大数据环境下基于云计算的图书馆用户信息 挖掘技术研究
2020-08-03主雪梅杨洪秀魏荣华许雅涵
主雪梅 杨洪秀 魏荣华 许雅涵
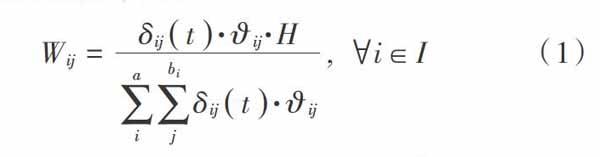
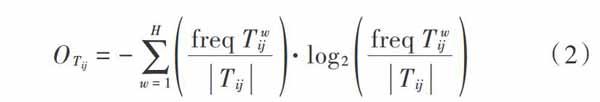

摘 要: 图书馆用户信息挖掘是提升图书馆管理效率,实现高质量用户管理与用户服务的有效方法。文中研究大数据环境下基于云计算的图书馆用户信息挖掘技术,构建图书馆用户信息挖掘技术结构体系。数据层包括用户基本信息、图书借阅历史数据、图书信息咨询记录等,采用降噪处理、遗漏数据处理等方式预处理用户信息数据;云计算层基于计算资源与存储资源,采用K?means聚类算法从用户借阅情况和用户兴趣类型两方面划分图书馆用户群体类型,依照划分后的用户借阅信息采用蚁群规则挖掘算法,获取用户信息关联规则,形成规则库;应用层依照云计算层的挖掘结果执行个性化推荐。用户信息挖掘结果显示,所研究技术能有效挖掘图书馆用户兴趣类型,以及用户群体信息和时间序列信息。
关键词: 图书馆用户; 信息挖掘; 云计算; 大数据环境; 用户分类; 个性化推荐
中图分类号: TN911.2?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2020)06?0168?03
Research on library user information mining technology based on cloud computing in large data environment
ZHU Xuemei1, YANG Hongxiu2, WEI Ronghua1, XU Yahan1
(1. Hebei University of Water Resources and Electric Engineering, Cangzhou 061001, China; 2. Cangzhou Normal University, Cangzhou 061001, China)
Abstract: Library user information mining is an effective method to promote library management efficiency, and realize high quality user management and user service. The library user information mining technology based on cloud computing in the big data environment is researched to build the structural system of the library user information mining technology. The data layer of the system includes user′s basic information, book borrowing historical data, book information consultation records and so on. The user information data is preprocessed with the modes of noise reduction processing and missing data processing. The cloud computing layer is based on computing resource and storage resource, in which the type of library user groups are divided into two aspects of users borrowing situation and users′interest type by means of the k?means clustering algorithm. According to the divided users borrowing information, the association rules of user information are obtained to form the rule base by means of the colony rule mining algorithm. The personalized recommendation is performed by the application layer on the basis of the mining results of the cloud computing layer. The mining results of user information show that the researched technology can effectively mine the interest types of library users, user group information and time series information.
Keywords: library user; information mining; cloud computing; big data environment; user classification; personalized recommendation
0 引 言
近年来,图书馆发展迅速,海量信息数据被存储在图书馆管理系统内[1]。在图书馆管理中,用户管理与用户服务始终是管理的核心内容,通过图书馆用户信息挖掘可研究图书馆用户群体的特征与关系[2]、增强图书馆对图书馆用户的吸引力、提升图书馆管理的效率[3],是高质量的用户管理与用户服务的基础之一。
为提升图书馆管理效率,实现高质量用户管理与用户服务,研究大数据环境下基于云计算的图书馆用户信息挖掘技术。云计算平台为大数据环境下图书馆用户信息数据特征分析和挖掘提供良好平台,其具有高效布置动态资源、依照用户需求实时计算与储存等功能[4]。实验结果显示,本文方法可有效挖掘出用户群体信息和时间序列信息,可为图书馆大数据用户信息特征挖掘提供有效手段,具有较好的应用前景。
1 图书馆用户信息挖掘技术研究
1.1 图书馆用户信息挖掘技术结构体系
大数据环境下基于云计算的图书馆用户信息挖掘技术结构体系分为三个层次,分别是数据层、云计算层和应用层。数据层作用是获取用户信息的数据来源,主要基于图书馆管理系统、OPAC(开放的公共查询目录)检索用户信息,并利用ODBC(开放数据库互连)或其他数据库接口获取图书馆用户信息[5];云计算层基于计算资源与存储资源,对预处理后的图书馆用户信息采用决策树、关联规则、神经网络、聚类、贝叶斯分类和回归等数据挖掘算法完成图书馆用户信息挖掘[6];应用层依照图书馆用户信息挖掘结果执行个性化推荐、学科化服务及馆藏资源布局与建设等相关管理。
1.2 基于聚类的图书馆用户群体划分
1.2.1 借阅情况聚类挖掘
从图书馆管理过程中可发现:部分用户对于图书馆的借阅需求较高,相比之下还有部分用户对图书馆不存在借阅需求[7]。根据图书馆用户借阅情况,采用聚类算法将图书馆用户划分为有所差异的组别。一个组别内,用户的书籍借阅分类大体一致,各组别之间用户的借阅书籍分类差异较为显著。借阅情况可反应用户借阅频率,采用K?means聚类算法挖掘图书馆用户借阅情况过程描述如下:
将聚类数K的取值范围设定为[2,8],分别确定图书馆用户划分对应的聚类情况,由此得到K取值越小簇涵盖范围越大,个别簇内数据达到总数据的70%以上,由此得到的聚类结果无效;K取值越大统计数据精度越低,簇内整体反应精度差,图书馆用户类型划分较为分散,降低后续关联规则可操作性。经过调整K值,将K值确定为3,也就是将图书馆用户划分为3个大类。
1.2.2 兴趣类型聚类挖掘
根据读者兴趣类型聚类挖掘的过程如下:在数据层内采集用户ID、用户类别以及用户所属科院等用户信息;聚类用户信息时重复调整K值,获取最优聚类数为7个大类。
依照有所差异的借阅信息将图书馆用户划分成不同的类别,且相同类别内用户借阅信息相似。在用户信息聚类结果的基础上,获取各类别中详细的书籍借阅信息,依照这些被划分后的用户借阅信息采用关联挖掘技术,获取关联规则,形成规则库,以便完成馆藏资源布局与建设等相关管理,并向读者提供个性化推荐服务[8]。
1.3 关联规则挖掘算法
利用蚁群规则挖掘算法挖据图书馆用户信息关联规则构造一条路径[9]。路径选择过程中,蚂蚁以一条空规则为基础构建图书馆用户信息规则库,构建过程中每次在规则库内增设一个term,各term均为蚂蚁所选择的路径。下一个增设的term为蚂蚁下一条选择路径,蚂蚁持续在规则库内增设term。当规则库内包含全部的图书馆用户信息属性,或增设一个新的term导致规则所包含的用户信息低于预先设定的各规则包含用户信息最小值时,增设term工作结束。螞蚁依照当前路径的启发函数和路径上信息素值[10]选取下一条路径,一个[termij]被选为当前规则的概率为:
式中:[?ij]和[δijt]分别表示[termij]个启发函数值和[termij]上的信息素值;[a]表示属性i应用的属性数量;[bi]表示属性j数量;[I]表示属性i的整体属性数量;[H]表示类别约束参数。用户[Tij]选择图书时,用户信息挖掘结果[OTij]表达式如下:
式中,[freq Twij]和[Tij]分别表示保护类别为[w]的用户信息的数量和用户[Tij]在图书馆用户信息的数量。
2 结果分析
实验为验证本文研究的大数据环境下基于云计算的图书馆用户信息挖掘技术的挖掘性能,以某高校图书馆为实验对象,采用本文挖掘技术,从图书馆用户兴趣类型关联规则挖掘结果、用户群体信息挖掘结果和时间序列信息结果三方面挖掘实验对象用户信息。
2.1 用户兴趣类型关联规则挖掘结果
采用本文技术挖掘实验对象用户兴趣类型聚类结果中的关联规则,得到的结果如图1所示。由关联规则挖掘结果得到,采用本文技术能够有效挖掘图书馆用户兴趣类型,可根据当前用户数据借阅信息,挖掘出符合用户兴趣偏好的书籍,实现个性化推荐功能。
2.2 用户群体信息挖掘结果
在挖掘高校图书馆用户信息时,专业素养的高低是影响用户借阅的主要因素之一。通常用户借阅图书的类型、数量受用户专业素养与学历水平影响较为显著。根据当前教学体制结构,可从学历上将高校在校人员分为教师群体、研究生群体和本科生群体。针对这三类群体进行实验对象用户信息挖掘,在2018年理科学院到图书馆借阅图书的不同类型图书馆用户如表 1所示。
根据图书馆用户群体信息挖掘结果得到,在总图书借阅人数中,本科生群体是图书借阅的主要群体,借阅人数达到80.29%;教师群体在图书借阅人数中所占比例仅为1.12%。对比平均借阅量得到,本科生群体平均借阅量最低,教师群体平均借阅量最高,两个群体的平均借阅量分别为9.36本和13.29本。实验结果表明本文技术能够有效挖掘实验对象用户群体信息。
2.3 时间序列信息挖掘结果
图2为用户时间序列信息挖掘结果。
根据用户时间序列挖掘结果可得不同学院2018年图书馆用户在借阅图书的时间特征。从整体上对比两个不同科类学院用户图书借阅特征大致相同:每年图书借阅量最高的月份和最低的月份分别是3月、9月和7月、8月;理科学院用户借阅量最高值和最低值分别为1 916本和270本;文科学院用户借阅量最高值和最低值分别为7 481本和1 093本。每年的3月和9月均为学校开学月,而7月和8月则为学校放假时间。
由上述分析可知,不同学科用户图书借阅信息存在共性特征,即开学月为图书借阅的高峰期,放假月为图书借阅的低潮期。文科学院5月份的借阅量呈现出一个小高峰主要原因在于该月中安排了每年本科大四学生的毕业答辩,此时以学术类文献为用户图书借阅的主要类型。每年的7月和8月是图书借阅量最低的月份,主要原因是这两个月为学校暑假放假阶段,虽然2月份也为寒假放假期间,但相比之下,7月和8月图书借阅量低于2月份图书借阅量,主要原因是7月和8月,本科大四学生毕业离校,图书馆用户相对降低。除上述分析月份外的其他月份中图书馆用户借阅量表现为无规律变化状态。结果表明,本文技术挖掘的实验对象用户时间序列信息与实际情况对应,验证了本文技术挖掘图书馆用户信息的准确性。
3 结 论
本文研究大数据环境下基于云计算的图书馆用户信息挖掘技术,构建图书馆用户信息挖掘技术结构体系,由数据层、云计算层和应用层构成。其中云计算层采用K?means聚类算法划分图书馆用户群体,在聚类结果的基础上采用蚁群规则挖掘算法实现图书馆用户信息关联规则挖掘。用户信息挖掘结果显示本文技术能够有效挖掘图书馆用户信息,实现个性化推荐功能。
参考文献
[1] 季忠洋,李北伟,朱婧祎.智慧图书馆用户使用行为影响因素研究[J].图书馆,2018(12):21?25.
[2] 王欣,张冬梅,闫凤云,等.大数据环境下基于科研用户小数据的图书馆个性化科研服务研究[J].情报理论与实践,2017,40(10):85?90.
[3] 王捷.基于用户行为数据分析的高校图书馆信息服务平台研究[J].现代情报,2017,37(1):128?131.
[4] 申琢.基于云计算和大数据挖掘的矿山事故预警系统研究与设计[J].中国煤炭,2017,43(12):109?114.
[5] 张稳,罗可.一种基于Spark框架的并行FP?Growth挖掘算法[J].计算机工程与科学,2017,39(8):1403?1409.
[6] 施航海,叶瑞哲,许卓斌.大数据环境下图书馆用户个人的信息保护研究[J].微电子学与计算机,2018,35(5):138?140.
[7] 王福,梁玉芳.移动图书馆用户信息行为对情境的作用机理研究[J].图书馆,2018(7):80?87.
[8] 戴咏梅.互联网思维下高校图书馆用户信息渠道研究[J].大学图书馆学报,2016,34(3):75?84.
[9] 陈廉芳.大数据环境下图書馆用户小数据的采集、分析与应用[J].国家图书馆学刊,2016,25(3):69?74.
[10] 陈小平.基于区块链理念的图书馆移动用户行为大数据挖掘研究[J].图书馆工作与研究,2018(12):65?70.