基于多源时空分析的复杂活动识别方法
2020-07-20崔海英方亚东郎瑞祥
王 方,崔海英,方亚东,郎瑞祥,叶 剑+
(1.浪潮集团有限公司 浪潮云信息技术有限公司,山东 济南 250010;2.中国科学院计算技术研究所,北京 100190)
0 引 言
用户基本活动识别一般是指识别用户的行走、奔跑、站立等简单活动,与基本活动识别相比,复杂活动识别(high-level activity recognition,HAR)主要识别吃饭、工作、运动等日常生活活动,复杂活动识别提供了更加丰富的用户情境信息,同时也大大增加了活动识别的难度[1]。
不同的复杂活动识别方法往往考虑不同的因素,例如将加速度传感器配置在人体多个位置从而考虑人体不同部位的加速度;用手机采集用户附近WiFi列表、地理位置、用户环境声音、加速度等。在众多的相关因素中,时空轨迹被证明是与用户复杂活动相关的关键因素[1-4]。该因素对于过滤用户的活动有重要的作用,此处的过滤作用主要指根据时空轨迹特征可以排除部分不会发生在某个地点的活动。例如,当用户在工作单位时,他可能会在工作、会议等,但是不会发生做饭、家务等活动。为此,以运动轨迹的时空特性为基础,研究复杂活动识别方法具有重要意义。
1 相关工作
用户的复杂活动由简单活动组成。所以对于复杂活动识别的过程通常,首先通过先识别简单活动,基于识别的简单活动进而完成复杂活动识别。简单活动识别首先将原始数据按照固定时间间隔划分为段,进而识别每段对应的简单活动。文献[5]提出了一种利用智能手机的加速度计数据和机器学习算法对运动进行分类的系统,该文利用特征提取和选择技术对简单或识别优化,该方法可以识别和分类动态和静态物理用户活动,利用特征选择,减少所需特征的数量,从而在保持分类精度的同时降低模型的复杂度,同时比较了SVM、KNN、kStar等多种机器学算法的优劣。文献[6]提出了一种基于光学HR(心率)传感器和三轴腕部磨损加速度计的活动监测框架。系统基于一种著名的监督分类算法——随机森林,利用了标签校正、信号分割、特征提取、参数检测和特征约简等数据处理方法,对坐、站、家庭活动等进行识别。文献[7]采用LDA模型分析训练数据包含的话题,将话题概率分布相似的段合并,通过比较段与用户标签来识别复杂活动。该类方法存在的问题在于简单活动种类较少,只包含基本的快走,慢走,站立等活动。这并不足以区分很多复杂活动,比如用户的工作和吃饭都是以坐这个简单活动构成的;用户的步行通勤和购物都是以慢走这个主要活动构成的。因此,种类过少的简单活动并不能很好区分复杂活动。
文献[8,9]考虑用户的活动受其周围用户影响,不同社区用户间存在相似性。因此借助相邻用户以及相似社区来识别当前用户活动。文献[8]提出了一种“众包”方法,通过发现目标用户和社区用户之间的类相似性,结合用户依赖模型和一般模型的优点,为HAR构建个性化模型,该方法使用集体数据来匹配个人数据,其中的关键是使用目标用户的稀缺标签数据,根据类的相似性选择其他用户数据的子集,而不是使用所有其他用户的数据构建模型,从而构建个性化模型。文献[9]使用轨迹相似度和用户活动区域相似度计算用户的关系强度从而构建关系网络,然后提取相应的社区特征训练基于社区的活动分类器,并根据个人的数据训练个人活动分类器,将两个分类器结果融合作为最终的结果。该类方法存在的问题在于当用户量很大时,构建关系网络是一个计算复杂性很高的任务,模型训练需要较长的时间。
文献[2,10-12]综合考虑时空因素,采集多源数据,利用多源数据的不同特点,构造合适的框架,识别用户复杂活动。文献[2]使用手机和心电监护仪作为数据采集设备,分别采集了WiFi,GPS坐标,环境声音等数据,并提出了一个启发式算法对活动识别。该方法对睡眠、工作两个活动的识别率很高,但是对于锻炼、吃饭、外出等活动的识别率都比较低。文献[10]提出了一种基于成本敏感的GPS活动识别模型,以提高少数活动的识别的准确性,从而反映出用户的个人偏好,是一种侧重于提供平衡结果的方法,采用成本敏感的隐马尔可夫模型进行识别。文献[11]在活动识别时考虑了加速度、GPS和声频等信息,并利用GPS信息估算出磁场信息,同时提出两种版本的支持向量机(SVM)分类器算法。文献[12]设计了一个启发式的活动识别框架,共需训练31个分类器,根据数据的不同,选择某个合适的分类器进行预测。由于该方法需要训练的分类器众多,大大增加了模型训练的工作量。该类方法中,时空特征只是作为分类器众多特征中的一维,并未考虑时空轨迹对活动的过滤作用。
为此,本文提出了一种基于ROA复杂活动识别方法,该方法充分利用时空轨迹对交通方式识别的重要作用以及对用户复杂活动的过滤作用,使得每个ROA内复杂活动具有较强的规律性并且复杂活动的种类小于待识别活动全集的种类,因此有助于提高分类器对复杂活动的识别率。与文献[5-7]所述的方法不同,本文并未识别简单活动,而是根据相关特征直接识别复杂活动。与文献[8,9]所述的方法不同,该类方法使用用户时空轨迹来衡量用户的关系强度构造关系网络,本文并不需构造复杂的关系网络,从而在计算复杂度上低于这些算法。与文献[2,10-12]所述的方法不同,该类方法一般利用时空轨迹提取速度,获取地理位置的类别等,并将这些信息作为分类器的一维特征辅助复杂活动识别,本文则是利用时空轨迹将数据划分为ROA,基于ROA识别复杂活动。同时,本文中提到的分类器并不局限于某种特定的分类器,每个ROA可以根据实际情况采用相同或者不同的分类器。
2 复杂活动识别
2.1 算法框架
基于ROA复杂活动识别方法的算法框架如图1所示。训练阶段,首先使用ROA提取算法从传感器数据流中提取ROA,基于不同的ROA,分别训练相同或不同的分类器。识别阶段,首先,判断待识别的数据属于哪个ROA,然后选择相应的分类器进行分类,分类的结果即为复杂活动识别的结果。当用户到达了一个他以前从未到过的地方时,由于缺乏有效的历史数据,判断当前数据的ROA将产生较大的误差,这种情况下,可以通过比较ROA属性的相似性来选择合适的ROA。同时,用户一天的识别结果就可以组成用户该天的活动模式。活动模式对活动识别具有重要意义:活动模式提供了一个活动之前活动和之后活动的信息,这样的信息使得可以根据活动之间的联系来对识别的结果进行合理调整;并且用户的活动模式具有规律性,例如用户在工作日的活动模式是相对固定的,在非工作的活动模式也是相对固定的。这样的规律性使得可以把活动规律当作用户活动识别的先验知识,提高活动识别的准确率。关于活动模式的应用,我们将在未来的工作中继续探究,本文我们将着重讨论ROA的提取及分类器的训练。

图1 基于ROA复杂活动识别方法框架
2.2 ROA提取算法
时空轨迹对复杂活动的过滤作用主要体现在用户不同ROA的活动种类相对较少并具有较强的规律性。本文提出了两种ROA提取算法,第一种是基于密度聚类的ROA提取算法,此算法基于用户长时间停留的区域GPS数据采样及WiFi列表数据采样的密度将会大于用户以某种交通方式经过的区域,因此采用密度聚类可以从数据中提取ROA。然而,用户的差异性和地点的差异性对密度聚类的参数具有较大的影响,使得密度聚类方法的参数不容易确定,同时,密度聚类算法具有较高的时间复杂度,面对大量数据时,需要较长的训练时间。因此,本文提出了基于滤波的ROA提取算法。用户的ROA是由若干道路连接在一起的,当用户以某种交通方式通过道路时,GPS坐标变化率将会高于用户长时间停留的ROA,因此采用滤波的方式,识别道路上的数据,并对非道路上的数据进行合理的合并,可以从数据中提取ROA。该算法相对于基于密度聚类的ROA提取算法而言,用户差异性和地点差异性对参数影响较小,同时具有较低的算法复杂度。
2.2.1 基于密度聚类的ROA提取算法
在基于密度聚类的ROA提取算法中,首先对WiFi列表进行了基于Jaccard距离的密度聚类,将每个类中的GPS坐标统一修正为该类中所有GPS坐标的平均值,进而对修正后的GPS数据进行基于欧氏距离的密度聚类。聚类结果中,每一个类即为一个ROA,所有非类内点视为一个ROA,非类内点所对应的ROA一般为道路上的点。算法伪代码如算法1所示。
算法1: 密度聚类ROA提取算法。
输入: GPS数据GPSData, WiFi列表数据WiFiData
输出: ROA标签ROATag
WiFiDistance←GetDistance(WiFiData, “jaccard”)
WiFiCluster←DBSCAN(WiFiDistance,eps,minPts)
WiFiClusterTag←WiFiCluster.tag
FOR(iINunique(WiFiClusterTag))
IF(i!= 0)
index←which(WiFiClusterTag==i)
GPSData[index, 1] ←mean(GPSData[index, 1])
GPSData[index, 2] ←mean(GPSData[index, 2])
GPSDistance←GetDistance(GPSData, “euclidean”)
GPSCluster←DBSCAN(GPSDistance,eps,minPts)
ROATag←GPSCluster.tag
RETURNROATag
之所以采取先对WiFi列表聚类修正GPS数据再对GPS聚类的原因是,在某些建筑物中,由于建筑物结构使得建筑物内GPS信号时有时无,这样情况下产生的GPS定位结果误差非常大,如果直接使用GPS密度聚类,无法将这些数据采样聚在一起,产生错误,如图2所示。图2中每个非圆的图形代表一个聚类。图2(a)中,右下角十字,叉,菱形为同一地点的GPS采样,由于信号问题导致有较大的偏差而无法聚在一起。WiFi的辐射距离相对较小,所以,使用WiFi数据聚为一类的数据,实际的GPS位置不会相差太大,因此采用WiFi聚类修正数据采样的GPS坐标。如果只使用WiFi聚类,由于某些建筑没有WiFi信号,导致会丢失这些建筑物的聚类,如图2(b)所示。图2(b)中右下角较为分散的点因为WiFi采样一致而被聚集在一起,但是右上方和左方的聚类由于没有WiFi信号而丢失。所以,采取了使用WiFi聚类修正GPS坐标再对GPS聚类的方法,结果图2(c)所示。图2(c)中左方和右上方的聚类没有丢失,右下方点经过WiFi修正而聚为一类。
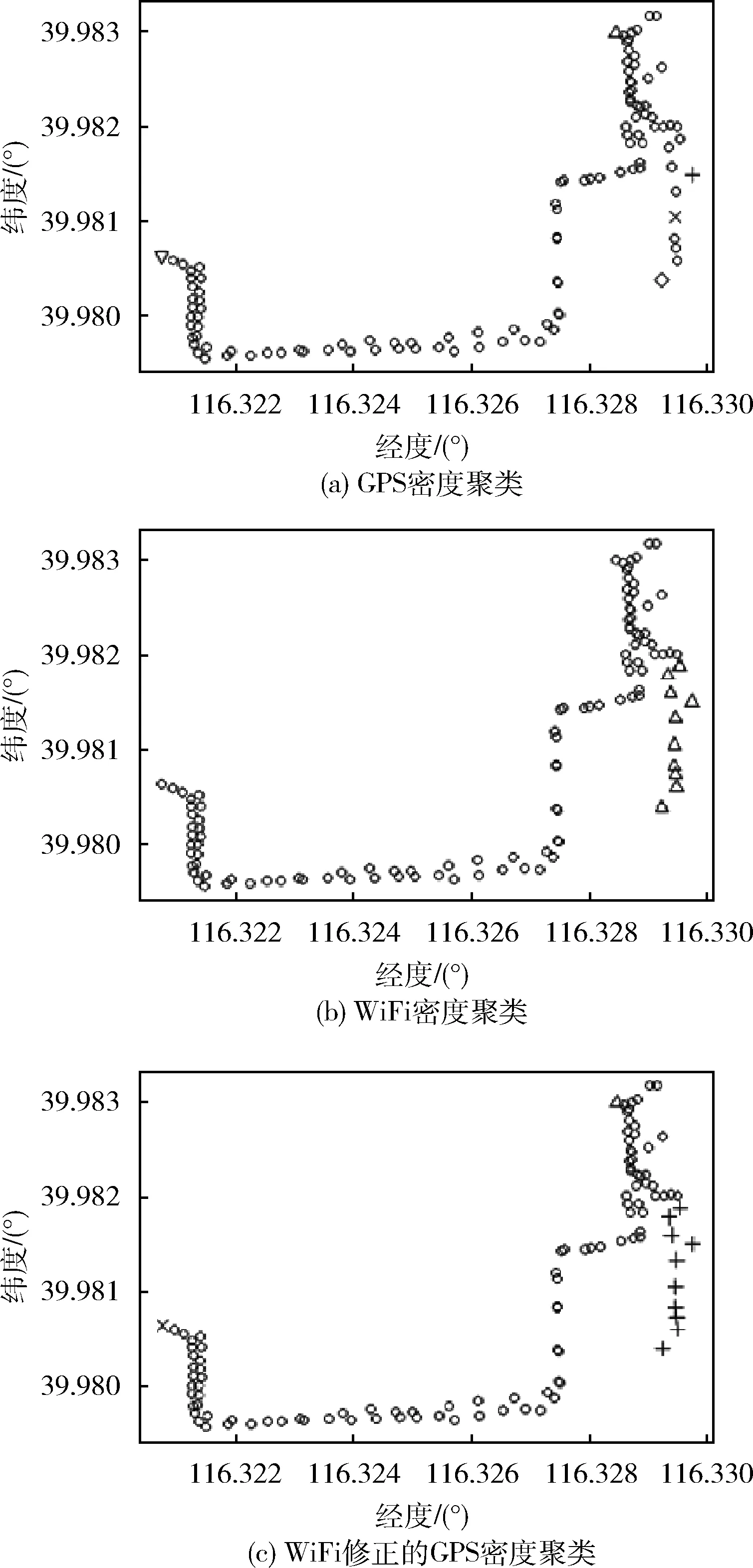
图2 基于密度聚类的ROA提取算法
2.2.2 基于滤波的ROA提取算法
在基于滤波的ROA提取算法中,首先根据GPS坐标及采样频率求出GPS坐标的变化率。由于用户在道路上可能因为某些原因会停止前进,同时,某些建筑物会发生GPS坐标的偏移产生GPS变化率的突变,因此首先采用平滑滤波器对GPS变化率进行平滑滤波,可以根据数据的不同情况采用平滑线性滤波器或统计排序(非线性)滤波器,本文采用了均值滤波器。对平滑滤波后的数据低通滤波,此时,标记为1的点组成用户长时间停留的数据段,标记为0的点为道路上的点。接下来需要将属于同一个ROA的数据段进行合并。对当前每个数据段计算一个平均值,当两个数据段的平均值小于一定阈值时,将两个数据段进行合并,合并完成即为ROA提取结果。算法伪代码算法2所示。
算法2: 滤波ROA提取算法。
输入: GPS数据GPSData
输出: ROA标签ROATag
GPSChangeRate←GetGPSChangeRate(GPSData)
GPSSmoothRate←SmoothFilter(GPSChangeRate)
GPSTag←LowPassFilter(GPSSmoothRate)
ROAMean←NULL
GPSList←NULL
FOR(iIN1:length(GPSData))
IF(GPSTag[i] == 1)
GPSList.add(GPSData[i])
ELSE
IF(GPSList!=NULL)
ROAMean.add(mean(GPSList))
GPSList←NULL
ROATag←mergeROA(GPSTag,ROAMean)
RETURNROATag
2.3 复杂活动识别方法
完成ROA提取后,需要为每个ROA训练一个分类器。特别的,当根据训练数据判定某个ROA为平凡ROA时,对该ROA不训练分类器,而直接使用该平凡ROA对应的复杂活动作为识别的结果。本文将从分类器数据采集及分类器设计两个方面介绍分类器的训练。
(1)数据采集。数据采集阶段,需要获取尽可能多的与用户复杂活动相关的特征,不同数据采集设备能获取到的数据不同,本文采用的智能手机作为数据采集的设备,因此,将以智能手机为例对数据采集的特征进行探讨。本文中采集的数据主要是:①时间。用户的复杂活动往往受到时间的约束,例如,用户在固定的时间上班,固定的时间下班,固定的时间吃饭等;②x、y、z方向的加速度。不同的复杂活动往往对应不同的加速度变化率,当用户睡眠时,加速度的变化率趋近于0,而当用户运动时,加速度值变化剧烈;③是否是工作日。用户在工作日的活动规律是与非工作日的活动规律不同的;④手机模式、是否在充电。某些用户的手机模式、充电状态是与用户的活动有关系的,例如某些用户习惯睡前将手机调为静音或震动模式,有些用户习惯睡眠的时候对手机充电等;⑤用户最近使用的5个App。由于智能手机的功能越来越强大,越来越多的人使用手机娱乐,学习,点外卖等,这时候,用户使用的App一定程度上与用户的复杂活动有关系。⑥GPS坐标。获得用户轨迹,提取ROA。⑦WiFi列表。用户直连WiFi和信号强度最强的15个WiFi MAC地址列表,提取ROA。
(2)分类器设计。由于不同分类器适用于不同的场景,为了发挥不同分类器在不同场景下的优势,本文分别为不同的ROA训练了kNN,SVM,决策树,朴素贝叶斯4种分类器。ROA提取算法会影响最优分类器的选择,本文在两种ROA提取算法的基础上,分别实现了上述的4种分类器。最优分类器与数据的特点具有比较密切的关系,无法根据ROA的特点直接选择最优分类器,由于留一交叉验证可以很好验证模型的泛化能力,本文采用留一交叉验证选择最优分类器。本文统计了所有ROA中,最优分类器的比例。在65%的ROA中,SVM是最优分类器,在32%的ROA中,决策树是最优分类器,3%的ROA中,朴素贝叶斯是最优分类器,没有任何ROA,kNN是最优分类器。因此,本文选择了SVM和决策树作为复杂活动识别的分类器。
3 实验结果及分析
本文将从比较基于密度聚类的ROA提取算法和基于滤波ROA提取算法的优劣以及验证ROA提取算法可以提高活动识别的准确性两个方面进行实验。为了比较两种ROA提取算法的优劣,首先本文对两种ROA提取算法的时间复杂度进行了严格的推导,比较两种算法时间复杂度的区别。然后分别使用两种ROA提取算法对相同的数据提取ROA,并使用相同的分类模型对活动进行识别,使用活动识别准确性来评价ROA提取算法准确性。为了验证ROA提取算法可以提高活动识别准确率,本文分别使用先提取ROA再分类的方法和直接分类的方法对相同的数据进行了实验,通过对比两种方法活动识别的准确率来验证ROA提取算法的效果。
3.1 实验数据集
我们在Android智能手机上实现了数据采集App来进行数据采集。数据采集App会以后台进程的形式使用 0.1 HZ 的频率进行数据收集,这样一个相对较低的频率使得数据采集App不会严重影响用户手机的续航能力。数据标注方面,一部分研究者采用的是用户开始活动时点击活动开始,结束是点击活动结束,用户点击按钮的时间即为活动的起始时间。实际使用过程中,本文发现,这种标注方式往往因为用户忘记标注活动结束而导致数据产生错误。因此,本文采用了用户在自己方便的时刻进行标注的方式,标注的时候用户可以选择活动的起始时间,从而减少错误标签的产生。大部分志愿者表示,这种标注方式对用户的正常生活干扰较小,友好性更强。
共7名志愿者参与了本次的数据采集,身份既有老师也有学生。他们有着不同的生活习惯和活动地点,从而保证了数据的多样性。每名志愿者收集了为期3周的活动数据,最后一共收集了130天的活动数据,共3120个小时,涉及活动标签743个,平均每个志愿者106个活动标签。
3.2 ROA提取算法的比较
本文在尝试了众多分类模型后,发现SVM和决策树是众多分类模型中性能最好的两个。因此本文采用了滤波提取ROA和SVM(Filter+SVM)、滤波提取ROA和决策树(Filter+DT)、聚类提取ROA和SVM(Cluster+SVM)以及聚类提取ROA和决策树(Cluster+DT)4种模型进行比较。本文使用数据集中前两周的数据作为训练集,分别对4种模型进行了训练,使用最后一周的数据作为预测集,得到了模型预测的结果。根据模型预测结果和数据采集时用户真实的活动标签,计算了4个模型对各种活动识别的准确率、召回率以及F-score,如图3所示。图3中对于学习和睡觉两种活动而言,滤波算法和聚类算法具有接近的F-score,对于吃饭、运动、家务和交通而言,滤波算法的F-score大于聚类算法的F-score。因为用户差异性和地点差异性会影响聚类算法参数的选择,导致部分数据被划分到错误的ROA导致活动识别产生错误。而滤波ROA提取算法参数受用户差异性和地点差异性影响较小,故取得了相对较高的F-score。

图3 两种ROA提取算法的对比
3.3 基于ROA复杂活动识别方法的准确性
因为基于滤波的ROA提取算法具有较高的准确性,因此本文采用了滤波ROA提取算法和SVM(Filter+SVM)、滤波ROA提取算法和决策树(Filter+DT)、不提取ROA的SVM(SVM)、不提取ROA的决策树(DT)这4种模型进行比较,同样采用前两周的数据作为训练集,后一周的数据作为预测集,计算了4种模型的准确率、召回率和F-score。如图4 所示。图4中,无论针对什么活动,加上ROA提取算法的模型F-score都大于不提取ROA直接分类的模型。极端的,对于睡觉这种活动,不提取ROA的情况下F-score为0,而提取ROA后,F-score超过90%。这表明ROA提取算法对于提高活动识别准确性具有明显作用。

图4 有ROA提取算法与无ROA提取算法的对比
表1中,列出了不同模型对各项活动识别的F-score,其中“所有”代表所有活动的F-score。从模型角度而言,Filter+SVM和Cluster+SVM的结果较好,并且相对接近,两种模型在识别不同的活动时各有优劣,但Filter+SVM的训练速度更快。Filter+DT的效果次于前两者,差别不大。SVM和DT与其它有ROA提取算法的模型效果相差甚多,再次验证了ROA提取算法有效提高了活动识别准确性。从活动的角度而言,学习、睡觉、运动、吃饭4种活动F-score较高,而家务、交通这两种活动F-score较低。本文对家务的定义是在家里发生的除了学习、睡觉、吃饭、运动以外的活动。由于家务的定义相对宽泛,并且用户在家里并不会随身携带手机,而经常将手机放置在某个地方从事家务,因此,对家务的识别率较低。借助室内定位技术和智能家居技术辅助识别家务将可能提高家务的识别率。对于交通而言,其错误的识别一般发生在用户离开座位但尚未离开建筑物或用户进入建筑区但尚未达到自己座位的时候。比如用户学习后离开建筑物步行一段时间进入餐厅吃饭,模型将离开座位但尚未离开教学楼和进入餐厅尚未到达座位的数据分别识别为学习和吃饭,而用户往往将这部分数据标记为交通。由于实际生活中,活动的切换并没有严格的界限,因此,模型对这部分数据的预测并不能认为是错误的,并且对实际的应用也不会产生太大的影响。因此,本文认为模型在这种情况下产生的误差是可以接受的。

表1 不同模型对各种活动识别的F-score
4 结束语
为了解决移动场景中的复杂活动识别问题,本文提出了一种基于ROA的复杂活动识别方法。该方法利用了时空轨迹对复杂活动的过滤作用,从数据中提取ROA,使得每个ROA中复杂活动种类相对较少,构成相对简单,规律性较强。在此基础上,该方法在不同的ROA上,可以使用不同分类模型对复杂活动进行区分,充分发挥不同分类模型在不同场景下的长处,大大提高了模型的鲁棒性。最后,本文基于现实生活中收集的数据进行了实验。实验结果表明,本文提出的基于ROA复杂活动识别方法可以明显提高复杂活动识别的准确率。
下一步,我们将从两个方面继续我们的工作,首先我们将考虑当用户到达一个新的位置,在没有有效历史数据的情况下怎样提高活动识别的准确性。进一步的,我们将考虑活动模式对活动识别的重要作用,用户活动一般具有较强的规律性和联系性,充分考虑活动模式将有助于提高用户活动识别的准确性。
