基于改进VGGNet-16网络新生儿胆红素水平测量方法
2020-08-03刘国玉王东颖候桂军
刘国玉,王东颖,候桂军
(唐山市妇幼保健院,河北 唐山 063000)
0 引言
在临床上,新生儿黄疸是新生儿常见的症状之一,主要病因是由于在新生儿体内胆红素(Bilirubin)代谢水平异常,而造成新生儿血液中胆红素水平升高,从而引起皮肤、粘膜及巩膜发黄的现象。一般情况下可以分为生理性和病理性两种[1-2]。正常情况下,当新生儿血液中的胆红素浓度高于2~3 mg/dL(34~51 μmol/L)时,这些部分便会呈现肉眼可见的其他颜色。医学研究表明,新生儿的发病率呈现逐年增加的趋势,造成不可逆转的神经系统后遗症[3],给普通家庭带来了众多的灾难。国内外一系列研究表明,较低浓度的胆红素足以影响到患者的神经系统、听力以及智力,早产儿中特别常见。所以,进行精确的检验,辅以早且有效化的治疗,能够在很大程度上防止高胆红素血症对患者的后遗症发生,避免脑损伤的形成[4],如何高效且有效监测新生儿血液中的胆红素水平成为了首要的问题。
检验医学领域,使用特定的仪器和经皮胆红素值测定两种主要的方法来测定新生儿血清总胆红素值,前者测量方法虽然精确,但是需要采集新生儿的血液,造成有创伤口,直接增加了新生儿的痛苦,被父母所排斥;后者测量方法虽然操作便捷,一旦新生儿出院后,无法实时在居家的环境下检测新生儿身体中较高的胆红素值,无法做到及时有效的干预治疗[5-6]。因此需要选择一种合理的方法,在不同的环境下均能实时便捷检测出新生儿血清中的胆红素水平,在不造成新生儿创口的同时,也要能保证检测的准确率。在哪吒保APP的启发下,可以借助卷积神经网络(CNN)[7]对新生儿图像特征进行识别,与样本数据进行比对,从而分析得出新生儿胆红素的含量,实现便捷且高效地对新生儿胆红素水平的监控。
本文提出了一种改进的VGGNet-16网络[8]在新生儿胆红素水平准确性研究算法,针对本院收集的新生儿胆红素特征照片以及医疗检测的记录,将这些特征图片和胆红素含量指标进行分类,然后再利用VGGNet-16网络的图像处理能力,得到这些新生儿的特征,借助全连接网络实现对特征图像的分类,被分到某个类别的新生儿特征图像会具备此类特征图像的胆红素水平值范围,给医疗人员提供一个有效的参考值。
1 算法构建
借助卷积神经网络对图像的特征提取,识别出新生儿胆红素照片的不同特征,然后使用全连接网络对这些不同的特征进行分类研究,从而给出测试的样本数据对应的类别胆红素水平的属性值。
1.1 卷积神经网络
卷积神经网络的主要核心是卷积核,卷积核是由特定大小组成的特征加权小区域,可以有效对图像的特征进行提取,卷积核的几个重要的特征包括卷积核的大小,卷积核的通道数以及卷积核的运算法则,包括是否进行边缘填充和卷积核的步长。单纯从理论的角度看待卷积核的通道数,其直接作用于上层图像的特征矩阵,能得到相应通道数的特征图,一般情况下,提取得到的特征图越多,特征空间的维度会越大,表明学习到的图像特征越多,得到的最终结果更加准确。但是另一方面,会增加卷积模型的参数个数,导致模型更加复杂,训练所需的计算量也更加庞大,有时甚至导致过拟合的现象,因此并不是卷积核的数量越多越好,而是要根据图像的特征来确定卷积核的数量。

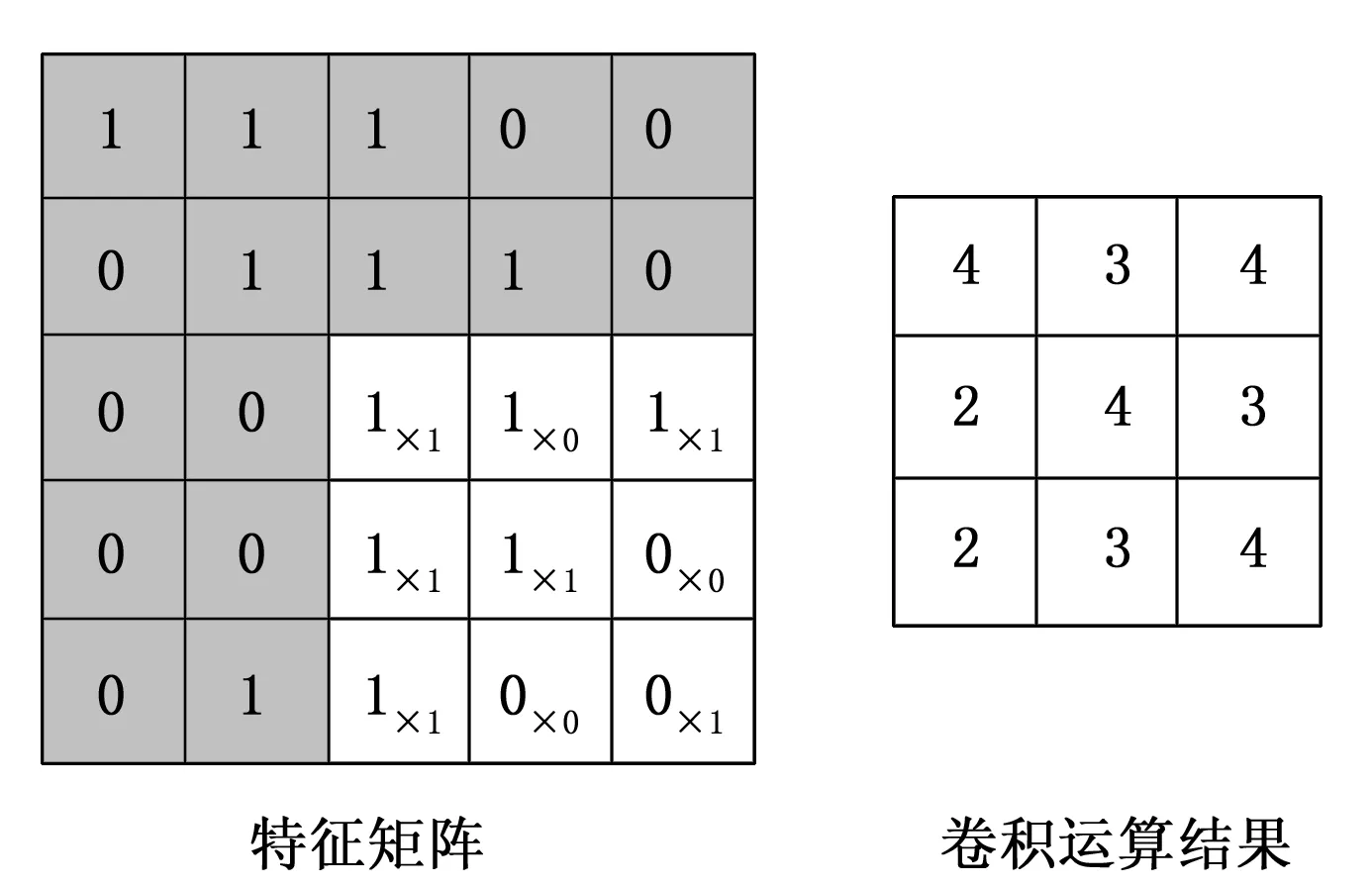
图1 图像卷积示意图
从图1中可以看出,对于卷积的运算是将对应的数值与卷积核各位对应相乘并求取总和。经过卷积运算后的数值特征矩阵不能直接用于下一阶段的处理,还需要进行池化[9]操作。所谓的池化操作,就是对经过卷积核运算后的特征图小邻域内进行下采样得到新的特征,这些新的特征在减少模型参数的情况下(特征维度降低,参数也会降低),也增强了相关的特征,使得最终的特征能准确表征图像的某些不变性,比对旋转、伸缩和平移等特征,池化的过程本质上是一个降维的过程。常用的池化操作分为均值采样(mean- pooling)、最大采样(max - pooling),一般情况下均值采样可以减小邻域大小受限造成的估计值方差增大造成的特征提取不准确的弊端,更能保留图像的背景信息;而最大采样可以减小卷积层参数误差造成估计均值的偏移,使得特征更能保留图像的纹理特征,由于本文在特征纹理上没有太多的要求,所以在池化的操作上采用均值采样(mean-pooling)操作。
1.2 激活函数
为了使得神经网络模型具备非线性映射的特点,需要在神经网络模型中使用激活函数,常用的激活函数有Sigmoid函数、Tanh函数、ReLU函数等[10],其中Sigmoid和Tanh函数在BP神经网络中运用广泛,而ReLU函数被广泛应用于深度学习中。假设一个神经单元的激活函数为h(i),其中i表示隐含层单元的个数,w(i)表示隐含单元的权值,那么ReLU函数的表达式如公式(1)所示。
(1)
ReLU函数的表示如图2所示。
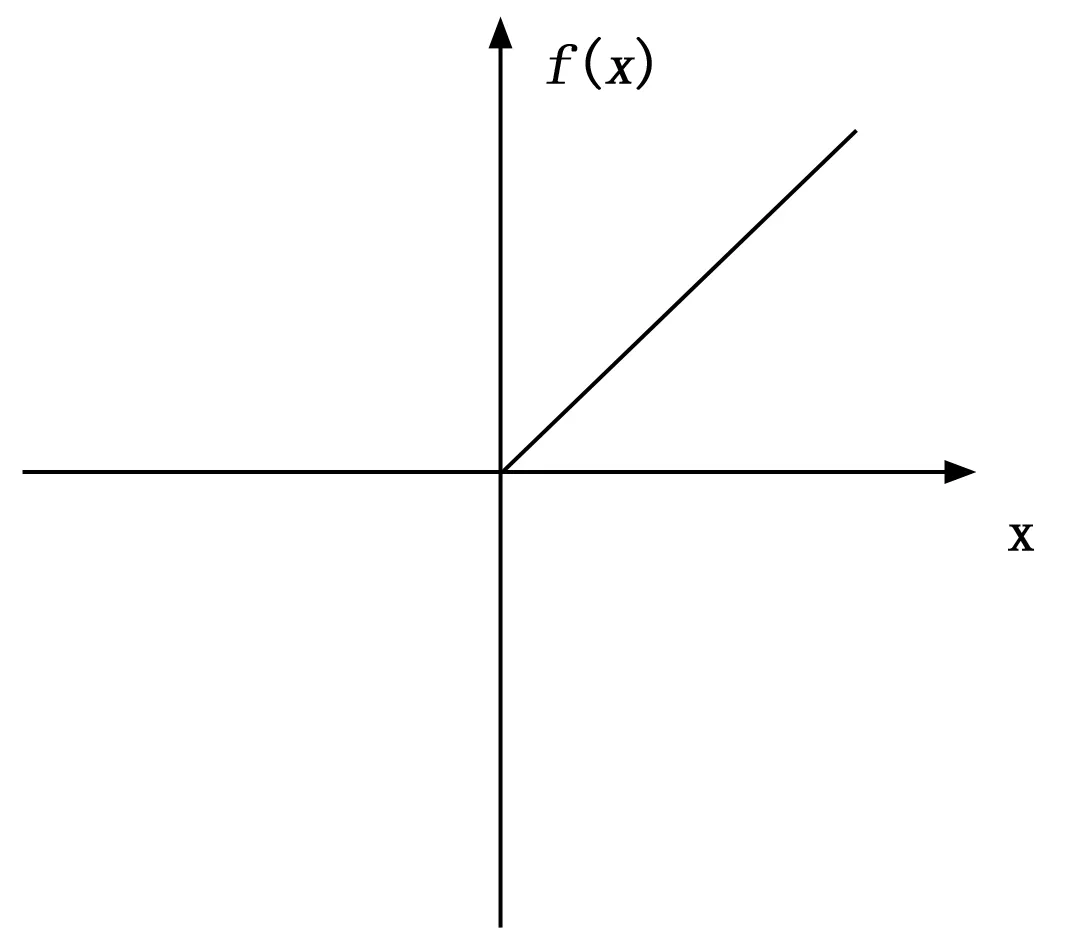
图2 ReLU函数的图像
经过大量的深度学习研究表明,ReLU函数具有非饱和、线性的特征,能够对单侧的特征值进行抑制,对另一侧的边界兴奋,分散了神经单元的激活性,相比Sigmoid和Tanh函数[10]在卷积神经网络中性能优异。
1.3 全连接神经网络
在对CNN网络提取的特征图像进行分类的时候,需要对已经提取得到的特征值进行全连接网络的分类处理,全连接网络的结构图如图3所示,其输入是已经得到的图像特征值,输出是处理分类的信息。

图3 全连接网络层
图3中的隐藏层包含了2层的全连接神经网络模型,本文构造的BP神经网络由1个输入层,3个隐藏层和1个输出层组成。对于第二层神经网络中的每一个神经节点来说,对于第一层输入的数据,经过线性变换,线性变换的公式为:

(2)
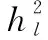
若隐藏层不采用激活函数,构造的全连接神经网络模型将会是一个线性模型,只是简单具备数据的线性拟合能力,无法具备逼近真实的分类函数能力,本文选用的激活函数为Sigmoid激活函数[10],公式如(3)所示。
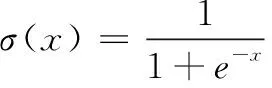
(3)
公式(2)可以将线性转化的实数转化到0~1之间的输出,具体来说也就是将越大的负数转化到越接近0,越大的正数转化到越靠近1。
1.4 改进的VGGNet-16网络算法
使用的CNN神经网络模型中流行的VGGNet-16作为网络的主体,因为其识别的精度较高,适合用于图像特征的识别,在此之上进行改进,将最大池化层原则更换为平均池化原则,主要是为了更多发现新生儿照片中的背景颜色特征,降低图像纹理特征的干扰。如图4所示,是本文选用的网络模型。
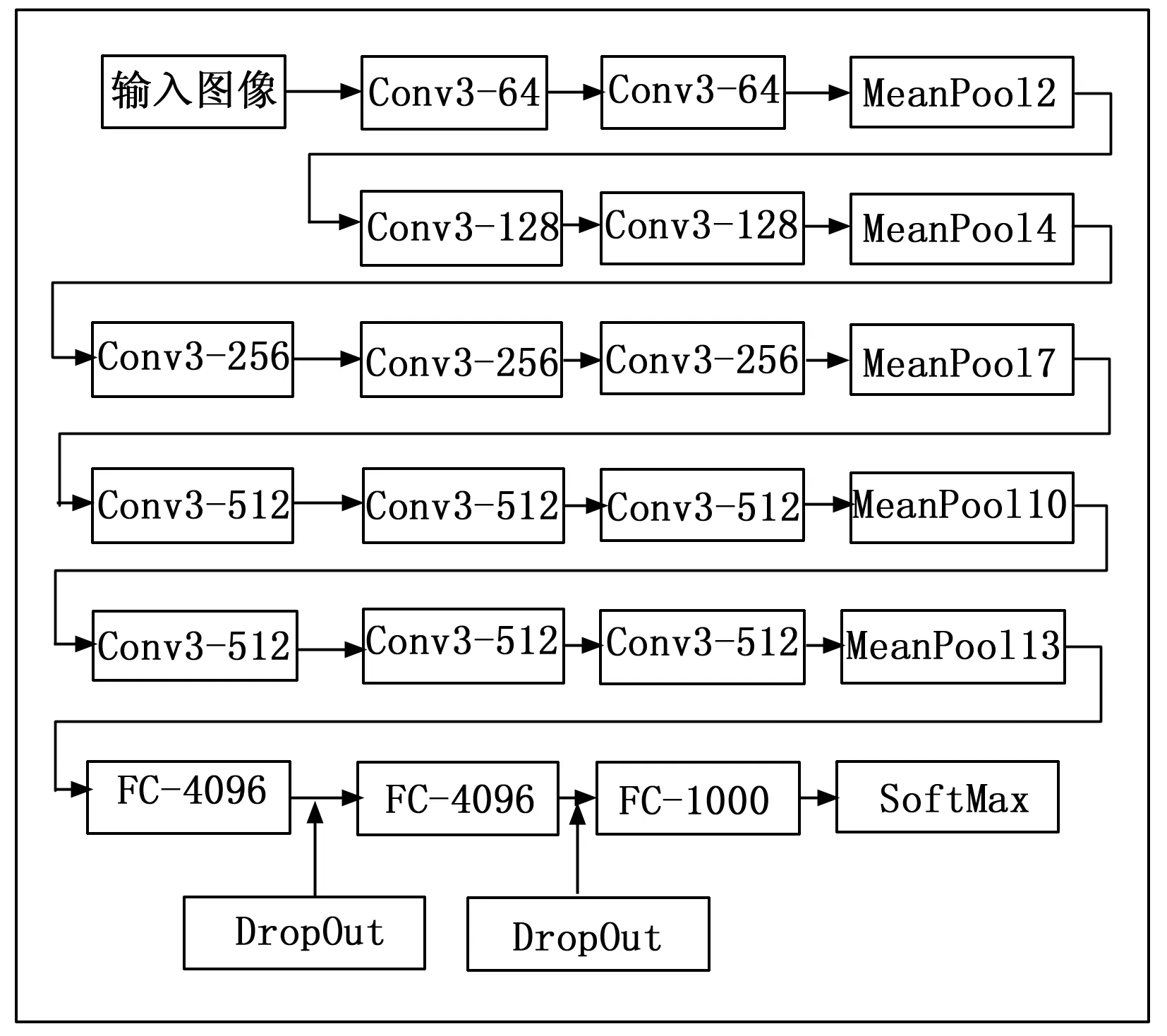
图4 算法采用模型
如图4所示,“Conv3-64”表示采用的是尺寸为3*3的卷积神经网络,深度为64,“MeanPool2”表示采用的是平均池化的策略,而且池化层的尺寸大小为2*2,这样可以有效降低特征维度的长宽尺寸;进一步分析图4可以得到,采用这样的神经网络模型,深度越来越深,而特征维度的长和宽在减少,有利于提取新生儿胆红素图像的更多特征。
采用VGGNet-16网络应用于图像分类任务时,需要在后面的全连接网络层连接一个Softmax分类器[11],用于生成对图像分类标签的预测,结合本文的实际应用场景,本文的模型中将会分为6类。在Softmax回归中,解决的是多分类问题(相对于logistic回归解决的二分类问题),标签值y可以取k个不同的值,每个标签是一个独立的类别。因此,对于不同的训练集{(x(1),y(1)),...,(x(m),y(m))},最终分类的结果都会得到y(i)∈{1,2,...,k}的不同概率,用p(y=j|x)表示样本相对不同分类标签的而不同概率,输出是一个k维的具有分类信息的向量(概率和为1),使用hθ(x)表示这k维分类特征,其表达公式如公式(4)所示。
(4)
公式(4)中使用θ符号表示模型的全部参数,θ是由k×(n+1)的矩阵组成的,该矩阵是通过θ1,θ2,...,θk参数进行堆叠得到的,如公式(5)所示。
(5)
由上式子可得样本x(i)属于j的概率公式如(6)所示。
(6)
当每个样本所属类别的条件概率p(y=y(i)|x(i);θ)都最大时,Softmax的分类识度是最高的,此时等价于最大化如公式(7)所示的似然函数。
(7)
为了降低计算量和防止溢出,对似然函数取对数,并适当变形得得到公式(8)。
(8)
其中:1{·}称为指示性函数,表达的意思是,当{true}时,其值为1,否则为0。于是最大化似然函数L(θ|x)可以转化为最小化代价函数J(θ)的问题,这也是深度学习中常使用的转化方法。对于求解最小化J(θ)的方法,常用的就是梯度下降法,给出使得J(θ)满足极小值时参数θ的值,但是理论上极小值很难求解。代价函数J(θ)的梯度如公式(9)所示。
(9)

(10)
在公式(10)中之所以加上第二项,是因为它会对偏大的权重值进行一定程度的惩罚,通常又称为权值衰减项,通过对超参数λ值的调控,可以降低权重值的数量级,防止训练模型过拟合。
使用反向传播算法进行梯度的运算,借助梯度信息对模型参数进行更新,主要的方法有随机梯度下降法[12](stochastic gradient decent, SGD),自适应矩估计法[13](adaptive moment estimation,Adam),本文使用的是SGD算法,通常情况下训练数据集会比较大,如何一次性装载所有训练样本进行训练,往往会出现内存溢出问题,因此随机抽取数据集的一个小样本数据集[14](mini-batch,数量为N<<|D|进行训练是很有必要的,具体的代价函数如公式(11)所示。
(11)
随机梯度下降法每次输入一个微型集(mini-batch)对网络进行训练,由于每次的微型集都是随机选取的,所以每次迭代的代价函数会不同,当前bacth的梯度对网络参数的更新影响较大,为了减少这种影响,本文选用引入动量系数对传统的随机梯度下降法进行改进,更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向,这样在一定程度上增加了模型的稳定性,促进模型学习地更快,具备一定的消除局部最优解的能力。加动量的随机梯度下降算法迭代公式如公式(12)~(13)所示。
Vt+1=μVt-η▽J(θt)
(12)
θt+1=θt+Vt+1
(13)
其中:Vt是上一次的权值更新量,μ为动量系数,表示要在多大程度上保留原来的更新方向,这个值在0~1之间,η为学习率。值得注意的是,本文还使用了DropOut策略[2]进行优化,Dropout通过随机修改神经网络的结构来实现的,属于神经网络训练过程中的优化方法,核心思想是在训练过程中随机隐藏部分神经单元,使之不参与运算,保留它们的权重值,暂时不进行更新操作,其他神经单元进行正常的更新。在实际的训练过程中,Dropout优化策略采用(1-p)的概率将隐含的神经单元输出值设置为0,在反向传播更新权值阶段,不再更新与该节点相连的权值,Dropout优化策略图如图5所示。
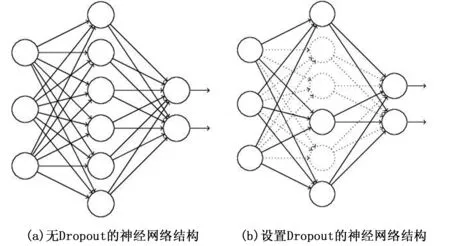
图5 Dropout优化策略示意图
本文提出的改进的VGGNet-16网络新生儿丹红水平准确性研究算法选用的DropOut的比例值是0.5。
2 实际应用
2.1 数据准备
为了将已经采样得到的新生儿胆红素检测照片(主要是心脏部位的皮肤照片)与通过仪器设备测定的胆红素含量进行分类,从已有的本院数据库中导出了1 300份有关的数据条例,借助文献[15]的部分理论结果,将数据分为6大类,每大类的具体信息如表1所示。

表1 训练数据的分类表
将本院已有的新生儿医疗记录信息供1 300条数据按照表1的分类方式进行分类,然后按照训练集:测试集的7:3的比例按照十字交叉验证[17]的方法对没个类别进行数据的随机选取与训练,每个类别中剩下的30%比例的数据做为测试集进行精确分类的测试集,随机进行10次试验,取10次验证数据集的平均值作为验证的准确率,这样做的好处是可以充分利用小数量的训练数据集,克服模型泛化能力较差的弊端,取10次中验证数据最好的网络作为新生儿胆红素准确性研究的算法模型。
2.2 试验结果
经过一系列的试验进行验证,得到的10次的十字交叉验证的实验数据集如表2所示。
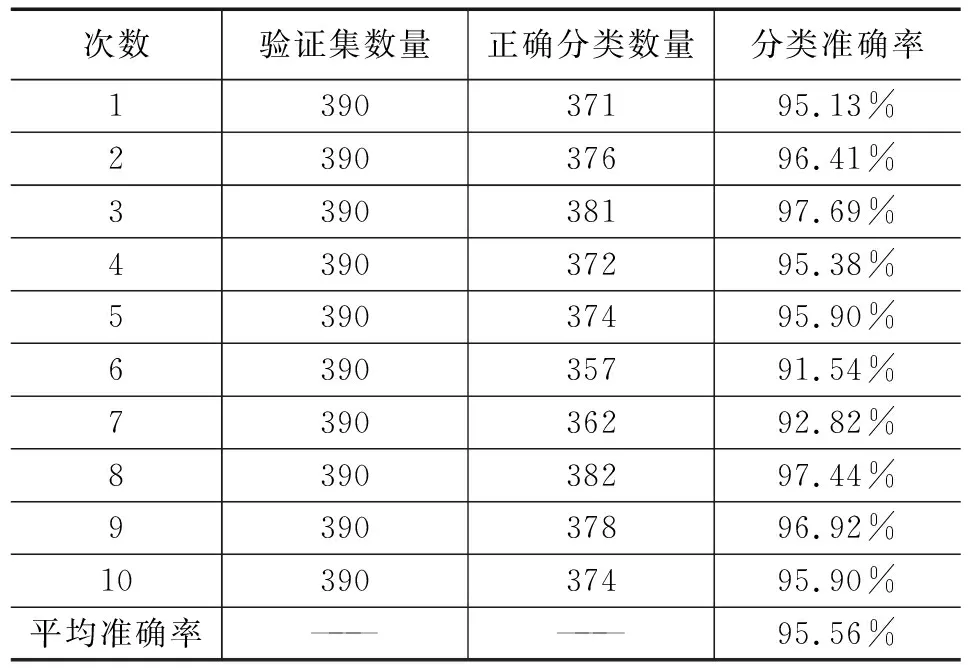
表2 实验结果的验证精确度
由表2可以看出,基于VGGNet-16网络提出的改进的VGGNet-16网络新生儿胆红素水平准确性研究算法在分类的准确率上最高可以达到97.69%,平均的分类准确率为95.56%,基本上完成了根据新生儿心脏部位表皮图像特征进行胆红素水平测试的任务,根据分类的不同类别可以给出一个新生儿胆红素水平值的参考数据值,在保证不伤害新生儿健康的情况下,做到了检测准确、方便,满足实时分析的需求。
3 结束语
提出了一种改进的VGGNet-16网络在新生儿胆红素水平准确性研究的算法,该算法借助卷积神经网络对于图像特征提取方面的优势,对已有的新生儿医疗照片进行特征提取,然后借助全连接神经网络对这些提取的特征值进行6个种类的分类,每个类别中标注了新生儿胆红素检测值的范围,作为检测水平值的参考;为了充分利用已有的小数据新生儿医疗数据,采用十字交叉验证的方法进行训练与验证。经验证,该算法在新生儿胆红素水平照片分类的准确率上最高可达97.69%,平均准确率达95.56%,达到了实用的水平。
本文存在着训练数据小的弊端,在未来的算法改进过程中,应该加大与其他医院的新生儿胆红素医疗数据的交流,争取利用大量数据使得算法准确率更高,更具泛化性。
