶段在查询碰撞时需要在对查询目标进行位置平移,这个过程会带来不可忽视的计算压力。以POP hashing为例,它需要在水平和竖直方向上进行[-2,+2]的移动,因此样本与模板之间需要尝试25种配准方式。如果能够在不损失精度的情况下减少这些尝试,搜索的复杂度将至多减少96%。


图4 LOFP示意图Fig.4 An example of LOFP
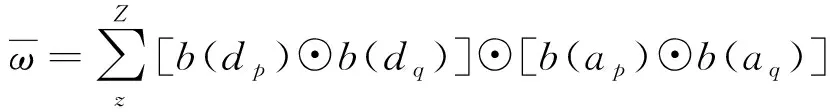
(12)
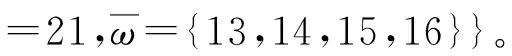
2.3.2 LOFP Hashing
在预处理阶段,提出一种基于窗口码图CM构建散列表H的方法,具体方法如算法1所示。用这种结构,可以方便地记录每个POF的双编码以及在图像坐标系下坐标到LOFP区域索引号ϑ的转换。其中算法1第3行中坐标(x,y)到区域索引号的映射方法如式(13)所示。
算法1 窗口码图的构建
输入:POF数量P;OFC编码OC={ap},p=1,2,…,P;POF坐标POS
输出:窗口码图CM
CM=NULL//初始化
fori=1 toPdo
ϑ=Get_Wnd_Idx(POS(i)) //坐标映射
Ccode=αi//获取OFC双编码
CM[ϑ][Ccode(0)]=TRUE //主导码位置
CM[ϑ][Ccode(1)]=TRUE //辅助码位置
end for

(13)
在搜索阶段,对于一个LOFP的二元表达{P=·,V=*},检索目标身份信息,即第1节中所述的碰撞检测方式如下:首先,根据位移表O[·][*]找到记录对应散列值子空间的起始位置。然后,根据尺度表S[·][*]找到H中记录的子空间大小。最后,根据子空间起始位置与大小返回所有模板的身份信息。如图5所示。

图5 散列表搜索示意图Fig.5 Searching the hash tables
详细的碰撞检测方法由算法2给出,变量Cs用于统计查询掌纹的LOFP中,在H的窗口码图CM有对应记录的数量,如果等于K,表示发生一次碰撞(算法2中的第13行),然后将相应的用户ID插入到待检队列Cd,并更新碰撞计数器c(算法2中的第21行)。当a中某个元素超过碰撞阈值C,认为找到候选目标,将输出对应模板ID,进行全匹配。
算法2 碰撞检测
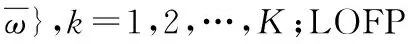
输出:碰撞计数器a
a=0 //初始化
Cd=NULL //初始化待检队列
Cs=NULL
fork=1 toKdo //逐个检测
forz=1 toZkdo //逐个检测
of=O[ϑk][Ccode] //起始位置
size=S[ϑk][Ccode] //子空间的大小
forsz=1 tosizedo //检测窗口码图CM
IfCM[ϑk][Ccode]=TRUE //CM有对应值
ID=H[of+sz]
Cs[ID]=Cs[ID]+1
IfCs[ID]=K
Insert(Cd,ID) //插入队列
end if
end if
end forsz
end forz
end fork
forl=1 to Length(Cd)
c[Cd(l)]=c[Cd(l)]+1 //更新计数器
end forl
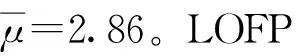
在方法上,LOFP hashing采用了与POP hashing相似的框架。所提出的方法与其主要区别在于以下三点。
(1)基于梯度的方向场能够以较少计算代价提取特征的连续方向表达θ,利用式(3)、式(4)得到的一致性加权梯度强度可以提取到稳定的POF。
(2)根据式(1),选取的较大的编码范围B使方向特征更具有区分度。OFC双编码方式不仅可以消除边界漂移和提高编码对连续方向θ的表达准确性,同时可以根据式(10)、式(11),以很小的存储和运算代价得到编码间的相似度得分。
(3)窗口化的特征表达方式LOFP可以去除检测碰撞时的位置平移过程,至多减少96%的碰撞检测次数。
3 实验结果与分析
3.1 测试数据库
使用三个大型公开数据库,简介如下。
(1)香港理工大学大型掌纹数据库(DB1)[20]:包含9 667个手掌,共93 638张图像。数据库中,约86%的受试者是学生,约12%是工人,约1%是老人,1%是其他人。
(2)中国科学院掌纹数据库(DB2-R)[21]:包含5 237张从600个掌获取的图像。每只手掌大约8张图片,所有的样本都在同一周期采集。在数据采集过程中,没有限制手掌姿态和位置,也没有构成半封闭环境。因此图像质量比DB1中要差。
(3)十万人模拟数据库(DB2-S)[22]:包含了100 000个模拟生成的模板,每个模板是一个1 024维随机生成的方向特征向量。
实验中,将第二个数据库DB2-R和第三个数据库DB2-S合并为一个超大型数据库DB2。数据库选取的依据有两点。首先,3个数据库的选择与设置和相关文献中一致,可以公平地比较方法性能。其次,3个均为国际公开大型数据库,有利用模拟大规模人群辨识过程。
3.2 结果评估标准
实验从识别准确度和速度两个方面评估方法性能。准确度方面,采用生物识别领域三个通用的评估指标:错误拒绝率(FRR)、错误接受率(FAR)和真实接受率(GAR)。FRR表示查询样本未被成功识别的比例,FAR表示查询样本被识别为错误身份信息的比例,GAR表示查询样本被成功识别的比例。速度方面,以方法相对于蛮力搜索的速度提升比例,即加速比为标准。蛮力搜索是生物识别系统中最广泛的一种匹配方式,它将查询目标与模板逐一匹配,直至找到满足相似度阈值的目标。
实验平台为一台PC机,配置为Intel i7-8700 320 GHz CPU,8 GB RAM,仅使用CPU单核单线程。软件环境是Windows 10 Home Basic(64位)和 Visual Studio 2010。测试程序由C++语言编写。
实验参数由网格法得到,即通过限制每个参数的取值范围,执行多个循环寻找最佳组合。它们分别是:LOFP包含的编码数量K=3、碰撞阈值C=4、编码数量B=18、窗口大小Sn=2。为了公平地进行对比实验,相似度阈值T=0.35与POP 和 A-POP hashing相同。
3.3 识别准确度实验与分析
在DB1中,模板和测试样本的数量分别为9 667和83 971。蛮力搜索的GAR为99.27%。在不同参数K和C下实验结果如图6(a)所示。由图6(a)可以看出,当K=2、C≤10和K=3、C≤6时,方法的GAR与蛮力搜索几乎相同。实验将DB2的模板和样本的量分别为100 600和4 637。在DB2中,蛮力搜索的GAR为95.99%,方法的GAR如图6(b)所示,其走势与DB1中的结果类似。
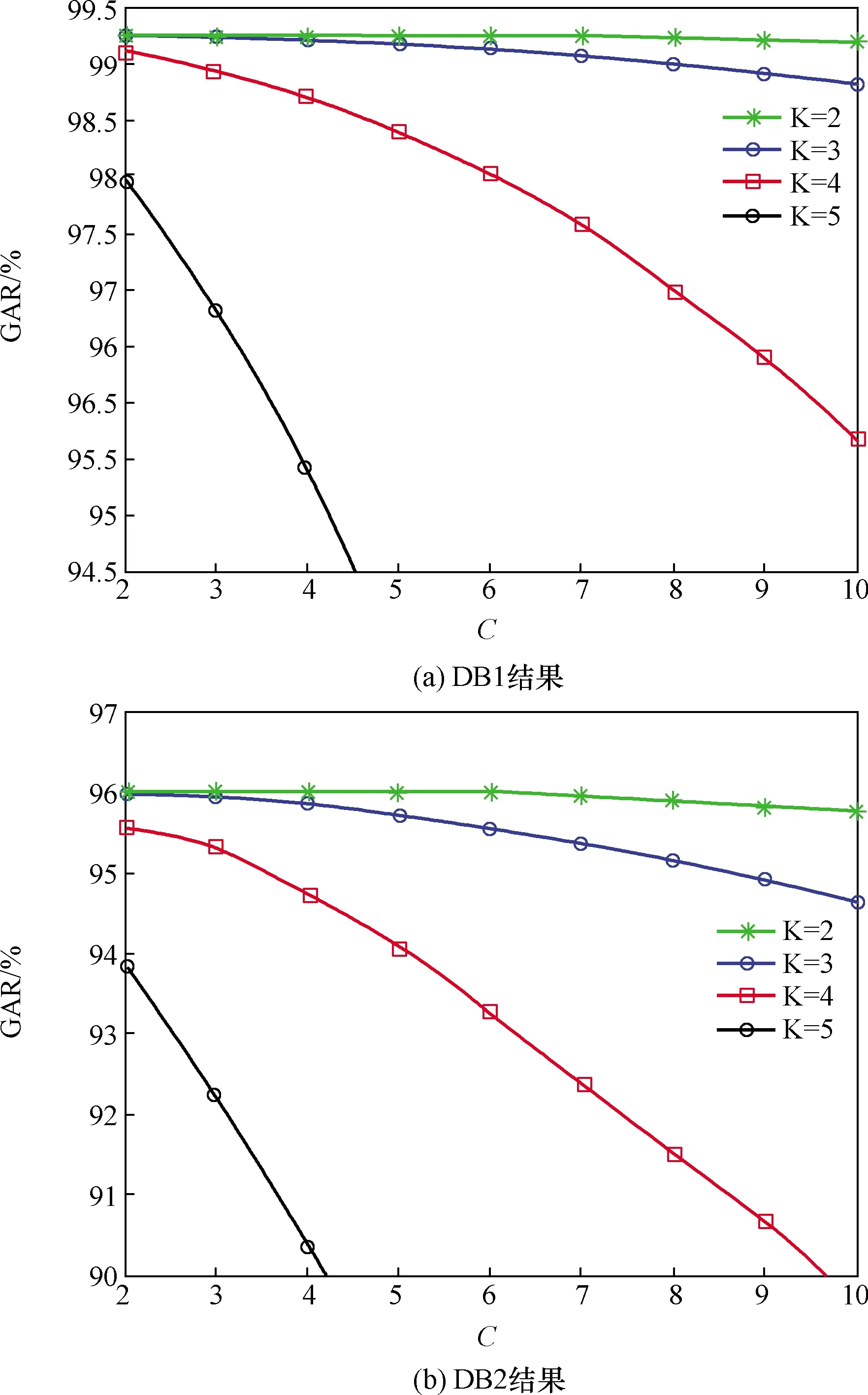
图6 LOFP hashing在DB1和DB2中的GARFig.6 GARs of the proposed method on DB1 and DB2
3.4 识别速度实验与分析
图7给出了不同数据库中LOFP Hashing相对于蛮力搜索方加速比的实验结果。从图7可以看到,曲线的走势可以近似看作具有极大值的抛物线。结合图6可知,在最初阶段随着C的增加,满足碰撞阈值的次数会减少,造成全匹配次数减少,加速比迅速上升,同时准确度开始下降。达到加速比顶点后,若C持续增加,虽然全匹配次数仍在减少,但是需要更多的LOFP参与碰撞检测,因此加速比开始下降。加速比顶点随着K的增加而越早地出现。
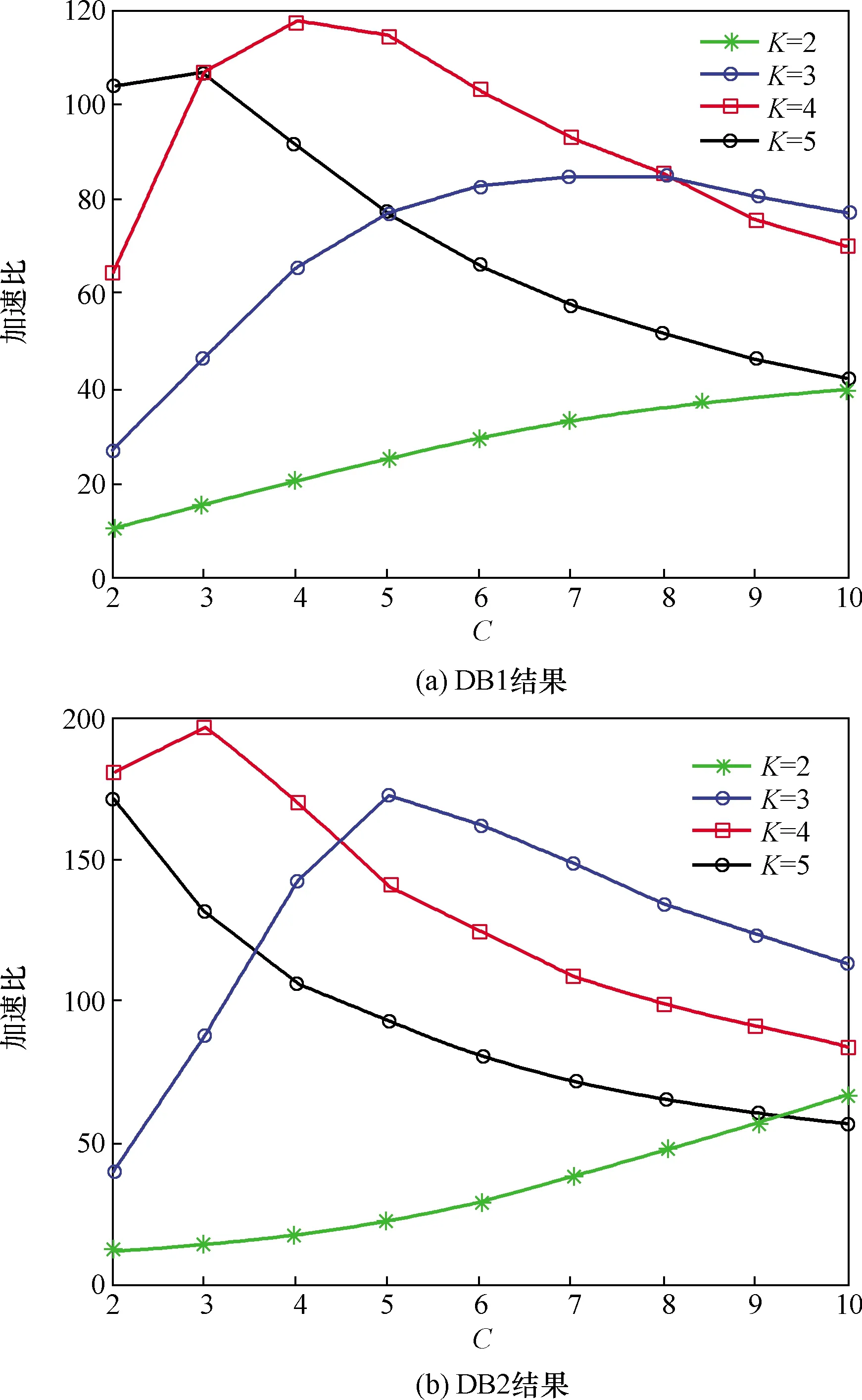
图7 LOFP hashing在DB1和DB2相对于蛮力搜索的加速比Fig.7 Speedups of the proposed method on DB1 and DB2
在搜索阶段,查询掌纹会与大小为N的模板集进行M次全匹配,直到找到目标或返回“不匹配”。M与N的比例在生物识别领域被称为渗透率[19]。渗透率越低表示算法减少全匹配次数的性能越强。图8给出了不同参数下渗透率的比较。蛮力搜索的平均渗透率约为50%,与蛮力搜索相比,DB1上LOFP hashing可以将渗透率减少189.25倍,而在DB2中结果达到了337.18倍。
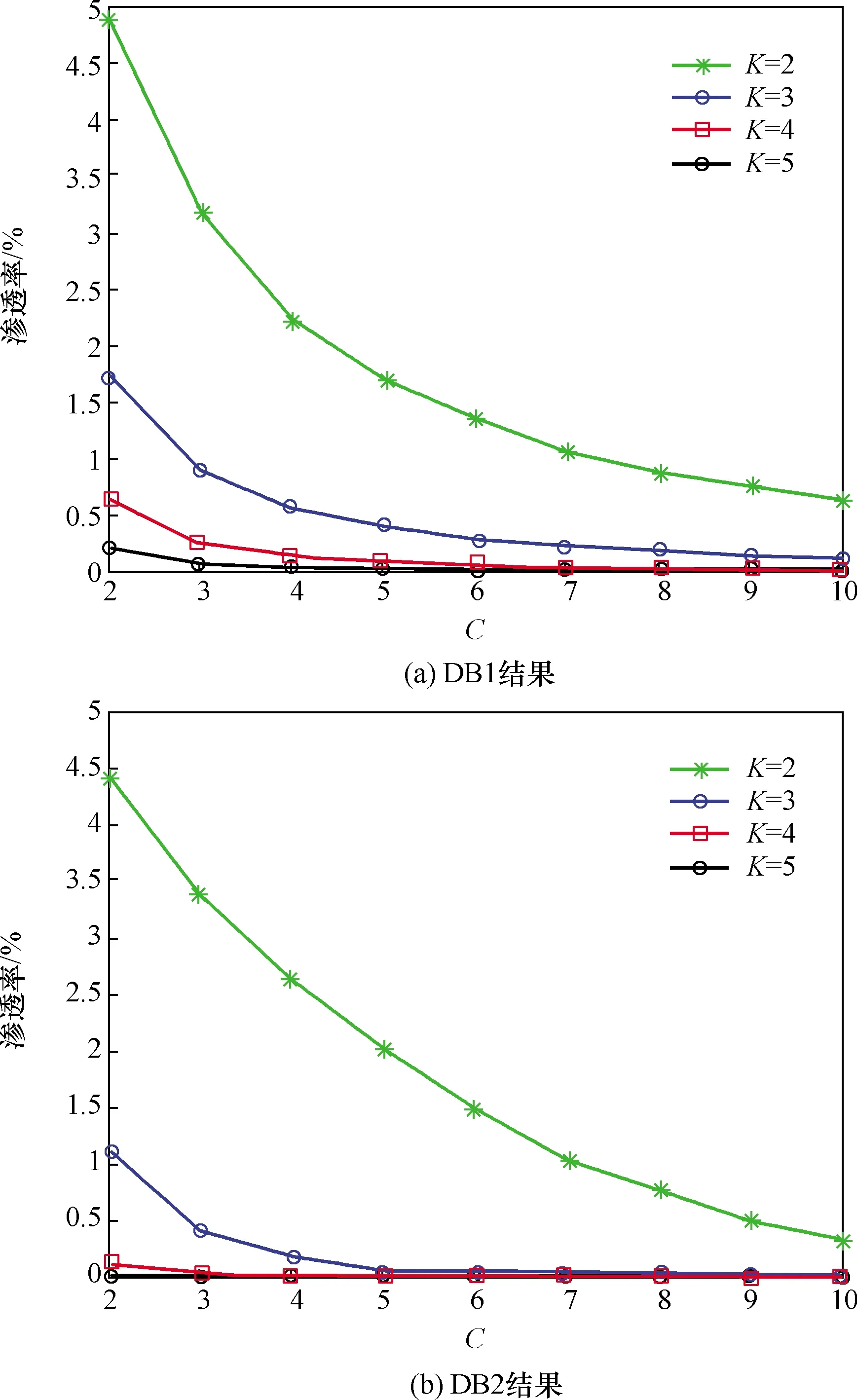
图8 LOFP hashing在DB1和DB2中的渗透率Fig.8 Penetration rates of on DB1 and DB2
3.5 对比实验与分析
作为已知最先进的快速掌纹识别方法,文献[13]已经提供了POP hashing与其他快速识别方法以及一些知名掌纹识别方法的对比。文献[14]中的A-POP方法是POP hashing的一种加速版本。因此,将二者作为标尺衡量所提方法的性能,所有的对比方法使用的软、硬件平台一致。
根据表2,在DB1上所提出的方法对于POP hashing的加速比是3.28倍,精度损失可以忽略不计,并将A-POP hashing的速度提升约50%,且精度更高。这主要是因为方法在去除了位置平移操作后,在两个数据库中将尝试碰撞的数量分别减少了约32%和49%,而选取更大的B=18和双编码方式使编码不仅可区分度更高,而且更精确。假碰撞的次数分别减少了约24%和21%。
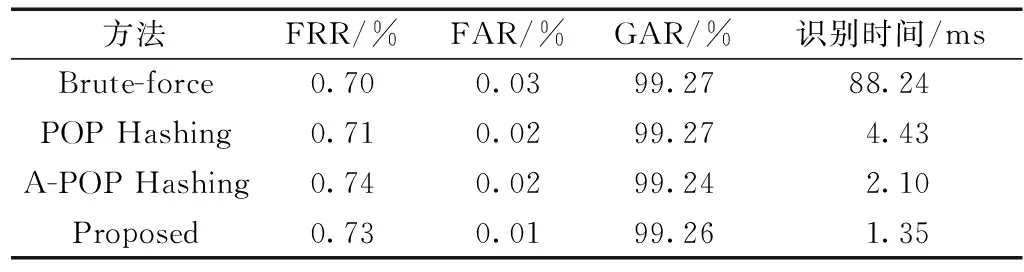
表2 在DB1上识别效果对比Table 2 Identification results on DB1

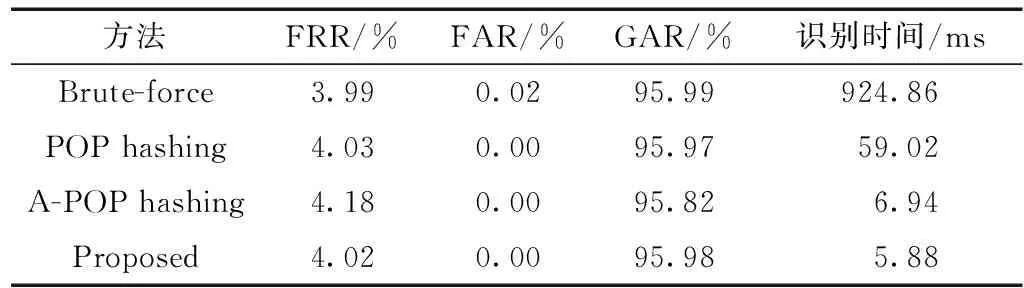
表3 在DB2上识别效果对比Table 3 Identification results on DB2
4 结论
提出了旨在面向大规模人群快速身份辨识的掌纹识别方法LOFP hashing。通过减少假碰撞的发生频率、加速目标搜索进程以及提高方向特征的稳定性和精确度三个方面对识别性能进行提升。提供了真实掌纹数据库和模拟数据库上辨识结果,并给出了理论上有进一步提升空间的合理的分析和解释。综合识别精度和速度的考虑,所提方法可以认为比当前最具优势的POP hashing及其加速版本A-POP hashing更适用于大规模人群身份辨识。随着深度学习理论与应用的快速发展,未来的研究重点将着重放在基于深度学习的快速掌纹识别方法研究。
