专用指令集在基于FPGA的神经网络加速器中的应用
2020-07-22胡航天马士超郭子博
胡航天,刘 凯,马士超,郭子博
0 引 言
近些年,神经网络算法广泛应用于计算机视觉,语音文字识别等领域并展现出了优越的性能.在目标检测、行为识别、语音识别等应用场景,神经网络算法已经逐渐取代传统算法成为主流算法.但在神经网络算法带来优越性能同时,其算法模型也有着更为庞大计算量和参数量,这也就给硬件平台提出了挑战.图1比较了几种经典DNN(深度神经网络)使用相同数据集情况下的Top-1准确率和计算量和模型参数大小(圆面积大小表示)[1].

图1 经典DNN模型性能指标Fig.1 Performance index of classic DNN model
由图1可以看出,无论哪种网络模型在计算量、模型参数量、推理准确性之间很难达到各项皆优.针对这个问题,选择合适硬件计算平台来进行神经网络算法加速是当前人工智能领域热点研究方向之一.
CPU平台难以满足结构复杂,计算量大模型的高性能计算,而GPU平台并行计算能力强,可以提供较高算力,并且有众多开发框架和开源库支持,如TensorFlow[2],PyTorch[3]等.在神经网络算法训练和推理过程中都能起到有效加速.但CPU和GPU都有较高的功耗,在星载系统、无人驾驶等能效要求较高的场景下,无法发挥其性能.
FPGA高并行性、软件可编程、功耗低等特性使其可以在星载场景下,提供低功耗且高性能算法加速.神经网络模型由多层构成,层与层之间具有严格独立性,这使得神经网络模型可以用高并行结构进行运算,从而进一步发挥FPGA本身的并行优势[4].
在FPGA加速方面,2016年亚利桑那州立大学Yufei Ma等人提出了一种基于FPGA的模块化CNN(卷积神经网络)加速结构[5],该结构将网络拆分为CONV(卷积)、POOL(池化)、UPSAMPLE(上采样)等操作单元,使用FPGA实现了AlexNet[6]和NIN CNN[7]网络模型.2017年北京大学Xuechao Wei等人设计了一种基于脉动阵列技术的高吞吐率FPGA CNN推理加速结构[8],该结构可以在高资源利用率下实现更高的时钟频率,从而提升了吞吐率.2018年深鉴科技发布了基于Xilinx FPGA平台的SDK端的深度学习开发工具包DNNDK (Deep Neural Network Development Kit,DNNDK)[9].使用该工具可快速的实现深度学习的硬件化,其利用的CNN剪枝技术可以在增加FPS的同时,将模型在FPGA上的性能优化5~50倍.2020年清华大学汪玉教授研究小组提出了通过多核硬件资源池、指令封装、两级静态与动态编译的方式分离任务,提供了针对于云端FPGA加速神经网络的虚拟化解决方案[10].除此之外,在神经网络硬件加速领域,也有公司设计专门用于深度学习的处理器.AI芯片领域的公司寒武纪将自主研发的AI指令集系统应用与硬件加速中,在2016年推出全球第一款商用终端智能处理器IP产品—Cambricon-1A[11].
在使用FPGA平台进行体系结构设计以实现神经网络模型时,资源占用一直是需要解决核心问题.如何在保证实现网络模型结构前提下尽量少使用片上资源,如何降低各个模块RTL代码之间耦合性一直是设计过程中棘手的问题.本文将一种自主设计专用指令集应用在FPGA神经网络加速器中,相较于平铺式[12]设计加速方案大大降低了片上资源,同时有效降低了不同计算模块耦合性,进而可以通过修改指令实现不同神经网络模型.
1 专用指令集架构设计
1.1 超长指令字设计
对神经网络架构进行分析,设计超长指令字由访存指令和运算指令构成,如图2所示,访存指令用于和DDR数据交互及片上数据转移,运算指令用于控制数据逻辑运算及条件转移等.超长指令字设计采用定长操作码和定长指令码[14]的方式,使指令设计变得简单,有利于指令的译码和后续执行.由于指令设计是顺序执行,各条指令之间并不存在跳转关系,因此指令地址码中不存在下一条指令地址.

图2 超长指令字设计Fig.2 The design of VLIW
1.1.1 访存指令
由图2可得基本访存指令由操作码、源操作数和目的操作数三部分组成,根据其操作的数据存储的位置,访存指令分为两种,即外存交互指令和片上数据转移指令.
(1)外存交互指令:对处于外存数据存储器进行读写操作,其源操作数和目的操作数分别在外存和片上;
(2)片上数据转移指令:负责对片上数据存储器进行操作,即各个模块间数据转送.根据是否满足条件,片上数据转移指令又分为条件转移指令和无条件转移指令.
为了避免访问其他存储产生冲突,数据寄存器寻址方式方式采用立即寻址,直接将操作数放在指令中;同时为了保证处理速度,每一条指令只在取数据和写回时访问外存,各个模块数据处理的中间值存于片上,减少访问外存消耗时间.
1.1.2 运算指令
运算指令只由操作码构成,运算指令根据其功能也分为两种,即数据逻辑运算指令和条件执行指令.
(1)数据逻辑运算指令:完成一个或两个数算术逻辑计算.
(2)条件执行指令:完成对执行条件的判断,满足条件时,执行某些特定的模块,否则不执行这些模块.
1.2 指令集逻辑系统架构设计
图3为一种应用于基于FPGA的卷积神经网络加速器的指令集逻辑架构.FPGA通过调整内部逻辑运行来实现各种功能,指令集由FPGA内部逻辑实现和控制.指令集架构由指令寄存器、指令解释器、指令转发模块、内存管理单元、和多个执行模块构成.指令解释器通过调配各个部分交替运行来实现指令的翻译及分发工作,从而实现调用不同的模块实现不同的功能,如图4所示.

图3 一种应用于基于FPGA的卷积神经网络加速器的指令集逻辑架构Fig.3 Application of special command set in neural network accelerator based on FPGA

图4 指令集架构框架Fig.4 The framework of VLIW
1.2.1 指令寄存器
指令寄存器是通过例化FPGA内部的嵌入式块RAM而形成的指令存储单元,指令顺序存放于指令寄存器中,上一条指令执行完时根据执行解释器是否收到完成信号来判断可否从指令寄存器中顺序取下一条指令.
1.2.2 指令解释器
指令解释器与指令寄存器和指令转发模块直接交互,是整个指令集架构的核心.从指令寄存器中取出指令被拆分并送往指令拆分解释器的不同单元,即访存指令送往访存指令处理单元,运算指令被送往运算指令处理单元.
访存指令处理单元将解释的访存指令送往内存管理单元,由内存管理单元对片上或外存数据进行读写操作,由于一条指令中有多个访存指令,因此内存管理单元执行顺序为访存指令处理单元解释先后顺序.运算指令处理单元将解释的运算指令送往指令转发单元,由指令转发单元调配各个执行模块工作.
1.2.3 指令转发模块
由于每个执行模块和指令解释器都是独立交互,因此指令转发单元存在于每一个指令模块和指令解释模块之间,负责转发两者之间的握手信号及运算指令,三者的工作模式采用idledonefinish方式,如图5所示.
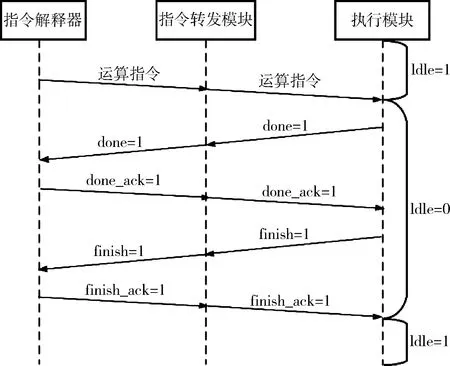
图5 Idledonefinish工作模式Fig.5 Idledonefinish working modes
图5所示的工作流程如下:
(1)执行模块处于空闲状态且运算指令解释完毕,此时模块处于idle状态,为可接受指令状态.
(2)指令解释模块发送计算指令并由指令转发模块转发到执行模块,执行模块接受到指令开始运行并跳出idle状态,并在指令执行完毕后向指令转发模块发送done信号.
(3)指令转发模块收到done信号并转发给指令解释器,指令解释器收到done信号并发送done_ack信号.
(4)指令解释器接收到done_ack信号并转发给指令转发模块,指令执行模块接收done_ack后发出finish信号,通知指令解释器功能已全部执行完毕.
(5)指令转发模块收到finish信号转发到指令解释器,指令解释器接受finish后发出finish_ack并于指令转发模块转发到执行模块,执行模块在接收到finish_ack信号后转为idle状态,等待下一条指令运行.
由于运算指令几乎同时解释完毕并送出,各个模块也在同一时间接收到运算指令,但由于数据流限制,每个模块必须接收到指令并且接收到上一个模块输出的数据才能满足执行的条件,可实现模块间串行的目的.
1.2.4 内存管理单元
内存管理单元主要用于片上模块与内存的交互,归纳来说,本设计的内存管理单元负责如下功能:
(1)将指令中地址映射为片上或片下物理地址.
(2)提供硬件机制的内存访问授权
由于片上寄存器和DDR已经通过AXI[16]总线统一编址,因此内存管理单元可以通过AXI总线将一个内存地址搬到另一个内存地址.内存管理单元不负责将内存中的数据读出并输出给其它模块,这是由于片上寄存器已经额外引出了native read port端口,其它模块可以直接读取其中数据.整个设计方案进行计算时,数据是已经缓存在片上RAM的,而不是直接从DDR取数参与计算的.
1.2.5 执行模块
执行模块是将原神经网络不同层间相似功能单独编写成的一个可执行块,在每层运行时只需实例化便可,采用模块化的方式,可以大大减少开发的时间和消耗的资源.
1.3 指令流水线
指令流水线由取指、译码、执行、写回、取下一条指令五部分组成,如图6所示.
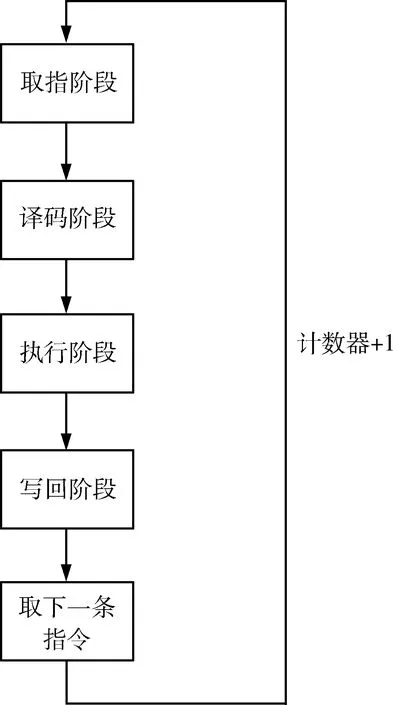
图6 指令流水线Fig.6 Instruction pipeline
图6所示的工作流程如下:
(1)取指阶段:根据指令解释器中计数器的值从指令寄存器对应位置取出指令并送往指令解释器.
(2)译码阶段:指令解释器将取出的指令拆分并根据指令类型分发到不同执行模块.
(3)执行阶段:各个执行模块接收到解释完的指令并等待上一个模块数据,接收到数据后模块运行.
(4)写回阶段:所有计算模块运行完后的数据送入写回模块,写回模块在指令的调度下执行写回操作,将计算结果写回片上或者外存.
(5)取下一条指令:每一个执行模块工作完毕向指令解释模块返回finish信号,当指令解释模块收到所有模块finish时,指令解释模块中计数器加一,取下一条指令.
2 应用实例分析
2.1 YOLOV3-Tiny网络模型操作介绍
以用于目标检测的YOLOV3-Tiny网络模型为例,其网络结构如图7所示,YOLOV3-Tiny共有23层网络层,其中16和23层为YOLO层,其他层为conv(卷积)、pool(池化)和upsample(上采样),其网络在YOLOV3网络的基础上去掉了一些特征层,只保留了两个独立的预测分支,相较于YOLOV3网络,YOLOV3-Tiny在损失可接受精度的情况下,检测速度得到提升.
该神经网络模型在FPGA上实现主要操作为Convolution(卷积),Pooling(池化),Upsample (上采样).各主要操作如表1所示.其中可以看出卷积操作次数最多,而利用FPGA进行算法加速,最为重要就是利用FPGA的计算资源并行化计算多通道卷积.目前FPGA内部都包含了大量DSP硬核资源(在一个指令周期内可完成一次乘法和一次加法的芯片),利用DSP阵列可以高速并行计算卷积的乘加操作.
2.2 平铺式与指令控制式加速方案比较
在使用FPGA平台实现该神经网络模型加速时,采用平铺式设计方案需要实例化大量的计算资源和存储资源,而采用指令集架构可通过不同的指令选择执行模块是否工作,使用这种方式可以很大程度下复用各个执行模块,降低片上资源的使用.

图7 YOLOV3-Tiny网络结构Fig.7 YOLOV3-Tiny network
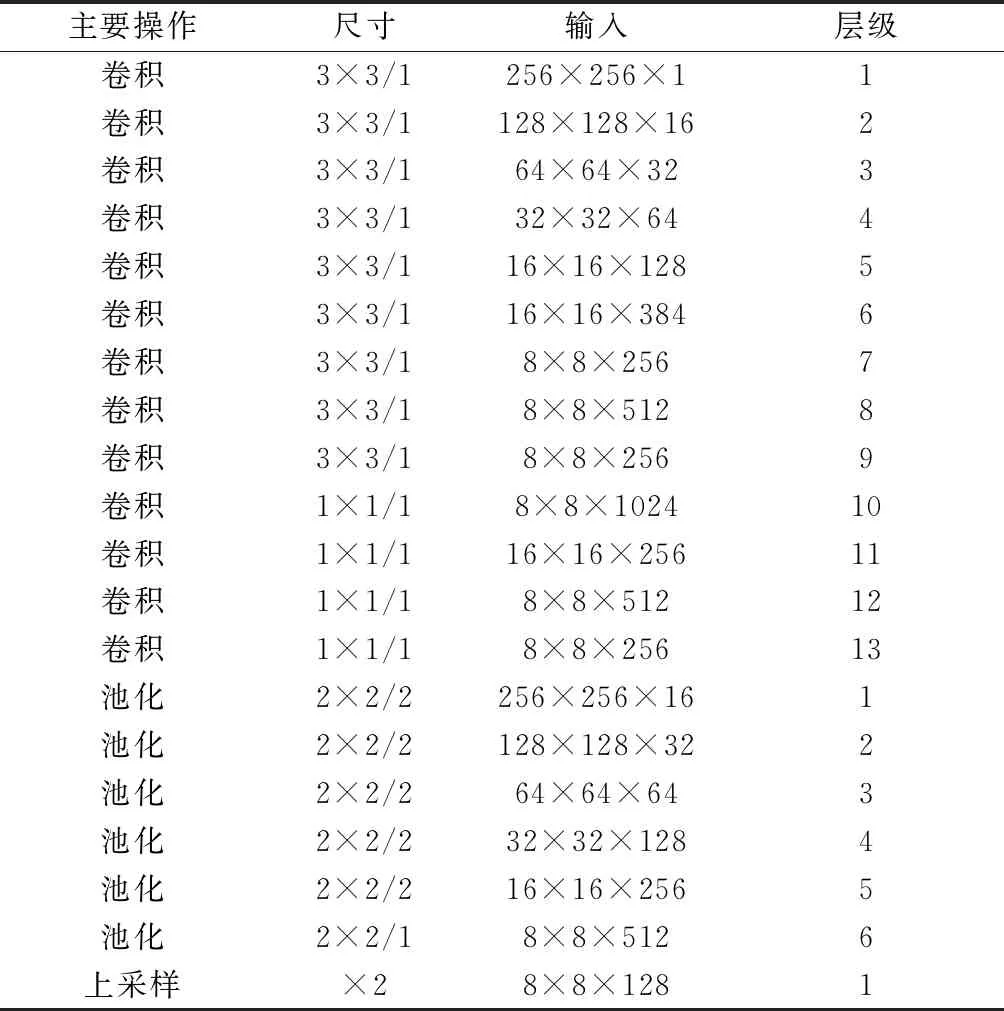
表1 YOLOV3-Tiny网络主要操作Tab.1 YOLOV3-Tiny network main operation
本文以卷积层操作使用16*32的高速DSP阵列实现为例,采用16bit量化和指令控制式加速方案在Xilinx XCVU9P FPGA使用的主要片上资源如表2而所示.根据实例化执行模块个数,本文估算了平铺式加速方案的资源消耗如表2所示,两种方案的资源消耗对比如图8所示(为了对比清晰,LUT、LUTRAM、FF资源数量缩小了100倍).
可以看出,使用平铺式设计方案会消耗大量片上资源,甚至对于复杂网络模型单一FPGA的资源无法满足设计需求,且数据流相对固定,不能灵活的适应不同的网络模型,而采用指令控制的方案可以不仅提高了模块的复用性,可通过修改指令的方式灵活适应各种网络模型,且可以节省50%片上资源,实现神经网络算法在FPGA上低功耗的加速.
精度检测采用的数据集为SAR图像船舶检测数据集,数据集来源于102张Gaofen-3 图片和108张Sentinel-1图片,含有43819张船舶切片,包含的船舶数目为59535,所有切片尺寸固定,为256*256,三通道,24位图像深度,标注文件提供相应图像的长宽尺寸、标注目标的类别以及标注矩形框的位置.
平铺式的YOLOV3-Tiny网络AP(平均正确率)为0.8,而指令控制式的YOLOV3-Tiny网络AP(平均正确率)为0.78,在没有精度损失的情况下,在相同的硬件环境中,指令控制式网络的GOPs为传统平铺式网络的4倍.
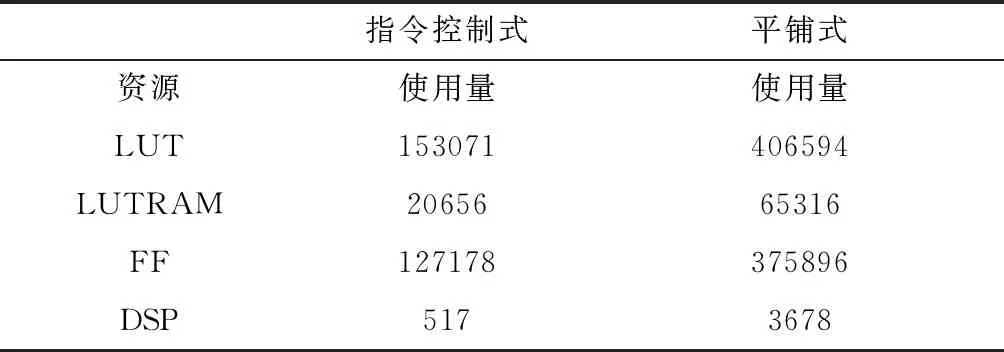
表2 两种方案使用资源情况Tab.2 Resource usage

图8 资源消耗对比图Fig.8 Comparison chart of resource consumption
3 结 论
为应对在基于FPGA的神经网络加速器的硬件结构设计中,片上资源消耗大、各执行模块耦合性高等问题,本文设计实现了一套专用指令集.在硬件条件相同情况下,相较传统平铺式方案,应用该指令集的方案可使GOPs提升4倍,资源消耗降低50%,验证了专用指令集可降低各执行模块之间的耦合性,并能切实减少在神经网络硬件加速结构设计时FPGA片上资源的使用.
