基于gcForest的多因子量化选股策略
2020-08-03王伦,李路
王 伦,李 路
上海工程技术大学 数理与统计学院,上海 201620
1 引言
近年来,有关股票预测的理论发展日趋激烈。从早期有效市场假说、随机漫步[1]理论,后来随着量化投资的发展,金融股票交易越来越多地和机器学习产生紧密联系。所谓量化选股[2],是指选择合适的选股指标体系[3],使用机器学习中相关算法,选出优质股票,其本质是数据挖掘领域[4]的分类问题。
在过去十几年中,已经有多种机器学习算法应用于股票市场的预测问题。刘道文等[5]在基于支持向量机的基础上,以交叉验证方法确定了最佳回归参数的选取问题,同时做了股票价格指数的预测,研究结果表明支持向量机能够准确地反映股票价格指数的变化趋势。王淑燕等[6]使用指标相关性分析方法,提出了八因子选股模型,然后利用随机森林算法验证了该模型在中国股票市场上的有效性。Kumar等[7]将支持向量机与遗传算法结合起来,并将该结合方法应用于股市领域进行股价预测,结果表明该算法进行的预测准确性高于单一支持向量机。虽然机器学习相关算法在分类问题有着出色的表现,但在投资领域的股价涨跌问题的预测准确性上依然没有达到理想效果。
gcForest(multi-Grained Cascade forest,多粒度级联森林,又称深度森林)是Zhou[8]在2017年提出的新的决策树集成方法。该算法是在深度学习理论的启发下,以随机森林算法为基础的一种有监督的集成机器学习算法。gcForest算法提出至今,已被应用于多个领域。朱晓妤等[9]首先用多粒度扫描结构提取了火焰的抽象特征,然后利用深度森林模型进行火焰检测,实验结果表明该方法能够提高火焰检测率,并且具有强鲁棒性。刘超[10]提出一种混合采样不平衡数据集成分类算法,使用SMOTE[11]算法合成新的少数样本后,在此基础上验证了gcForest算法比逻辑斯蒂回归和随机森林算法具有更高的准确性。宫振华等[12]根据每种森林的预测精度分别对级联层中每个森林进行加权,由此提出了一种加权的深度森林算法,证实了加权的深度森林在高维和低维数据集上性能都获得一定提升。
由于传统机器学习算法在股票市场的预测问题上并没有到达理想效果,而gcForest模型则具有模型复杂度小,参数设定少等优点,同时鉴于gcForest算法在诸多领域[8-10,12]的都达到了预期的效果,为了追求更高的超额收益,本文将建立基于gcForest的多因子量化选股模型来探索股票市场。
2 gcForest算法分析
gcForest模型把训练分成两个阶段:多粒度扫描(Multi-Grained Scanning)和级联森林(Cascade Forest)。多粒度扫描阶段生成特征,级联森林阶段经过多个级联层得出预测结果。
在处理序列数据处中,多粒度扫描就是用多个滑动窗口对原始输入数据进行扫描,并通过随机森林和完全随机森林两种森林模型获得级联森林的输入数据。每个完全随机森林包含500(参数可调)棵完全随机树(complete-random trees),每棵完全随机树通过随机选择一个特征在树的节点进行分裂,直到每个叶节点的实例都属于同一类;每个随机森林也包含500棵决策树,每棵决策树随机选择输入的总特征)个特征生成,并且每次选择具有最佳的基尼值的特征进行分裂。
如图1中所示,序列数据特征为400维,滑动窗口大小选择为100,滑动步长为1,通过滑动窗口将得到301个100维的实例数据。提取的实例数据将应用于森林模型的训练,假设有三类要预测,每个实例通过森林模型会得到三维的类别概率向量,每个森林训练得到301个3维的类别概率向量,最后将两个森林得到类别概率向量按顺序拼接成1 806维的序列数据作为级联森林的输入向量。
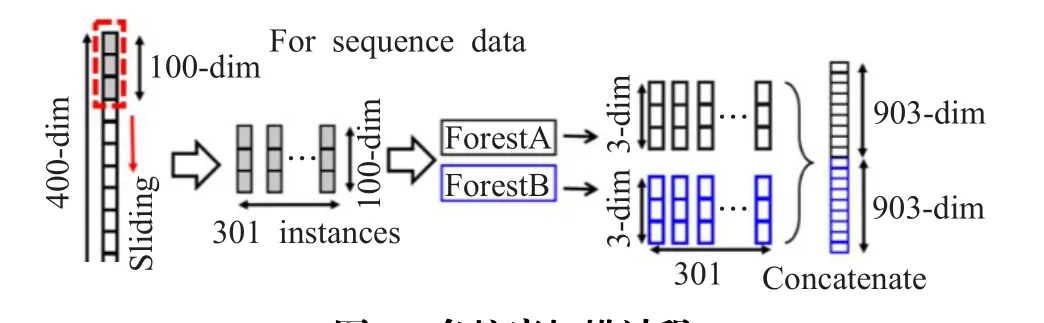
图1 多粒度扫描过程
图2 中级联森林主要由随机森林和完全随机森林构成。对于每一层的森林模型,首先,训练样本通过k折交叉验证训练每个森林,同时每个森林都会输出一个预测的类别概率向量;然后将该层中所有森林输出的类别概率向量与样本的原始输入向量拼接后作为级联森林下一层的输入向量。每层结束后,都会在测试集上对预测结果进行检测,以决定是否产生下一层。最后将输出的类别概率向量算术平均后,取概率最高的类作为gcForest模型的最终预测结果。

图2 级联森林过程
3 gcForest多因子选股策略
3.1 数据处理
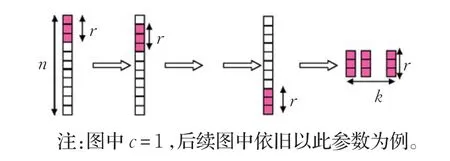
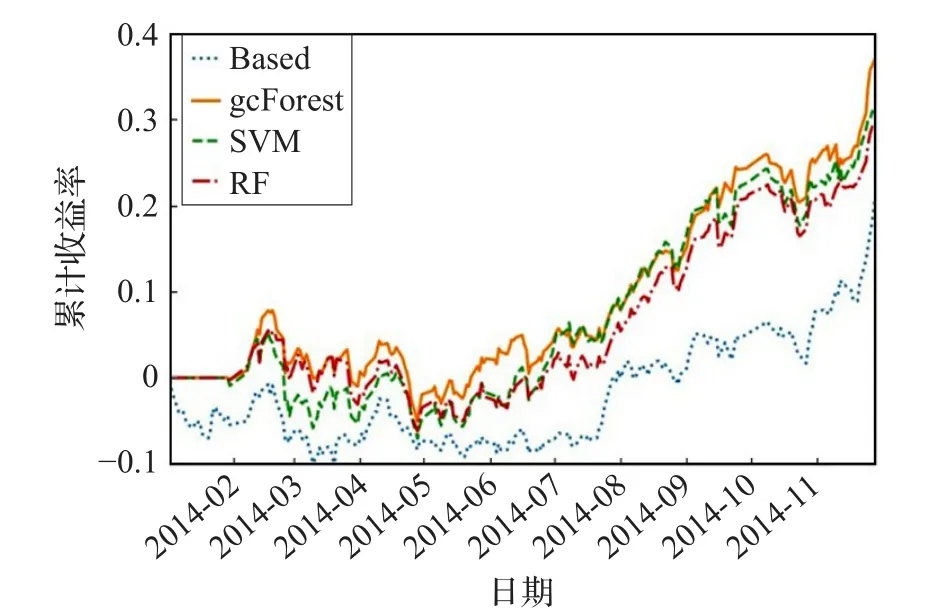
取沪深300成分股数据起始时间为t0,终止时间为t2,中间时间t1,满足t0 (1)设训练集整体股票数据 记xi=[xi1,xi2,…,xin]为第i行某只股票的全部因子,其中xij表示第i行某只股票的第j个因子,y=[y1,y2,…,ym]为股票的月收益率。z=[z1,z2,…,zm]为股票收益率标签,其中: 当股票的月收益率yi>0时,zi=1;当股票的月收益率yi<0时,zi=0。 (2)删除含有缺失值的股票数据。 (3)对股票数据进行归一化处理: 其中,x·j表示每只股票第j个因子的所有数据。 3.2.1 选股模型多粒度扫描结构 对于序列数据样本而言,预测模型尽可能地有效地处理样本的特征,将有利于提高算法的准确性[8]。为提高gcForest算法中级联森林阶段的股票涨跌的预测效果,这里设置了多粒度扫描过程对股票数据的因子进行特征提取。 (1)卷积层 图3所示为一只股票的所有因子数据xi,收益率标签zi,选股模型要解决的问题为2分类问题。设置1个r维的向量窗口在原始股票数据xi上进行滑动取值,步长为c,则可获得k(k=向下取整符号)个r维向量,将所得的向量均标记为zi。 图3 多粒度扫描卷积层 (2)森林层 对于股票数据集X,总共有m只股票因子数据xi,按照图3步骤处理完每只股票数据,然后分别经过两种森林模型学习(图4所示),确定完全随机森林模和随机森林模型。 图4 多粒度扫描中森林模型的构建 (3)输出层 图5中展示的是股票数据xi经过卷积层后,将得到的k个r维向量分别经两种森林模型进行分类处理,每个森林得到k个2维类别概率向量。最后每个森林将所有的类别概率向量按顺序拼接组成一条新的4×k维特征向量ai(标签为zi),作为级联森林的输入。对于整体股票数据X,得到的是一个新的股票数据集: 图5 多粒度扫描输出层 3.2.2 选股模型级联森林结构 在级联森林中,每一层都从上一层获取经过处理后股票的特征信息,并利用股票特征信息产生出新的股票特征信息传递至下一层。随后每一层都将上一层的输出的股票特征结果的类别概率向量与原始输入级联森林的股票数据拼接作为自身的输入。 首先将多粒度扫描阶段生成的股票数据集A分别经过级联层1中(图6所示)的四个森林模型进行学习训练,确定每个森林模型。 图6 级联层森林模型确定过程 图7 级联森林整体流程 图7 中所示为经过多粒度扫描阶段生成的股票特征向量ai经过级联层1中的4个森林模型后,会得到4个2维的类别概率向量,将其按顺序拼接得到新的8维增强特征向量bi(gcForest模型[8]认为这4个2维类向量能够有效地反映样本的特性,将其称为增强特征向量)。接着,增强特征向量bi将与级联森林的原始输入向量a拼接组成4×k+8维的特征向量作为下i一层的输入,依此方法直至进行到级联森林的最后一层。最后对产生的类别概率向量取平均值,再取其中最大值所对应的类别作为股票的分类结果。 3.2.3 选股模型迭代终止条件 级联森林的层数为gcForest模型的深度,gcForest算法在训练级联森林时可由算法自动确定级联森林的层数。设级联层N中4个森林产生的类别概率向量取平均值后对应股票的分类标签为。 定义函数Acc(h1,h2),表示两个同维向量h1,h2中相同位置zN=[ ]zN1,zN2,…,zNm元素相等的个数所占的比例,例如: 则级联层每层检验的准确率: 每当级联森林训练层数增加一层后,都会用样本数据对级联森林的性能进行检测,如果准确率dN 3.2.4 gcForest策略回测 本次回测采用每月月末交易,每次交易前卖出所有持仓股票,然后根据股票得分买入得分排名前30只的股票。 (1)确定股票得分si,根据级联森林最后的输出层的结果中选取预测股票标签zi=1的股票的概率,si=P(zi=1|xi)。 (2)将si从大到小进行排序,取前30只股票,将这30只股票的得分记做s1,s2,…,s30,计算买入股票的权重gi: 其中,M为资金量,ci为每月末第i只股票价格。 在因子选择方面,为了比较不同类型因子选择方法的效果,综合多篇文献分析[13-14]结果,在优矿网上,从交易量因子、估值因子、规模因子、动量因子等几个方面选取了34个有效因子,见表1,相关因子详细说明请参考https://uqer.io。 实验数据[t0,t2]是2009年1月1日至2017年12月31日期间沪深300成分股所有股票每月最后一个交易日的股票因子值和每月收益率。[t0,t1]为2009年1月1日至2016年3月31日的数据将被作为训练集来训练模型,(t1,t2]为2016年4月1日到2017年12月31日的数据用于回测部分。所有股票数据经过归一化处理,并去掉了包含缺失值的股票数据,剩余股票数据为19 796条。 表1 gcForest策略因子表 Zhou在文献[8]中介绍了gcForest算法较深度神经网络算法的一大优势,即无需大量设置参数和调参。鉴于gcForest算法在文献[8-10,12]中使用的常用参数都取得了良好的结果,因此这里也采用常用参数设置。 表2中展示的是gcForest在不同窗口下的样本检验结果,可以看出在不同窗口选取的情况下,其样本检验结果的准确率约为0.54,误差不超过0.02,因此窗口的选取原则对实验最终结果影响不大。 表2 深度森林算法中不同扫描窗口的样本检验结果 为了避免和深度学习[15-17]模型一样需要大量调参,最终窗口选取原则是按照常用方法,即按照Zhou在文献[8]中(n为一条股票数据的维度)选取三个大小的多窗口模式,具体参数设定见表3。 表3 深度森林算法中超参数的设置 图8展示是实证gcForest整体流程,原始输入的是一只34维的股票数据,准备了8、16、24三个大小的滑动窗口进行采样,股票分类为2分类问题,经过多粒度扫描过程后分别产生92、72、44维特征向量,将所有特征向量按顺序拼接成212维的特征向量作为级联森林的输入向量。级联森林每层输出的是长度为8的类别概率向量,这个8维类别概率向量与212维的级联森林输入向量拼接在一起作为级联森林下一层的输入向量,这样层层传递下去,直到检验停止继续加深层数。 图8 实证gcForest整体流程(RF:随机森林,CRF:完全随机森林) 表4中所示为级联森林层数的迭代过程,从表4中可以看出级联层在第3层时终止训练,确定级联森林的层数为2。 表4 样本准确率检验结果 为了更好地衡量深度森林(gcForest)算法在股票市场的表现,本文将深度森林模型实证结果和随机森林[18](Random Forest,RF)、支持向量机[19](SVM)算法进行了比较。表5展示了三种策略和沪深300股票收益指标和风险绩效指标。 表5 三种算法在中国A股市场的投资绩效 首先,这三种基于机器学习的投资策略的年化收益率都是高于基准年化收益的,年化收益最高的为gcForest模型的29.2%,高于基准的2倍左右。 其次,从阿尔法超额收益上来看,gcForest位于第一,结果为15.8%,而RF模型的超额收益只有2.4%。 三种算法中,最大回撤较高一点的为RF模型的9.4%,gcForest和SVM分别为6.6%,5.9%,说明其他两种算法可以更有效地防范回撤风险。 最后从夏普比率看,gcForest的夏普比率明显高于其他两种算法,说明在承担同样的风险系数下,gcForest可以更好帮助投资者作出有效的投资决策,获取更高的收益率。综合各种指标来看,gcForest较其他两种算法都具有一定的优势。 图9绘制gcForest、RF、SVM三种策略的累计收益率。可以看出,在三种策略中gcForest的累计收益率最高,超过50%,然后是SVM策略,累计收益率超过40%,最后则为RF,基本和基准线相同。整体来看,gcForest策略在沪深300指数稳健趋势中,能够较好地控制回撤,同时也能有效地抓住证券上涨的机会,获取更多的超额收益。 图9 基准、gcForest、SVM、RF策略累计收益率(股市行情上涨时期) 从图9沪深300基准线可以看出,2017年股市行情较好,基本处于上涨阶段,为了比较不同时期股票市场三种策略的收益情况,另外选取了股市行情较为平稳时期的2014年,和股市行情下跌时期2015年(股灾)的数据进行回测。 图10所示为三种策略在股市行情平稳时期的2014年的累计收益率情况,可以看到gcForest策略依然处于领先地位,此时仍能获取更高的超额收益;图11中所示为三种策略在股市行情下跌时期2015年的回测结果,此时获取的最大累积收益率为SVM策略,其次为gcForest策略。因此结合图10、图11和图9中结果结可以得出,gcForest策略在股市行情平稳和上涨时期能够更好地发挥其优势,投资者应抓住机会,根据股市行情合理选择投资策略。 图10 基准、gcForest、SVM、RF策略累计收益率(股市行情平稳时期) 图11 基准、gcForest、SVM、RF策略累计收益率(股市行情下跌时期) 多因子量化选股利用有效因子设计相应的投资策略建立有效的投资组合,以寻求超额收益。本文通过利用gcForest算法进行量化选股,并与支持向量机和随机森林算法进行比较,以股票因子数据作为算法的输入,输出对未来股票价格形式的预测,并通过预测结果建立相应投资组合。实证结果显示:gcForest算法在股市行情平稳和上涨的时期无论从风险还是收益角度均较其他两种模型有一定的优势,并且在样本检测的预测准确率高达55%,显著高于50%的随机概率。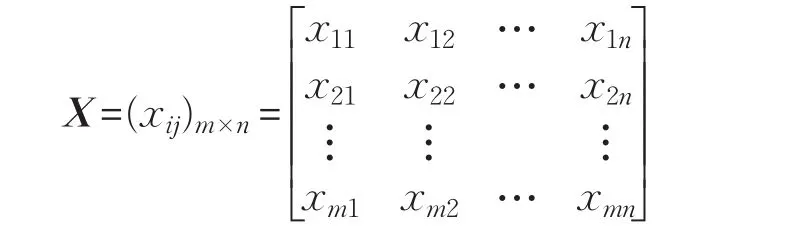

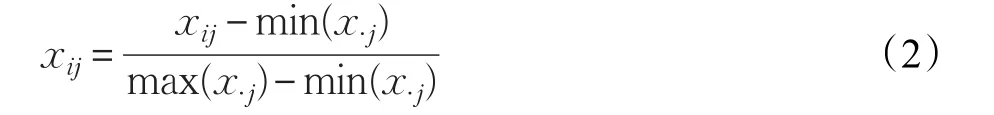
3.2 gcForest选股模型








4 实证分析
4.1 gcForest策略实证





4.2 gcForest、支持向量机、随机森林回测结果比较


4.3 gcForest策略不同时期的有效性分析

5 结论
