基于Huffman编码的区域控制器记录数据压缩算法的研究
2020-08-03王福源雷成健任建新
王福源,雷成健,任建新
(1.湖南中车时代通信信号有限公司,湖南 长沙 410005;2.湖南铁路科技职业技术学院,湖南 株洲 412001)
0 引言
区域控制器(zone controller, ZC)系统是负责城轨列车安全运行的关键信号设备之一。在城市轨道交通信号系统的应用中,ZC系统根据列车所汇报的位置信息以及联锁所排列的进路和轨旁设备提供的占用/空闲信息,实时地为通信列车计算移动授权,从而确保列车之间的安全追踪,是基于通信的列车控制(communication based train control,CBTC)系统中列车自动保护(automatic train protection, ATP)的轨旁部分[1]。ZC系统为全天候连续工作设备,工作期间实时、不间断地发送和接收各种数据信息并计算存储,其承担的信息量大、数据多[2]。在实际工作中,ZC系统日志最高可产生的数据量达每天10 GB,对存储和转储工作带来较大压力。此前,针对此类数据压缩处理方法的研究较少,为此,本文提出了一种软件压缩算法对其进行处理[3]。
1 数据压缩
数据压缩是一个减小数据存储空间的过程,是信息论的最重要成果之一,其利用数学工具采用多种方法来管理和处理信息[4]。按照压缩精度划分,数据压缩一般有无损压缩和有损压缩两种。在有损压缩算法中,可以接受一定的损失,用以换取更大的压缩比。在某些应用中,如图像处理和音频处理,一定的损失是可以接受的,因为这种损失会受到严格控制,不会影响播放效果。而ZC系统日志数据需采用无损压缩,以保证解压缩时准确地还原原始数据。无损压缩数据算法,典型的有算术编码、RLE算法、LZ算法和Huffman算法。其中算术编码运算复杂、速度慢,主要用于图像处理;LZ系列算法需要构建索引字符串字典,字典通常会很大;RLE算法主要是对数据块进行压缩运算;而Huffman编码是通过构造Huffman树来进行编码的,适用于文件处理,特别是对字符数据的编码。ZC日志数据具有标志位多、状态位多及重复率高[5-6]的特点,故本研究选用针对数据文件处理的基于Huffman编码的无损压缩算法。
1.1 Huffman编码
Huffman编码是基于最小冗余编码的数据压缩算法。最小冗余编码指的是,如果能统计出一组数据中所有符号的出现频率,就用一种特定的方法来表示符号,以减少存储数据所需的空间。对出现频率高的符号,编码使用尽可能少的位来表示;对出现频率低的符号,编码使用尽可能多的位来表示[7]。在数据中,所表示的符号不一定要占用一个字节,经过重新编码,可以是任意大小的数据[8]。
1.2 熵和最小冗余
要使用Huffman编码,需了解熵的概念。熵的作用是量化数据信息。信息的概念很抽象,此前人们无法精确指出信息量到底有多少,直到1948年,数学家香农定义了“信息熵”,信息的量化问题因此得以解决。他首次利用数学语言阐明了概率与信息冗余度的关系:任何数据信息都有冗余,冗余的大小与数据信息中每个符号出现的概率有关[9]。
任何数据集合的信息量都是一定的,即所谓熵。对于一组数据而言,熵就是这组数据中每个符号熵的总和。具体而言,熵有如下定义:
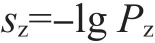
式中:PZ——符号z在数据集中出现的概率。
如果确切知道z出现了多少次,就知道z出现的频率[10]。例如,如果一个40个符号的数据集合中z出现了10次,即出现的概率为1/4,于是z的熵sz=-lg(1/4)=2位。由此可知,如果在数据集中用来表示符号z使用了超过两位的二进制数,这将是一种浪费。目前一般都用一个字节来表示一个符号,在这种情况下使用合适的数据压缩算法可以很大程度地减小数据的容量,即通过重新编码,可以实现使用较少的位对出现频率高的符号编码,用较多的位对出现频率低的符号编码。
2 压缩算法的实现
2.1 数据压缩过程解析
数据压缩包括两个过程:一是压缩或编码数据,使数据容量减小;二是解压缩或解码数据,使数据还原到本身的状态[11]。
(1)压缩部分
压缩部分采取单输入单输出结构,输入为需要压缩的数据地址,输出为压缩后的数据地址。压缩部分按照字节长度对数据进行压缩,压缩字符数最大为256个,其按照每包最大1 400个字节进行压缩,且能持续压缩,直至目标文件全部执行完毕。
(2)解压缩部分
解压缩部分采取单输入单输出结构,输入为需要解压缩的数据地址,输出为解压缩后的数据地址。解压缩部分按照字节长度对数据进行解压缩,解压缩字符数最大为256个,其按照每包最大1 400个字节进行解压缩,且能持续解压缩,直至目标文件全部执行完毕。
2.2 算法的具体实现
ZC日志记录软件中的Huffman压缩算法采用分包压缩和循环压缩的方法。将数据包按字节输入,每包数据最大有256个字符;压缩后重新按字节组成数据包输出,具体的Huffman数据压缩软件流程如图1所示[12-13]。
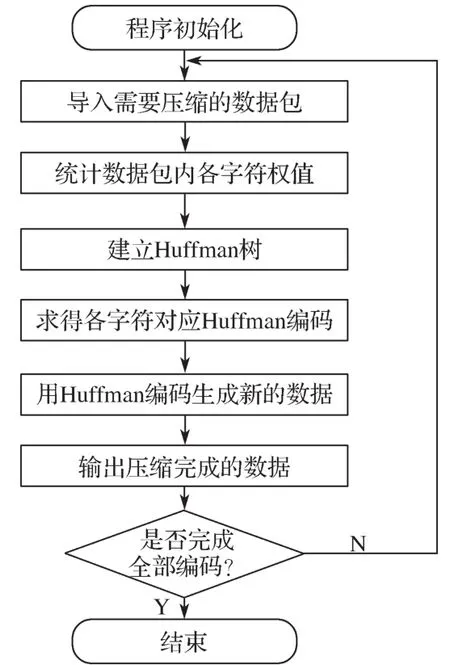
图1 Huffman数据压缩软件流程Fig. 1 Flowchart of Huffman data compression software
解压缩算法同样采用分包解压缩和循环解压缩的方法。将需要解压缩的数据包按字节输入,组成新的字符串后根据Huffman编码解压缩;解压缩完成后依然按字节组成数据包输出[14]。具体的Huffman数据解压缩软件流程如图2所示。
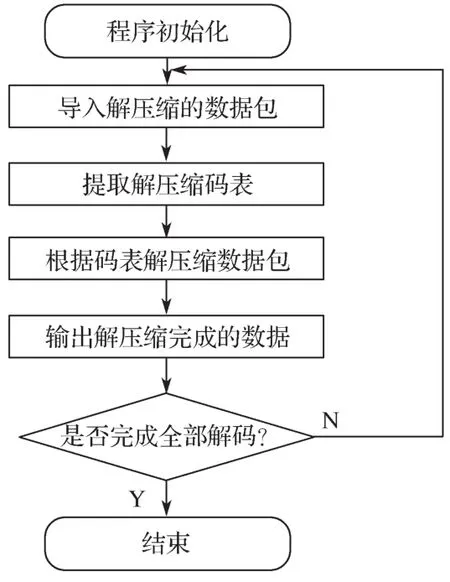
图2 Huffman数据解压缩软件流程Fig. 2 Flowchart of Huffman data decompression software
ZC日志记录软件中的Huffman压缩算法部分代码截图如图3所示。压缩过程中,对相关模块采用必要的模块化封装,以保证该软件算法的独立性。
图3 部分代码截图Fig. 3 Partial code screenshot
3 应用结果及分析
根据Huffman压缩算法的特性可知,被压缩数据包内字符数越少,字符重复率越高,压缩率越高[15]。软件编写完成之后,进行了多次调试与实验,以验证软件可用性和实际的压缩效果。下面设定3组实验进行验证。
(1)实验一
数据集中字符的频率和种类都能对数据压缩效果产生影响。本实验是为了测试字符频率的变化对Huffman压缩算法的影响。首先,设置一个包含1 400个字节的数据包,设定其中各字符权值相等;其次,从2个字符到256个字符依次实验,将数据包压缩之后再进行解压缩;确认压缩数据无误,将压缩后数据包字节数记录下来并统计压缩前后数据字节变化。实验结果如图4所示。可以看出,在各字符权值相等的情况下,压缩变比随着字符数增多而趋于减小,说明在各字符权值相同的情况下,Huffman编码依然能够对数据进行有效的压缩。根据Huffman编码理论,字符重复率越高,Huffman编码压缩效果越好。
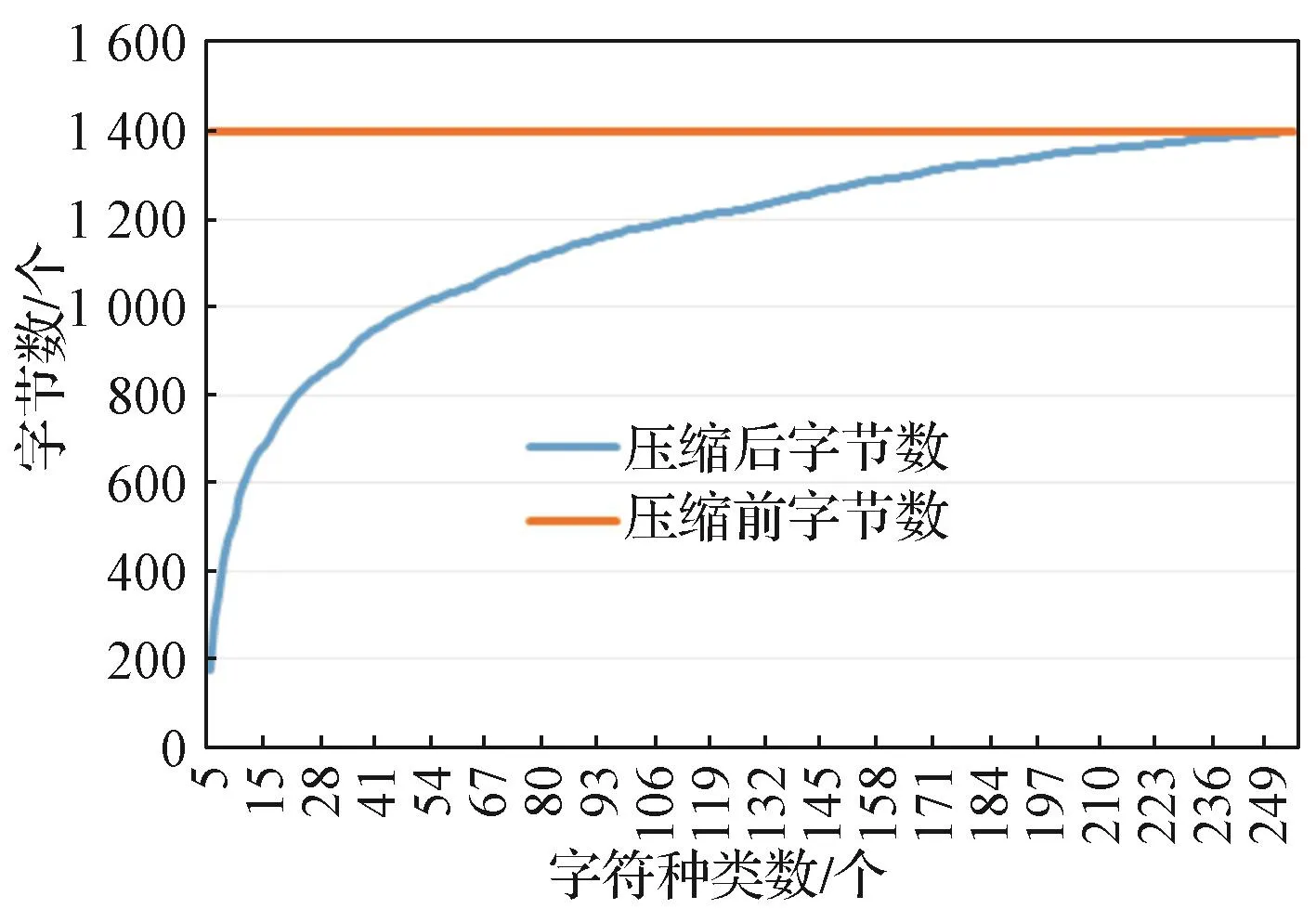
图4 实验一压缩变比图Fig. 4 Compression transformation diagram of the experiment 1
(2)实验二
为了测试字符种类的变化对Huffman压缩算法的影响,设置一个包含1 400个字节的数据包,其恒定含有256个字符(0x00~0xFF)。设定每个字符重复率一样,进行压缩、解压缩实验;然后设定其重复率按比例上升,共进行5次实验,分别将数据包压缩之后再进行解压缩;确认压缩数据无误,再次将压缩后数据包字节数记录下来。其压缩变比如图5所示。可以发现,随着数据重复率比例的升高,Huffman算法压缩后数据包越小,压缩效果越好;而实际ZC日志记录数据中,按照通信协议,有大量的重复数据,如0x00/0x01/0xFF/ 0x55/0xAA等,这说明Huffman压缩算法在本应用中压缩效果是确实可行的,且数据重复率越高、字符数越少,压缩的效果越好。
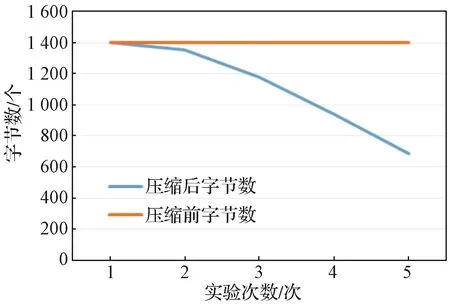
图5 实验二压缩变比图Fig. 5 Compression transformation diagram of the experiment 2
(3)实验三
经过多次验证分析之后,按照实际的ZC日志记录数据来进行分析。现以2019年9月某日长沙地铁4号线路的ZC日志记录为例,从中连续取100组1 400个字节的数据,经过Huffman编码压缩后,根据码表进行解压缩,并验证数据无误。该100组数据解压缩后的效果如图6所示。可以看出,每一组1 400个字节的数据经过压缩后的数据量在200到600个字节之间,充分证明了基于Huffman编码的数据压缩算法对ZC日志记录数据的压缩是可行的。
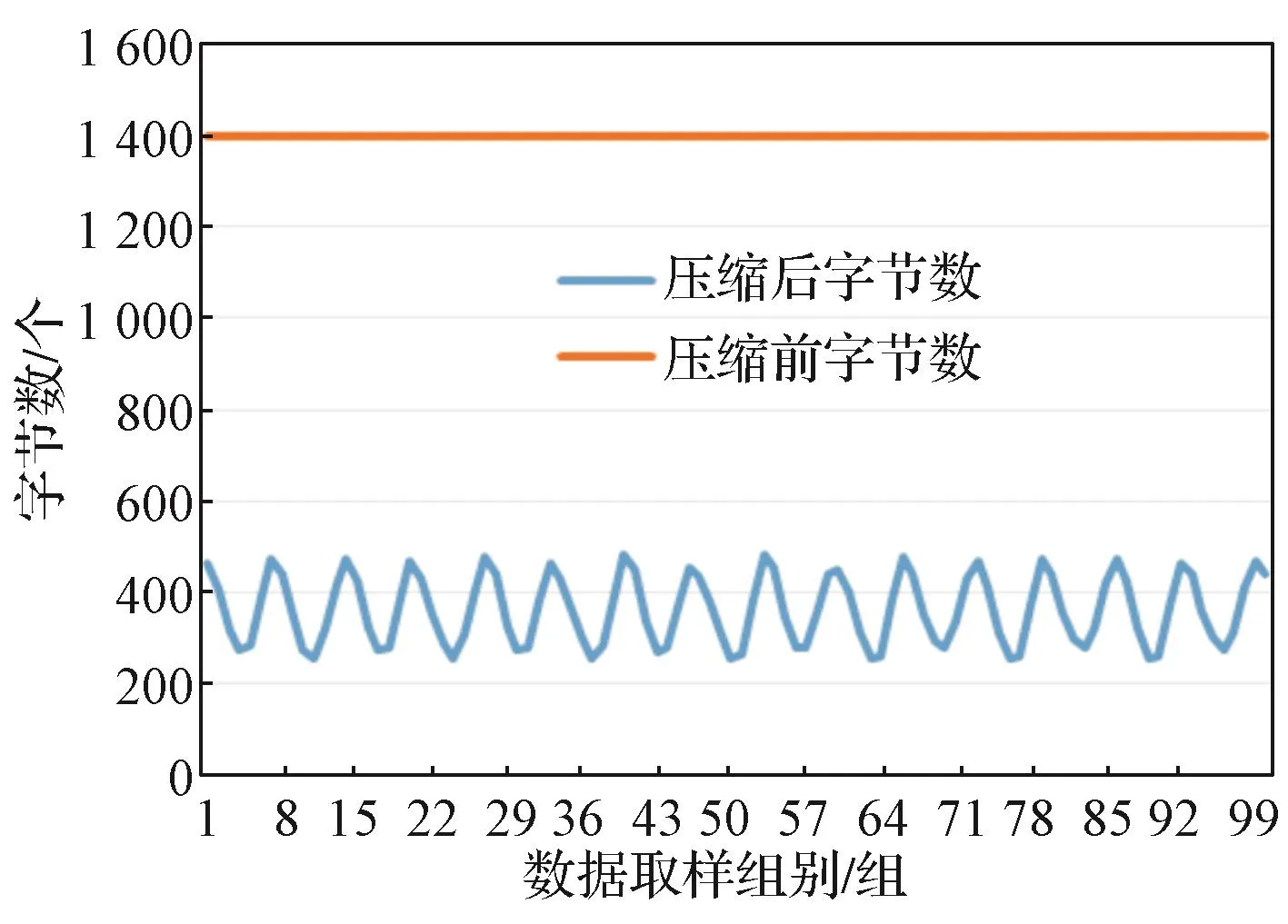
图6 实验三压缩变比图Fig. 6 Compression transformation diagram of the experiment 3
4 结语
随着城市轨道交通自动化程度的日益提高,不管是目前普遍运行的GOA2等级的线路,还是今后越来越多的GOA3等级或者GOA4级别线路,数据交互现象会越来越多,数据量会越来越大,数据压缩技术的研究也势在必行。本文针对实际ZC日志的数据压缩问题,提出了一种基于Huffman编码的数据压缩算法。从实验结果来看,其压缩效果好、效率高。目前该算法已被应用于实际的产品中。
当然,信息论领域有很多算法可以充分利用,而Huffman压缩算法是其中一种。今后将考虑对ZC日志纪录进行多重压缩,即在Huffman压缩算法的基础上增加其他的压缩算法,以更大程度地提高压缩率。另外,轨道交通产品正在向网络化、远程可视化方向发展,其数据的传输受到了网络带宽限制。本文所提供的数据压缩存储的思路,可以减轻网络传输的压力,为轨道交通中大数据的网络化应用提供参考。
