基于节点多属性相似性聚类的社团划分算法
2020-07-21邱少明杜秀丽
邱少明,於 涛,杜秀丽,陈 波
(1.大连大学 通信与网络重点实验室,辽宁 大连 116622; 2.岭南师范学院 信息工程学院,广东 湛江 524048)
0 概述
网络是由节点和连线构成,表示不同对象之间的相互联系。在现实生活中,存在蛋白质网络[1]、神经网络[2]、社会网络[3]等各种类型的网络,不同的网络具有不同的结构和属性,而不同的属性也会表现出不一样的特征。随着对网络研究的进一步深入发现网络中存在一种特殊的拓扑结构,其主要特点是在该网络结构内的节点联系非常紧密,在网络结构之间的节点联系相对稀疏,研究人员将该结构特征初步定义为网络社团现象[4]。社会网络的社团宏观结构体现了网络成员之间的联系,反映了成员之间的关系属性,可以被定义为社会成员之间紧密相连的集合。
目前,社团划分方法主要包括基于模块度的社团划分方法、基于图划分的社团划分方法和基于层次聚类的社团划分方法。基于模块度的社团划分方法由NEWMAN于2004年提出[5],其核心是一种分层贪婪算法,如Fast-Unfolding算法[6],可以快速实现对社团的划分,但容易陷入局部最优,不适用于大规模的网络社团划分。基于图划分的社团划分方法[7]如Kernighan-Lin算法[8]、谱平分算法等,均是经典的图谱理论划分算法,需要预知社团数目才可实现社团划分。基于层次聚类的社团划分方法[9]尽管具有较好的社团划分效果,但是聚类标准的选取对划分质量影响较大。
在此基础上,文献[10]提出局部社团检测算法,通过不同的隶属函数进行动态检测,但其是针对局部社团进行划分,忽略了网络全局特性,对网络整体结构的判断不够准确,容易陷入局部最优。通过进一步研究发现,社团划分与聚类问题非常相似,因此文献[11]提出基于密度的聚类方法,相对于已有方法聚类效果有所改进,但其聚类的初始条件选取存在随机性,会导致划分的社团不稳定。文献[12]提出相似性概念,但其在相似性网络定义上很少从自身属性进行考虑,并且社团划分方法仅采用单一指标,如聚集系数[13],不具说服力。文献[14]基于RA指标提出顶点相似性指标,并将其运用于推荐系统中,具有较好的推荐效果,但其仅针对小型网络,如果将其运用于具有较多属性的大型网络中,则聚类效果会迅速下降。文献[15]提出一种基于节点相异度的社团层次划分算法,结合核度和接近度评估得出节点相异度评价结果,从而计算节点间的相似度。虽然该算法能够针对性地选取初始节点,但相异度评估方式没有考虑到网络节点间的多属性关系,仅通过节点之间的最短距离衡量相异程度,缺乏一定的合理性。相似性指标主要分为局部相似性指标与全局相似性两类,常见的局部相似性指标主要有Jaccard指标[16]等,全局相似性指标主要有SimRank指标[17]等。文献[18]提出一种综合考虑用户行为与相似度的社区发现算法,将网络中用户间的多维关系抽象成相似度,并将相关因子作为模块度的目标函数进行社团划分,能够基本达到划分的目的,但是精确度较低。由于上述研究方法多数仅考虑了网络局部特性,未考虑网络全局特性,存在划分方法单一、划分精度不高等问题,因此本文提出基于节点多属性相似性聚类的社团划分算法SM-CD。
1 节点多属性相似性度量
1.1 网络抽象
所有网络都可以被抽象成节点及其连边构成的结构,本文提出一种考虑节点多属性的度量方法,将网络中某节点与其邻居节点直接相连的网络节点之间的属性称为节点自身属性,将非直接相连的网络节点之间的属性称为结构属性,从节点自身属性和结构属性角度出发,根据相似性进行社团划分操作。

1.2 节点相似度计算
1.2.1 节点属性选择
由于网络中的节点不是完全孤立存在的,而是与其他节点存在联系,在社会关系网络中其集聚性表现尤为明显,因此集聚性是重要的节点自身属性指标。
属性1(聚集系数C) 节点i的聚集系数计算如式(1)所示:
(1)
其中,φi表示节点i的邻居节点集合,|E(φi)|表示节点i的邻居节点之间的实际连边数目。
在社会网络中,每个成员地位不同,有的成员与其他成员联系少,但是他可能是两个社团的中间联络人,如果忽视其作用,则可能导致两个社团中的联系出现中断或者难度加大。如果网络中的两个个体没有直接相连,且两者之间不存在间接相连,则两者之间存在阻碍,节点效率是用来描述该节点对网络中其他相关节点的影响程度,是重要的结构属性指标。
属性2(节点效率Eef) 设节点数量为n,则节点i的效率计算如式(2)所示:
(2)
其中,j表示节点i的邻接节点,l表示节点i和节点j的共同邻接节点,Υil和Υjl分别表示节点l在节点i和节点j的邻居节点中所占的比例。
属性3(核度) 节点的核度定义为节点在核中的深度,核度的最大值对应网络结构中最中心的位置。使用核度可以描述度分布所不能描述的网络特征,揭示源于系统特殊结构的层次性。核值的大小可以将网络中的节点按照影响力进行分类,在实际网络中,核度越大的节点,影响力也相对较大。
属性4(共有节点引力) 在进行网络节点划分时,节点归属的强弱是节点划分的依据,如果两个节点之间的共有节点集合越多,说明两个节点之间的交互信息量越大,在考虑相似度时会在结构上产生更强的吸引力。因此,在定义共有节点引力时,共有节点占据相应节点的比例可以直观反映两节点在结构上的相似性。节点i和节点j的共有引力计算如式(3)所示:
(3)
其中,|φi,φj|表示节点i和节点j的共同邻居数量,|φi|和|φj|分别表示节点i和节点j的邻居节点数量,两者的比值越大,说明两类节点在结构上具有更强的关联性。
1.2.2 节点属性相似度矩阵求解
本文利用节点的多属性信息结合局部与全局信息对网络中的社团进行划分,具体的相似性指标定义为:


(4)
在获取中间矩阵后,需要进一步获取不同节点之间的相似度矩阵,相似度矩阵描述了网络中的各节点在各属性协同下,依据不同的权重值计算出的相似情况,从而求解相似度矩阵SSim的每个值。例如,给定两个节点vi和vj,其对应的属性向量为hi和hj,则两个矢量节点之间的相似度Sij计算如式(5)所示:
(5)
当i、j直接相连时,满足式(6):
(6)
当i、j不直接相连时,满足式(7):
(7)

(8)
2 基于节点多属性相似性聚类的社团划分
2.1 节点多属性相似性聚类

图1描述了考虑节点不同属性的社团划分结果。在图1(a)和图1(c)中的簇节点划分情况在不断变化,因此在简化社团结构图1(b)和图1(d)中反映的结果也存在差异。在图1(a)中,当不考虑簇7节点的结构属性(如共有节点引力及效率)而仅考虑节点的自身属性时,整个网络被划分成3个社团如图1(b)中简化图所示,当考虑网络自身属性时,网络会分成4个社团如图1(d)中简化图所示。

图1 考虑节点不同属性的社团划分结果
根据节点多属性定义可以利用本文聚类算法将不同节点划分到不同社团结构中,因此,在进行社团聚类算法实现时,最重要的是如何使用聚类思想合理融合节点属性信息并对社团进行划分。在进行社团划分时,本文考虑到节点的不同属性,并在此基础上,结合节点相似度矩阵SSim,提出一种基于节点多属性相似性聚类的社团划分算法。
传统聚类算法是对于给定的基本样本集,按照样本之间的距离,将样本集划分为K个簇,使簇内的点尽量紧密连接在一起,而簇间距离尽可能大。在本文算法中,将各节点之间的相似度作为样本集,即相似度矩阵中的各sij值,根据影响度函数选取初始质心节点,并采用聚类思想进行划分操作。
1)社团K值的确定。依据当前研究发现,对于社团结构不是很明显的网络,无法在初期直接确定网络中的社团数目。所以,本文在理论范围内采用遍历方式寻找最佳K值,选出最优划分结构对应的K值即为最终输出的社团数目。
2)聚类质心的选取。一个好的初始质点是均值聚类的必要条件,在选取聚类的初始质心时,本文从影响度的角度出发,而不是随机选取初始点。由分析可知,如果某个顶点vi的周围节点连接比较稠密,则表明该节点在网络中具有较强的吸附能力,即更容易形成社团,则以这类节点作为质心节点相比于在网络中随机选取初始节点更具代表性。本文影响度函数的定义如式(9)所示:
(9)
其中,影响度函数f(vi)∈(0,1),用于衡量一个节点相对于其他节点的影响程度,d(vi,vj)表示节点vi和vj之间的欧几里得距离,考虑到网络节点之间的距离对影响度函数具有较大影响,所以本文引入∂调节因子,通过∂来调整不同距离之间的节点影响程度。在本文实验中发现,如果不引入调节因子会导致计算出的指标值相近,区分效果不明显。因此,本文依据影响度函数的大小,选取排名前η个的节点作为选取合理K值的依据。
2.2 算法描述
本文SM-CD算法的主要思想是同时考虑网络节点的自身属性与结构属性信息得到中间矩阵,并利用节点相似度计算方法,将计算得到的相似度值作为聚类样本集得到相似度矩阵,再结合影响度函数选取排名靠前的节点集合η作为遍历上限值,通过不断改变α与β,选取合理的K值,直至模块度值达到最大,并将对应的K值作为最终社团划分数量,算法具体流程如图2所示。

图2 SM-CD算法流程
SM-CD算法实现步骤具体如下:
输入简化了属性值的无向图G=(V,E)
输出通过算法得到的社团划分数目K与社团结构
步骤1输入网络的邻接矩阵A。
步骤2计算网络节点结构属性与自身属性得到中间矩阵M,其中属性4是网络中节点i与其他n-1个节点之间的共有引力,作为结构属性,得到网络的相似度矩阵SSim。
步骤3通过影响度函数选取前η个备选节点作为社团个数的有效集合,计算模块度Q值。
步骤4判断每次计算的模块度是否增加,如果当前计算得到的模块度差值持续增加,则调整K值继续计算当前α与β取值条件下模块度的变化情况,如果模块度值没有持续增加,则调整α与β的取值,跳转至步骤2重新计算相似度矩阵,从而得到不同权重下的模块度值。
步骤5统计在不同权重下的模块度值,选取最大模块度对应的K值,即社团划分的最佳数量。
3 实验设置
3.1 评价指标
3.1.1 模块度
由于在真实网络中无法预先明确网络中的社团结构,因此在衡量社团划分准确性时,本文采用模块度Q作为评价指标。在每次进行节点聚类时,都会计算此时的模块度大小并观察其值的变化,从而决定是否将该节点划分到相应社团中。
模块度Q是常用的比较社团划分质量的评价指标,其中Q∈[0,1],社团划分的质量越高,其模块度的值越大,社团内的节点相似性越强,社团划分效果越好,Q的具体定义如式(10)所示:
(10)

3.1.2 划分准确率
模块度评价指标是聚类的内部评价指标,是一种无监督度量指标,虽然对于单个聚类有较好的评价效果,但是对于聚类最终结果与实际结果之间存在一定的误差。因此,需要引入一种有监督度量指标划分准确率S,作为外部评价指标,其值一般为准确划分后的社团个数占全部节点的比例,如式(11)所示:
S=NR/N
(11)
其中,NR表示准确划分的社团数目,N表示总节点数。
3.2 真实网络实验
为验证本文算法的准确性,选取2个真实网络,分别为Zachary网络和Football网络(http://www-personal.umich.edu/~mejn/netdata/),如表1所示。对这2个真实网络进行实验研究并将本文算法与其他算法进行性能比较,以验证本文算法的有效性。

表1 真实网络拓扑结构
3.2.1 Zachary网络实验
Zachary网络是美国某大学空手道俱乐部的关系网络,该网络包含34个节点及78条边,其中节点表示俱乐部成员,边表示成员之间存在的关系。节点1代表教练,节点34代表校长。由于教练和校长对于俱乐部收费问题存在分歧,因此导致该俱乐部分成以校长和教练为核心的小社团。本文算法对Zachary空手道俱乐部网络进行划分,在进行多次实验后发现,当K=2时,社团模块度Q=0.427,此时β=0.5,调节因子∂=0.4,划分效果最优,社团划分结果如图3所示。

图3 本文算法对Zachary网络的社团划分结果
通过本文算法对Zachary网络结构进行社团划分,将网络划分成2个社团,社团1主要以节点1为中心,社团2主要以节点34为中心。在设定初始值时,将网络划分出的社团个数对应网络中的社团模块度,基于本文算法得到Zachary网络社团划分模块度与社团个数之间的关系如图4所示。

图4 Zachary网络社团个数与模块度的关系
3.2.2 Football网络实验
Football数据集是一个经典的社团研究数据集,该网络由115个球队的613场比赛抽象而成,如何根据不同球队之间的实力合理划分球队,并合理安排相应的赛事是该实验关注的重点。因此,采用本文算法对该网络进行社团划分,初步结果如图5所示。将网络划分成10个社团,模块度Q=0.619 6达到最大值,此时α=0.3、β=0.7、∂=0.4,划分效果最优。对网络社团进行反复划分实验,最终得到的仿真结果如图6所示,通过调节不同的α和β值,对不同社团个数计算网络模块度,可以看出当α=0.3、β=0.7时,模块度Q=0.619 6达到最大值,可以认为当划分得到10个社团时,网络划分结果最佳。

图5 本文算法对Football网络的社团划分结果

图6 Football网络社团个数与模块度的关系
3.3 结果分析
针对相同网络数据集,将本文SM-CD算法社团划分结果与经典的Newman算法、GN算法、NC算法[15]、基于节点特征向量的复杂网络社团发现算法[16]、IJ-CD算法[19]、基于节点内聚系数的局部社团发现算法[20]和GD算法[21]划分结果进行对比验证,结果如表2、表3所示。
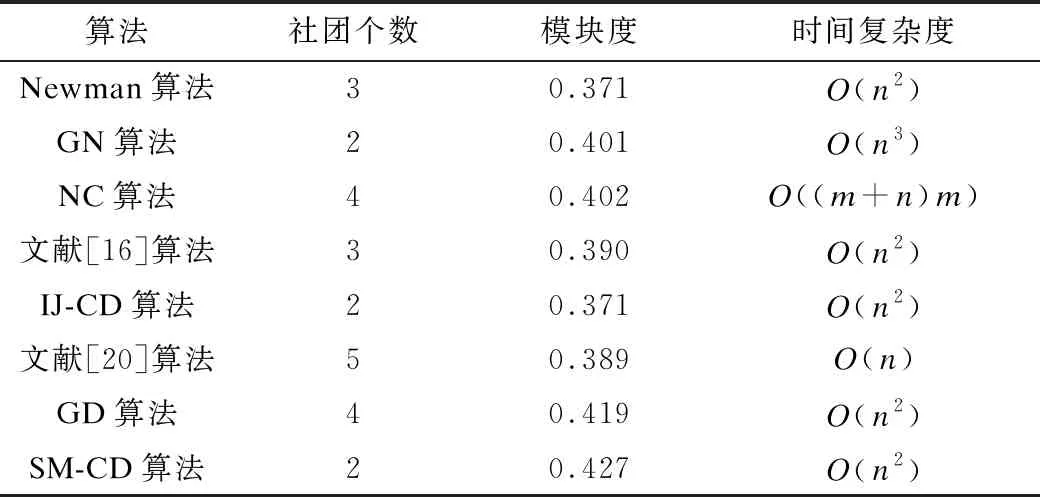
表2 针对Zachary网络的算法划分结果对比

表3 针对Football网络的算法划分结果对比
Newman算法基于贪心算法原则,选取模块度增长最大或者减小最少的社区,将其合并为一个新社区,不断迭代循环,将模块度最大值对应的网络社团作为最优社团划分结果。该算法在降低时间复杂度的同时,准确度也相应降低。从表2、表3结果可以看出,本文算法相比Newman算法在模块度上分别提升了15%和13%。
GN算法的主要思想来源于聚类分裂法,原理是使用网络中的边介数作为相似度的度量。首先计算网络中所有边的介数,找到介数最高的边并将其从网络中移除,重新计算网络中剩余边的介数,不断重复该过程,直至网络中的任一顶点作为一个社区为止。虽然该算法准确度相对较高,但时间复杂度也较高。对比表2的Zachary网络与表3的Football网络时间复杂度指标,传统GN算法时间复杂度是O(n3),本文算法的时间复杂度比GN算法低一个数量级。
文献[16]算法采用效能传递思想对社团进行聚类,与本文算法的区别是将网络节点之间的距离倒数作为信息传递效能指标并构建矩阵,从而计算模块度值作为划分依据,算法考虑相对单一。IJ-CD算法通过改进Jaccard相似系数矩阵并选取部分特征值对应的特征向量作为聚类样本,虽然时间复杂度和本文算法相当,但在划分精度上本文算法相对更好。
文献[20]算法与GD算法思想类似,通过选取最大度节点作为起始社团,不断搜索其邻居节点,将强社团结构定义作为节点添加的约束条件最大度节点,不断添加至社团中形成新的社团,直至邻居节点集为空时停止。与本文算法相比,虽然文献[20]算法的时间复杂度比本文算法的时间复杂度低,但是其将网络划分为5个社团,使用本文算法将网络划分为2个社团,且模块度与本文算法相比相差较多,本文算法在划分精度方面优势明显。与此同时,文献[20]算法在划分精度上与其他算法相差很小。因此,本文算法划分精度比文献[20]算法高,更具实用价值。NC算法虽然对于Zachary网络划分的模块度与本文算法很接近,但时间复杂度为O((m+n)m),其中m为边数,在仿真网络中m远比n要大得多,因此其时间复杂度大于本文算法。在同等情况下,本文算法的划分精度相比其他算法略高,划分效果更好。
本文针对社团划分采用相同网络数据集,选取经典Newman算法、GN算法和IJ-CD算法与本文算法在时间消耗和准确率方面进行比较,如图7和图8所示。从图7可以看出,与经典Newman算法、GN算法相比,本文算法时间消耗更少,优势明显,与文献[20]算法的时间消耗相差较小,但从表2、表3以及图8可以看出,本文算法在划分准确率上更具优势,划分效果更好。

图7 社团划分算法的时间消耗比较

图8 社团划分算法的准确率比较
4 结束语
本文定义了网络中的节点自身属性和结构属性,提出一种基于节点多属性相似性聚类的社团划分算法。根据两类属性在网络上的权重不同,在实验中通过不断调整调节因子将网络划分为不同的社团结构并计算相应的模块度。实验结果表明,本文算法能有效提高社团划分的准确率。但由于本文中考虑的网络为无权无向网络,而在实际生活中网络节点之间的连接权重存在差异且可能具有方向性,因此下一步将对有权有向网络社团划分进行研究。
