我国食品安全与数据科学交叉研究的科学计量学分析
2020-07-23宋英华李墨潇雷生姣库任俊夏亚琼
邵 航,宋英华,*,李墨潇,*,邵 伟,雷生姣,库任俊,夏亚琼
(1.武汉理工大学中国应急管理研究中心,湖北 武汉 430070;2.安全预警与应急联动技术湖北省协同创新中心,湖北 武汉 430070;3.武汉理工大学安全科学与应急管理学院,湖北 武汉 430070;4.三峡大学生物与制药学院,湖北 宜昌 443001)
食品安全关系人民群众身体健康和生命安全,关系中华民族未来[1]。以食品安全突发事件为研究对象,深入开展演化机理、检测技术和预警方法等方面的研究,能够帮助政府及时采取有利的措施,预防食品安全问题的再次发生,已经得到党和国家的高度重视[2]。
数据科学是基于传统的数学、统计学的理论和方法,运用计算机技术进行大规模数据计算、分析和应用的一门学科[3]。它是一门既古老又年轻的科学,其渊源可以追溯至1749年起源于瑞典的统计学[4];随着计算机技术的发展与大数据概念的兴起,数据科学又逐渐成为大数据技术的代名词。大数据时代的到来使得数据科学逐步演变成了一门“立足现代、面向未来”的显学;而公共安全领域对大数据挖掘与利用的迫切需求加剧了全社会对数据科学人才的需要;同时,这种社会需求导向又反向显著地提升了数据科学在公共安全各个子领域中的学科地位。
随着社会信息化程度的提升与信息储存方式的变革,食品生产与消费的各个环节已经积累了海量异构的食品安全历史数据,且仍在源源不断地产生着新的食品安全大数据。在大数据时代的背景下,大数据技术方法相比起传统的研究方法,在处理海量的食品安全数据时显得更加对口和有效。
已发表的科技论文是经过同行评议,且其主题被认为是隶属于该领域的论文[5]。因此,从已发表的学术论文中识别并探测某一特定研究主题是被实践证明的可靠方法[5]。基于此种假设,本文选取中国知网(China National Knowledge Infrastructure,CNKI)数据库中食品安全研究与数据科学存在交集的科技文献作为我国食品安全与数据科学交叉研究的样本数据集,运用科学计量学理论,主要使用科技文本挖掘软件Citespace对文献数据进行深度挖掘。
本文将从所收集的文献数据的特征出发,开展本交叉研究的研究主体分析与研究主题分析,以期从文献数据空间中发现本领域重要的研究机构、期刊和作者,并进一步地发现本领域当前的研究热点与未来的发展趋势。
1 数据与方法
1.1 数据采集与预处理
本文所收集的数据全部来源于CNKI。考虑到文献题录数据的更新会有迟滞,本研究以2019年5月20日0时为截止时间,以“主题 = 食品安全 AND 数据”为检索条件,收集了1996年1月至2019年5月跨度约23 年的3 375 条文献数据,文献类型包括期刊论文、学位论文、会议论文和报纸图书等。文献数据以Refworks格式(包含文献类型、作者、作者单位、标题等主要科学计量字段)存储为UTF-8编码的.txt文件到本地路径备用。同时,使用Python爬取检索页面分年数据的完整信息,并写入Excel文件。
1.2 科学计量学方法与科技文本挖掘软件
科学计量学是运用数学等定量方法对科学的整体及其各个方面进行定量化研究,以解释科学发展规律的一门新兴学科[6]。传统的科学计量学研究方法主要有出版物统计、著者统计、引文分析、词频分析等[7]。
Citespace是由美国德雷塞尔大学信息科学与技术学院的Chen Chaomei教授应用Java语言开发的一款信息可视化软件[8],本研究使用的是该软件的5.1.R8.SE.版本。它主要基于共引分析理论和寻径网络算法等,对特定领域文献(集合)进行计量,以探寻出科学领域演化的关键路径及知识转折点,并通过一系列可视化图谱的绘制,来形成对科学演化潜在动力机制的分析和学科发展前沿的探测[9]。
2 结果与分析
2.1 交叉研究的研究主体分析
2.1.1 文献年代分布
对数据集进行分类检索可知:其中期刊论文记录1 604 条,博、硕士学位论文记录1 599 条,会议论文记录71 条,这3 类文献体例占总体文献的97.01%。进一步地对期刊和博、硕士学位论文的年累计量进行多项式回归预测,发现当多项式阶数由2阶增加到4阶时,预测精度不再随着方程阶数的增加而增加,故采用4阶多项式预测。
文献累计量的分年统计及回归预测见图1,期刊论文、学位论文累计数量预测曲线的R2均达到99%以上,证明回归模型的拟合优度很高。曲线数值的增长具备某种指数型趋势,而此处依据泰勒公式原理,以多项式函数来近似计算指数函数值,通过设置预测点,可以推测:本领域期刊论文总量有望在2019年达到1 940 篇左右,在2020年达到2 340 篇左右;本领域学位论文总量有望在2019年达到1 810 篇左右,在2020年达到1 950 篇左右。在2007年以前,期刊论文的累计量高于学位论文的累计量,这表明1996—2007年交叉研究还处于讨论与积累的萌芽阶段,尚未形成较完备的学科形态;2007—2019年学位论文的累计量高于期刊论文的累计量,这表明从事交叉研究的人越来越多,交叉研究的热度在不断提高,社会的重视程度也在不断提高;预计2019年会成为期刊论文数量第二次超过学位论文数量的转折点,这将标志着交叉研究会逐步形成新的学科增长点,推动新一阶段的交叉研究发展。
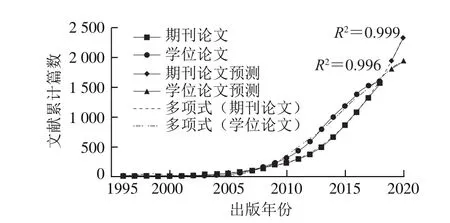
图1 我国食品安全与数据科学交叉研究的文献累计量分年统计与预测Fig. 1 Accumulated annual statistics and prediction of literature on cross-disciplinary studies on food safety and data science in China
2.1.2 重要机构分布
使用CNKI数据库的“分组浏览-机构”功能,可以查询到当前学科领域中重要机构的信息(以发文量统计,列表机构最低发文量为14 篇)。由表1可知,发表论文30 篇及以上的机构有18 家,所发表的论文占全部3 375篇文献的26.93%,属于引领本领域研究的核心机构群体。

表1 1996—2019年我国食品安全与数据科学交叉研究领域文献产出量前18的机构Table 1 Top 18 most prolific research institutions in terms of crossdisciplinary studies on food safety and data science in China (1996-2019)
在本领域发表论文的数量与该机构研究人员的数量、获得相关科研项目的数量密切相关。例如:在南京农业大学所发表的论文中,李太平教授团队的研究成果最多,共有6 篇论文,主要受到国家自然科学基金面上项目“生鲜农产品质量安全的监管机制研究”(71173114)的资助;在浙江大学所发表的论文中,杜树新副研究员及其团队的论文数量最多,共有5 篇,主要受到国家科技攻关计划资助项目(2001BA804A34)的资金支持。
2.1.3 重要期刊与学位授予单位分布
使用Excel 2016软件的数据透视表功能,对所收集的3 375 条题录数据的“期刊名称”或“学位授予单位”字段进行数据透视,可以得到期刊论文文献的来源期刊或学位论文的学位授予单位的统计信息。共有1 611 篇与本主题相关的期刊论文被刊载在684 种学术期刊上,平均载文量为2.36 篇/刊。由表2可知,集中刊载本领域论文10 篇及以上的期刊有18 种,载文数量达438 篇,占全部期刊论文的27.19%,在期刊分类[10]上分属于4大类,其中“食品科学技术”和“农业综合”分类占大多数。
共有1 598 篇与本主题相关的学位论文来自248 个不同的学位授予单位,平均载文量为6.44 篇/机构。由表3可知,学位论文数量在20 篇及以上的机构有17 家,论文数量达到650 篇,占本领域学位论文总量的40.68%。其中,农林类与综合类高校涉足食品安全与数据科学交叉研究领域的数量相较于其他类别更多。
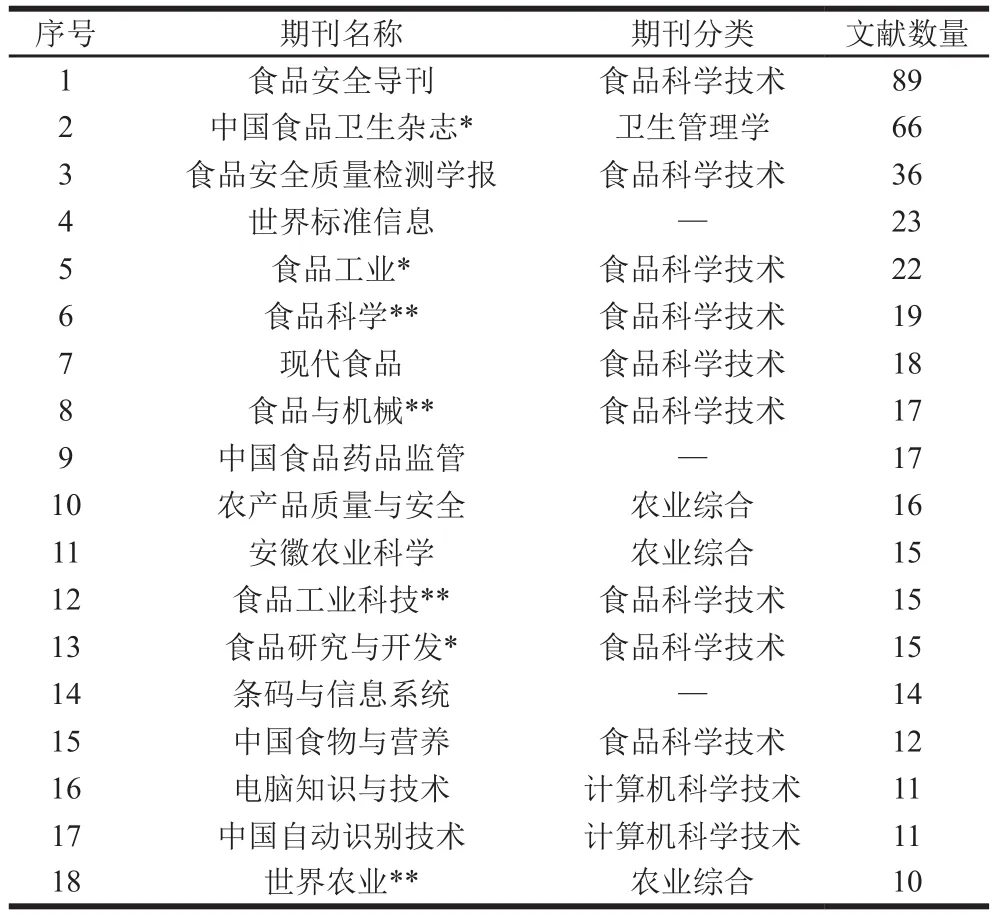
表2 交叉研究期刊论文的来源期刊分布Table 2 Journal distribution of published papers on cross-disciplinary studies on food safety and data science

表3 交叉研究学位论文的学位授予单位分布Table 3 Degree conferring institution distribution of dissertations on cross-disciplinary studies on food safety and data science
本文通过文献[11]的方法,统计载文数量、载文数量的出现频数、出现概率和累计概率,得到了期刊论文和学位论文的频数与概率分布表。使用Origin Pro 9.1软件对上述数据进行概率分布模型的拟合检验,得到图2。
图2A、B分别表示本领域期刊论文载文数量和学位论文载文数量的概率分布拟合曲线,决定系数分别为0.999 9、0.999 6,具有很高的拟合优度。所以两种文献的载文数量的概率分布都服从异速生长指数(Allometric)分布。这表明我国食品安全与数据科学交叉研究领域经过萌芽与积累,研究规模正在高速增长。根据异速生长尺度规律[12]的特点,我国食品安全与数据科学交叉研究所形成的这个特定的食品安全子领域,可以看作是一种广义的生态系统,而本主题新科技论文的产生则是这个生态系统中最重要的信息流之一。自身的主题与偏好适合这个子领域的优质文献被刊载的期刊,或者重视这个新兴子领域发展的研究机构,会在这个新兴子领域里快速生长,显得愈发重要。

图2 期刊论文(A)和学位论文(B)载文数量的概率分布拟合Fig. 2 Fitted probability distribution of the number of papers published in journals (A) and degree papers (B)
2.1.4 重要作者分布
关于论文合著情况,共有3 619 人次的作者参与撰写了这1 611 篇期刊论文,平均作者为2.24 位/篇,即作者合作度[6]为2.24。使用CNKI数据库的“分组浏览-作者”功能,可以查询到当前学科领域中高产作者的信息,本文将所述高产作者中发文数量大于5 篇的作者信息进行整理。同时,为了客观地评价各位高产作者在论文合著中对其论文的贡献度,本文引入了Du Yongping等2015年提出的基于作者顺序的影响力计算方法,该方法适用于大数据环境下具备统计意义的计算[13]。该方法的算理实质是:先计算除第一作者以外其他作者的分配得分(以百分数计),再反向用总贡献值倒减出第一作者的得分,其计算见下式。
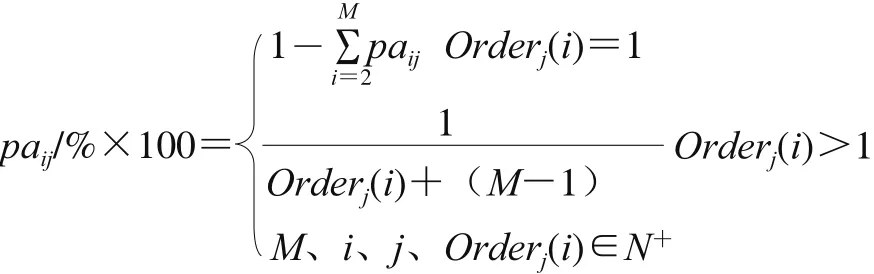
式中:paij表示论文署名次序为i(即Order(i))的作者对其论文j的规范化贡献值;M表示该论文的作者总数。
本文使用pa链来记录作者的署名和排位情况,如:5(2)表示该作者的某一篇论文共有5 位作者,其为第2作者(若为通信作者,则视为第一作者;若存在并列一作,也视为第一作者;特殊情形(比如通信作者)将以“*”标记,如:5(2*),计分为5(1))。根据公式(1)进一步计算累计pa和平均pa,并将以上字段信息合并为表4。
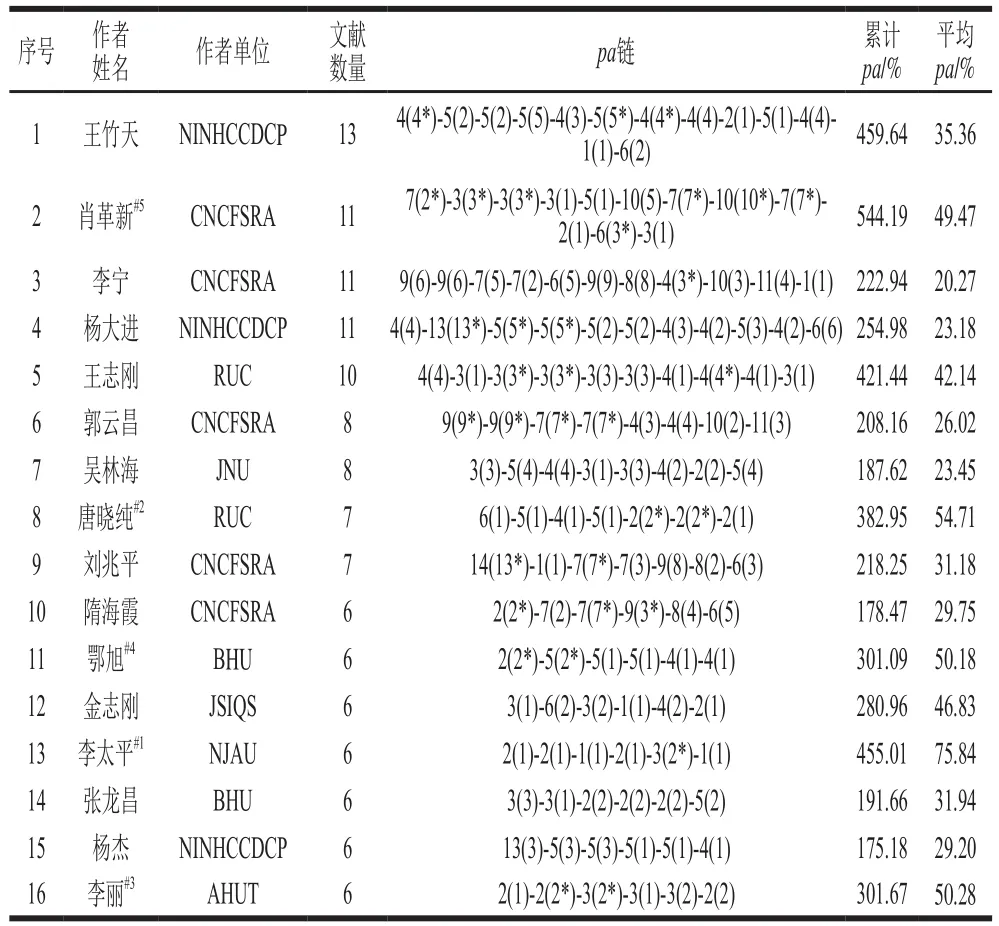
表4 本领域发文数量大于5 篇的高产作者和pa链Table 4 Productive authors publishing more than 5 papers and their pa chain in this field
由表4可知,这些高产作者中,平均pa前5 名分别是:李太平、唐晓纯、李丽、鄂旭、肖革新,他们应该是本领域研究合作的优秀候选人。从累计pa来看,王竹天、王志刚也是本领域具备合作潜质的优秀候选人。
2.2 交叉研究的研究主题分析
2.2.1 关键词共现分析
本文使用对数似然率(log-likelihood rate,LLR)算法对关键词共现网络进行聚类分析,得到了具有11 个主要聚类的关键词共现网络图谱(图3),这些聚类的轮廓值(Silhouette)均大于0.5,且部分大于0.7,说明这些聚类合理且令人信服[14]。这11 个聚类可以进一步归纳为3大类(表5),即:食品安全领域的新型数据采集技术(类I)、食品安全领域的新型数据分析技术(类II)、食品安全领域的新型数据科学应用(类III)。
由图3可知,1996—2019年我国食品安全与数据科学交叉研究领域形成了内部边界聚合且外部边界分明的复杂关键词共现网络图谱。该图谱有405 个节点和1 543 条连线,是一个由大量高频关键词形成的广阔知识空间。以下将根据引文空间聚类成员的归属和食品安全意义上的类别界定,以大类(I、II、III)划分为展开顺序,对所得到的关键词共现网络图谱进行深入的分析。
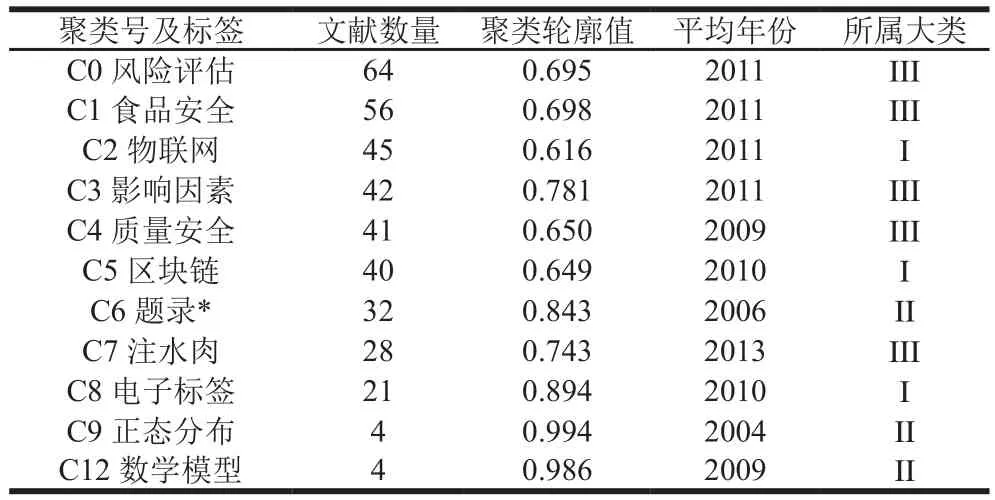
表5 关键词共现网络的聚类信息Table 5 Clustering information of keyword co-occurrence network
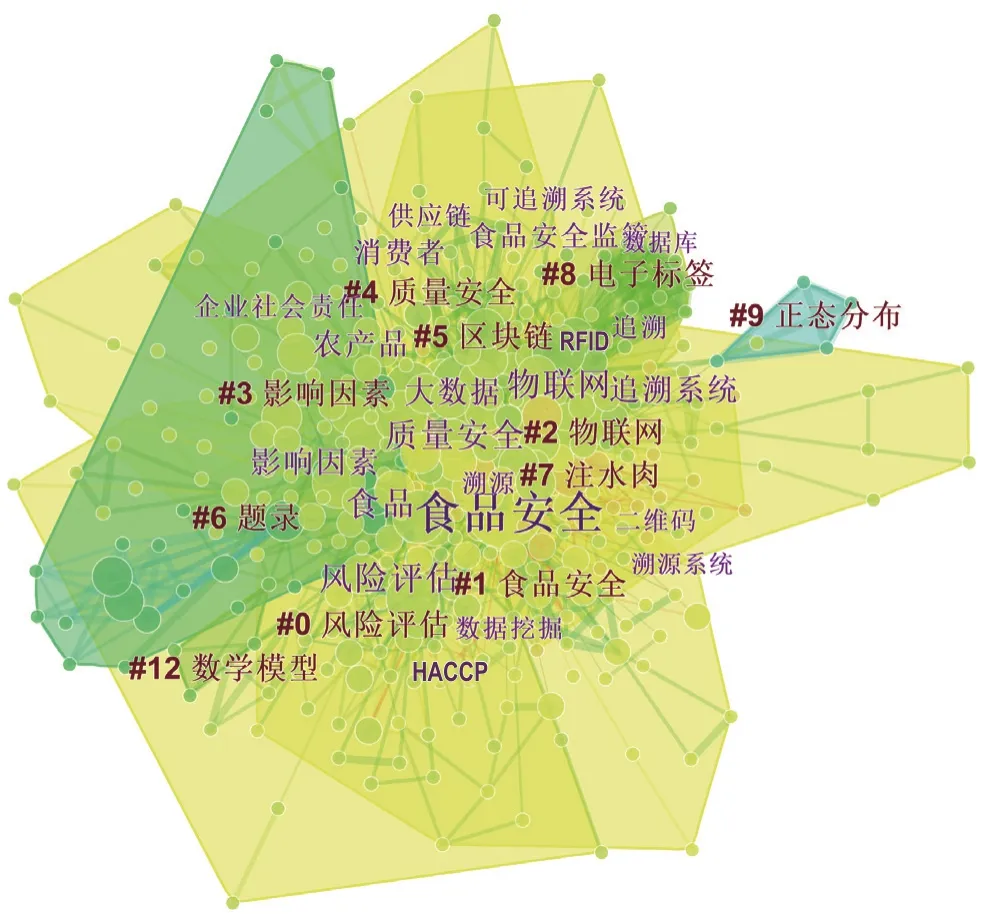
图3 我国食品安全与数据科学交叉研究的关键词共现网络图谱Fig. 3 Keyword co-occurrence network map of cross-disciplinary studies on food safety and data science in China
2.2.1.1 食品安全领域的新型数据采集技术
在大数据时代的背景下,物联网、区块链和电子标签等技术成为了采集新型食品安全数据的重要支撑技术。将网络嵌入食品生产流通各环节的物理设备,有利于提升食品供应链的智能化,完善食品溯源体系。尚培培等[15]研究了具备感知层、网络层和应用层3 层架构的产品电子代码(elctronic product code,EPC)物联网在牛肉供应链安全中的应用,实现了牛肉产品标准化唯一标识、不合格牛肉溯源追踪、全程信息共享3 个层面的食品安全保障。区块链技术的数据分布式储存与数据不可删改的特性将对食品从生产到零售的整个商业过程起到某种监督与净化作用。颜波等[16]设计并开发了基于RFID和EPC技术的具有企业、政府部门和消费者3 个追溯主体的罗非鱼供应链可追溯平台,在罗非鱼上架销售前一直使用可循环RFID标签,实现了销售前的全程追溯;而零售端顾客则可以通过独立包装外的条形码标签溯源,提升了生鲜食品安全监管的效率,满足了顾客的食品安全需求。
2.2.1.2 食品安全领域的新型数据分析技术
数学模型方法结合新兴的人工智能技术应用于食品安全领域,提升了食品安全数据及其分析挖掘技术在食品安全治理中的功能与地位。晁凤英等[17]对某出入境检验检疫局提供的食品安全检测数据,使用广度优先的Apriori算法进行了关联规则数据挖掘,并对挖掘出的几条有代表性的关联规则进行了解读,由此提炼出食品安全抽检的优化策略。质量控制图是一种简单、有效的统计技术[18]。带有上中下控制界限的、以检测食品生产过程安全和判断食品质量稳定状态为目标的控制图,已经逐步演化和固定为食品质量安全过程控制的专门化数据分析方法。秦燕等[19]使用控制图工具进行危险检出物指标预警,对广州食检中心某时段内的出口茶叶中的六氯环己烷和白兰地酒中的甲醇的检测数据进行统计分析,提出了Y-Pn控制图、C-Pn控制图、J-Pn控制图和-δ控制图4种预警方法。
2.2.1.3 食品安全领域的新型数据科学应用
以数据密集型科学发现的研究范式,研究前沿且恰当的食品安全问题,是数据科学应用在食品安全领域的一种使命。因为面向主体对象不同,故其应用场景和应用需求也不相同[20]。所研究的对象是当前层出不穷的各类食品安全事件及危险源,如:使用主成分分析-最小二乘支持向量机预测模型鉴别地沟油[21]、使用层次分析法(analytic hierarchy process,AHP)评价水产品孔雀石绿的残留风险[22]、使用SGompertz-SLogistic生长动力学模型预测清蛋糕中金黄色葡萄球菌的生长速率[23]等;所研究的内容是在宏观层面上食品安全水平提升所亟待解决的各种问题,如:使用关联规则算法探寻食品质量安全保障的关键因素[24]、使用循环神经网络算法对食品安全描述文本的情感倾向进行分类[25]、通过构建贝叶斯网络对白酒质量安全进行预测[26]等;交叉研究所受益的主体及研究方向包括:政府的智慧监管与风险预警[27-29]、食品企业的生产控制与事后应对[30-32]、消费者的食品安全风险认知与支付意愿[33-35]等。
2.2.2 时间线聚类分析
使用Citespace软件进一步绘制关键词共现网络的时间线图谱,由图4可知,我国食品安全与数据科学交叉研究的各研究主题存续时间不同。例如:聚类C0、C1和C2存续时间都接近20 年,而且从聚类产生到现在一直是活跃的聚类;而另一些聚类的存续时间则相对较短,例如:聚类C6、C7和C8,存续时间只有大约7~10 年,且目前已经不再是该主题研究热度最高的时段,这些主题都具有从存续时间长的主题中分化产生的特点。图中的这些颜色与流向表征着我国食品安全与数据科学交叉研究的不同发展阶段。
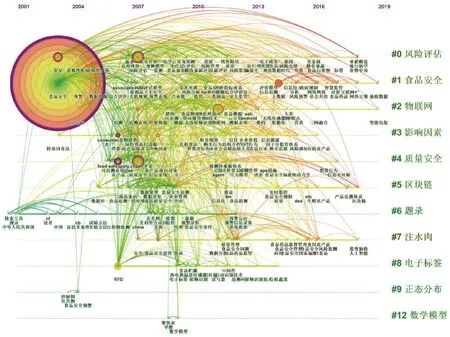
图4 我国食品安全与数据科学交叉研究的关键词聚类的时间线图谱Fig. 4 Keyword clustering time-line atlas of cross-disciplinary studies on food safety and data science in China
1996—2006年为重视食品标准数据与传统数理统计方法的阶段。此阶段的科技文献主要侧重引进国外先进的食品安全标准并与我国的食品安全标准进行比较[37-39];在数据分析上多基于HACCP系[40-42]、调查问卷方法和数理统计工具[43-45]。
2007—2014年为新型食品安全数字技术和数学模型方法开始涌现的阶段。此阶段层次分析法[46-47]、贝叶斯网络[48]、关联规则[49]、决策树[50]、可拓决策[51]等数学模型方法被广泛地应用于食品安全风险评估和风险预警等方面;RFID[52-54]、QR二维码[55-56]、同位素指纹[57-58]等技术被广泛地应用于食品质量安全追溯领域。
2015—2019年为大数据与人工智能开始广泛地应用于食品安全各子领域的阶段。此阶段计算机视觉[59]、电子鼻与电子舌[60]、模式识别[61]等基于人工智能的食品安全无损检测技术得到应用;基于区块链技术的可追溯平台[62]、基于大数据的社会共治模式[63]、食品安全大数据的可视化分析方法[64]、基于大数据的食品安全风险分析[65]等由大数据技术驱动的食品安全智慧监管技术与模式正在探究与实践中。
2.2.3 关键词突现分析
本文采用Kleinberg突发事件检测算法[66]来探测文献空间中的突现词,Citespace软件会从论文题目、关键词和摘要等字段中提取候选专业术语,通过跟踪分析它们在不同时间区间内出现频率的突然变化(激增),识别出代表研究前沿的若干名词术语[67]。运行程序后,Citespace找到了47 个突现关键词,将突现度前50%的突现词按照其突现起止时间的升序排列得到表6。
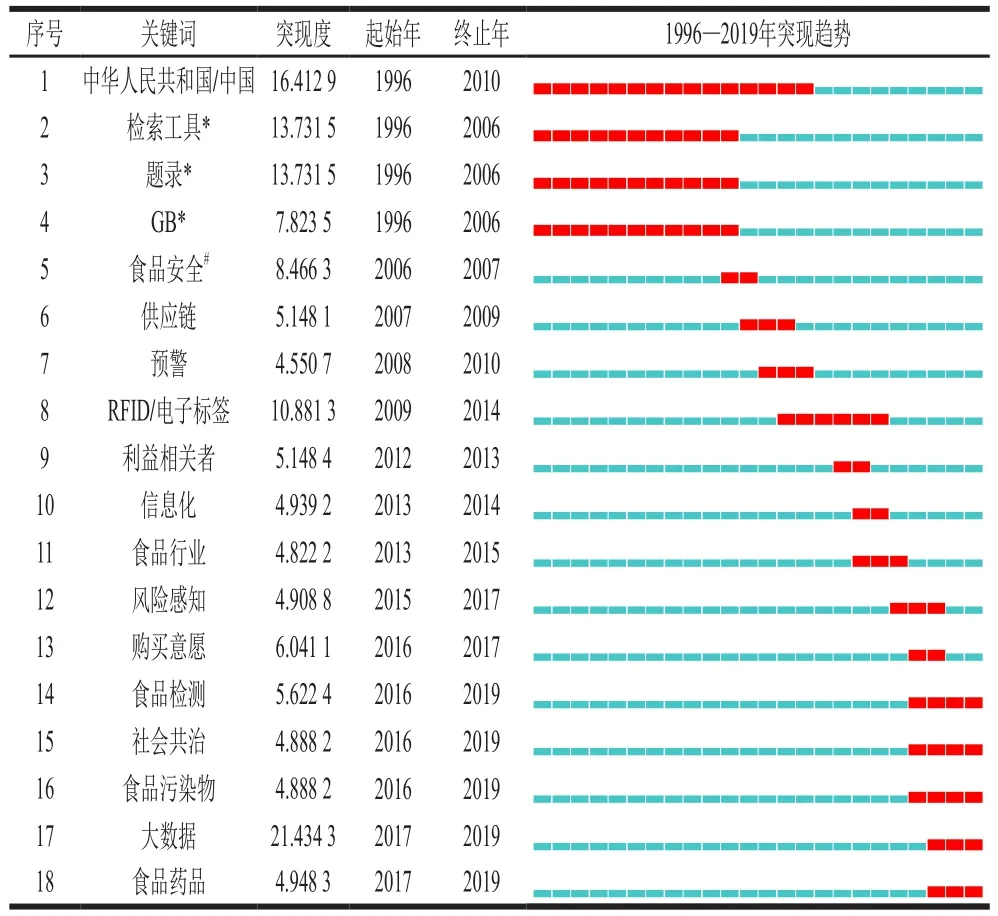
表6 突现度最高的前50%的关键词Table 6 Top 50% keywords with the strongest citation burstness
从表6可以看出,不同年份本领域的研究者所关注的研究热点不同。根据表6可以进一步把我国食品安全与数据科学交叉研究的热点演进划分为3 个阶段,与时间线聚类分析的年代划分相吻合。1)1996—2006年为重视国外食品安全标准的引进及与我国食品安全标准开展比较研究的阶段,“检索工具”、“GB(国家标准)”是这一阶段的突现词。2)2007—2014年,突现词“RFID”和“电子标签”代表了新型食品数字溯源技术的研究方向;突现词“利益相关者”与“食品行业”代表了与食品企业有关的研究方向;突现词“供应链”与“预警”等代表了与食品安全风险控制有关的研究方向。3)2015—2019年,突现词“大数据”代表了数据密集型科学发现的研究范式;突现词“风险感知”、“购买意愿”和“社会共治”等代表了这一阶段涌现出的研究热点。
3 讨 论
3.1 交叉研究当前的研究热点
3.1.1 新型数据采集技术与食品溯源及网络舆情的研究在食品从农田到餐桌的流通过程中,食品及其有关主体的多重属性被计量和记录,产生了食品关联属性的数据化基础[68]。以保障食品质量或数量安全为目的,提取这些数据,则产生了海量的食品安全数据。数据采集技术的发展使得文本资料、社会关系、地理方位等不易被提取的数据变得可被利用;使得政府、企业、检测机构、行业协会、媒体和消费者这6 类食品安全社会主体[20]所产生和需要的结构化、半结构化和非结构化数据[69]被各种技术手段收集和储存,以备挖掘与利用。
一方面,RFID和传感器、物联网等面向现实世界中食品理化数据的数据采集技术,推动了食品安全溯源技术的发展。圣光磊[70]通过改进滑动窗口射频识别数据分析-目标自适应射频识别数据分析(statistics moothing for unreliabler fid data-dynamic tags-based SMURF,SMURF-DSMURF)算法中数据完整性和标签动态性条件,设计了新的更高效的多层级射频识别数据分析(multi label DSMURF,MDSMURF)算法,并应用于白芍饮片溯源系统中,提高了数据噪声的清洗效率和多标签动态的阅读效率。钟聪儿等[71]将ALOHA算法应用于基于RFID技术的茶叶物流溯源系统中,并设计了仿真实验,结果表明:通过解决硬件不兼容、信息冗余等问题,能够显著地提高追溯系统的响应效率。
另一方面,网络爬虫及数据接口等面向虚拟世界中的食品资讯数据的数据采集技术,推动了食品安全舆情研究的发展。程铁军等[72]使用网络爬虫技术在线获取了2011—2014年总贴数达50万以上的超热度食品安全新闻事件15 例,并构建了4大类11小类的食品安全风险预警指标,通过粗糙集理论进行属性简约计算,从高热度舆情事件中提炼出易引发食品安全事件的关键食品流通环节,为源头管理和社会共治提供了针对性建议。洪小娟等[73]以所收集的包含588 个媒体微博节点的2014年食品安全微博舆情事件为数据集,使用Pajek软件进行了社会网络分析特有的网络结构、度、K-核以及派系分析,发现了食品安全新闻传播的核心节点、媒体派系以及传播模式,为食品安全舆情的利用与引导提供了可参考的建议。
3.1.2 新型数据存储技术与食品数据仓库及预警系统研究
大数据及其应用技术的爆炸式发展所产生的数据存储需求推动了数据存储技术的发展。大规模并行处理机(massively parallel processor,MPP)存储架构、Hadoop技术和分布式计算等新兴技术,让已经长期存在的食品安全大数据有了被规范化存储和多元化挖掘利用的可能性,尤其是基于数据库的食品安全预警系统,是当前研究的重要热点形态。郭曙超等[74]以山东地区进出口食品检测实验室的检测数据为数据集,根据食品安全工作需要,设计数据字典和体系架构,建立了“进出口食品与农产品实验室检测数据仓库系统”,该系统可进行数理统计、可视化分析与数据挖掘,能够实时掌握食品安全状况的动态,可以为食品安全管理人员提供高质量的决策依据。刘翠玲等[75]使用Eclipse开发环境和Java语言,设计并开发了一种基于多源大数据的食品安全监测预控系统,该系统后台采用My SQL关系数据库,实现了拉曼光谱仪数据的导入、分析与预警。黎建辉等[76]以云计算、云存储、分布式计算框架为系统主体,结合信息爬取、模式识别以及深度学习技术等,设计并开发了全球食品安全信息监控与分析云平台,通过对近5 000 个信息源的固定周期爬取与监控,成功地预警出了矿泉水水源污染事件、病死猪肉流入市场事件以及保鲜膜中塑化剂超标事件等具有重大社会影响的食品安全事件。
3.1.3 新型数据分析技术与食品安全智能解决方案研究
应用数据科学模型方法体系中的有监督学习、半监督学习和无监督学习[77]的各类算法对海量的食品安全数据进行计算分析,可以为食品安全的信息探测、数据预测和风险评估等各方面带来更加智能化的解决方案。刘金硕等[78]提出一种基于隐狄利克雷分配模型(latent Dirichlet allocation,LDA)的K平均值(K-means)聚类的网络食品安全问题话题发现算法,并以网络爬取的2017年包含43 个食品安全分类的1 920 条新闻报道为数据集,通过LDA-K-means算法进行聚类,以此发现新的食品安全话题,并与传统的向量空间模型(vector space model,VSM)算法进行了比对,实验结果表明,LDA-K-means算法相对于传统的VSM算法聚类效率更高,更加利于快速探测网络中新的食品安全问题话题。陈国庆等[79]使用基于荧光光谱和径向基函数神经网络,对光谱仪发射波长的网络特征参数进行训练,并对胭脂红溶液样本的浓度进行预测,结果表明,该方法对食品色素溶液种类识别的准确度接近100%,可应用于合成食品色素检测及食品安全监管。赵静娴[80]以2005—2009年华北地区20 个蔬菜种植基地的调查数据和国家农业科学数据中心的共享数据为数据集,抽取82 个样本作为训练集,抽取10 个样本作为验证集,应用决策树算法进行食品安全评估,提取了5 条规则,与验证集对比的准确率达到了90%,说明该方法能够有效指导农产品质量安全的提高方向。
3.1.4 新型数据可视化技术与食品安全决策辅助研究
食品安全数据可视化分析作为一个新兴的交叉研究领域,通过先进的交互式可视化工具帮助食品安全领域人员快速分析数据的分布态势、探寻数据间隐含关联、提升认知和分析能力、提高食品安全监管的科学性和有效性[81]。陈谊等[81]在分析食品安全大数据特征的基础上,使用了数据地图、ThemeRiver、双曲树、TimeWheel和SolarMap等新型图表,展示了时空数据、层次数据、多维数据和关联关系的数据可视化形式,为提升数据可视化的易用性和辅助食品安全决策的可靠性提供了技术路径。陈红倩等[82]提出了一种基于Open GL图形库与统计数据的农残检测数据的融合对比可视化方法,该方法可将一定规模的农残数据根据其所属的地区和类别进行分类统计,并将多个统计结果融合到一个可视化界面中,可对农残检测数据进行快速展示,并以此进行分析和预判,为有关专家进行农产品安全快速决策提供研判依据。杨璐等[83]提出了一种挖掘数据关系的可视分析图ExploreView,以国家食品药品监督管理总局抽检数据为数据集,使用立方体隐喻组织数据,进而完成数据编码,综合使用层次图、细节描述图和关系挖掘图等新式可视化图像,实现对数据的展示和交互,为食品质量安全的监测和预警提供决策帮助。江美辉等[84]以“上海福喜过期肉”事件新闻文本为研究对象,基于复杂网络理论,使用Gephi软件对非结构化的文本信息进行了拓扑特征分析和关联网络挖掘,结果表明,食品安全事件新闻报道的关注点具有集聚性,且关注点会随着时间推移而变化,该研究挖掘出了新闻实体间的隐含关系,为有关部门对食品安全突发事件的应急管理提供了决策依据。
3.1.5 面向对象的食品安全大数据技术应用研究
面向食品安全治理的不同社会主体的数据特征和数据需求的应用研究,是目前交叉研究的重要横向层面。总体来看,政府需要食品安全智慧监管类的研究。张亮等[85]提出了面向智慧型城市的食品安全监管体系,该体系基于感知网络发现与采集数据,基于云储存规划与分析数据,基于大数据技术挖掘与预测数据,为智慧城市食品质量的安全预警和应急管理提供了参考路径;食品企业需要产品质量与舆情安全类的研究,席磊等[86]提出了一种分布式无公害农产品数字认证系统,该系统具有中心化分布式拓扑结构,使用元数据、工作流和Web Service技术,可实现跨部门、跨地域的协同工作和高效认证的系统功能;检测机构需要共享分析和能力评价类的研究,沐晓馥[87]提出了一种基于AHP算法的检验检测机构检测能力管理信息系统绩效评价方法,该方法基于AHP算法设计了具有4 个一级指标和10 个二级指标的评价指标体系,用于量化评价不同检测机构的检测能力管理信息系统的绩效,为有关单位进行系统选型提供了实际的决策依据;行业协会需要行业自律和治理参与方式类的研究,刘根华等[88]以浙江省金华市为例,应用数据统计分析方法分析了行业协会参与食品安全社会共治的现实困难,提出了“政府职能前移”和“五方联动机制”等有益对策;媒体需要治理策略和信息查询类的研究,谢康等[89]基于Kahneman-Tversky前景理论和博弈论方法,定量化分析了媒体参与食品安全社会共治的条件,借助MATLAB软件进行系统仿真,得出媒体可采取的“提高违规者声誉损失度”、“持续跟踪调查或深度报道”、“动态监督”和“媒体群监督与共治代表制度”4 种有效策略;消费者需要风险感知和购买意愿类的研究,张宇东等[90]使用数理统计方法分析了所设计、发放与回收的550 份有效调查问卷,定量化地揭示了食品安全风险感知下,消费者的量化信息偏好、购买意愿和决策逻辑,结果表明,对食品安全风险严重性的主观判断会显著提升消费者对食品安全量化信息的偏好,而这种偏好会反向刺激消费者量化消费,以应对所认知的食品安全风险。
3.2 交叉研究未来的发展趋势
随着大数据时代的到来以及数据挖掘技术在食品安全领域的应用,数据科学在食品安全各领域的地位将会越来越重要,食品安全监管也将向着更加智能化的方向发展,社会食品安全水平必然会得到更加显著的提升。数据科学的发展是推动交叉研究进步的重要推动力,食品安全研究的发展过程中对数据科学产生的新需求是引领交叉研究进步的重要牵引力。从数据科学的发展趋势来看:数据可视化、文本挖掘与自然语言处理、社交网络分析、计算机视觉和高性能计算等会成为未来的大数据技术前沿[91]。若将这些前沿技术投射到食品安全领域,则会带来如下的未来研究热点:1)计算机视觉技术的发展将推动食品无损检测技术的研究;2)自然语言处理能力的提升将推动食品安全网络舆情处理的研究;3)各种机器学习算法的进步将推动食品安全历史数据的知识发现以及决策支持的研究;4)食品安全大数据的云储存与人工智能服务的需求将持续扩大,其产业化的研究将得到蓬勃发展。
4 结 语
在近23 年的发展历程中,我国食品安全与数据科学的交叉研究从零星的学科交集萌芽,逐渐发展出一个新兴交叉学科的雏形,目前正处于新的快速增长期。文献数量呈指数式增长,目前已存在3 375 篇各类文献的研究体量,期刊论文和学位论文的年平均增速分别达到51.49%和52.45%,作者合作度为2.24。涌现出的高产和高贡献度作者越来越多,例如南京农业大学的李太平教授、中国人民大学的唐晓纯副教授和安徽工业大学的李丽副教授等。通过CNKI的“分组浏览-研究层次”检索功能获知,我国食品安全与数据科学交叉研究目前涉及到国内工程技术(自科)、行业指导(社科)和基础研究(社科)等16 个学科领域。结合科学计量学的分析,得出以下3 个方面的结论。
第一,通过关键词共现图谱分析,找出了本领域3大类11小类热点研究主题。通过时间线聚类图谱分析与关键词突现度图谱分析,划分出了本领域发展史上的3 个典型历史阶段,即:1996—2006年的食品安全标准引入与比较和食品安全数据的数理统计阶段;2007—2014年的食品安全数字技术与数学模型阶段;2015—2019年的食品安全大数据与人工智能阶段;预计在未来计算机视觉、自然语言处理技术、机器学习算法和大数据服务产业会在我国食品安全与数据科学交叉领域发挥更加重要的作用。
第二,通过文献分析,在食品安全与数据科学交叉融合的方向层次来看,数据科学的数据采集、数据存储、数据分析和数据可视化等技术,在23 年间不同程度地与食品安全的食品溯源、网络舆情、风险预警、智慧监管和可视化决策等重要方面相融合,诞生出新的食品安全前沿研究形态,是推动交叉研究不断发展的重要纵向动力。数据科学的各种技术与食品安全社会共治的各个主体的实际需求相结合,诞生出各种面向对象的食品安全大数据技术,是推动食品安全与数据科学交叉融合、促进食品安全大数据技术发展的重要横向动力。
第三,值得注意的是,虽然在仅仅23 年的时间里,我国食品安全与数据科学的交叉研究得到了迅猛发展;但是高被引论文[92]却只是总体文献中的极少数,国内研究与世界先进水平相比仍有差距;相比起食品安全领域的其他成熟学科板块,本领域的学科影响力仍然较为有限。结合未来的科技发展趋势和国家科技政策导向,我国食品安全与数据科学交叉研究应该得到社会各界更多的重视;本领域经过探索且被证明是成熟可行的研究范式,应该以课程化的形式进入到与食品安全有关的专业学科的课程体系之中;各级科学基金也应该加强对本领域的支持力度,推动本领域新的科研成果的不断产生以及科技成果的高效转化,以此推动我国食品安全监管防控的智能化进程。
本文也存在一定的局限性,因为数据下载阶段可检索到并可供下载的数据与所在高校(或研究机构)所购买的数据库的时间跨度及文献种类的权限有关[93]。故可能存在少量未被CNKI收录的文献,或作者单位未购买下载权限的数据库所包含的文献,未被纳入本研究的数据集会造成少量的样本缺失,并会一定程度地影响科学计量与主题分析的精准度。
