物联网边缘计算服务容灾算法分析与验证
2020-07-20郭荣佐
黎 明,李 露,郭荣佐
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
有限的网络带宽、云计算能力的不足已经无法满足物联网应用的低延迟要求[1],新兴的边缘计算是其有效解决方案[2]。然而,边缘服务的可靠性是亟待解决的问题,服务可靠性的重要方面,就是服务数据的容灾特性[3]。为提高服务的可靠性,以克服边缘服务的不稳定性,就需要提高其服务的容灾特性。
国内外研究者们对边缘计算的可靠性研究[4-6],在小范围的故障时可提高系统可靠性,而对地震、洪灾等不可抗灾难则是无效的。近年来,研究者们研究了基于集中式云计算的容灾。Alexander Lenk等[7]提出了一种将云中的分布式系统复制到另一个云的新方法。Yu Wan等[8]设计了一种用于备份HDFS数据的系统,能够以高速实现客户端与远程服务器之间的备份和恢复。Wang等[9]分析了云托管企业应用程序的灾难恢复,提出一种调度算法。由此,现有研究主要针对集中式云计算中心而建立一套备份容灾系统[10],但物联网边缘计算的边缘服务器较密集,必须研究适合于物联网边缘计算特点的容灾方案和容灾算法。
综上,为解决物联网边缘计算的服务容灾问题,以确保边缘服务器上的数据安全性,提出一种基于站点协作的容灾方案,并对该容灾方案的算法进行设计。同时,通过多台虚拟机模拟边缘服务器,搭建一个小型容灾系统,对所提出的容灾算法的执行延迟时间以及系统可靠性与增加中间件的方案进行比较,突出本文算法的优越性。
1 物联网边缘服务容灾架构
物联网概念从提出到应用,其体系结构亦在不断进行演化和变迁,仅集中式物联网已由5层系统结构演变为三层模式,又由三层向多层模式转化。在集中式三层/多层物联网体系结构中,感知层数据通过网络层传输到云中心进行处理;而云中心存储能力不足、骨干网络带宽需求高等问题,已成为物联网发展和应用的瓶颈。
随着边缘计算概念的提出和不断发展,以使物联网由集中式向边缘计算模式进化。物联网边缘计算在靠近感知层增加边缘服务节点,能够对大部分数据进行处理、卸载与计算任务调度等,从而使车联网、增强现实和工业物联网等延迟敏感型应用成为可能。此外,通过靠近用户的边缘服务节点处理数据,减少传到云中心的数据流量,从而降低云中心数据存储量和减少网络带宽等。物联网边缘计算的边缘服务容灾是针对边缘服务节点层,通过边缘服务节点间协作而成为一个自组织的容灾子系统,以实现系统遭遇区域性灾害时的保护数据,同时,提高边缘服务的可靠性、延伸服务的连续性。因此,增加边缘服务节点后的物联网边缘计算体系结构,如图1(a)所示。

图1 物联网边缘服务容灾架构
物联网边缘计算的边缘服务容灾后,容灾体系结构如图1(b)所示。容灾组成架构中的源服务器(source server,Ss),在用户购买容灾服务时,由通信人员指定,主要为用户提供相关服务,并将用户数据同步或异步复制到灾备服务器;近距离灾备服务器(short-range disaster recovery server,S-DRS),由Ss根据相邻服务器的链路情况选择,正常情况下,Ss将数据同步复制到S-DRS,保证在节点或网络故障时RPO、RTO接近0,Ss故障时,S-DRS 接替其工作,具体如何切换到备用服务器不是本项工作的内容,可参考Ayari等[11]的研究;远距离灾备服务器(remote disaster recovery server, R-DRS)通过相邻最远的服务器之间传递Req数据报协作得到,用于异地保存Ss的数据,在发生区域性灾难时,如地震、洪水、停电等,能够根据用户需求,不同程度地保护数据不被丢失。S-DRS 和R-DRS同时也作为其他用户的Ss,每个边缘服务器处于热备用状态,不会浪费边缘服务器的计算能力。
2 容灾算法
基于提出的容灾架构,设计了相应的容灾算法。本部分从DR(disaster recovery)数据报的格式、算法描述两方面对算法进行设计。
2.1 DR数据报格式
DR数据报是本文容灾算法中数据报的总称,如表1所示,DR数据报中各个部分的含义如下:
Sid:源服务器的IP地址。Sid与普通网络的IP地址不同,当搜寻R-DRS时,中间的边缘服务器不能修改Sid,仅符合Sid的边缘服务器返回ReqACK应答数据报,则返回该应答的边缘服务器即为R-DRS。
Did:目标IP地址。
Type:DR数据报的类型,共有以下4种。
Message:普通的数据报。
ASK:邻接服务器间间歇互发的测试服务可达性的问候数据报,并以此更新服务器的链路信息表。
Req:寻找R-DRS时发送的询问数据报。
ReqACK:对于Req数据报,若当前服务器满足容灾的距离要求,则返回ReqACK应答数据报给源服务器。
Time:DR数据报发送的时间戳。
Distance:当前边缘服务器到Ss的链路距离。
Dmax:容灾的距离要求,由用户购买容灾服务的等级决定。
Data:数据部分。

表1 DR数据报格式
2.2 数据库表
服务器邻接状态表(tblNeighbor,tblNB),用于保存服务器到相邻服务器的链路距离,见表2。Neighbor为邻接服务器的IP地址,d为到对应邻接服务器之间的距离。具体如何得到在下一节的算法描述中介绍。

表2 tblNB
服务器容灾信息表(tblDisasterRecovery,tblDR),用于保存服务器的容灾对象,即服务器作为用户的源服务器,则为该用户添加一条数据,其结构见表3。UserIP为用户的IP地址,IsDR表示该用户是否购买了容灾服务,Dmax为该用户对容灾距离的要求,S-DRS和R-DRS分别为相应服务器的IP地址。UserIP、IsDR和Dmax这3项是在用户购买容灾服务时告知通信人员,通信人员将信息插入数据库表中,此时S-DRS和R-DRS为空,Ss通过执行相关的容灾算法,得到S-DRS和R-DRS。

表3 tblDR
2.3 算法描述
本文采用基于事件的方式呈现算法,分别对建立tblNB表、建立tblDR表和处理Message数据报进行描述。
2.3.1 建立tblNB表
在createtblNB算法中,首先建立一个tblNB表,然后创建一个子线程,函数接口为receiveASK,主线程每隔 10 s 向相邻服务器发送ASK数据报。receiveASK函数监听当前服务器端口为9900处的数据报,计算接收到的数据报中的时间戳与当前时间戳之差,结合数据传输速率,估算出相邻两个服务器间的距离d,若当前tblNB表中的Neighbor不包含接收到数据报的Sid,则将Sid和对应的距离d插入tblNB表中,若包含,则更新距离d的值,同时,若长时间未再次收到表中邻接服务器的ASK数据报,则将其从表中删除。实现tblNB表在初始时的建立以及链路变化后的更新。其流程如图2所示。
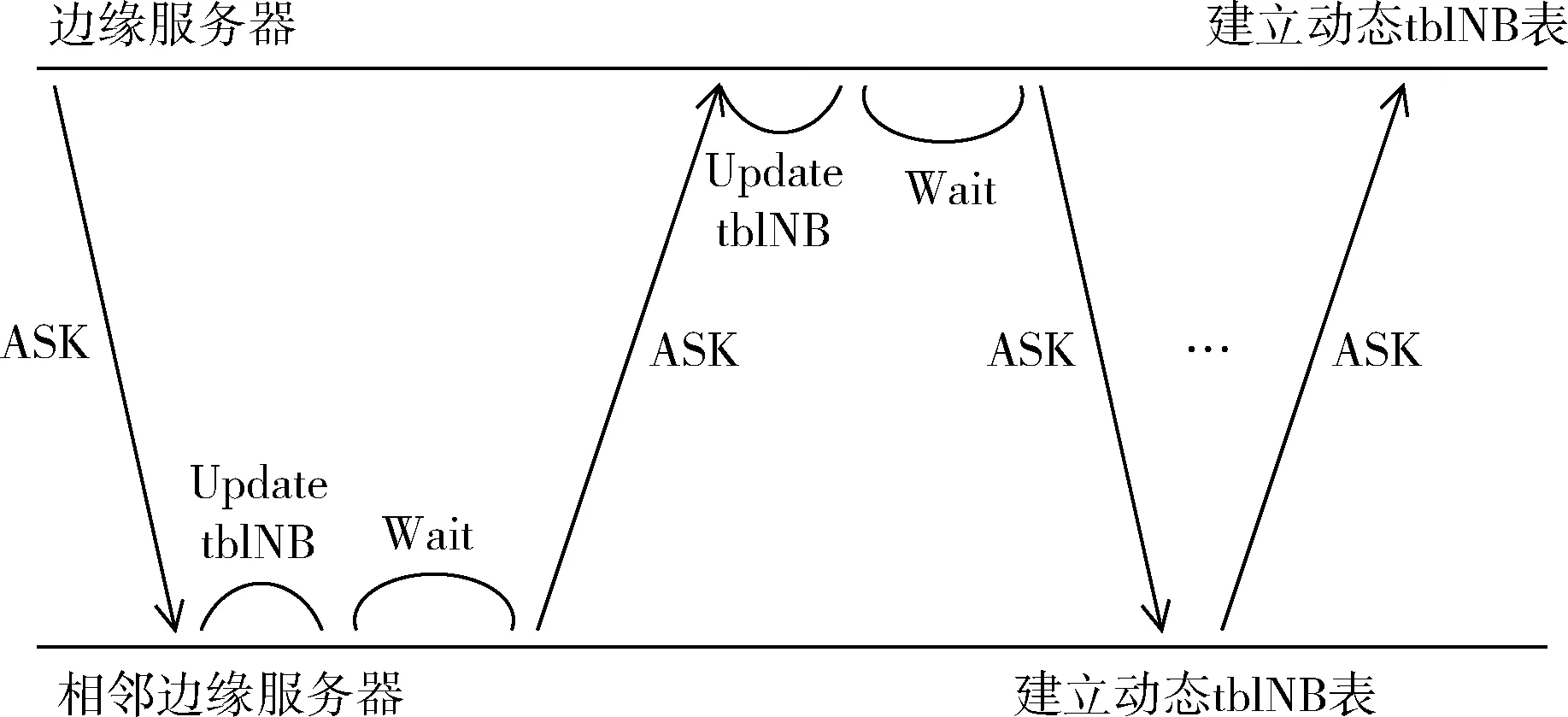
图2 建立tblNB表的流程
建立tblNB表:
(1) create table tblNB
(2) create thread(reciveASK,&host)#线程监听ASK并更新tblNB
(3)whiletruethen
(4) wait 10 s #发送ASK间隔时间,可根据用户情况修改
(5)Forip in tblNB.Neighborthen
(6) Send ASK to Neighbor
(7)EndFor
(8)EndWhile
2.3.2 建立tblDR表
在create算法中,创建了一个tblDR表并插入了一条UserIP为‘192.168.56.109’的数据。源服务器通过遍历tblNB表得到S-DRS和最远的邻接服务器(farthest adjacent server,Fas),再向Fas发送Req数据报,等待符合要求的服务器返回ReqACK数据报。接收到Req数据报的服务器,根据数据报中的Dmax和Distance,以及自身的存储能力,判断是否满足容灾要求,若满足则返回ReqACK数据报,源服务器接收到ReqACK数据报则更新tblDR表中的R-DRS。其流程如图3所示。

图3 建立tblDR表的流程
建立tblDR表:
(1) create table tblDR
(2) insert (UserIp,IsDR,Dmax) into tblDR
(3)IfS-DRS and R-DRS is nullthen
(4) S-DRS←selecttblNB#查询最近邻接服务器
(5) Fas,d←selecttblNB#查询最远邻接服务器和对应距离
(6) sendReq to Fas
(7) listening ReqACK #监听ReqACK数据报
(8) tblDR.R-DRS←ReqACK.Sid
(9)EndIf
2.3.3 处理Message数据报
接收到Message数据报保存到“server_data”文件中。然后判断该数据报是否来自邻接服务器,若是,则是作为S-DRS接收到该数据,不需要做其它操作;否则,将数据再写入“server_data_temp”文件,调用handle_Message函数处理数据,将数据同步备份到S-DRS、将“server_data_temp”中的数据异步备份到R-DRS并清空“server_data_temp”文件中的数据,保证每次备份的数据不重复。其流程如图4所示。
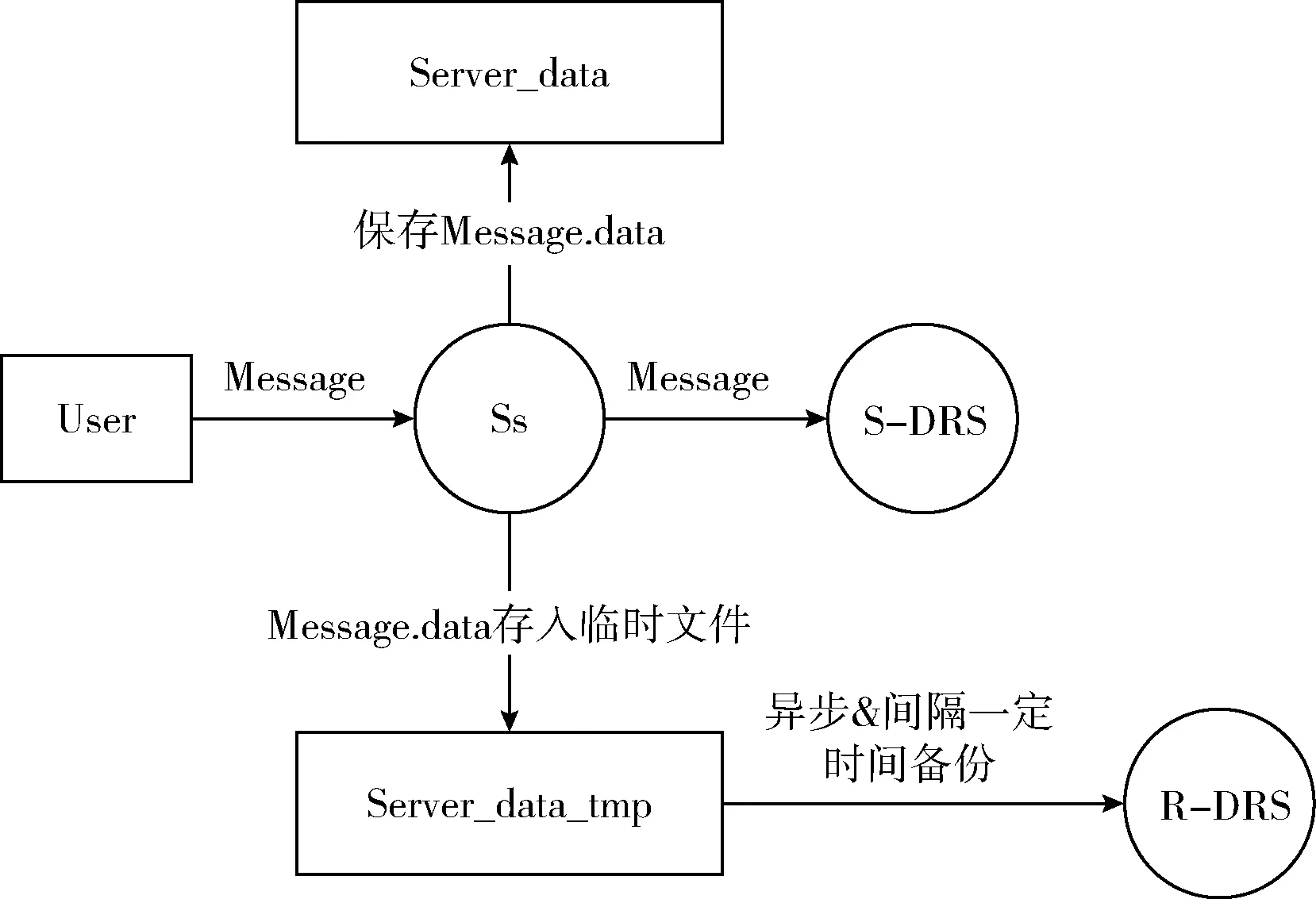
图4 处理Message数据报
处理Message数据:
(1)Whiletruethen
(2) Listening Message #监听Message
(3) Save Message.data to ‘server_data’ #保存数据
(4)IfMessage.Sid not exits in tblNBthen#Message来自用户
(5) Write Data.data to ‘server_data_temp’
(6) create thread(backup to R-DRS)#异步备份并清空‘server_data_temp’文件
(7) send Message to S-DRS #同步备份
(8)EndIf
(9)EndWhile
由上可知,算法的相邻服务器之间通过交换相关数据报,建立相邻的链路信息表,依次向相邻远端服务器发送询问R-DRS的数据报,根据返回结果建立容灾服务表,最后根据容灾服务表对用户的数据进行同步和异步的备份。该容灾算法可实现[12],实现时,仅对寻找S-DRS、D-DRS以及数据备份过程进行设计即可。
3 算法分析与验证
3.1 算法分析
3.1.1 时间消耗
在分析算法时间消耗时,假设链路材质与距离等引起的传输延迟不计。
(1)建立tblNB表:时间消耗主要是发送和更新时查询数据库的时间。假设建立tblNB表的执行时间为T1,相邻服务器的数量为n,查询tblNB表中一条数据的时间为t。则:T1=nt。
(2)建立tblDR表:时间消耗主要是遍历tblNB表、发送Req数据报和等待ReqACK数据报。根据(1)中的假设,得到遍历tblNB表的执行时间为2nt。假设传输平均速率为v,则发送Req并等待接收ReqACK数据报的执行时间为2(Dmax/v),则建立tblDR表的执行时间T2=2nt+2Dmax/v。
(3)处理Message数据报的时间消耗:主要是将数据分别同步、异步备份到S-DRS和R-DRS。根据上面的假设,发送到S-DRS的执行时间T3=d/v+t; 同时,发送到R-DRS的执行时间T4=Dmax/v+t。
综上,执行该算法的总时间为
T总=T1+T2+T3+T4=
nt+2nt+2Dmax/v+d/v+t+Dmax/v+t=
3nt+2t+3Dmax/v+d/v
(1)
式中:v和d的值取决于边缘计算的链路设计,在边缘服务器部署后是不变的,同时,查询表中一条数据的时间t也是不变的,则执行时间T总随n的增加呈线性增长。
3.1.2 空间消耗
tblNB表的大小与相邻服务器数量相关,而数量n最多不过百条,在系统上所占的开销很小。
tblDR表的大小与用户数量有关,当前服务器作为某一用户的源服务器,该服务器便会新增一条相应的记录,由于边缘服务器的密集部署,一个边缘服务器负责的周围区域并不会很大,所以tblDR表所需的开销也很小。
处理Message数据报的空间消耗主要是保存用户数据的“server_data”和“server_data_temp”文件,“server_data”文件是必要的,则空间的额外开销主要是“server_data_temp”文件。
综上,该算法所需系统的空间消耗主要是“server_data_temp”文件,而“server_data_temp”文件的内容在每次向R-DRS异步备份后被清空,其大小取决于异步备份的间隔时间以及在此时间内用户的使用情况。这是一个NP难问题,因为并不能预测用户在此时间内的使用情况。只能通过减小时间间隔来使“server_data_temp”文件所需空间更小,但是时间间隔的缩小必然会增加网络流量负担,将在后面的算法验证中得到“server_data_temp”文件大小与间隔时间以及用户请求数量之间的关系图,管理人员可根据边缘设备的存储能力以及用户使用情况来设置异步备份的时间间隔。
3.1.3 系统可靠性
在本文提出的容灾架构中,系统的失效率受边缘节点以及链路故障影响,由于边缘节点和链路只存在正常与故障两种状态,故采用故障树(fault tree analysis,FTA)的方法来分析系统的失效率。
系统失效是在Ss、S-DRS、R-DRS服务同时故障的情况下发生,Ss、S-DRS、R-DRS服务故障分别是在对应的边缘服务器故障或到用户的某一链路故障时出现,而边缘服务器故障可能是硬件的损坏或自然灾害导致。此外,由于Ss、S-DRS距离很近,可以假定Ss和S-DRS同时遭遇自然灾害的破坏。基于此,对系统可靠性进行故障树建模如图5所示。
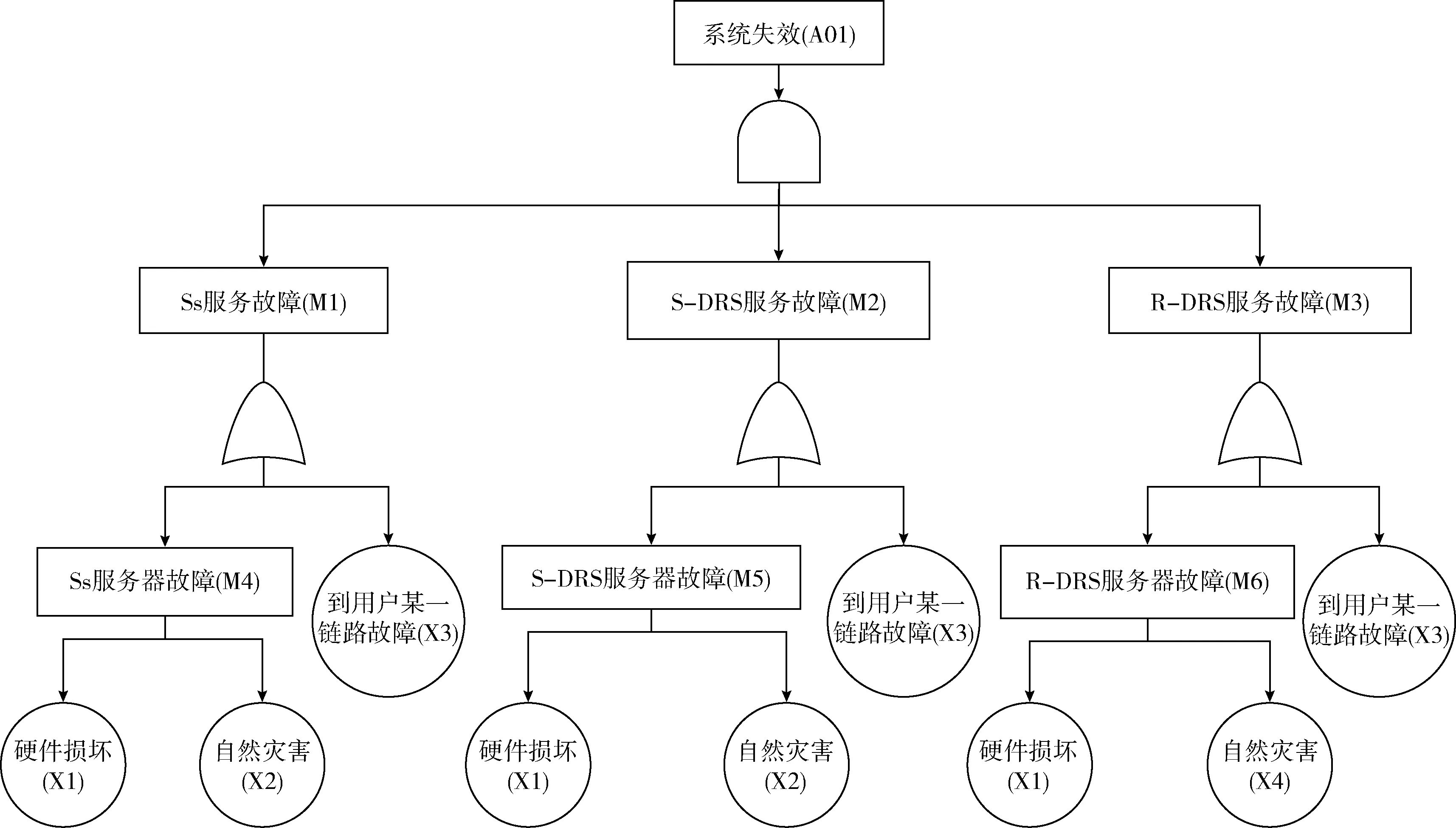
图5 容灾系统失效的故障树
假设Ss、S-DRS、R-DRS服务器故障的概率分别为PM4、PM5、PM6,Ss、S-DRS、R-DRS服务故障的概率分别为PM1、PM2、PM3,整体系统失效的概率为PA01。根据FTA分析可得如下公式
PM4=Px1+Px2,PM5=Px1+Px2,PM6=Px1+Px4
(2)
PM1=kPx3+PM4=kPx3+Px1+Px2
(3)
PM2=mPx3+PM5=mPx3+Px1+Px2
(4)
PM3=nPx3+PM6=nPx3+Px1+Px4
(5)
PA01=PM1PM2PM3=(kPx3+Px1+Px2)
(mPx3+Px1+Px2)(nPx3+Px1+Px4)
(6)
式中:k、m、n分别代表Ss、S-DRS、R-DRS到用户的链路数,与用户的距离直接相关,此外,由图1的物联网边缘服务容灾架构可知,R-DRS到用户的距离远大于Ss和S-DRS到用户的距离,所以k≈m≪n。
3.2 算法验证
实验基于Debian9.6.0系统,使用Python2以及内置的sqlite3,采用socket通信编程实现。实验在同一局域网内完成,共使用6台虚拟机,模型如图6所示,用户默认的Ss是“192.168.56.101”。根据实验的模型,通过ASK数据报建立tblNB表。设置用户“192.168.56.109”的容灾距离要求为1 000 000,通过tblNB表以及Req数据报,得到用户的S-DRS是“192.168.56.103”,R-DRS是“192.168.56.105”。下面将从时间、空间消耗以及系统的可靠性对算法分析进行验证。
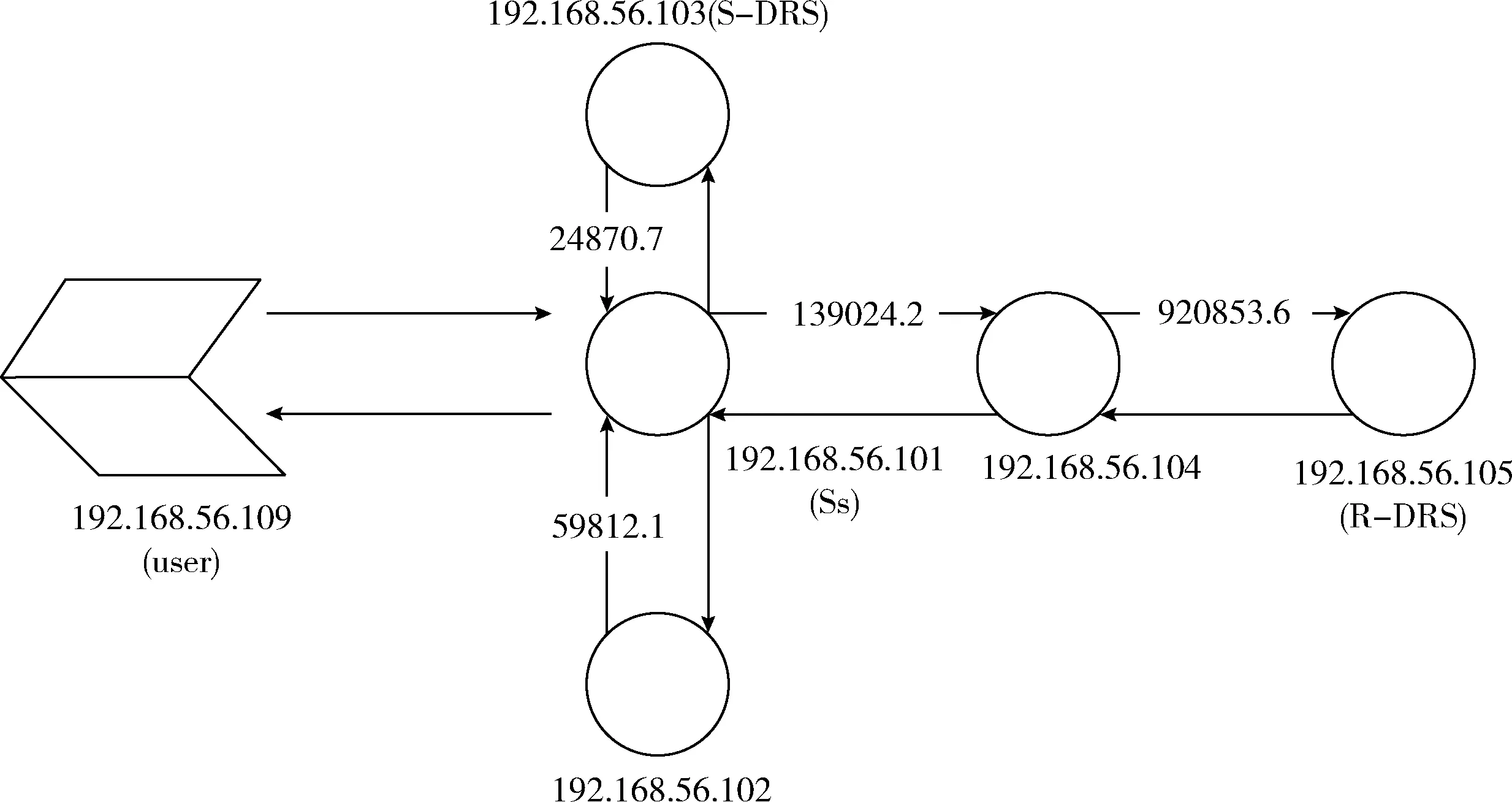
图6 实验模型
3.2.1 时间消耗验证
首先模拟了相邻服务器之间发送ASK数据报、监听ASK数据报并更新tblNB表的过程。在实验中,忽略数据报在链路上的传输时间以及发送ASK的间隔时间,得到发送和处理一条ASK数据报的执行时间分别为10 ms、20 ms,则T1=30n(ms)。
然后模拟了建立tblDR表的过程,根据图6的实验模型,在虚拟机上运行了createDR函数,根据时间戳之差,得到了在该模型中建立tblDR表所需时间约为T2=5300ms。
最后,模拟了备份数据的过程,忽略链路延迟,在虚拟机的理想状态下,得到了备份一条数据到S-DRS的执行时间为10 ms,备份一条数据到R-DRS的执行时间20 ms。由于备份到R-DRS是异步进行,则处理数据的延迟时间仅跟T3有关。假设用户的请求包含N个数据报,则在处理每条数据时,算法的执行时间T3=10N(ms)。
综上,因为只有在初始化时才需要建立tblNB和tblDR表,则算法在初始和真正运行的执行延迟时间分别为T初=30n+5300;T延=10N。
本文算法的初始时间消耗随相邻服务器数量增加的变化,如图7所示。同时,将本文算法的执行时间和文献[5]中增加中间件方案的执行时间进行对比。显然,本文算法虽然在初始化时需要消耗较多的时间,但是,在相邻的边缘服务器数量小于15台时,本文算法的执行延迟时间远低于文献[5]中的方案,如图8所示。

图7 初始时间消耗
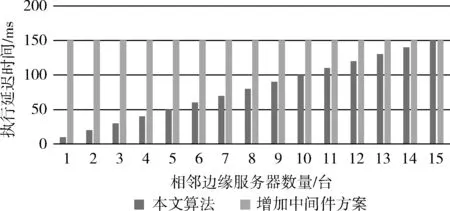
图8 执行延迟时间对比
3.2.2 空间消耗验证
在实验中,通过向tblNB表中插入多条数据,发现数据库DRserver.db的大小并不是每插入一条数据便增长,当插入的数据小于233条时,通过”ls-l”命令查看到DRserver.db的大小为12 288字节,超过233条时,DRserver.db的大小增长到20 480字节,可见,DRser-ver.db的大小是按照8192字节增长。显然,在本文提出的容灾架构中,tblNB表和tblDR表中的数据均不会超过223条,则数据库所占空间大小为12 288字节。对于”server_data_temp”临时文件,所占空间的大小由间隔时间以及用户的请求频率决定,假设异步备份间隔时间为t,请求频率为V(次/s),每次请求包含数据量为N条,由TCP/IP通信协议可知,数据报每条不超过1460(Byte)。则文件所需大小为:S=(V*N*1460)/1024(Mbyte)。 通过模拟实验,得到了临时文件大小在不同的间隔时间内随用户请求数量的变化,单位是Mbytes。在实际应用中,异步备份间隔时间可根据用户的使用情况以及用户对容灾系统的级别要求选择,容灾级别具有弹性。如图9所示。
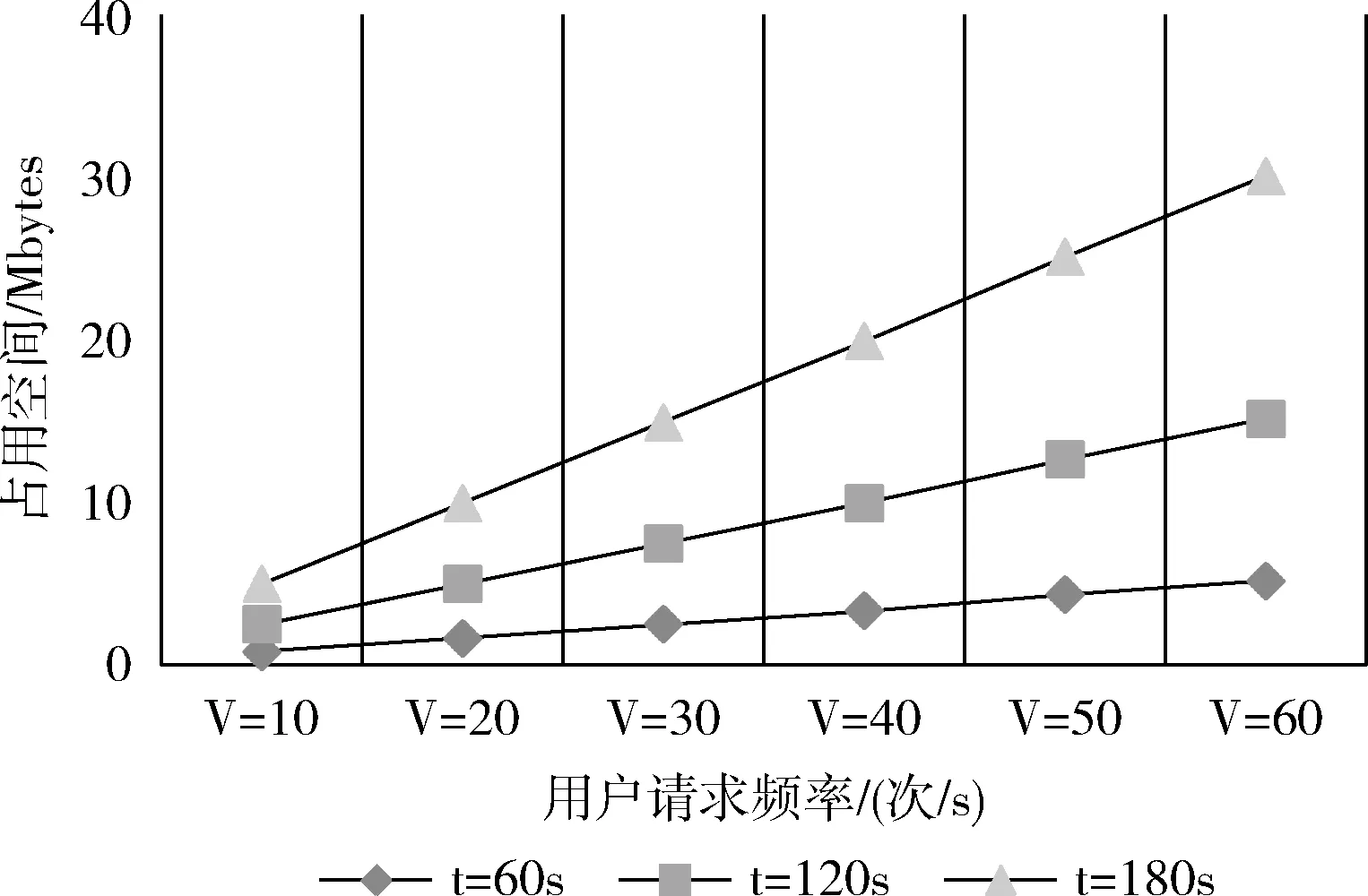
图9 文件所占空间变化
3.2.3 可靠性验证
假设系统失效故障树的基本事件情况见表4,在之后的实验中将在此假设的基础上进行。最终得出的结果通过对比得到,所以数值本身的大小对算法分析无影响,只需关注数值之间的大小。
基于以上假设,对式(6)进行MATLAB仿真,由于k≈m≪n, 可以假设k=m∈(1,10),n∈(10,50),得到系统失效率如图10所示。

表4 故障树的基本事件情况
对文献[5]中增加中间件的方案进行故障树建模,如图11所示。假设边缘节点和簇头服务故障的概率分别为PM21、PM22,边缘节点和簇头故障的概率分别为PM23和PM24,增加中间件方案的失效率为PA02。根据FTA分析得到如下公式
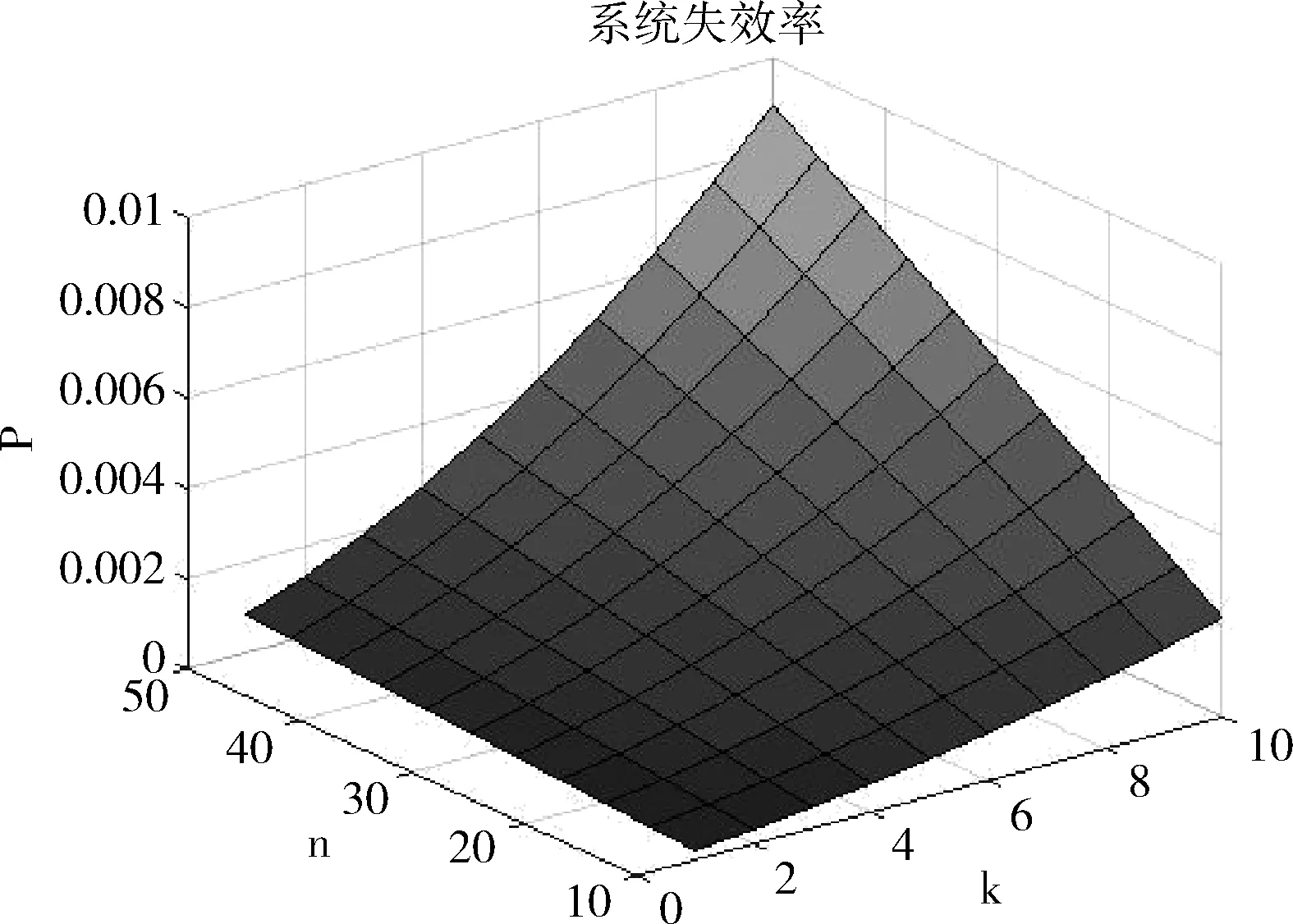
图10 本文算法
PM23=PM24=Px1+Px2
(7)
PM21=PM23+Px3=Px1+Px2+kPx3
(8)
PM22=PM24+Px3=Px1+Px2+mPx3
(9)
PA02=PM21PM22=(Px1+Px2+kPx3)(Px1+Px2+mPx3)
(10)

图11 增加中间件方案
由于边缘节点与簇头到用户的链路数几乎相同,可以假设k=m∈(1,10), 通过MATLAB仿真得到如图12所示关系。

图12 增加中间件方案
由图10与图12对比可知,本文设计的容灾算法在系统失效率上平均低于文献[5]方案的系统失效率,本文算法的可靠性更高。
4 容灾性能分析
4.1 网络负载
本文采用iptables统计端口流量,得到了在建立tblNB表时,网络负载随着相邻服务器数量增加的变化,如图13所示。
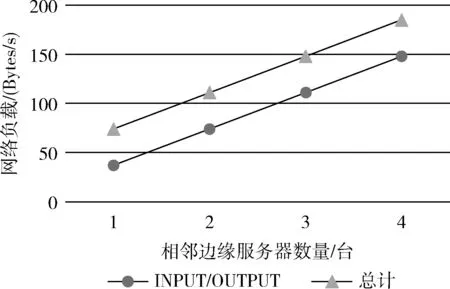
图13 网络负载变化
在该表中,一条是Ss在9900端口处的INPUT/OUTPUT流量,另一条是该处的总计流量。由图13可知,ASK数据报仅以每秒几十字节进行传送,对网络的负载影响很小;结合实际需求,调整发送ASK的间隔时间,以降低网络负载或提高更新表的速度。
建立tblDR表时,网络负载仅发送一条Req数据报和接收一条ReqACK数据报,且建立tblDR表仅在初始化时进行。Message数据报是用户的数据报。该算法下仅ASK数据报是额外的开销,但对整个方案在网络负载上对通信的影响是非常小的。
4.2 RPO
RPO(recovery point objective)是针对数据丢失的指标,指灾难发生时刻与最后一次备份的时间间隔。S-DRS同步复制Ss的数据,若只有Ss故障,数据的丢失接近于0。R-DRS异步复制Ss的数据,若Ss与S-DRS同时故障,则数据的丢失主要取决于在异步备份的间隔时间内,用户传输到Ss的数据。

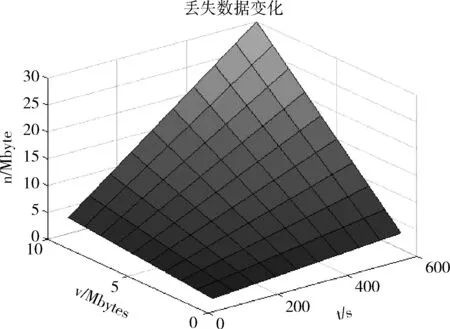
图14 丢失数据变化
5 结束语
边缘计算的兴起是必然的,主要探讨基于边缘计算特性的容灾算法。通过边缘服务器本身进行容灾,突破传统容灾的局限性,降低容灾成本和复杂性,提高容灾服务质量。通过算法分析和实验验证,从执行时间延迟和可靠性突出该算法的优越性,同时,也从空间消耗、网络负载、RPO验证了该算法的可行性。通过合理地部署边缘服务器,优化容灾方案,为边缘服务器的部署提供容灾措施。当然,该方案亦存在不足,如在Ss选择R-DRS时,若Req数据报未按单方向发送,可能导致累加的链路距离远远大于Ss与R-DRS之间的地理距离,不过这种隐患很少出现,亦或存在其它方面的不足,下一步将从这些不足入手,进行深入研究。
