基于大数据分析的电力客户服务需求预测*
2020-08-01朱州
朱 州
(中国南方电网贵州电网公司 信息中心, 贵阳 550000)
智慧城市使用物联网与云技术建立了一个可交互、可感知、可视和可控的城市运行机制及智能生产生活方式[1].智慧城市不仅可以减少成本、节约能源,且能提升效率,改善生活质量.智能电网作为智慧城市的重要组成部分,通过电力数据建立电力服务需求预测模型,保证电力系统的安全稳定运行与统一调度,并可有效地指导电力工程建设规划[2-4].但传统的电力需求预测模型只考虑区域平均用电量和最高负荷等电力系统内部数据,未考虑气象、人口和政策等影响,其预测精度有限,因此,亟需在智慧城市的建设框架下提出新的预测模型与方法[5-6].
近年来,针对电力市场随机性、多变量和时变性的特点,主要提出了两方面的电力需求预测方法:一是使用数据挖掘方法分析电力市场外部因素对电力需求的影响,并以其变化趋势预测市场需求的变化;二是提出新的预测模型来提升预测精度[7].文献[8]中使用径向基神经网络分别建立短期和中长期电力需求模型;文献[9]结合气象、日期数据等外部因素,使用最小二乘支持向量机建立了短期电力需求模型,并通过与其他预测方法进行比较来证明其有效性.
虽然上述方法都选用了不同的预测模型和方法对短期和中长期电力需求进行了预测研究,但是仍存在着一些不足:1)部分模型仅根据历史数据来预测,而没有关注经济社会发展因素;2)部分模型只根据主观判断来考虑外部因素的影响,而未从海量数据中筛选出关键因素.针对以上问题,本文首先依托贵州地区的智能电网大数据,通过挖掘其中的关联信息,建立了电力客户的细分模型,然后在该模型基础上,使用BP神经网络算法建立了电力客户的需求预测模型.
1 电力客户细分模型
本文为建立更智能的需求预测模型,首先将电力客户进行细分,再使用细分后的数据指导需求预测模型的训练,所建立的电力客户细分模型如图1所示.首先根据人口信息、企业信息、宏观经济信息及其相关信息建立数据仓库,然后对数据进行格式转换与清洗,并提取出用户的自然特征和行为特征,最后使用K-means聚类对数据进行挖掘,并对结果进行分析.
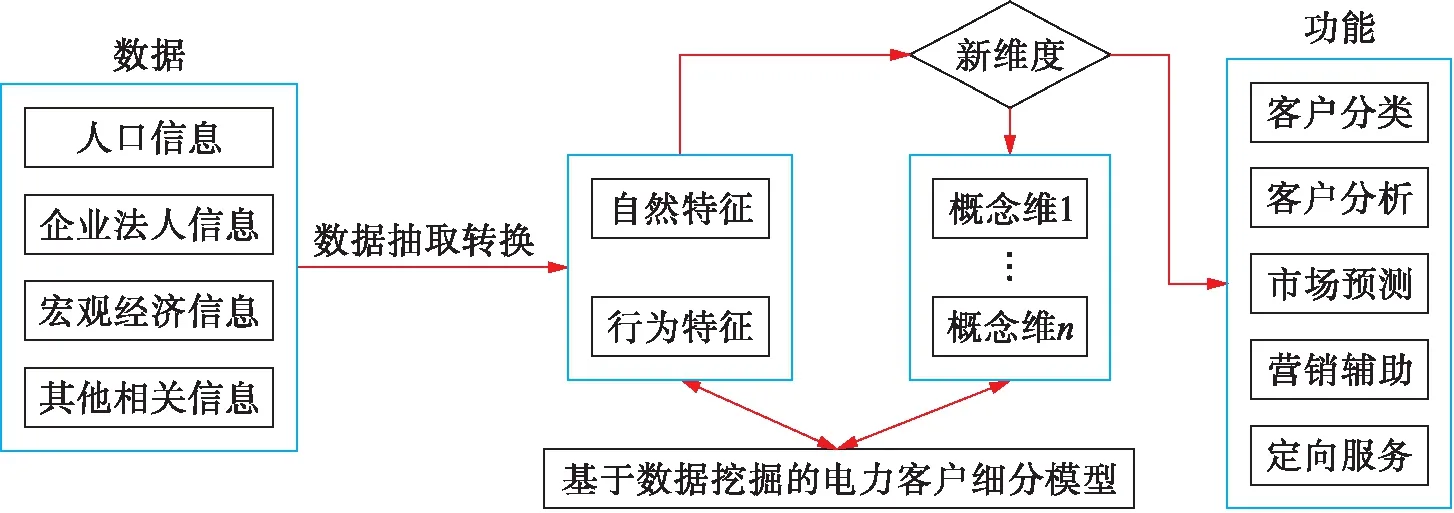
图1 电力客户细分模型功能图Fig.1 Function diagram of power customer subdivision model
1.1 数据仓库构建
随着数字化技术的广泛应用,电力客户数据库中存储着大量的自动化办公系统、监控和财务系统等信息[10],但这些数据随着日常业务的进行与时间的推移不断被添加、删除和修改,故本文根据电力客户细分模型的实际需求建立了星型结构的数据仓库.该数据仓库结构最大限度地节省了数据存储空间,保证数据存储的有效性.本文从个人用户的角度出发,通过采集其社保信息、个人信息和地域特征等信息来分析电力客户的电力价值,并建立图2所示的电力价值组成图.该图结合公民的社保信息、个人信息和地域特征,并依据电价值的排序划分电力用户区域.
本文从区域商业价值和区域宏观经济两个角度来采集数据,并建立与图2类似的价值构成数据库.其中,区域商业价值数据库从商业实体的角度分析企业信息、商场信息和法人信息来实现数据搜索.区域宏观经济数据库则从地区物价指数、贸易数据和资产投资数据等宏观信息来分析地区的贸易活动,实现不同层次用电客户的划分.

图2 区域电力价值组成图Fig.2 Value composition diagram of regional power
1.2 数据清洗与挖掘
由于电力客户信息存在大量的冗余信息,本文使用东方通TI-ETL软件对数据进行清洗,得到符合身份证号码设置、民族和性别的数据,清洗后的数据便于读取与模型训练.
得到可读性更强的数据后,本文根据上文建立的区域电力价值图、电力客户的影响力和用电潜力对居民信息进行集成划分,如图3所示.使用K-means聚类算法对搜集的数据进行深层次分析,以强化业务协同和资源共享,解决信息孤岛问题.为较好区分出不同用电行业与客户之间的差异,本文在样本相似性聚类的基础上,提出使用相关性度量聚类后类别内样本间的一致性.使用Pearson相关系数法来表示样本x与样本y之间的相关系数,其计算表达式为
(1)
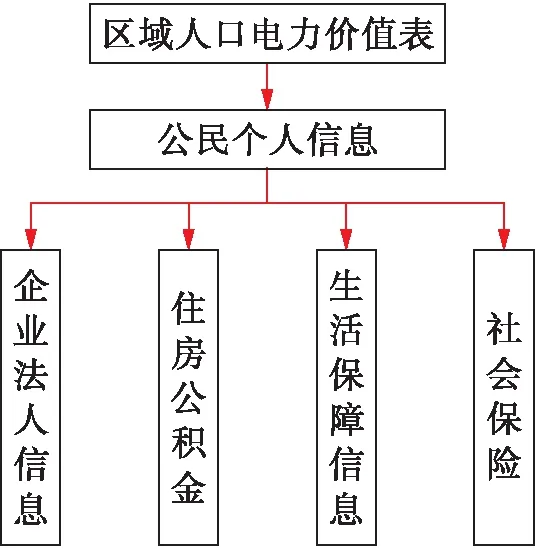
图3 区域居民信息集成划分结构Fig.3 Integrated partition structure of regional resident information
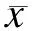
结合样本相似度与相关系数,可以得到本文的相似性度量方程为
Eik(x)=μdik(x)+(1-μ)rik(x) (0≤μ≤1)
(2)
式中:Eik(x)为样本i与类中心k的相似性值;dik(x)为样本i与类中心k的距离,本文使用平方差距离;rik(x)为样本i与类中心k的相关系数;μ为权重常数.当μ为1时,相似性度量指标为基于距离的度量;当μ为0时,相似性度量指标为基于相关系数的度量.使用改进后的相似性度量指标后,电力客户的具体划分过程如下:
1) 读取数据得到初始数据集X=NP和客户组数,其中,N为居民综述,P为特征维度;
2) 从X中随机选择k个样本作为数据的初始聚类中心;
3) 计算其样本与各聚类中心的相似性度量指标,并根据其数值将样本划分到对应的聚类中心;
4) 利用每一组数据的均值更新聚类中心;
5) 重复步骤3)和4),直至聚类中心不再更新,得到分组结果.
2 电力需求预测
电力需求预测是根据已有的历史数据总结其规律,并建立预估模型来预测未来的电力需求.但由于客观因素与人为因素影响,电力需求通常具有连续性、多变性和季节性,导致无法准确预测客户的用电需求.本文从电力需求预测的影响因素出发,根据时间、经济、社会和天气等因素建立电力需求模型.具体使用的数据指标包括:
1) 宏观经济指标.第一产业、第二产业和第三产业的投资总值,制造业、文娱业和基础建设的投资值等.
2) 历年电力消费数据.
3) 已经建立的电力客户细分数据.
4) 政策数据.第一产业、第二产业和第三产业的耗电数据,居民消费和收入数据等.
基于上述数据,本文使用BP神经网络建立电力需求预测模型.为避免神经元过饱和的问题,文中首先对数据进行归一化处理,即
(3)
式中:xi0为归一化数据的第i个特征分量;xmax和xmin为对应样本的最大值与最小值.
为了更准确地从挖掘到的数据中提取出关联规则来解决电力需求问题,本文从网络层数、神经元数目、初始权重设置和学习速率的选择来介绍具体预测模型的设计方法.
1) 网络层数.虽然使用更深的神经网络能提升模型的性能,但也在一定程度上降低了训练效率.因此,本文设计了一个包含输入层、隐含层和输出层的三层神经网络模型.
2) 输入层节点数.输入层用于加载数据,过多的输入节点数将引入较多的噪声;而过少的输入节点数将导致网络获取信息能力不足,因此,本文根据输入数据维度设置网络的输入节点数为65.
3) 输出层节点数.本文分别预测5个区域的用电需求,故输出层节点的数量设置为5,输出层用于获取5个区域的实际用电需求.
4) 隐含层节点数.隐含层节点数确定表达式为
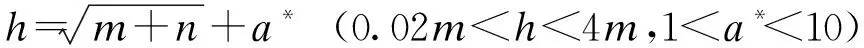
(4)
式中:m、n和h分别为输入层节点数、输出层节点数和隐含层节点数;a*为1~10间的常数[11],因此,本文设置隐含层节点的数量为18.
5) 学习率设置.神经网络的学习率影响网络权重的变化情况,设置过大的学习率将导致网络不稳定;而学习率过小将增加训练时间,并可能引起局部最小值.因此,为了保证网络的稳定训练,本文设置学习率为0.01.
为了避免网络陷入局部最优解,文中提出了一种改进的附加动量法来调整网络权重,其对权重和阈值的调节表达式分别为
(5)
式中:w为网络权重;k为训练速度;c为动量因子;η为学习率;δi为误差函数的梯度;b为阈值.
附加动量法即使用动量因子对网络权值的变化进行加权调节,增加动量因子将使权重向着误差曲面凹陷区域运动,从而避免网络权重陷入局部平坦区域.因此,可以通过调节动量因子来帮助网络跳离局部极小值.根据式(2)可以看出,调整后的阈值在出现较大误差时应取消本次权重更新,避免网络陷入较大的误差范围.因此,在使用式(2)时应设定条件来决定是否修改网络权值.本文设置附加动量法的判别依据为
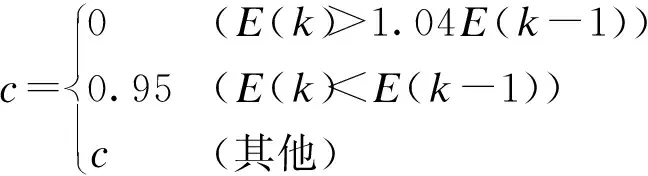
(6)
式中,E(k)为网络第k次迭代时的平方和误差.
3 仿真与实验结果
本文使用贵州电力信息数据构建了宏观经济数据库、区域历年电力消费数据库、政策数据库和电力客户细分数据库等数据库表.在数据库构建过程中得到符合身份证号码设置、民族和性别的数据,直接删除没有身份信息的数据,然后选取其中有代表性的1 446 000余名住户和企业的用电信息进行仿真分析.
基于这些数据本文将该市按照行政区划分为3个类别:工业区、商业区和居民区.根据居民电力用户基数大和数据繁杂的特点,本文以经济和社会行为做依据,并关联企业法人信息来反映用电客户全貌,根据缴费额度和用电量对电力客户进行划分.将电力用户划分为:居民生活用电(A类),大工业用电(B类),农业生产用电(C类)和商业用电(D类),电力客户进行细分的结果如表1所示.
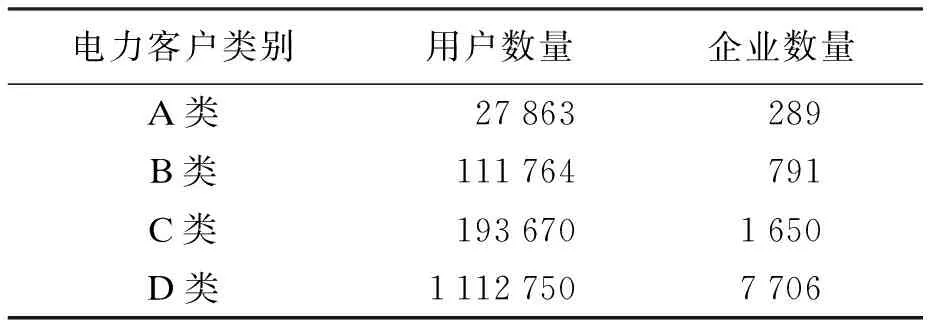
表1 电力客户细分结果Tab.1 Subdivision results of power customers
为验证本文所提出的改进聚类算法的有效性,比较了仅使用传统基于距离的相似性度量方法和本文所提出聚类方法的性能,结果如表2所示.从表2中可以看出,所提出的方法虽然在距离属性上的表现较差,但能明显增加样本间的相关性.
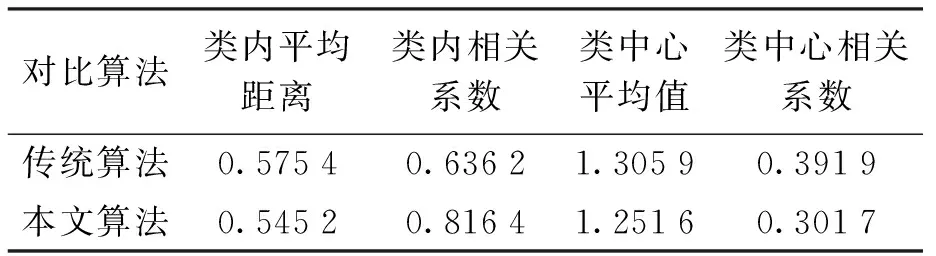
表2 改进前后K-Means聚类算法性能Tab.2 Performance of K-Means clustering algorithm before and after improvement
本文也测试了所提出的神经网络电力的预测精度.表3为使用某地区2008~2018年的用电数据训练预测获得的2019年电力需求误差百分比.从表3中可以看出,本文算法最大的相对误差仅6.52%,表明算法可以得到较好的预测结果,能有效地预测电力客户用电需求.从表3中还可以看出,不区分用户类别直接预测的最大误差为10.86%,表明使用电力客户细分数据后能在一定程度上提升预测精度.
为了验证本文算法的有效性,本文使用10个不同小区的用电量数据进行训练和预测,结果如图4所示.从图4中可以看出,本文算法的预测值十分接近实际用电量,表明本文算法能取得较高的预测精度.
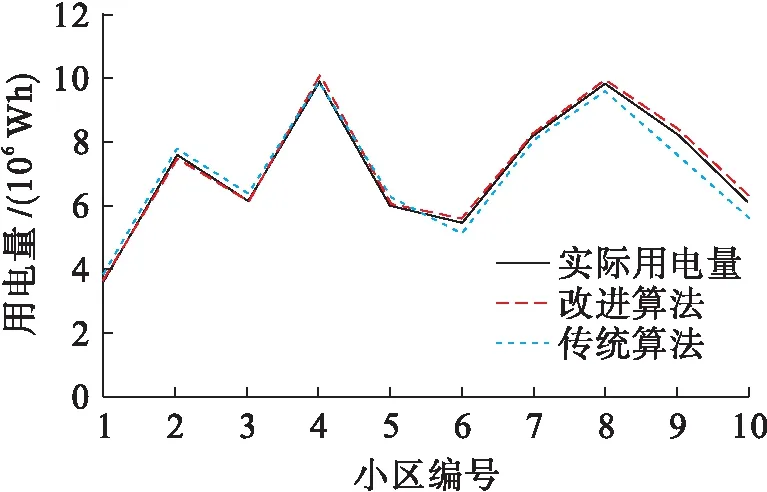
图4 10个小区用电量预测结果Fig.4 Forecasting results of electricity consumption from 10 communities
4 结 论
本文依托贵州智能电网大数据,从区域商业价值和区域宏观经济等角度搜集电力服务数据,并通过挖掘其中的关联信息,使用K-Means算法建立了电力客户的细分模型,将客户划分为4类.在客户细分模型的基础上,设计了BP神经网络算法来建立需求预测模型,该模型能根据清洗后的数据特征直接预测客户的需求变化情况.在Matlab平台上的仿真与测试结果表明,所提出的方法能帮助电网公司更好地理解客户行为和服务需求,制定营销策略.
