单目视觉惯性的同时定位与地图构建综述
2020-07-26瑚琦蔡文龙卢定凡姜敏
瑚琦 蔡文龙 卢定凡 姜敏


摘 要:在机器人领域,同时定位与地图构建(SLAM)是导航定位的关键技术。单目视觉传感器由于结构简单、成本低且能获取丰富的视觉信息,被广泛应用于SLAM。随着无人机、AR设备以及自动驾驶汽车技术的快速发展,视觉惯性SLAM(VI-SLAM)技术得到了越来越多人的关注。针对VI-SLAM,从滤波与非线性优化的角度出发,首先介绍相关算法理论框架,然后分析几种具有代表性的单目VI-SLAM算法创新点及实现方案,并通过EuRoC MAV数据集评估各算法优劣,最后结合深度学习与语义SLAM,对SLAM未来发展趋势进行探讨。
关键词:视觉惯性SLAM;滤波;非线性优化;深度学习
DOI:10. 11907/rjdk. 192271 开放科学(资源服务)标识码(OSID):
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)007-0275-06
Survey on Monocular Visual Inertial SLAM Algorithms
HU Qi1,2,CAI Wen-long1,2,LU Ding-fan1,2,JIANG Min1,2
(1.School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology;
2.Shanghai Key Lab of Modern Optical System, Shanghai 200093, China)
Abstract:In the field of robotics, simultaneous localization and mapping (SLAM) is the key technology for navigation and positioning. Monocular vision sensors are widely used in SLAM due to their simple structure, low cost, and access to rich visual information. With the rapid development of drones, AR equipment and self-driving cars, visual inertial SLAM (VI-SLAM) technology has received more and more attention. For VI-SLAM, from the filtering-based and optimization-based perspective, the basic theory of algorithm implementation is introduced first. Secondly, the innovation points and implementation schemes of several representative monocular VI-SLAM algorithms are analyzed. Then, the advantages and disadvantages of each algorithm are evaluated through the EuRoC MAV dataset. Finally, combined with deep learning and semantic SLAM, the future development trend of SLAM is discussed.
Key Words:VI-SLAM; filter; nonlinear optimization; deep learning
0 引言
同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)是指搭载特定传感器的主体在未知环境中移动,对自身进行定位并构建增量式地图的技术[1]。根据传感器的不同,分为激光SLAM和视觉SLAM。激光SLAM使用的激光雷達结构单一,且价格昂贵,一般需要结合其它传感器才能有效工作。基于视觉的同时定位与地图构建(Vision-based Simultaneous Localization and Mapping,VSLAM)利用视觉传感器获取图像数据,通过多视图几何对其进行处理,得到机器人位置。VSLAM有多种视觉传感器方案,一般以RGB-D深度传感器、双目传感器与单目传感器为主。其中,单目传感器在过去30多年中对SLAM的研究起到了重要的推动作用,MonoSLAM[2]是第一个实时单目VSLAM,LSD-SLAM[3]是直接法第一次成功应用于单目VSLAM,ORB-SLAM[4]是现有VSLAM中功能最完善、易用的。然而,随着无人机、人工智能以及自动驾驶技术在机器人领域的快速发展,仅采用单一传感器的VSLAM由于在动态环境下容易出现误匹配问题而无法胜任复杂场景,于是VI-SLAM应运而生。视觉惯性SLAM(Visual-Inertial SLAM,VI-SLAM)是一种结合视觉传感器和惯性测量单元(Inertial Measurement Unit,IMU)估计移动平台位姿(位置和姿态)变化的技术,该技术主要分为滤波和非线性优化两种。本文重点研究单目VI-SLAM,首先系统分析几种具有代表性的滤波VI-SLAM和非线性优化VI-SLAM,然后通过实验评估各算法性能,最后探讨SLAM未来发展趋势。
1 滤波法
滤波法在早期SLAM研究中占据主要地位,基于滤波的VI-SLAM一般使用EKF[5]。EKF在假设马尔可夫性的前提下,通过维护状态量均值和协方差确定最大后验概率分布,从而解决非线性系统模型的估计问题。
1.1 EKF框架
基于EKF框架的VI-SLAM分为预测和更新两部分。IMU能够得到三轴加速度和三轴角速度,根据式(1)的运动方程,用上一时刻的状态[xt-1]预测当前时刻的状态[xt]。
其中,[ut]是已知的输入变量,噪声[ωt]满足零均值的高斯分布[ωt~Ν(0,Rt)],[Rt]为协方差,待估计的状态变量[xt]是一个16维向量。
其中,[IWq]为从世界坐标系到IMU坐标系的四元数,[WpI]、[WvI]对应于世界坐标系的旋转和速度,[bg]、[ba]分别为陀螺仪和加速度计的偏差(bias)。
由于受到噪声干扰,随着时间的增加,预测阶段得到状态变量的准确性会不断下降,而视觉传感器通过式(3)的观测方程对预测结果进行更新,能够有效减少误差。
其中,[xt]为待优化的状态变量,观测过程中的噪声[vt]满足零均值的高斯分布[vt~Ν(0,Qt)],[Qt]为协方差。
完整的预测及更新过程如下:
(1)预测:
(2)更新:
其中,[F]、[H]为雅克比矩阵,[Pt]为后验概率。
1.2 单目滤波VI-SLAM
视觉传感器与IMU在进行数据融合时,按照将图像特征信息加入状态向量的方式分为松耦合和紧耦合。松耦合虽然运行速度快,但是无法纠正视觉测量引入的尺度漂移,在视觉定位困难的地方鲁棒性不强;紧耦合是指将IMU状态变量与相机状态变量合并在一起,共同构建运动方程和观测方程,然后进行状态估计。紧耦合具有定位精度高、鲁棒性强的优点,因而被广泛应用于单目滤波VI-SLAM中[6-9]。其中,MSCKF[8]、ROVIO[9]是当下最流行的。
1.2.1 MSCKF
MSCKF是一个基于多状态EKF约束的VI-SLAM,该算法应用于谷歌Tango,至今尚未开源。传统EKF-SLAM进行数据融合时,状态向量保存当前图像帧的位姿、速度及地图点(Map Points),然后用IMU作预测,再通过视觉传感器的观测误差进行更新。MSCKF预测过程与传统EKF-SLAM相同,其创新点在于更新过程。在更新之前每接收到一帧图像信息,便将状态向量加入到按时间排序的滑动窗口中,只有当地图点被多个图像帧同时观测到才进行更新。从2007年提出MSCKF至今,该算法因具有计算复杂度低及鲁棒性强等优点,被广泛应用于智能手机、扫地机器人等小型化场景中。
1.2.2 ROVIO
ROVIO是苏黎世大学Ethz ASL实验室于2015年提出的基于EKF框架的单目VI-SLAM算法。该算法通过IMU预测状态向量,利用视觉的光度误差约束对状态向量进行更新。ROVIO的独到之处在于将地图点的空间位置信息拆分成两项,一项是由方向角和倾斜角组成的二维向量(bearing vector),另一项是逆深度(inverse depth)。这种构造方式使得获取的数据在初始化阶段不会产生延迟,从而能够有效提高系统的鲁棒性和精度。
当获取到一组最新的加速度计数据和陀螺仪数据时,ROVIO通过卡尔曼预测对得到的数据进行处理。卡尔曼预测(Kalman prediction)需要完成3项工作:一是预测当前时刻的状态变量[x],得到均值的先验[x-],使用多次迭代的EKF得到更准确的状态向量[xiter],并结合相机模型计算特征点在当前帧上的像素坐标[pi],用于计算下一帧图像的像素位置;二是预测协方差的先验[p-],并将[x-]和[p-]传递给视觉更新过程,当接收到一帧最新的图像时,需要对状态向量进行更新,并剔除异常点;三是更新Warping Matrix,用来校正不同视角下的图像映射变化,得到第i个地图点的[Di]在当前时刻的增量。最后通过地图点[Di]和像素坐标[pi]得到当前帧的光度误差[e],通过多次迭代求解雅克比矩阵和误差项,得到位姿的最优估计。
2 非线性优化
基于非线性优化的VI-SLAM主要依靠多视图几何技术[10]对视觉传感器采集的数据进行处理,而当相机因快速移动得不到清晰图像时,可以利用IMU测得的数据作為先验信息对整个系统进行校正。计算非线性优化的单目VI-SLAM主要包括初始化、前端、后端和回环检测4部分。
2.1 初始化
初始化主要为系统提供一个精确的尺度信息,而该尺度信息估计的好坏直接决定了SLAM能否正常运行。由于单目相机不能直接得到深度信息,所以估计出来的位移与周围环境相差一个尺度,这种现象称为单目的尺度不确定性(Scale Ambiguity)。针对这种问题有多种解决方法,VI-SLAM的解决思路是对IMU进行预积分[11],利用运动学方程估计出相对运动距离,并通过非线性优化求解出环境地图的真实尺度,该方法由于精度高而被广泛应用于单目VI-SLAM。其它方法如文献[12]通过不同角度观测环境中的同一点,利用三角测量的方法确定该点距离,但该方法对视差选取要求严格;文献[13]提出逆深度(Inverse Depth)方法,将深度的倒数加入状态变量中进行更新,该方法虽然能够得到一个比较精确的结果,但会占用更多的计算资源;文献[14]采用速度传感器和GPS直接得到尺度信息的方案,但该方案不适用于室内等场景。
2.2 前端
前端称为视觉里程计,它根据相邻图像信息粗略估计出相机运动,给后端提供位姿初始值。其中,待估计的位姿[T∈SE(3)]包括旋转矩阵[R]和平移向量[t]。
[T=Rt01,R∈SO(3),t∈R3] (6)
前端按是否需要提取特征,分为特征点法和直接法。特征点由关键点与描述子组成,关键点是特征点在图像中的位置,描述子描述了该关键点周围像素的位置。特征点法如图1所示。
由图1可知,特征点法利用式(7)的针孔相机投影模型将三维世界地图点[pu]映射到二维图像平面。
其中,[u0]、[v0]为主点坐标,[fu]、[fv]为焦距。当从两帧连续的图像之间得到匹配好的特征点时,通过八点法[15]求得位姿T。当得到特征点[u]与对应的深度[du]时,通过式(8)的反投影模型得到3D地图点[pu],用PNP求得位姿T。
直接法如圖2所示,直接法以第一帧图像C1为参考,通过光度不变原理预测上一帧像素点P1在当前图像帧C2的位置P2。当得到匹配好的像素点之后,采取与特征点相同的方式求取位姿。
直接法根据地图点P的来源不同,分为稀疏直接法、半稠密直接法与稠密直接法3类。
(1) 在稀疏直接法中,P来自稀疏关键点,一般使用几百至上千个关键点,不计算描述子,同时假设关键点周围像素是不变的。
(2) 在半稠密直接法中,P来自部分像素,由于像素梯度为0的地图点不会对运动估计有任何贡献,因此只考虑带有梯度的像素点,舍弃像素梯度不明显的地方。
(3)在稠密直接法中,需要对所有地图点P进行计算。
2.3 后端
由于位姿T在李群SE(3)下的奇异性,进行后端优化需要将其转换为李代数[se(3)]下的[ξ]。
式(10)表示以特征点为前端的代价函数,误差项为重投影误差,式(11)表示以直接法为前端的代价函数,误差项为光度误差。通过对式(10)、式(11)进一步构建最小二乘目标函数,使用高斯牛顿法或Levenberg-Marquardt法迭代估计位姿T的最优解。
其中,[ei]是特征点[p1]、[p2]之间的光度误差。
其中,[z]是测量值,[z]是估计值,[z]是两者的重投影误差。
2.4 回环检测
虽然后端能够估计最大后验误差,但其误差会随着时间一直叠加,使得整个SLAM估计结果的可靠性不断降低,而回环检测提供两种思路解决该问题:一方面,由于累计误差的影响,递推得到的位姿差别很大,而回环检测能够提供当前数据与所有历史数据的关联,当系统两次经过同一位置时,可以认为这两次的位姿相等,然后校正其它图像帧的位姿,以此降低累计误差的影响;另一方面,在视觉传感器跟踪地图点丢失之后,还可以利用回环检测进行重定位。因此,回环检测能够有效提高SLAM算法的精度和鲁棒性。
2.5 非线性优化VI-SLAM
在基于非线性优化的VI-SLAM算法中,捆集调整(Bundle Adjustment,BA)[16]是极其重要的一部分。BA利用图优化技术,沿着目标函数梯度下降方向[Δx]对状态向量的估计值进行优化,使得整体误差下降到一个极小值。在以上优化过程中,关键在于如何通过求解线性增量方程[HΔx=g]得到[Δx]。由于BA需要计算大量特征点和位姿,因此对H矩阵直接求逆将十分耗费资源。主流处理方法是:利用H矩阵的稀疏性对当前图像帧的无用信息进行边缘化(Marginalization)处理,并通过滑动窗口(Sliding Window)减少累积误差。
近年来,机器人领域出现了许多单目非线性优化VI-SLAM算法[17-21],其中,OKVIS[19]、VI-ORB[20]、VINS[21]是最常见的。
2.5.1 OKVIS
OKVIS是Leutenegger等提出的基于非线性优化的VI-SLAM,其特点在于选择关键帧及边缘化准则。算法基本思想是尽可能保存当前关键帧的有用信息,对信息量少的图像帧进行边缘化,并保留其与关键帧之间的约束,进而通过两帧图像之间的特征匹配与IMU采样数据积分估计相机位姿和地图点。
2.5.2 VI-ORB
VI-ORB是在ORB-SLAM2[22]基础上融合IMU的定位算法,其计算过程包括跟踪(Tracking)、局部建图(Local Mapping)和回环检测(Loop Closing)3部分。与ORB-SLAM2相比,VI-ORB的主要特点在于局部地图中优化方式不一样。整个局部地图中需要优化的状态量包括固定的N帧图像以及由N帧图像共同观测到的地图点(Map Poings)。其中,ORB-SLAM2只优化包含视觉误差的关键帧,而VI-ORB根据局部地图是否更新优化视觉重投影误差和IMU测量误差,且存在以下两种情况:
(1)当局部地图进行更新时,首先构建整体优化状态向量,包括旋转、平移速度、位移、加速度计偏置和陀螺仪偏置,然后通过视觉重投影误差和IMU测量误差优化当前帧状态向量,上一帧图像的状态量和地图点不会进行优化,而是作为约束项优化当前帧状态向量。
(2)当局部地图没有更新时,地图点不会进行优化,而是作为约束项优化下一时刻的状态量,将优化结果作为先验数据边缘化当前时刻的状态量。
2.5.3 VINS
VINS是香港科技大学沈劭劼团队提出的单目实时VI-SLAM,是目前非常先进的单目VI-SLAM算法。VINS主要分为5部分:数据预处理、初始化、后端、回环检测及全局位姿优化。
(1)数据预处理与初始化为系统提供初始地图和尺度信息。数据预处理包括对图像和IMU的预处理。其中,在图像处理层面,前端提取图像Harris角点,利用金字塔光流跟踪相邻帧,通过RANSAC[23]去除奇异点,并通知后端进行处理;在IMU预处理层面,将IMU数据进行积分,得到当前时刻的位姿和速度,同时计算相邻帧的预积分增量、预积分误差的雅克比矩阵和协方差项。初始化利用SFM进行纯视觉估计滑动窗口内所有图像帧的位姿及3D点逆深度,并与IMU预积分进行对齐,求解初始化参数。
(2)后端对状态向量[χ]进行非线性优化,为系统提供一个可靠的位姿估计。
其中,[xk]表示第k帧图像时刻的IMU状态,包括位置、速度、世界坐标系下的IMU方向以及IMU坐标系下的加速度计与陀螺仪偏移。n表示关键帧数目,m表示滑动窗口中的特征总数,λm是第m个特征的逆深度,[xbc]表示相机在IMU坐标系下的位姿。
后端通过最小化先验误差和所有观测误差的马氏距离之和得到最大后验估计,求解滑动窗口内所有帧的状态变量。
其中:
式(13)中第一項来自边缘化后的先验误差,第二项来自IMU观测误差,第三项来自视觉误差。
(3)回环检测及全局位姿优化为系统构建全局一致的轨迹和地图。回环检测使用BoW模型挑选回环候选图像帧,通过匹配BRIEF描述子建立局部滑动窗口关键帧与回环候选图像帧之间的联系。当回环检测成功后,对整个系统的运动轨迹进行全局位姿优化。
3 算法评估
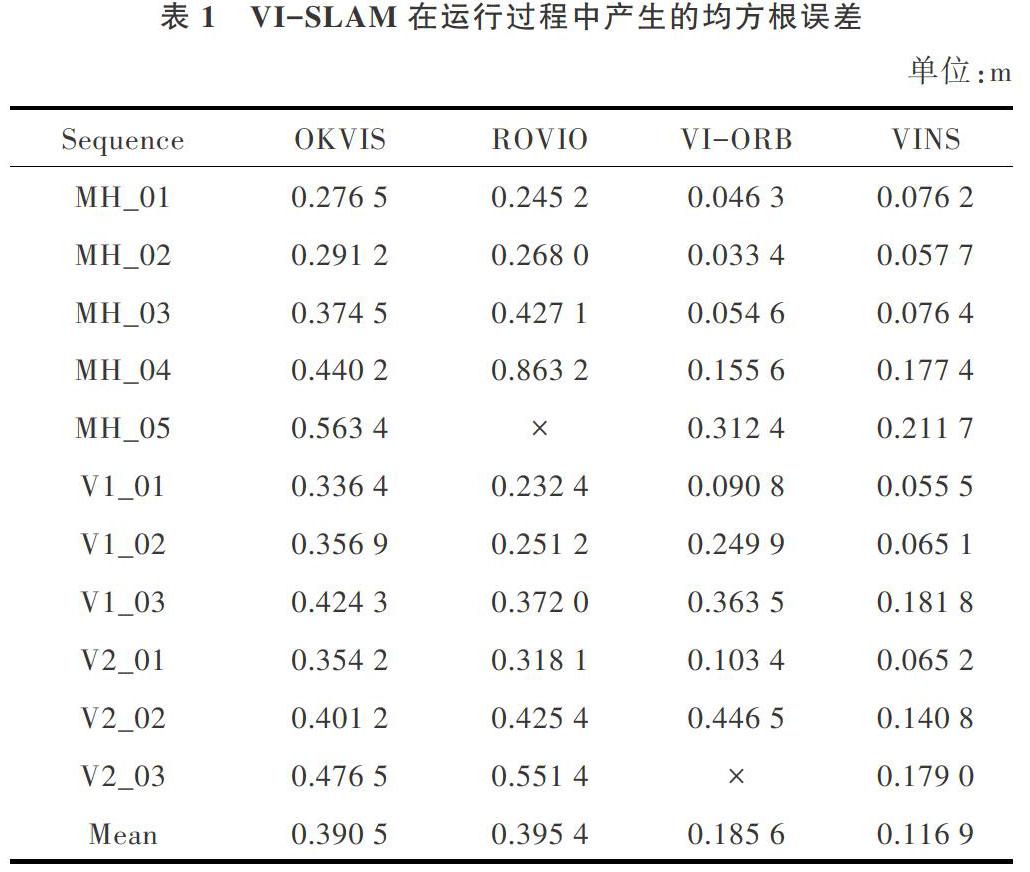
VI-SLAM已应用于众多领域的状态估计问题,为了与现有开源算法的效率和精度进行对比,挑选4种被广泛使用的单目VI-SLAM算法OKVIS、ROVIO、VI-ORB、VINS进行实验,通过对比均方根误差(Root Mean Square Error,RMSE)评估各算法优劣。该实验在配置为Intel Xeon E5-2609 V2 × 4 @2.50 GHz 16 Gb RAM的计算机上运行,使用EuRoC MAV数据集[24]对上述单目VI-SLAM算法进行测试,测试结果通过evo工具(https://github.com/MichaelGrupp/evo)进行评估。EuRoC MAV数据集分为Machine Hall(MH)、Vicon Room 1(V1)、Vicon Room 2(V2) 3个场景,共有11个序列,序列数字大小代表算法执行难度。
对表1中各VI-SLAM算法实验结果进行分析可以得到:
(1)OKVIS可以完成各序列的测试要求,总体精度与鲁棒性能够满足实际需求。
(2)ROVIO没有表现出很好的性能,其在运行过程中产生的RMSE平均值最大,相比其它算法,该算法的准确性和效率都有待提高。
(3)VI-ORB虽然在V2_03_diff序列中无法正常运行,但该算法在其它序列中表现出很好的精度与效率。
(4) VINS的性能是4种算法中最好的,该算法在运行过程中产生的RMSE平均值只有0.116 9m,但需要占用很高的计算资源。
4 发展趋势
4.1 深度学习与SLAM
深度学习作为一种端到端的方法,可以应用于SLAM的前端和回环检测。基于深度学习的SLAM前端无需特征提取,使得整个计算过程更加简洁、直观[25]。Costante等[26]利用卷积神经网络学习图像数据的最优特征,在应对相机快速运动造成的图像模糊问题中表现出很好的鲁棒性。回环检测本质上是场景识别问题,传统方法使用BoW模型进行回环检测,而基于深度学习的SLAM通过神经网络学习图像中的深层特征,因此具有更高的识别率[27]。Hou[28]利用caffe框架下的AlexNet模型进行特征提取,在光照变化明显的环境下,使用深度学习的特征描述能够迅速提取特征信息,并大幅提升精度。但目前深度学习只能应用于SLAM的某些子模块,如何将深度学习技术应用于整个SLAM系统是未来发展的主要趋势。
4.2 语义SLAM
语义SLAM是指SLAM在建图过程中从几何和内容两个层次感知世界,对地图内容进行抽象理解。Li等[29]利用DeepLab-v2中的CNN架构预测像素级的物体类别标签,结合条件随机场对生成的单目半稠密三维语义地图进行正则化。地图的语义生成与SLAM过程是相互促进的两部分,语义可以帮助SLAM缓解特征依赖,获得更高层次的感知,SLAM可以帮助语义在移动机器人场景下进行目标识别[30]。语义与SLAM的结合使得机器人能够获取更高层次的感知,从而能够处理更复杂的任务。
5 结语
VI-SLAM是一种结合视觉传感器与惯性测量单元估计移动平台位置和姿态变化的技术,由于VI-SLAM使用的传感器具有结构简单、成本低的优点,因此在定位和建图领域有着广泛应用,包括移动机器人、自动驾驶汽车、无人驾驶飞行器及自主水下航行器等。然而,VI-SLAM为了获得较高的准确性与更强的鲁棒性,需要耗费大量计算资源,从而限制了其在小型化和轻量化场景中的应用。因此,在未来的发展中,VI-SLAM需要在现有框架基础上作进一步完善与拓展,为资源受限的系统提供一些有效策略以解决以上问题。
参考文献:
[1] 周彦,李雅芳,王冬丽,等. 视觉同时定位与地图创建综述[J]. 智能系统学报,2018,13(1):97-106.
[2] DAVISON A J,REID I D,MOLTON N D,et al. MonoSLAM:real-time single camera SLAM[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 1052-1067.
[3] ENGEL J, SCH?PS T, CREMERS D. LSD-SLAM: large-scale direct monocular SLAM [C]. European Conference on Computer Vision. Springer, Cham, 2014: 834-849.
[4] MUR-ARTAL R,MONTIEL J M M, TARDOS J D. ORB-SLAM: a versatile and accurate monocular SLAM system [J]. IEEE Trans on Robotics, 2015, 31(5): 1147-1163.
[5] BAILEY T,NIETO J,GUIVANT J,et al. Consistency of the EKF-SLAM algorithm [C]. Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems,2006: 3562-3568.
[6] LYNEN S,SATTLER T,BOSSE M, et al. Get out of my lab: large-scale, real-time visual-inertial localization [C]. Robotics: Science and Systems,2015.
[7] SCHNEIDER T, DYMCZYK M, FEHR M, et al. Maplab: an open framework for research in visual-inertial mapping and localization [J]. IEEE Robotics and Automation Letters,2018,3(3):1418-1425.
[8] MOURIKIS A I,ROUMELIOTIS S I. A multi-state constraint Kalman filter for vision-aided inertial navigation [C]. Proceedings of IEEE International Conference on Robotics and Automation,2007:3565-3572.
[9] BLOESCH M,OMARI S,HUTTER M,et al. Robust visual inertial odometry using a direct EKF-based approach [C]. IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS). IEEE,2015: 298-304.
[10] HARTLEY R,ZISSERMAN A.Multiple view geometry in computer vision [M]. Cambridge: Cambridge University Press, 2004.
[11] FORSTER C,CARLONE L, Dellaert F, et al. IMU preintegration on manifold for efficient visual-inertial maximum-a-posteriori estimation [C]. Robotics Science and Systems,2015.
[12] Davison A J. Real-time simultaneous localisation and mapping with a single camera[C]. IEEE International Conference on Computer Vision (ICCV),IEEE, 2003.
[13] MONTIEL J,CIVERA J,DAVISON A J. Unified inverse depth parametrization for monocular SLAM [C]. Robotics: Science and Systems, 2006.
[14] AGRAWAL M, KONOLIGE K. Real-time localization in outdoor environments using stereo vision and inexpensive GPS [C]. The 18th International Conference on Pattern Recognition (ICPR 06),2006.
[15] HARTLEY R I. In defense of the eight-point algorithm [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1997, 19(6): 580-593.
[16] TRIGGS B, MCLAUCHLAN P F, HARTLEY R I, et al. Bundle adjustment—a modern synthesis [C]. International Workshop on Vision Algorithms.Springer, Berlin, Heidelberg,1999:298-372.
[17] CONCHA A, LOIANNO G,KUMAR V,et al.Visual-inertial direct SLAM[C]. IEEE International Conference on Robotics and Automation (ICRA). IEEE,2016:1331-1338.
[18] KEIVAN N,PATRON-PEREZ A,SIBLEY G. Asynchronous adaptive conditioning for visual-inertial SLAM [C]. Experimental Robotics. Springer, Cham, 2016: 309-321.
[19] LEUTENEGGER S,LYNEN S, BOSSE M,et al. Keyframe-based visual-inertial odometry using nonlinear optimization [J]. The International Journal of Robotics Research, 2015, 34(3): 314-334.
[20] MURARTAL R, TARDOS J D. Visual-inertial monocular SLAM with map reuse [J]. International Conference on Robotics and Automation, 2017, 2(2): 796-803.
[21] QIN T, LI P, SHEN S, et al. VINS-Mono: a robust and versatile monocular visual-inertial state estimator [J]. IEEE Trans on Robotics, 2018, 34(4): 1004-1020.
[22] MURARTAL R,TARDOS J D.ORB-SLAM2:An open-source SLAM system for monocular,stereo,and RGB-D cameras [J]. IEEE Trans on Robotics,2017,33(5):1255-1262.
[23] FISCHLER M A, BOLLES R C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography [J]. Communications of The ACM, 1981, 24(6): 381-395.
[24] BURRI M, NIKOLIC J, GOHL P, et al. The EuRoC micro aerial vehicle datasets [J]. The International Journal of Robotics Research, 2016, 35(10): 1157-1163.
[25] 趙洋,刘国良,田国会,等. 基于深度学习的视觉SLAM综述[J]. 机器人,2017,39(6):889-896.
[26] COSTANTE G, MANCINI M, VALIGI P, et al. Exploring representation learning with CNNs for frame-to-frame ego-motion estimation [J]. IEEE Robotics and Automation Letters, 2015(1): 18-25.
[27] 罗顺心,张孙杰. 基于深度学习的回环检测算法研究[J]. 计算机与数字工程,2019,47(3):497-502.
[28] HOU Y, ZHANG H, ZHOU S. Convolutional neural network-based image representation for visual loop closure detection [C]. IEEE International Conference on Information and Automation. IEEE, 2015: 2238-2245.
[29] LI X, BELAROUSSI R. Semi-dense 3D semantic mapping from monocular slam[DB/OL]. https://arxiv.org/pdf/1611.04144.pdf.
[30] 白云汉. 基于SLAM算法和深度神经网络的语义地图构建研究[J]. 计算机应用与软件,2018,35(1):183-190.
(责任编辑:黄 健)
