改进的GDT-YOLOV3目标检测算法
2020-08-05唐悦,吴戈,朴燕
唐 悦, 吴 戈, 朴 燕
(长春理工大学 电子信息工程学院,吉林 长春 130022)
1 引 言
随着国家经济飞跃式的增长,人民的生活水平也在不断地提高,在城市道路上,可以看见机动车几乎人人都在使用,而随着互联网科技的发展,大多数人都用饿了么、美团外卖进行订餐,这种足不出户叫外卖的生活方式导致了骑电动摩托车的人也多了起来。机动车和非机动车(电动车、摩托车)的出现改变了人们的生活方式,它取代了原始的人力车和步行的出行方式。在给人们的出行带来极大的方便之时,也给交警部门的工作人员对道路上车流的监管带来了较大的挑战。机动车和非机动车数量的增加,导致了交通事故的频频出现,间接地造成了人员的伤亡以及财产损失。
深度学习在目标检测中被广泛应用,特别是对远小近大和运动速度不同的目标,在背景复杂的交通场景中,进行准确并实时的检测是最具挑战性的任务[1-7]。深度学习也取得了质的发展,第一类是两阶段基于区域的检测算法,以Fast RCNN(Fast Region Convolutional Neural Networks)、Faster RCNN(Faster Region Convolutional Neural Networks)、Mask RCNN(Mask Region Convolutional Neural Networks)为主要代表的算法,这类算法对目标的检测准确度很高,但是检测速度稍慢。第二类是单阶段基于回归方法的检测算法,将检测事件当作回归事件进行解决,可以直接将检测目标的位置和类别预测出来。该类算法可以达到实时性检测,但检测的准确度显然不如第一类算法。主要以YOLO(You Only Look Once)、SSD512(Single ShotMultiBox Detector512)、YOLOV2(You Only Look Oncev2)、YOLOV3(You Only Look Oncev3)为代表性的网络为主。
使用卷积神经网络所提取到的前景目标的特征,确实要比传统方法提取到的特征要好得多,可以避免许多缺点。基于CNN(Convolutional Neural Networks)的目标检测算法被应用于道路车辆监管、农业果实采摘、辅助驾驶等方面。文献[8]将VGG(Visual Geometry Group)网络提取特征,经过初步二分类和回归后得到一系列预选框,将此预选框输入到特征金字塔结构中,并构建注意力掩模模块自适应地学习有效特征,同时融合特征金字塔结构与注意力掩模模块得到更具表征性的特征;文献[9]提出了一种多尺度聚类卷积神经网络算法,来实现对行人的识别与检测,该算法是对YOLOV3进行改进,为了得到相应的特征图,首先通过简单聚类对图像特征进行提取,然后通过抽样K-means聚类算法结合核函数确定锚点位置,以达到更好的聚类;文献[10]将利用VGG16网络作为微调网络,并添加部分深层网络,通过提取目标浅层特征与深层特征进行联合训练,克服检测过程中定位与识别相互矛盾的问题。
本文以基于回归的目标检测方法中的深度卷积网络YOLOV3为基础,首先为了解决场景中运动目标尺寸大小不一的问题,将视频图像中的运动物体作为待检测目标。本文基于YOLOV3算法,针对视频图像中的运动目标对YOLOV3算法做了优化及改进,并设计搭建了一个用道路监控场景中目标检测的CNN网络。使用3种不同的数据集混合[11]训练,可以解决单个类别检测效果差的问题。实验结果表明,改进后的GDT-YOLOV3(GIOU Densenet Transition Module)网络与SSD512、YOLOV2与YOLOV3比较,检测效果有了明显提升。
本文首先提出了将GIOU(Generalized Intersection over Union) Loss引入到YOLOV3检测算法中,解决了原IOU(Intersection over Union)无法直接优化非重叠部分的问题。搭建一个紧密连接的GDT-YOLOV3网络,使尺度1、尺度2、尺度3在进行预测之前,能够收到Denseblock输出的多层卷积特征,最大化地实现特征的复用及融合。使用密集连接块提高了CNN层间的连接,可用Max Pooling前一个密集模块间的输出,可更好地增强DenseNet区块间的连接,可解决CNN网络的退化问题。针对道路监控中的运动目标,例如骑电动车的行人数据集比较少的现象,制作了相关数据集。
2 YOLOV3网络介绍
YOLO(You Only Look Once)算法最初是Redmon[12]等在2016年提出的一种基于回归的目标识别方法,到2018年发展到了第3代,所以被命名YOLOV3,它的思想是端到端的回归方法,对比先选取候选区域,再特征提取做分类的双阶段算法,它是一种轻快高效的检测方法。
YOLOV3网络仍然保持着YOLOV2[13]网络的优点,不仅在检测速度上有了提升,而且在对目标的检出率也有了提升,尤其在距离视频监控远的小目标的检测方面,检出率有显著的提升。
YOLOV3网络使用anchor boxes[14]的思想,使用了3个尺度在COCO数据集上进行了预测,每一个尺度有3个anchor boxes,小的先验框被尺度大的特征图使用,可以根据要检测的目标挑选合适的先验框anchor boxes,最后根据准备预测的尺度对网络结构进行修改。
3 相关工作
3.1 数据集
目前COCO数据集的应用较为广泛,尤其在目标检测、语义分割及目标识别等方面,更是被广泛应用,这个数据集包含了自然景象图片,以及生活中随处可见的一些背景复杂和简单的图片,而且COCO数据集的数量比较多。
在深度学习中,数据集质量选取的好坏,以及样本数量是否处于一个平衡状态直接影响最终检测效果的高低,大量的样本让网络能够充分学习到需要检测的目标特征。但是本实验中所使用的数据集中骑电动车、摩托车或行人的样本相对于机动车较少,也就会产生样本失衡的问题。因此会有过拟合问题的出现,且最终得到的检测模型在训练后泛化能力比较差。
为了避免这一问题的出现,本文在实验中采用训练整合数据集的方法,首先通过视频图像提取出含有骑车人的图像,然后进行人工标注样本个数;为了保证样本数量的最佳平衡,同时下载KITTI数据集,并将这个数据集的格式转换为COCO数据集的格式,选择使用这个数据集的原因是,它包含了各种场景下由车载摄像头采集的道路车辆实际情况,KITTI数据集中分为8个类别:汽车、行人、厢式货车、坐着的行人、骑车的人、杂项、电车。本文对KITTI数据集原有的8类标签信息进行处理,保留实验需要的3个类别标签,即Car、Pedestrian和Cyclist。
本文最终将从3个数据集选取共9 698张图片,同时用于训练视频监控场景下的运动目标检测模型。测试集采用人工标注的图片约2 000张。
3.2 候选边框维度聚类
如果初始候选框选取不好,网络的学习速度也会变得较差。对于本文使用的数据集来说,它包含的种类非常多,每个目标在图片中的姿势、所处位置、大小都略有不同;而对于行人以及骑车的行人数据集来说,它的基本特点都是长宽比明显不同。在Faster R-CNN和SSD中需要人为事先设置好先验框,主观性比较强。对于人为设置的先验框,在设置先验框时,选择一个维度适合的先验框是非常重要的,如果选择的先验框很好,网络就可以进行相对容易的学习过程,从而得到更好的预测。
本文在YOLOV3网络中使用K-means算法,将视频监控场景下捕获的运动目标做成数据集,并将数据集中的真实边框进行聚类,可以获得初始候选边框的参数信息。原始的K-means算法分别使用了以下几个距离度量方法:曼哈顿距离、欧氏距离以及切比雪夫距离,用其计算两点之间的距离。设置先验框是为了使predict boxes与ground truth 的GIOU更好。

图1 YOLOV3网络多尺度预测方式Fig.1 YOLOV3 network multi-scale prediction method
本文选取了K=1,2,3,........,9,分别对训练集使用K-means聚类分析,最终选取的候选边框数量为9,具体参数为:(10,13),(16,30),(33,23),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)。YOLOV3网络在数据集上采用3个尺度分别进行预测,具体方式如图1所示。
4 基于YOLOV3的改进
本文针对道路监控的运动目标进行检测,对图像中的车和人进行目标检测,对YOLOV3提出了3点改进。
4.1 改进的IOU Loss融合到YOLOV3
目标检测的中心思想是,如何准确输出图片里物体的类别及所在位置,对于以上两个问题,需要进行位置回归和分类的训练。在位置回归中,使用频率最高的是Bounding box和Ground Truth框的交并比,通过计算两个框的交集与并集之比,可以预测当前的predict box位置与ground truth之间的误差,并在训练过程中逐渐回归出一个更好的框。
在位置回归中,通过对L2损失函数的分析发现,即使有好的局部最优值,但这个值也未必会是IOU的局部最优值,也进一步说明了回归损失与交并比值之间仍有差距。用IOU做loss的弊端是,当两个目标框无重叠时,交并比(IOU)值为0,如果直接把IOU=0作为loss,梯度不会回传,则对训练来讲是毫无意义的,在实际情况中,这个0是非常重要的,它证明了两个框的距离比较远。为了解决IOU的缺点,本文提出了GIOU,该算法的具体过程如下:对于A、B两个框,首先要找到最小边界框来涵盖A、B区域;其次计算最小框C去除了A、B外的面积在C中所占总面积的比值,最后得到GIOU的值就是IOU减这个比值,GIOU为两个框度量准则的算法,如表1所示。

表1 预测框和真实框的度量准则算法Tab.1 Metric algorithm for prediction box and real box
表1中A为预测框,B为真实框,S是全部框的集合,C是包含A与B的最小框,C也属于S集合。
在对目标进行检测中,本文提出了使用广义的交并比GIOU取代原始损失,解决了原IOU无法直接优化非重叠部分的问题。
4.2 密集相连网络设计
在YOLOV3中,Redmon[7]等人通过参考残差网络,设计了Darknet53网络。为了实现对道路监控中运动目标的准确检测,本文使用了Darknet53,它通过ResNet结构使得训练的复杂度降低,采用了1×1卷积核及3×3/2,stride为2的卷积核取代了Max Pooling,降低了参数的数量。
2017年,Huang等人提出了新的网络Densenet[15],这个网络借鉴了Resnet[16]思想,通过对图像特征的最大化利用,可达到更好的效果和参数。在保证了网络中层与层之间最大化的信息传输后,将每个Denseblock中的每一个层连接起来。Densenet网络结构中有3个密集卷积块,3个密集卷积块中包含12个卷积层,在每个密集卷积块中,每一个卷积层可以得到所有之前的卷积层的输出作为输入,卷积层+池化层连接了毗邻的卷积层,密集卷积块的结构如图2所示。

图2 密集卷积块结构图Fig.2 Structure of dense convolution block
通过引入这种密集卷积块,可以缓解梯度消失的问题,紧密的连接结构可以提高图片特征的信息传递,在某种程度上降低了参数信息的数目。
本文在基于Darknet53网络的基础上使用密集相连增强,Darknet53的密集连接版本称为Darknet53-Dense。Darknet53-Dense由3个密集相连模块和4个Transition module构成,每个密集相连模块间都有一个Transition module,可将特征图的尺寸降低。如图3所示,Transition module中分别对上一个Dense module的输出做步长为2的Max Pooling后与使用Stride为2的卷积核的输出进行串行连接,作为下一个Dense module的输入,以这种方式使Densenet的模块间连接得到增强,可增强特征的重复使用,减少跨模块间的特征传递损失,使网络可更好地检测到视频图像中的运动目标。图3为过渡模块的图解。

图3 过渡模块的图解Fig.3 Diagram of the transition module
4.3 改进的GDT-YOLOV3网络设计
在拍摄视频图像过程中会有许多因素的影响,比如相机的内部配件、光照条件及天气因素的影响,尤其在对小目标的检测中,有时人眼都难以准确地看到运动的目标。为了使网络在这些单帧图像上仍然可以有较好的检出率,本文借鉴了Densenet网络的思想,将YOLOV3网络中尺度1、尺度2及尺度3进行预测输入的3组Resnet模块替换成自定义的Densenet模块,搭建一个紧密连接的GDT-YOLOV3网络,使尺度1、尺度2、尺度3在进行预测之前,能够收到Denseblock输出的多层卷积特征,最大化地实现特征的复用及融合。改进的GDT-YOLOV3网络结构如图4所示。

图4 改进的GDT-YOLOV3网络结构Fig.4 Improved GDT-YOLOV3 network structure

(a)尺度1(a) Scale1

(b)尺度2(b) Scale2

(c)尺度3(c) Scale3图5 密集网络块结构图Fig.5 Dense network block structure
这3个Denseblock的具体结构如图5所示,首先设定x0为模块输入的特征图,xn为第n个模块的输出特征图,[x0,x1,x2...,xn-1]表示对x0,x1,x2...,xn-1的连接。H( )代表BN-RELU-CONV(3,3)与BN-RELU-CONV(1,1)的连接,Denseblock的计算公式为:
xn=Hn([x0,x1,....,xn-1]),n=1,2.....,8 .
(3)
通过推导得出,更改后的Dense-YOLOV3网络结构将会在尺度2的预测网络中输入2 304个特征图,在尺度3的预测网络中输入4 608个特征图,在尺度1的预测网络中输入2 560个特征图。
5 实验结果与分析
本实验分别选用另外4种网络进行了实验仿真。实验的软硬件平台配置如下:深度学习框架是darknet53和caffe;操作系统是ubuntu16.04.2,cuda版本是8.0.44;电脑配置是I7-800CPU,16 G RAM;显卡是NVIDIA GeForce GTX 1070Ti。
5.1 网络的训练
本文采用了动量项是0.9的异步随机梯度下降,设置subdivisions为16,权重的衰减系数为5×10-5,权值的初始学习率为10-3,由于显卡的限制,在训练阶段设置batch=32,每次训练的batch是32/16=2,输入的图像大小为416×416。在SSD512网络、YOLOV2、YOLOV3网络和改进的GDT-YOLOV3分别训练350 000次,分别在简单和复杂交通场景下进行试验。测试结果表明,当对网络训练的迭代次数超过一定值时,则会出现过拟合的现象,为了以后测试最佳权重文件更方便,在训练时本文选择每40 000次迭代保存一次网络的权重文件。选择的测试集为前2 000张图片,使用4种网络分别对其所有的权重进行测试,计算召回率的公式为:
R=Tp/(Tp+FN),
(4)
式中:Tp表示正确检测出来的目标个数;FN代表没有被检测出来的目标个数。测试的部分结果如表2所示。

表2 部分网络召回率与迭代次数关系的对比
从表2可以看出,YOLOV3网络迭代最好的次数为300 000次左右,改进的GDT-YOLOV3网络迭代最好也是在260 000左右,可以发现改进的GDT-YOLOV3网络在检测目标时要比YOLOV2、YOLOV3网络和SSD512网络的效果好。
5.2 检测效果对比
本文选取了4种网络的最佳迭代次数对4种网络进行对比与测试。表3为本文的网络检测模型与其他优秀的目标检测模型的检测精度对比,所有的模型都是采用混合训练集训练的。其中本文的模型检测精度要远高于SSD512网络、YOLOV2和YOLOV3网络,虽然检测速度不如YOLOV3和YOLOV2,但也完全满足既实时又准确的要求。
本文对2 000张图像进行测试,用这4种网络对图像中的目标进行检测。实验结果表明,4种网络均能准确地检测出道路上的车辆、电动车和行人,虽然原始的SSD512,YOLOV2、YOLOV3网络都有较高的检测速度,但是与本文改进的GDT-YOLOV3网络的检测精度和速度相比,可发现其他4种网络明显不如本文改进的网络模型,而且GDT-YOLOV3网络几乎不会发生误检和漏检现象,实验效果如图6和图7所示。

表3 不同检测模型精度的对比Tab.3 Comparison of the accuracy of different detection models

(a)原图像(a) original image

(b)SSD512网络(b) SSD512 network
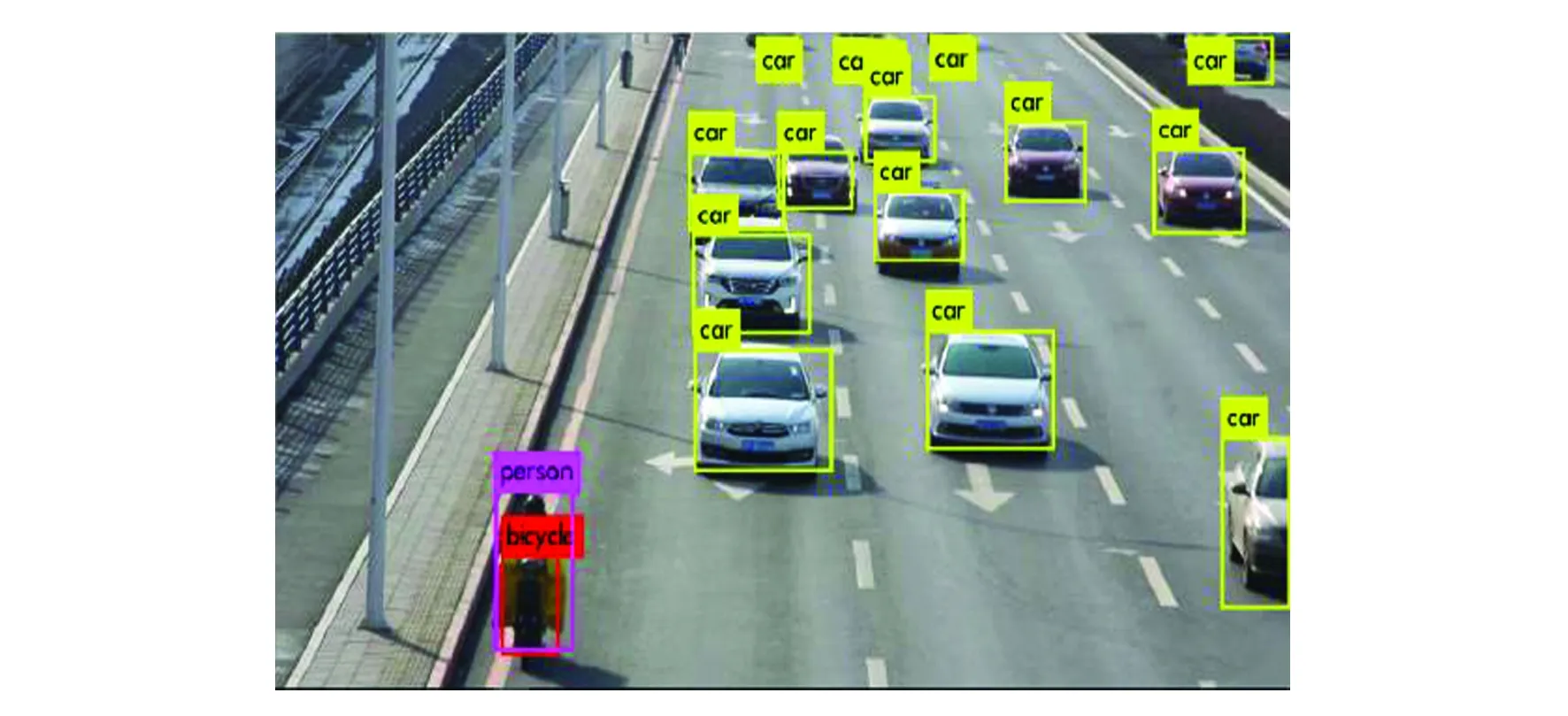
(c)YOLOV2网络(c) YOLOV2 network

(d) YOLOV3网络(d) YOLOV3 network

(e) 改进的GDT-YOLOV3网络(e) Improved GDT-YOLOV3 network图6 简单交通情境下实验检测的对比结果图Fig.6 Comparison results of experimental tests in a simple traffic situation
这2 000张图片包含51 700个目标,用这4种网络在数据集上进行测试,然后计算检测5种目标类别的准确率,准确率的计算公式:
P=Tp/(Tp+Fp)
.
(5)

(a)原图像(a) Original image

(b)SSD512网络(b) SSD512 network

(c)YOLOV2网络(c) YOLOV2 network

(d)YOLOV3网络(d) YOLOV3 network

(e)改进的GDT-YOLOV3网络(e) Improved GDT-YOLOV3 network图7 复杂交通情境下实验检测的对比结果图Fig.7 Comparison results of experimental tests in complex traffic situations
经过计算得出SSD512网络误检车辆个数为6 260个,行人误检个数为7 468个,电动车误检个数12 811个,公共汽车误检个数为9 864个,卡车误检个数为11 270个;YOLOV2网络车辆误检车辆个数为3 282个,行人误检个数为3 955个,电动车误检个数10 567个,公共汽车误检个数为8 358个,卡车误检个数为9 471个;YOLOV3网络误检车辆的个数为2 476,行人的误检个数为3 541,电动车误检个数为7 160个,公共汽车误检个数为6 969个,卡车误检个数为6 653个;GDT-YOLOv3网络误检车辆的个数为1 897,行人的误检个数为2 078,电动车误检个数为4 027个,公共汽车误检个数为5 378个,卡车误检个数为5 315个。从实验结果可知,本文改进的GDT-YOLOV3检测效果更好,与SSD512相比分别在车辆、行人、电动车、公共汽车和卡车的检测准确率分别提升了8.44%、10.46%、16.99%、8.66%、11.52%;与YOLOV2相比在车辆、行人、电动车、公共汽车和卡车的检测准确率分别提升了2.68%、3.63%、6.06%、5.8%、8.06%;与YOLOV3相比在车辆、行人、电动车、公共汽车和卡车的检测准确率提升了1.12%、2.83%、6.06%、3.06%、2.4%,检测速度满足需求。
6 结 论
本文采用K-means算法聚类初始目标边框,以YOLOV3算法为基础,根据混合数据集的特点,对网络进行了改进。本文设计了一种改进的GDT-YOLOV3网络,并分别对SSD512、YOLOV2及YOLOV3和改进的GDT-YOLOV3网络进行训练与测试。实验结果表明,本文方法的平均检出率与SSD512、YOLOV2、YOLOV3相比分别提高了11.22%、6.57%、2.11%,可以对交通场景下不同尺寸的目标有较高的检出率。但是本模型对更复杂的交通场景或重叠的运动目标检测效果不是特别好,在未来会将上述问题作为重点的研究方向。
