基于卷积神经网络的油茶籽完整性识别方法
2020-07-24谢为俊丁冶春王凤贺杨德勇
谢为俊 丁冶春 王凤贺 魏 硕 杨德勇
(1.中国农业大学工学院, 北京 100083; 2.赣南医学院药学院, 赣州 341000;3.赣南医学院赣南油茶产业开发协同创新中心, 赣州 341000)
0 引言
油茶(CamelliaoleiferaAbel.)是山茶科、山茶属植物,与油棕、油橄榄、椰子并称为世界四大木本食用油料作物,广泛种植于我国南方丘陵地区和一些东南亚国家[1]。茶油是油茶籽的主要产物,富含多种不饱和脂肪酸,被誉为“东方橄榄油”[2]。中国是油茶种植大国,据统计,2017年油茶籽产量达到243万t,在我国脱贫政策扶持下,油茶产量将进一步增加[3]。
油茶蒲不含油脂,对制取茶油不利,因此需要对其进行脱蒲处理[4]。机械脱蒲后的产物为完整油茶籽、破碎油茶籽和果蒲等组成的混合物,需要将茶籽从中分选出来,以进行后续的茶油制取,同时还需要将完整茶籽与破碎茶籽分离,以保证茶籽的储藏质量。目前油茶籽分选方式主要分为筛孔分选、气流分选、胶带摩擦分选和油茶籽色选机分选等。筛孔分选主要根据油茶籽和油茶蒲的尺寸差异进行分级筛分。如熊平原等[5]设计了一种三级筛分网振动分选装置,以获得大、中、小蒲和碎末分层筛选的效果。气流分选是根据物质之间的质量差异进行分离。如郭传真[6]研究了气流对油茶果蒲籽混合物清选的影响规律,并确定了油茶果清选气流的最佳参数。胶带分选主要利用油茶籽、果蒲与胶带的摩擦因数不同实现分选。如WANG等[7]利用倾斜的胶带外加气流方式进行油茶籽、果蒲分选试验,结果表明,油茶籽分选精度达到98%,果蒲分选精度为93%。油茶籽色选机主要利用油茶籽与果蒲的颜色差异进行籽与蒲的识别,实现油茶籽分选。如周敬东等[8]设计的油茶籽色选系统,可对CCD相机获取的油茶籽和果蒲图像进行识别,进而利用气流对油茶籽、果蒲进行分离。目前,油茶籽分选机械可以实现将果蒲从混合物中分离,但不能分离碎籽。
机器视觉技术在农产品加工领域已有广泛应用。李霁阳[9]设计了一套适用于谷物外观品质分析的算法,该算法利用谷物的长度、宽度和像素面积等谷物特征参数实现谷物完整性识别。李伟等[10]基于图像处理技术提出基于形态学的棉籽破损识别方法,根据棉籽轮廓的对称性特征判断棉籽完整性。上述两种算法都是基于图像处理技术,算法复杂度较高,识别速度和识别率偏低。近年来随着深度学习技术的发展,机器视觉技术在图像分类检测和目标识别上的准确率不断提高。深度学习技术已被应用于不同领域[11],越来越多的学者将其运用在谷物[12-13]、水果[14-15]、蔬菜[16-17]等农产品目标识别和品质检测上。目前,卷积神经网络(CNN)模型,如AlexNet[18]、VGGNet[19]和GoogLeNet[20]等,主要针对种类繁多的目标识别,且对识别速度要求不高,因此,研究人员通常根据实际问题,设计出独特、适用的卷积神经网络结构[21-23]。上述研究结果表明,将CNN运用于农产品目标识别和品质检测是可行的。
本文根据油茶籽完整性识别任务要求,构建卷积神经网络模型,实现油茶籽的完整性识别。通过对比实验确定模型的总体结构;为提高网络的收敛速度、泛化性能与准确率,通过对比不同归一化方法的模型性能确定最佳归一化方法,同时比较不同激活函数对模型性能的影响,并对网络的超参数(批量尺寸和学习率)进行优化;为减小模型规模,使其更适用于茶籽分选设备,对模型卷积层感受野和全连接层节点进行压缩,以提高网络的准确率和实时性。
1 材料与方法
1.1 数据集构建
油茶果购自江西省赣州市,品种为“赣州油”。油茶果经过机械脱蒲后,选取1 761个完整籽和1 039个破碎籽,随机选取每个种类的70%作为训练集,30%为验证集。其部分数据集如图1所示。
油茶籽图像是由彩色CCD相机(DFK-33UX265型)和8 mm镜头(The Imaging Source,德国)采集,图像尺寸为1 920像素×1 080像素。图像处理算法和卷积神经网络搭建是基于Python 3.7、图像处理库OpenCV 4.0和深度学习库Tensorflow 2.0.0。程序运行环境为Intel i5-7200U 2.70 GHz CPU、4 GB运行内存、Windows 10操作系统。
1.2 图像预处理
单粒油茶籽图像由整幅图像(1 920像素×1 080像素)裁剪得到,主要步骤为:①利用OpenCV中的cv2.inRang函数对原图像进行二值化处理,得到含有大量噪声点的二值图像(图2b)。②对二值图进行中值滤波、形态学操作和面积去噪后,得到不含噪声的二值图像(图2c)。③将二值图作为掩膜,与原图像进行“与”操作得到去除背景的RGB三通道图像(图2d)。④检测出油茶籽轮廓,并得到油茶籽最小外接矩形(图2e)。⑤为了保持油茶籽形状轮廓不受裁剪影响,将油茶籽外接矩形每条边向外扩展5个像素作为裁剪矩形,得到单粒油茶籽图像(图2f)。⑥为了满足卷积神经网络对输入图像的要求,油茶籽图像在输入前统一调整为224像素×224像素的正方形图像。

图2 油茶籽图像预处理Fig.2 Image preprocessing of Camellia oleifera seeds
1.3 网络构建步骤
1.3.1归一化层
在AlexNet[18]经典网络中,为了提高模型泛化性能,提出了局部响应归一化(LRN),其能对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元。批量归一化(BN)是一种防止网络过拟合的方法,在每一层的激活函数之前采用批量归一化处理,使非激活的输出服从均值为0方差为1的正态分布,然后通过缩放和平移,将批量归一化计算结果还原为原始输入特性。该过程可以保证网络容量、加快网络训练速度、提高网络泛化能力[24],其数学表达式为
(1)
X=(x(1),x(2),…,x(d))
(2)
(3)
(4)
(5)
(6)
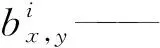
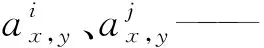
i——通道序号
N——通道总数
x(d)——第d维输入值
x、y——特征图的宽、高
k——超参数,防止除0的情况发生
α、β——常数n——邻域长度
X——BN层输入值,共有d维
x(k)——第k维输入值
y(k)——第k维输出值
E——均值Var——方差

1.3.2激活函数
激活函数将非线性因素引入神经元,使得深度神经网络可以逼近任何非线性函数,增强了深度神经网络的学习能力。因此,深度神经网络中激活函数的选择对训练过程和模型性能有着重要影响。目前应用最多的激活函数是ReLU函数。图3为不同激活函数在定义域上的函数图像,当x≥0时,ReLU函数无边界,梯度可以持续传递,不会出现饱和现象,然而x<0时,函数梯度消失,出现神经元死亡的问题。为了解决此问题,ReLU函数的改进函数如PReLU和ELU相继提出。此外,谷歌大脑于2017年提出了Swish函数[25]来解决ReLU函数梯度消失的问题。

图3 不同激活函数图像Fig.3 Different activation functions diagram
1.3.3网络结构
本文构建的模型(CO-Net)可以视作一种局部特征自学习方法,包括一系列在卷积神经网络中发挥不同作用的连续层,包括卷积层、归一化层、池化层和全连接层。油茶籽图像特征主要由卷积层自主学习得到;归一化层可以提高模型训练收敛速度;池化层可以减小网络结构参数并保持图像特征不变,提高模型泛化能力;全连接层将前面卷积层所学到的局部特征综合为油茶籽图像的全局特征。所构建的网络可以自动学习获得油茶籽主要特征。
油茶籽在线分选具有实时性和检测准确率要求高的特点,为了提高模型的训练速度和准确率,本文对AlexNet[18]网络进行了结构简化。首先,研究模型各层对模型性能的影响,确定网络总体结构;然后调整网络全连接层节点数量,以达到压缩模型的目的;最后调整网络卷积层各层感受野数量,达到加快模型训练速度的目的。在网络结构调整过程中,比较表征模型性能的4个参数(模型尺寸、训练时间、准确率和损失值),寻找出适合油茶籽完整性识别任务的最优网络结构。通过调整后,得到更适合油茶籽完整性识别的CO-Net网络,其拥有4层卷积层、2层BN层、3层池化层和1层全连接层(图4),其初始参数分布如表1所示。

图4 CO-Net网络整体结构图Fig.4 Overall structure diagram of CO-Net
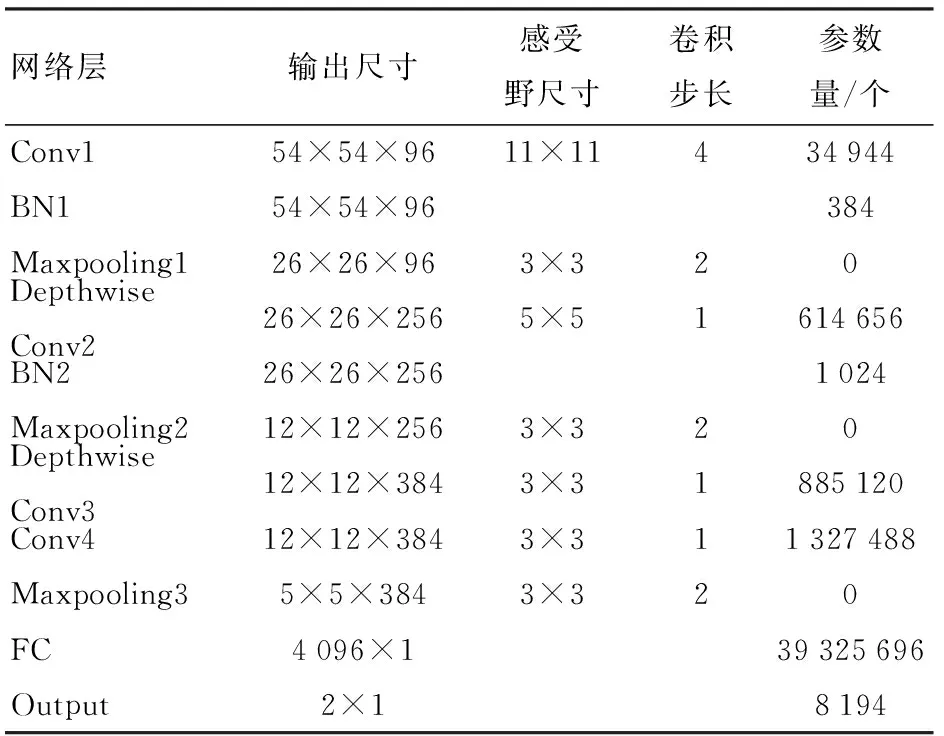
表1 CO-Net初始参数分布Tab.1 Initial parameters distribution of CO-Net
1.3.4卷积层结构的优化
深度可分离卷积认为卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果[26]。深度可分离卷积将传统的卷积操作(图5a)分为一个深度卷积操作和一个卷积核为1×1的传统卷积操作(图5b),通过此操作后可以减少卷积操作的参数量和计算量。假设输入特征图为DF×DF×M、输出特征图为DF×DF×N、卷积核为DK×DK,则传统卷积的参数量、计算量和深度可分离卷积的参数量、计算量为

图5 传统卷积与深度可分离卷积示意图Fig.5 Traditional convolution and depthwise convolution diagram
Cpara=DK×DK×M×N
(7)
Ccal=DK×DK×M×N×DF×DF
(8)
Dpara=DK×DK×M+M×1×1×N
(9)
Dcal=DK×DK×M×DF×DF+
M×N×DF×DF
(10)
式中Cpara——传统卷积层参数量
Dpara——深度可分离卷积层参数量
Ccal——传统卷积层计算量
Dcal——深度可分离卷积层计算量
深度可分离卷积与传统卷积参数量、计算量之比为
(11)
由式(11)可知,当卷积核尺寸大于1时,深度可分离卷积可有效减少模型参数量和计算量。因此,为了进一步压缩模型尺寸和提高模型训练速度,本文依次将第2~4层卷积层(Conv2~Conv4)替换为深度可分离卷积层(Depthwise Conv)。
2 结果与分析
2.1 批量尺寸对模型性能的影响
批量尺寸(Batch size)表示卷积神经网络在训练过程中每批训练使用图像的数量。合适的批量尺寸可以加快模型训练速度、减少训练时间。批量尺寸与模型训练梯度下降速度关系密切。本文进行了不同批量尺寸对模型性能影响的对比实验,结果如图6所示。由图可知,模型训练准确率和损失值分别随训练次数的增加而升高和减小。此外,随着批量尺寸的增大,训练收敛速度不断加快,但过大的批量尺寸会导致过多内存消耗,可能会导致程序崩溃,且当批量尺寸为64和128时,模型收敛速度相近,最终CO-Net网络选择批量尺寸为64进行训练。

图6 批量尺寸对模型训练效果的影响Fig.6 Effects of batch size on training accuracy and training loss
2.2 学习率对模型性能的影响
学习率(Learning rate)是卷积神经网络训练过程中很重要的一个超参数,学习率表示每次更新参数的幅度,合适的学习率可以加快模型训练收敛速度。本文比较了5个不同学习率对模型训练效果的影响,结果如图7所示。由图可知,模型训练收敛速度随学习率增加而加快。但学习率不能无限增大,当学习率过大时,需要优化的参数会出现波动而不收敛;而学习率过小,会导致待优化的参数收敛缓慢。本文网络模型在学习率为10-2时收敛速度最快,因此选择学习率为10-2进行训练。
2.3 归一化方法对模型性能的影响
对数据进行归一化操作可以提高模型泛化性能和加快模型训练收敛速度,因此选择合适的归一化方法对模型性能有重要意义。本文比较了无归一化层、局部响应归一化(LRN)和批量归一化(BN)对网络模型性能的影响,结果如图8所示。可以看出,未添加归一化层与添加LRN层的模型准确率基本一致,但模型训练时间由1.01 h增加到1.12 h,说明LRN层对模型识别准确率没有大幅度提升作用,还会增加网络复杂性,这与SIMONYAN等[19]的研究结果类似。然而,添加BN层网络的收敛速度比添加LRN层的快,模型训练时间由1.12 h减少为0.71 h,且训练准确率有所提高,可能是因为LRN层作用于特征图通道层面,而BN层作用于特征图整体数据且BN层中含有可学习的重构参数。另一方面,BN层解决了深层网络训练过程中由于网络参数变化而引起内部节点数据分布发生变化的现象。所以在CO-Net中使用BN层作为网络归一化层。

图8 归一化层对模型训练效果的影响Fig.8 Effects of normalization layer on training accuracy and training loss
2.4 激活函数对模型性能的影响
激活函数对CNN成功的训练起着重要作用。Swish激活函数具有非饱和、光滑、非单调等特点,其应用于图像分类、机器翻译等多个具有挑战性领域时,在深度网络上的表现优于或等同于ReLU激活函数[25],本文也得到了同样结果。图9为PReLU、ELU、ReLU和Swish激活函数对模型训练效果的影响。结果表明,Swish函数对模型收敛速度的影响比其他3个函数大,这可能是由于Swish函数在定义域上处处可导且在x为负值时,模型梯度仍然可以传递,从而避免了神经元死亡的问题。因此,在CO-Net中使用Swish函数作为模型激活函数。

图9 激活函数对模型训练效果的影响Fig.9 Effects of activation function on training accuracy and training loss
2.5 全连接层对模型性能的影响
全连接层是将卷积层学习到的局部特征整合为去除空间位置信息的全局特征,所以全连接层含有参数最多,是影响模型尺寸的重要因素。为了确定模型全连接层数量,本文将全连接层数量由零依次增加到2层,结果如图10所示。由图可知,当只有1层全连接层时,模型性能与拥有2层全连接层时没有明显变化甚至有所提高,但是当无全连接层时,模型性能明显下降,这可能是因为模型所有参数均包含在全连接层内,所以只有1层全连接层对模型性能影响不大,但全连接层包含的是去除空间位置信息的全局特征,全部删除将导致模型性能下降。为了进一步压缩模型,通过调整全连接层节点数量来寻找模型规模最优值。表2是全连接层不同节点数对模型的影响。由表2可知,减少模型节点数可以压缩模型规模,但是对模型训练时间影响有限,因为全连接层参数最多,而模型训练耗时主要来自卷积操作。综合模型测试准确率、模型尺寸和训练时间,最终CO-Net采用1层全连接层,节点数为256。

图10 全连接层对模型训练效果的影响Fig.10 Effects of fully connected layers on training accuracy and training loss

表2 全连接层节点数对模型性能的影响Tab.2 Effects of fully connected layers on performance of model
2.6 卷积层对模型性能的影响
卷积层通过不同尺寸感受野对图像进行卷积操作,提取图像局部特征,是卷积神经网络中最重要的组成部分,因此卷积层的设置对模型性能起着至关重要的作用。CO-Net是从零开始独立训练,在只有1层卷积层时,模型训练准确率和收敛速度均最低,模型性能随着卷积层层数增加而提升,但提升速度越来越慢,当卷积层数量为4时,模型性能甚至优于5层卷积层(图11),由此可见保证模型具有一定深度是必要的,但模型深度也不是越深越好,最终确定CO-Net卷积层层数为4层。为加快模型训练速度、降低模型训练时间,本文对卷积层感受野数量进行调整,结果如表3所示。结果表明减少模型感受野数量不仅可以减小模型规模,更重要的是可以大幅降低模型训练时间。子模型1与子模型3相比,模型规模由40.60 MB减少为8.47 MB,训练时间由4.30 h减少为1.16 h,而测试准确率基本保持不变,原因是卷积层拥有大量卷积操作,需要消耗大量时间,减少感受野数量可以减少卷积操作,降低模型训练时间。此外,本文还将传统卷积层替换为深度可分离卷积层,结果如表4所示,深度可分离卷积层可以有效减少模型参数量以达到压缩模型的效果和减少模型计算量以达到加快模型训练的效果。当模型第2、3层卷积层替换为深度可分离卷积层后,模型规模由原来的8.47 MB进一步减小为1.65 MB,模型训练时间减少一半而模型精度仅轻微下降,使其更适合在嵌入式系统上使用,可以用于硬件配置较低的分选设备。实际使用时,应当根据软硬件条件,挑选适合实际生产的模型。

图11 卷积层对模型训练效果的影响Fig.11 Effects of convolution layers on training accuracy and training loss

表3 卷积层感受野数量对模型性能的影响Tab.3 Effects of number of LRFs on performance of model

表4 深度可分离卷积层对模型性能的影响Tab.4 Effect of depthwise convolutions on performance of model
2.7 模型性能比较
本文将模型性能表征参数(训练准确率、模型规模、训练时间和测试准确率)作为目标参数,将CO-Net与其他经典模型(AlexNet、MobileNet V1、MobileNet V2、MobileNet V3[26]和SqueezeNet[27])进行比较,结果如表5所示。由表可知,采用不同模型结构时,模型性能不同,其中AlexNet模型训练时间最长,为9.43 h,测试准确率为98.33%,但其模型规模最大(356 MB),不适用于油茶籽在线分选设备。MobileNet V3_Large在轻量级网络中模型规模最大,训练时间为5.52 h,其测试准确率达到了97.26%。本文提出的CO-Net测试准确率达到了98.05%,而模型规模和训练时间分别是MobileNet V3_Large的1/38和1/10,且单幅图像检测平均耗时仅13.91 ms。通过比较可知,CO-Net更适合用于油茶籽在线分选。

表5 CO-Net与不同经典模型性能比较Tab.5 Performance comparison between CO-Net and different classical models
3 结论
(1)以批量归一化(BN)作为模型归一化方法,提高了模型的训练收敛速度和模型的泛化性能。Swish函数可有效解决ReLU激活函数出现神经元死亡的问题,提高了模型的准确率和训练收敛速度。
(2)CO-Net网络具有4层卷积层、2层归一化层、3层池化层和1层全连接层,4层卷积层和1层全连接层的节点数分别为32、64、128、128和256,第2、3卷积层采用深度可分离卷积层,使模型规模减小为原来的1/5,且训练时间缩短一半。模型选择训练批量尺寸为64,学习率为10-2。
(3)CO-Net网络对油茶籽完整性的识别准确率达98.05%,与MobileNet V3_Large模型相当;但训练时间大幅缩短,为0.58 h;模型规模大幅减小,为1.65 MB;单幅图像检测平均耗时13.91 ms,可满足油茶籽在线实时分选的要求。
