大数据环境下基于用户属性的细粒度访问控制
2020-07-20王嘉龙台宪青马治杰
王嘉龙,台宪青,马治杰
(1.中国科学院 物联网研究发展中心 数据与服务研发中心,江苏 无锡 214135;2.中国科学院大学 微电子学院,北京 101407; 3.中国科学院 电子学研究所苏州研究院地理空间信息系统研究室,江苏 苏州 215121)
0 引 言
随着大数据环境下数据量的飞速增长,越来越多的企业和机构选择通过搭建大数据平台的方式进行数据的存储、交付和扩展[1]。然而,随之带来的则是平台上的数据安全问题(如非法用户入侵)。为保证数据的安全访问,需要对用户和数据进行细粒度的访问控制,实现最小授权原则[2],保证信息资源不被非法使用和访问[3]。
Apache Ranger是一个集中式授权管理框架[4],支持绝大多数开源大数据组件的访问控制。然而,其访问控制模型基于用户/用户组指定静态策略进行授权,不能根据用户的多个属性标签进行分组授权,更不能根据用户的属性变化进行权限的动态变更,使得其仅适合应用于少量用户的权限管理中(详细解释参考1.2节)。
本文在Ranger基础上设计并实现一种基于用户属性的访问控制模型(user attribute based access control, UABAC)。UABAC模型将密文策略属性基加密算法(ciphertext policy attribute based encryption,CP-ABE)[5]应用于Ranger的访问控制中,实现了基于用户属性的细粒度访问控制,很好解决了大数据环境中访问控制面临的问题。
1 Ranger的访问控制模型
Apache Ranger是一个开源的中央授权管理组件,解决授权和审计的问题。它以插件化的形式,对Hadoop生态组件如HDFS、Hive、Hbase、Knox、Yarn、Storm、Solr、Kafka等,进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松通过配置策略来控制用户访问文件、文件夹、数据库、表或列的权限。
1.1 模型基本结构与授权方式
Ranger将策略直接与用户/用户组绑定,进行用户权限的授予,其权限模型如图1所示,具体解释如下。
U:Users,即为终端上访问数据和服务的用户。
G:Groups,即为多个用户组成的用户组,一个用户组可以有多个用户,一个用户也可以属于多个用户组。
S:Subjects,即为用户/用户组创建的访问数据和服务的实体(如读写数据的应用程序)。
HS:Hadoop Services,即Hadoop服务,如NameNode、Resource Manager等,用户或应用程序请求Hadoop服务以提交任务及读取任务的状态时,需获取相应的权限。
OPHS:Operations on Hadoop Services,即Hadoop服务支持的操作类型,如向YARN上提交MR任务等。
ES:Ecosystem Services,即Hadoop生态服务,位于Hadoop上的一组服务联合提供一项数据服务,如HDFS提供了分布式文件服务,Hive提供了数据仓库服务,ES也可被习惯性的叫作Hadoop组件。终端用户请求Hadoop组件获取其上的数据对象时,必须获取对应服务的权限。
OB:Data and Service Objects,即Hadoop组件服务的数据对象,不同服务提供了不同的对象,如HDFS的文件、Hive的表等。
OP:Operations on Objects,即数据对象支持的操作类型,如HDFS支持Read、Write,Hive表支持select、create 等。

图1 Ranger的访问控制模型[6]
Ranger的访问控制模型中,包含了两种授权对象:服务资源和数据资源[7]。这两类授权对象涵盖了大数据组件的所有资源类型,统一和规范化了大数据平台中授权对象的形式化描述。不同的授权对象拥有不同的操作类型,在授权时,使用(用户或用户组,授权对象,操作类型)三元组的形式描述访问控制策略,使得用户或用户组直接获得该授权对象的相应操作权限。用户或用户组和授权对象为多对多关系,一项授权对象可以赋给多个用户或用户组,一个用户或用户组也可以获得多项授权对象的访问权限。在Ranger的用户模型中,一个用户可以同时属于多个用户组,一个用户组也可以包含多个用户,用户可从用户组继承其拥有的权限,当用户拥有多个用户组的时候,就拥有了多个用户组对应的权限集合。用户可以创建多个实体,并将部分或全部权限赋予该实体。
1.2 模型的缺陷
Ranger的访问控制模型将权限和用户或用户组直接进行绑定,两者之间的耦合关系非常严重。因此,Ranger模型存在以下三方面的问题。
由于Ranger通过静态策略进行逐条授权,所以当面对海量用户时,会导致静态策略的指数增长。这样不仅带来巨大的时间和空间成本[8],更使得后续的权限变更十分复杂。
Ranger对单个用户或用户组进行授权,当需要对多个用户的权限进行统一管理,而这些用户又不在同一个用户组中的时候,只能逐条修改每个用户的策略,无法对一类用户进行有效的抽象。
在大数据环境下,面对动态变化的用户和数据资源时,Ranger的模型无法实现权限随着用户属性变化而动态变更,且Ranger使用单一用户ID区分用户,因此难以满足大数据环境下复杂的用户模型。
2 UABAC模型
本文在Ranger访问控制模型基础上,将属性作为访问控制的关键要素[9],提出了基于用户属性的访问控制技术(UABAC)。
2.1 UABAC基本思想
UABAC抛弃了Ranger中用户组的概念,为用户分配属性值,多个属性组成用户的属性集合。算法根据用户属性集合判定访问是否合法,实现了基于属性的访问控制。图2展示了UABAC的组成结构,其中灰色框部分为基于Ranger原生模型的改进,具体描述如下。

图2 UABAC
舍弃了用户组的概念,用户不再属于用户组,权限也不再赋予用户组。
引入用户属性(UA),用户可以拥有多个属性,同一属性也可被分给多个用户。
权限不再赋予用户/用户组,而是通过统一的访问控制机制进行管理,在该模块中基于用户属性指定访问控制树,访问控制树的详细描述可参见2.2中的定义7。
用户通过其创建的客体向大数据平台发送访问请求,每次请求视为一次单独的会话,请求的客体继承该用户的属性值。
2.2 UABAC基本概念
在Ranger访问控制模型基础上,UABAC引入了用户属性的概念,并通过属性值的逻辑运算进行访问控制。下面对UABAC模型的重要概念进行定义。
定义1 用户属性。表示用户某项特征的信息,如“age”表示用户的年龄。
定义2 属性值。用户属性的对应取值,如“age”的可取值为“17”。属性与属性值成对出现,以“key:value”的形式赋值给用户。
定义3 属性取值范围。根据属性表达的具体含义,其取值范围可分为原子型和集合型两种。当属性类型为原子型,该属性的取值为单个元素。当属性类型为集合型,该属性的取值为枚举集合中的多个元素,以“key:value”的形式通过空格字符连接,如“attr:val1 attr:val2 attr:val3”。
定义4 偏序关系。同一属性的对应取值可能存在偏序关系,如“年龄:17”<“年龄:18”,表示对于“年龄”属性,其取值“17”偏序于“18”。
定义5 包含关系。不同属性之间可能存在包含关系,如“部门”∈“公司”,表示公司包含了部门,这符合实际生活中对用户进行分层管理的场景。
定义6 属性值逻辑运算式。属性值对应的“key:value”可通过逻辑运算符“AND”、“OR”、“[m]of[n]”(m,n均为整数,m
定义7 访问控制树。以树状结构对一条属性值逻辑运算式的形式化表达,如“年龄>17 AND 部门:d1 OR (公司:c1 公司:c2 公司:c3 1of3)”可使用如图3所示的树表示。用户的属性值集合带入运算后,由根节点输出True或False。

图3 访问控制树示例
2.3 访问控制机制描述
为实现基于用户属性的访问控制,引入了CP-ABE算法。CP-ABE算法是一种非对称加密算法,可以在加密文件时为其指定访问控制树,并将其嵌入到密文中。当数据使用者进行解密时,当且仅当用户的属性集合满足该访问控制树时,才可解密成果。通过CP-ABE算法加解密过程,可以实现基于用户属性的访问控制。其在UABAC模型的应用中具体步骤如下:
(1)系统初始化。指定初始化参数,使用CP-ABE算法生成系统唯一的公钥和主钥[10],并将公钥和主钥以字符串的形式存储在关系型数据库中。
(2)用户注册。管理员向系统发送新用户的用户名和属性列表,系统将属性列表转换成CP-ABE算法可以识别的格式,并生成用户唯一的私钥,将新用户及其私钥存储在关系型数据库中。
(3)资源的授权。
1)管理员选定要进行授权的资源对象(如HDFS上的文件)以及对应的操作类型(如文件的Read、Write);
2)管理员指定本次授权的访问控制树policy_tree,形式与定义7中的示例类似;
3)根据本次要授权的资源对象名,生成一个与当前时间相关的随机字符串M;
4)使用CP-ABE算法加密M,将2)中的访问控制树作为CP-ABE算法加密时的控制字段,得到加密后的密文S;
5)申请创建策略,得到唯一值pid,并将(资源名,pid)二元组作为访问控制策略,存入策略列表中;
6)将(pid,S,M, policy_tree)四元组存入关系型数据库中。
(4)资源的访问控制。
1)根据本次访问的用户名,获取事先生成的该用户唯一私钥;
2)根据本次访问的资源名,获取对应的策略列表,得到授权时指定的唯一值pid;
3)根据pid查找关系型数据库,获取授权时随机字符串M,加密后字符串S,访问控制树policy_tree;
4)CP-ABE算法使用用户唯一私钥,解密失败,则判定用户非法,解密成功,则得到字符串M1;
5)判断解密结果M1是否与M相等,若相等,则判定用户合法,否则,判定非法。
(5)权限的变更。资源授权策略变更和用户属性变更均会导致用户权限的变更,其各自的工作流程如图4所示。

图4 权限变更流程
2.4 数据资源的粒度划分
为实现数据资源的细粒度访问控制,根据大数据组件常见的存储类型,使用分层的方式对资源对象进行粒度划分。
Server
URI
Database
Table
Row
Partition
Column
View
各层的具体含义详见表1。

表1 资源粒度描述
从根节点到叶子节点的完整路径表示了一个具体的资源对象,如server1->db1->table1->col1,表示了服务server1上的db1数据库中的table1表的col1列,对于不同类型资源对象,拥有相应的权限集合。
对于文件、消息队列来说,存在read、 write两种权限;
对于表来说,存在以下几种权限:
SELECT 表的查找
INSERT 行的插入
UPDATE 行的修改
DELETE 行的删除
CREATE 表的创建
DROP 表的删除
二元组(资源对象,权限操作符)用于表示一个具体的授权对象,如(server1->db1->table1->col1,SELECT) 表示对server1上数据库db1中表table1内col1列的select权限。授权时以授权对象为中心,通过为其指定访问控制树来限制获得对应权限的用户集合。
3 基于UABAC的访问控制系统
基于UABAC模型,设计系统来实现对大数据平台上文件、表、消息等资源的访问控制。
3.1 总体结构
图5展示了访问控制系统与其它平台或模块的交互关系,其具体含义如下。
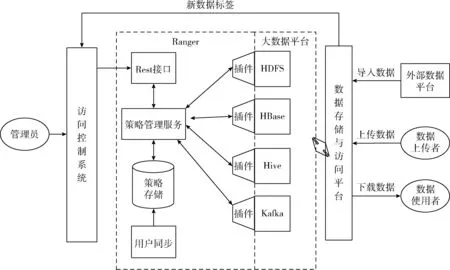
图5 访问控制系统总体设计
外部数据平台:第三方数据中心,可通过数据ETL将数据通过数据存储与访问平台导入到大数据平台中进行存储;
数据上传者:可将本地数据通过数据存储与访问平台的接口存储到大数据平台中;
数据使用者:可将大数据平台中的数据通过数据存储与访问平台的接口下载到本地使用;
数据存储与访问平台:数据服务平台,提供接口以供外部用户存储、访问大数据平台中的数据;
大数据平台:通过大数据组件(如HDFS、HBase、Hive、Kafka)搭建的数据集群;
Ranger:提供对大数据组件的访问控制,为实现基于用户属性的访问控制,需要对Plugin和Ranger Policy Admin Server进行修改;
访问控制系统:本文所实现的应用系统,为管理员提供大数据平台中数据资源的权限管理功能,达到了基于用户属性的访问控制目的。另外,系统接收数据存储与访问平台传来的新数据标签,方便管理员对新数据进行授权管理;
管理员:访问控制系统的使用者,通过可视化界面操作系统,完成大数据平台中数据的权限管理。
在介绍了访问控制系统与外部各平台的交互情况之后,下面对系统的软件架构进行设计。
图6展示了访问控制系统的软件架构及其依赖的软件环境。软件依赖环境中列出了应用系统所需的基本运行环境,其中操作系统可为主流操作系统中的任何一种;Spring Boot是应用系统开发的基本框架,其中内置的Tomcat服务器可作为系统启动的环境;MySQL用于存储应用系统的业务数据;Ranger是本系统依赖的大数据访问控制组件,本系统基于Ranger实现访问控制策略的管理和对大数据组件的访问控制。

图6 访问控制系统软件架构
访问控制系统包含了4层:数据层、服务层、应用层、展示层。数据层提供系统数据的交互,Spring JPA是一个ORM框架,实现MySQL数据库中表到java对象的映射;fastjson是JSON数据处理框架,用于实现json字符串和java对象间的相互转换。服务层提供系统的公共服务,包括访问控制模型的实现,CP-ABE算法以及系统日志等服务。应用层为系统的功能模块,分为用户管理、权限管理等。展示层提供终端用户访问系统的接口,以两种形式展示:Web UI提供的HTML界面和REST接口提供的JSON数据。服务层、应用层、展示层整体通过Spring MVC框架实现。
3.2 UABAC在系统中的实现
图7中灰色部分为UABAC模型在系统中实现涉及的模块,其各部分含义如下。

图7 系统访问控制模块的实现
UABAC管理接口:负责UABAC模型中资源的授权、权限变更的实现。
MySQL:关系型数据库,用于存储UABAC模型对应的访问控制策略以及CP-ABE算法的公共参数。
Ranger ABAC Provider:负责用户访问会话的拦截,并根据用户名进行会话信息的增强[11]。
Ranger ABAC Matcher:负责UABAC模型中的权限验证,在此屏蔽非法用户的访问。
管理员授权时,调用UABAC Admin API进行访问控制策略的设置。UABAC Admin API中实现2.3中UABAC模型的资源授权算法,通过该算法的6个步骤,产生了(资源名,pid)二元组和(pid,S,M,policy_tree)四元组。将(资源名,pid)二元组包装成Ranger策略,发送给Ranger Policy Admin Server进行创建,当策略创建成功后,将(pid,S,M,policy_tree)四元组存入到MySQL的对应表中,将pid设为主键。
当用户U发起对大数据平台上某项数据TO的访问请求时,Ranger Plugin会拦截用户的该请求,并进行权限的验证。通过Ranger ABAC Provider和Ranger ABAC Matcher进行会话的增强和调用UABAC模型的访问控制算法进行权限的验证,其具体的工作流程如图8所示。由于Ran-ger Plugin只能识别Ranger策略,因此将Ranger策略作为获取(pid,S,M, policy_tree)四元组的桥梁,最终通过CP-ABE算法解密S判断用户是否满足访问控制策略的要求。
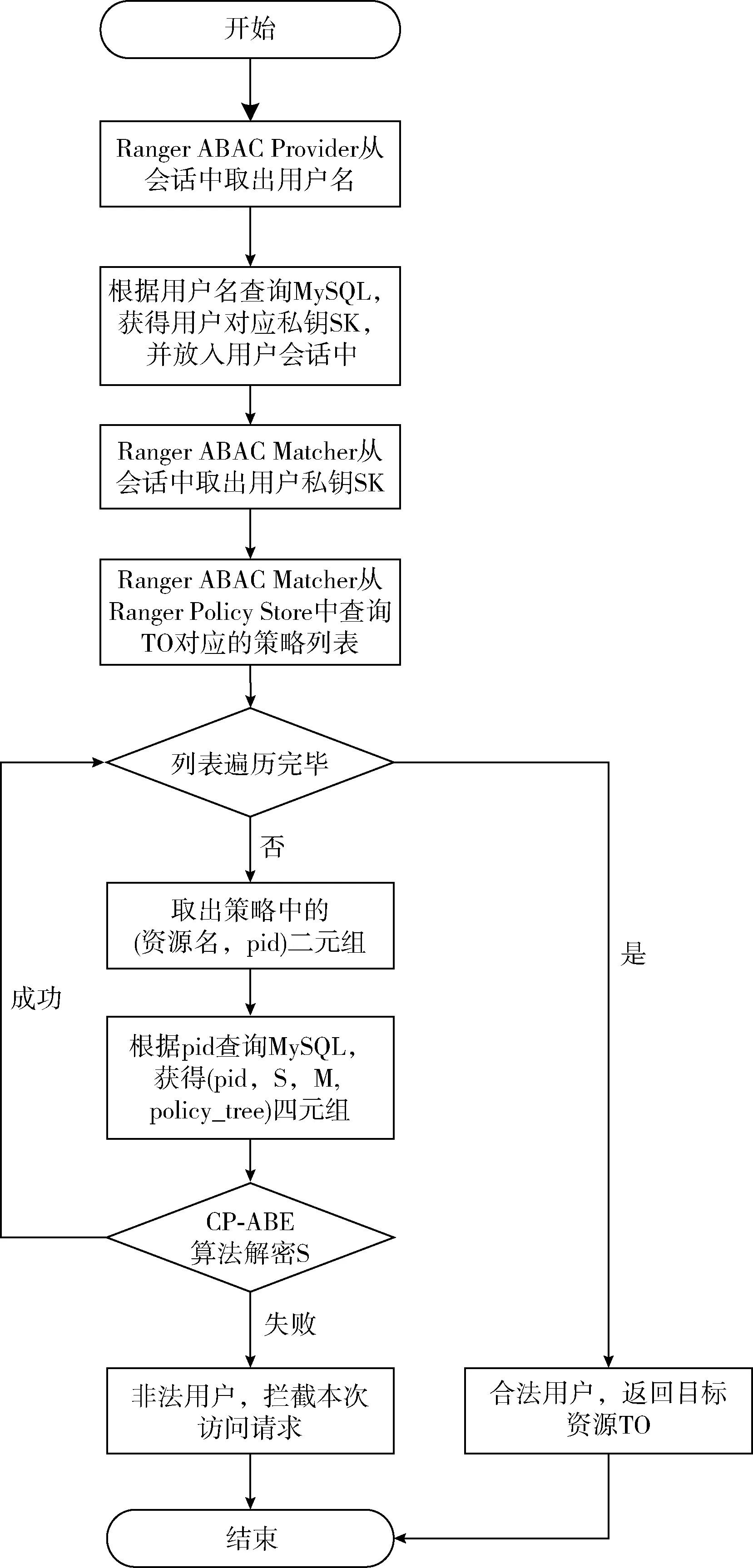
图8 会话劫持与访问控制
3.3 系统的优点
系统在Ranger基础上进行了功能增强,其在功能上的技术改进为如下4点。
(1)抛弃用户组概念,引入用户属性集合概念。
用户组的管理方式不适用于本系统的应用场景,因此抛弃用户组的概念,为用户引入属性集合。用户可拥有多个属性标签,通过属性标签的组合来代表用户的身份,与实际场景中的用户管理方式一致。另一方面,用户属性集合丰富了用户的身份信息,使得可通过属性集合来判定用户的当前身份。
(2)实现了基于用户属性的访问控制。
通过引入CP-ABE算法,实现了基于用户属性的访问控制,通过为授权对象指定访问控制树,使得只有属性集合满足该树的逻辑运算的用户可以获得对应的权限,极大丰富了授权方式,使得权限控制更加灵活。
(3)细粒度的访问控制。
根据大数据组件的数据类型,对数据资源进行了不同粒度的划分,并将(资源对象,权限操作符)二元组作为最基本授权对象,达到了细粒度的访问控制目的。
(4)兼容性高、可扩展。
UABAC模型在Ranger原生模型基础上改进,极大利用了Ranger原生模型的优点,当Ranger组件支持新的大数据组件的访问控制后,UABAC模型可以无缝兼容,不需要进行任何的修改,具备很高的可扩展性。
4 安全性分析
本文在Ranger访问控制模型上,引入CP-ABE算法,其主要区别为:在Ranger策略中加入访问控制树,并通过CP-ABE算法的加、解密过程判断用户是否符合策略要求。
首先,Ranger作为成熟的开源商用软件,其策略模型的安全性已经得到检验。其次,本文在Ranger策略中加入的访问控制树,是嵌入到通过CP-ABE算法加密随机字符串得到的密文中的,根据文献[12],在密钥不被泄漏的前提下,非法用户是无法成功解密获得加密前的随机字符串的,又由于字符串的随机性,非法用户无法通过猜测获得该字符串。因此,UABAC模型的安全性与CP-ABE算法一致,可以保证当且仅当用户属性满足访问控制树要求时,才可以访问目标资源。
5 仿真实验
本实验使用IDEA作为开发工具,选择Java作为编程语言,基于Spring Boot框架开发了一个REST服务器实现了UABAC模型,并选择MySQL数据库作为授权策略的持久化存储,另外基于Mockito框架开发了一个客户端模拟终端用户发出对服务器的数据请求。
定义REST服务器上的文件F作为客户端发出访问请求的目标文件,为文件F指定访问控制树,如图9所示。访问控制树中包含3种属性attr0、attr1、attr2,它们的值分别可以被指定为val0、val1、val2。根据访问控制树的定义,只有用户同时含有attr0、attr1、attr2这3种属性的时候,且其属性值为{val0、val1、val2}中的一个时,该用户才满足访问控制树的逻辑运算,进而拥有对应的访问权限,即文件F的访问权限。
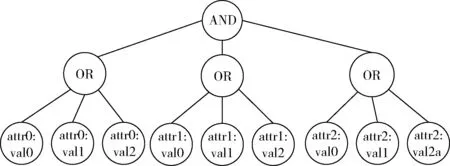
图9 访问控制树
设置每次实验的总用户数分别为10、100、500、1000、1500、2000、3000、4000、5000、10 000。利用随机函数生成每个终端用户的属性,使得总用户数中合法用户(同时具有图7中3种属性的用户)和非法用户(不同时具有,或仅具有部分图7中3种属性的用户)的比值约为1∶2。统计每次实验通过的用户数(合法用户判定为合法、非法用户判定为非法的总个数)、通过的合法用户数(合法用户判定为合法的个数)和通过的非法用户数(非法用户判定为非法的个数),并计算每次实验中单条测试平均时间(对单个用户判定合法/非法所消耗的时间),实验结果见表2。
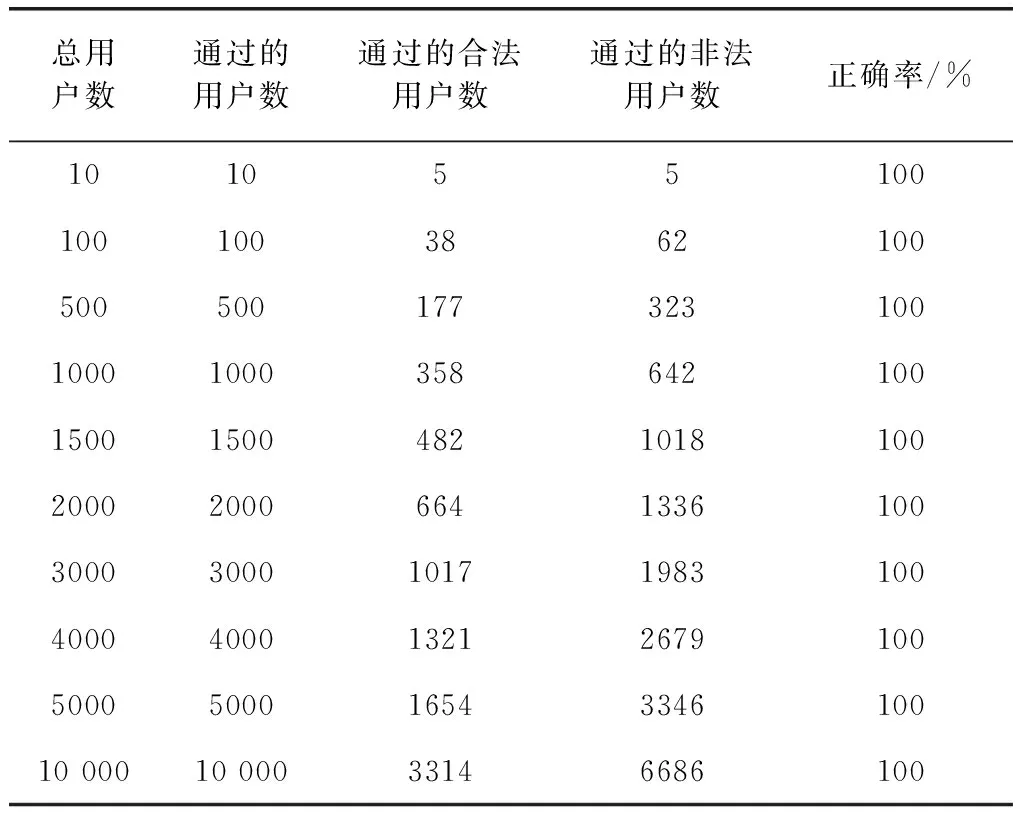
表2 正确性验证实验结果
表2展示了每次实验的总用户数、通过的用户数、通过的合法用户数以及通过的非法用户数,据此可计算每次实验的正确率(正确率=通过的用户数/总用户数)。由表中数据可得,随着总用户数量的增多,每次实验中通过的用户数始终等于总用户数,即UABAC模型的正确率均为100%。而且,合法用户与非法用户个数的比值接近于1∶2,符合实验预期结果。实验结果表明,UABAC模型能够实现基于用户属性的访问控制功能,正确率为100%。Ranger原生访问控制模型仅支持对用户进行分组管理和授权,不支持为用户添加丰富多样的属性值,更无法实现如图9所示的通过AND、OR等逻辑运算符构成的复杂访问控制结构,因此无法实现本实验对应的访问控制场景。
图10折线图展示了每次实验中对单个用户进行授权和鉴权所耗费的时间,以毫秒为单位。由图可知,随着用户个数的增多,单个用户的耗时不会呈现上升趋势,且逐渐稳定在350 ms左右。由于大数据环境下多为GB级以上的数据访问,毫秒级别的访问控制耗时几乎可以忽略不计,而且随着用户个数的增多,访问控制的耗时稳定不变。由于CP-ABE算法需要进行初始化以生成系统公钥和主钥,因此在用户数量较少时单个用户测试时间较高,而公钥和主钥只需要生成一次,随着用户数量的增多使得平均每个用户的测试耗时降低。综上分析,本文的访问控制方法不受系统中总用户个数的影响,适用于大数据环境下针对多种类、大批量用户的访问控制场景。

图10 测试时间统计
6 结束语
本文针对大数据环境下访问控制技术面临的挑战,研究了开源组件Ranger的不足,并基于Ranger设计与实现了一种基于用户属性的细粒度访问控制模型,最后验证了模型的正确性并测试了其访问控制的耗时。本方案实现了用户属性级别的访问控制,并可根据动态属性实现权限的动态变更,更加灵活、准确完成访问控制系统的授权工作。然而,此模型在解决用户属性继承关系的权限问题上仍存在缺陷,需通过深入分析与研究,加以改进和完善。
