基于相似性度量的用户推荐方法
2020-07-20虞慧群范贵生
张 许,虞慧群,范贵生
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
推荐系统被证明可以有效地减轻信息过载问题,基于协同过滤(collaborative filtering,CF)的推荐已经应用于互联网上的许多领域[1-3]。传统的协同过滤中通常使用评分数据等显示反馈分析用户偏好,至今为止,许多研究人员从各方面对基于评分预测的协同过滤推荐进行了深入研究,取得了一些显著成果。但是评分数据这种显示反馈更多情况下很难收集,大多数反馈都不是明确的,隐式反馈更常见,也更易于获得。在实际应用中,传统的协同过滤推荐在显示反馈数据缺失的情况下,不能进行有效推荐。同时,在新用户加入的情况下,协同过滤也存在冷启动问题。本文针对上述两个问题,提出了一种基于隐式反馈的相似度计算和用户推荐方法,该方法使用隐式反馈行为数据计算用户行为相似度,同时,引入用户属性信息计算用户属性相似度,然后融合用户属性和行为综合度量用户相似性,解决了传统协同过滤算法存在的一些问题。在真实数据集上的实验结果表明,本文方法在用户推荐具有一定的准确度和有效性,并且冷启动条件下,也具有较好的推荐效果。
1 相关研究
推荐算法作为一门热门研究学科,发展至今已经有了非常成功的应用,例如电影[4,5]、社交网络[6]以及其它方面[7]。常见的推荐算法包括基于内容推荐、协同过滤和混合推荐。
基于内容推荐分析用户评价对象的特征,然后学习用户的兴趣模型。协同过滤(CF)在推荐系统中起着重要作用,是最成功的推荐方法之一。协同过滤推荐与目标用户最相似的用户所偏好的信息。混合推荐方法提供了两种方法的组合,并利用了每种方法的优点。协同过滤算法分为两种不同类别,即基于内存的CF和基于模型的CF。基于内存的CF可分为基于用户的CF[8,9]和基于项目的CF[10,11],在基于用户的CF中,分析用户的相似性进行预测,可以认为,用户可能会购买与他相似的用户购买过的物品。在基于项目的CF中,分析项目之间的相似性以进行预测,一般认为,用户很可能会购买类似于他过去购买的物品。基于模型的CF方法中,使用数据集以生成学习模型。本文研究的重点是基于用户的CF方法。
传统的协同过滤通常使用显示反馈数据进行推荐,然而,实际应用中,这种显示反馈数据通常难以收集,而隐式反馈数据更容易获取。关于隐式反馈的协同过滤也被称为单类协同过滤(one-class collaborative filtering,OCCF),与没有数据评分的传统CF相比,OCCF在许多情况下适用性更高。文献[12]提出了一种UOCCF方法,该方法基于CLiMF(collaborative less-is-more filtering)和概率矩阵分解(probabilistic matrix factorization,PMF),具有低复杂度、高精度和良好的可扩展性的优势。文献[13,14]通过利用隐式反馈来解决协同过滤的数据稀疏性问题。文献[15]提出了一个仅使用隐式反馈数据的数字内容推荐框架,其不仅考虑用户和内容之间的交互,还考虑在期间可用的各种其它隐含信息。文献[16]利用预定义相似性和学习相似性的互补性,提出了一种具有隐式反馈的混合相似性推荐方法。
2 本文算法
传统的相似性度量方法主要依据评分数据,通过评分数据计算相似性。在显示反馈的评分数据缺失的情况下,利用隐式反馈数据计算相似性是可行的。此外,新用户加入没有反馈数据,即冷启动的情况下,引入其它用户信息是一种有效的方法。本文引入用户信息和隐式反馈,提出了一种相似度计算方法。
本文提出的方法从用户属性和用户行为两个方面计算用户相似度,主要贡献在于:①利用用户隐式反馈计算行为相似度,使用隐式反馈替代缺失的显示反馈数据,解决了协同过滤在显式反馈数据缺失的情况下不能有效推荐的问题。②引入用户个人信息计算属性相似度,并融合用户属性和行为相似度,解决了协同过滤推荐的用户冷启动问题。本文提出的算法模型如图1所示。
2.1 相似性度量
2.1.1 用户属性相似度
用户属性相似度依据用户属性特征矩阵计算得出,每位用户属性特征使用Attr=(a1,a2,…,ak) 表示,其中,ai为用户的第i个属性值,k为属性总数。本节用户属性值均设定为分类属性,年龄等数值属性则按一定范围划分转换为分类属性。对于两个用户u和v,若属性值ai相同,则认为simAttr(u,v,i)=1, 否则,认为simAttr(u,v,i)=0。 两个用户之间属性相似度计算定义如式(1)所示
(1)

2.1.2 用户行为相似度
用户行为相似度依据用户行为特征矩阵计算得出,每位用户行为特征使用Act=(b1,b2,…,bl) 表示,其中,bi为用户产生的第i类行为的数量,l为行为类型总数。对于两个用户u和v,如果行为数量bi相近,则表明二者某种程度上相似,一般数值差距越小,二者越相似。本文使用sigmoid函数表明这种非线性变换,两个用户在类型为i的行为下的相似度定义如式(2)所示
(2)
其中,rui和rv i分别表示用户u和v产生的第i类行为的数量,系数2是归一化。
用户行为相似度是所有行为类型依据式(2)所得相似度的均值,两个用户之间行为相似性定义如式(3)所示
(3)
其中,l为用户行为类型总数。
2.1.3 用户融合相似度
本节定义上文两种用户相似度融合后的相似度为用户融合相似度。融合相似度具有更高的可靠性和准确度。两种相似度融合基于假设:新用户加入时,没有行为数据,用户行为相似度计算结果为零,融合相似性仅利用属性相似度;当用户行为逐渐增多,用户行为相似度准确度逐渐增高,融合相似性更多利用行为相似度。使用sigmoid型函数实现这种平滑过渡,用户融合相似度定义如式(4)所示

(4)

2.2 预 测
本文预测燃气系统中用户使用的访问方式,用户访问方式使用向量Way=(w1,w2,…,wm) 表示,其中,wi表示用户是否使用方式i访问,m为访问方式的总数。根据用户信息和隐式反馈行为数据,计算用户融合相似度,然后使用K近邻方法计算预测值。用户访问方式的预测值计算如式(5)所示
(5)

本文算法具体描述见算法1所示。
算法1: 本文算法
输入: 用户数n, 属性特征矩阵Attrn×k, 行为特征矩阵Actn×l, 访问方式矩阵Wayn×m;
输出: 访问方式预测矩阵Pren×m;
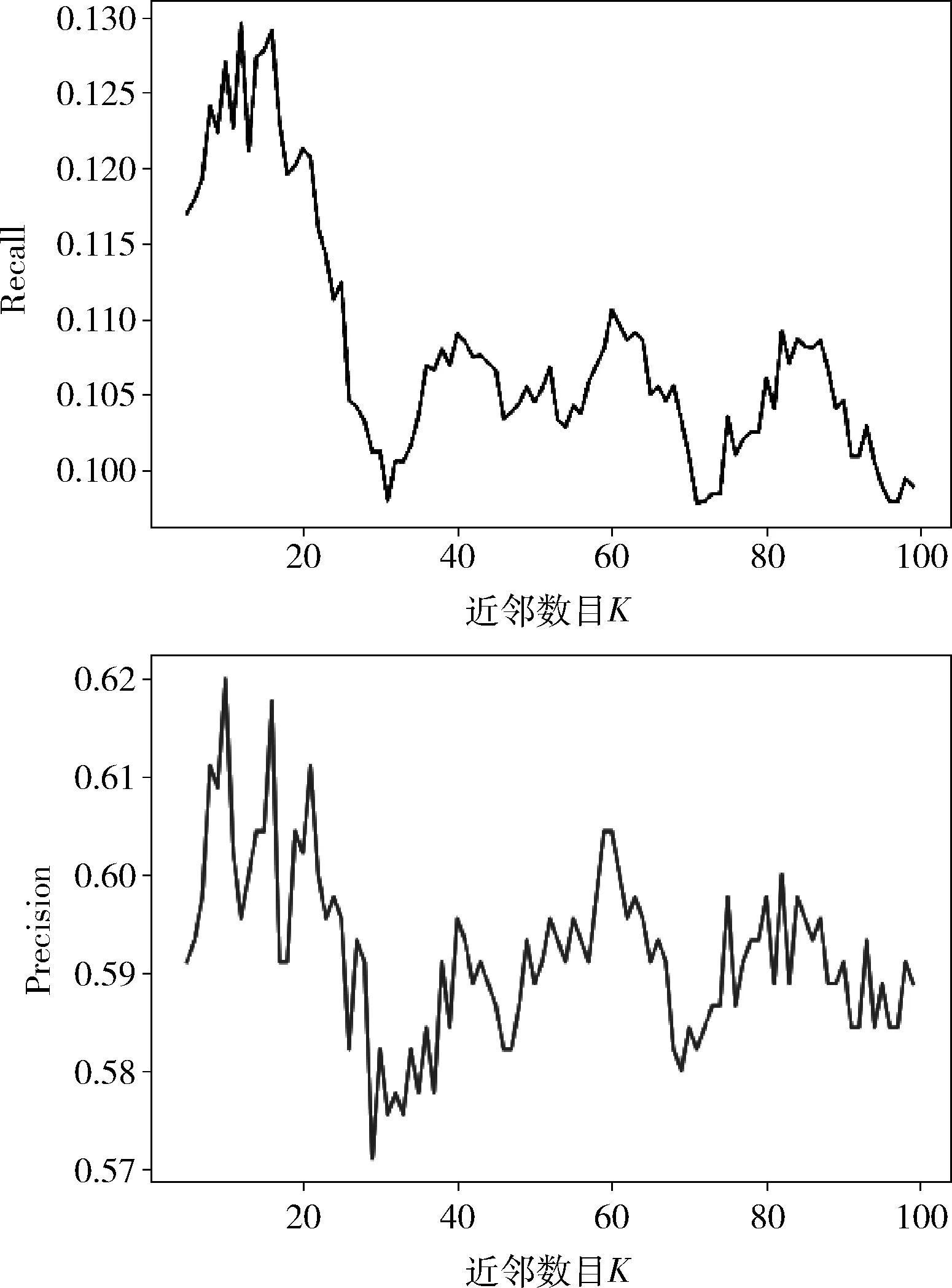
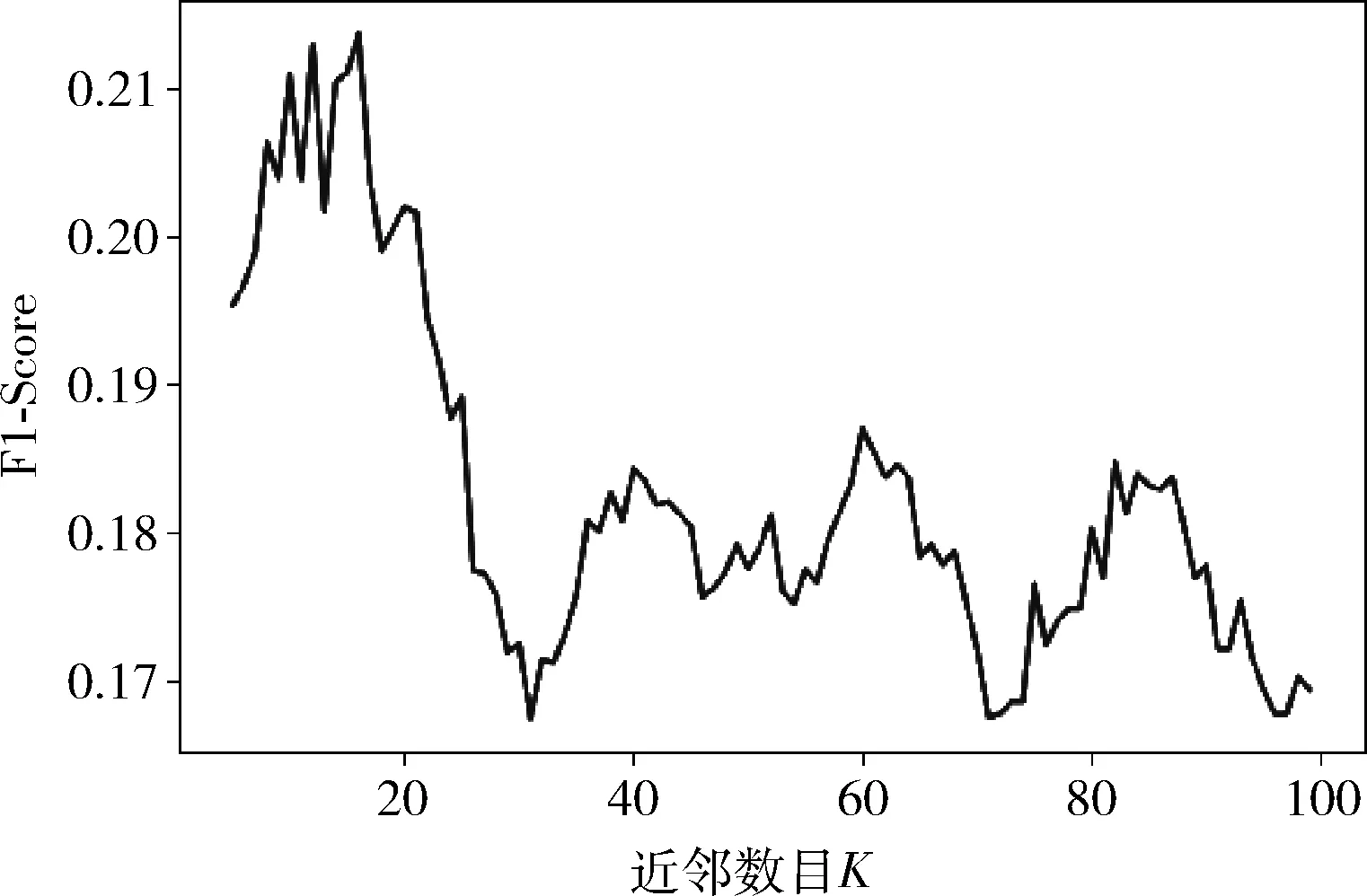
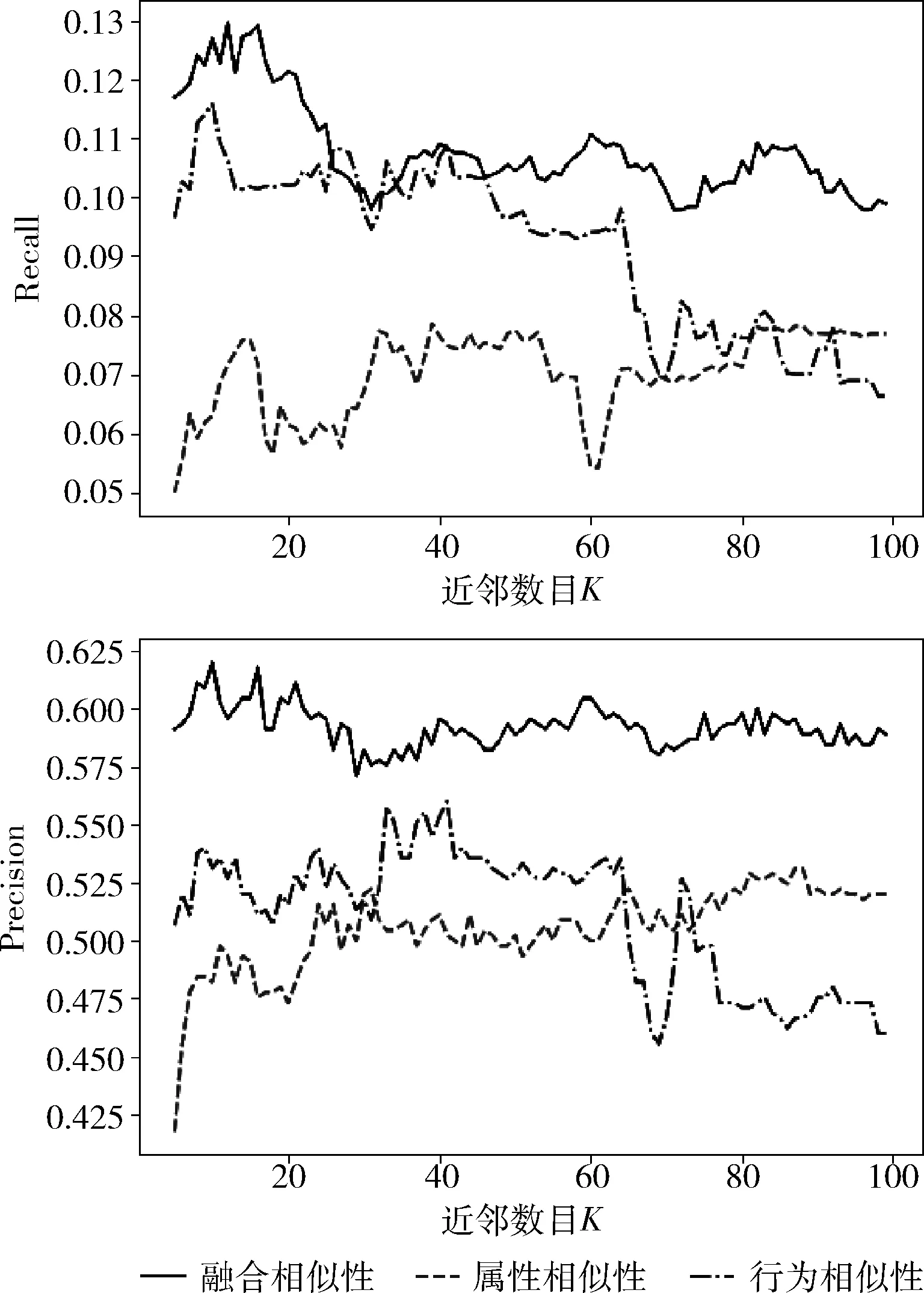
(2)fori= 0;i (3) forj= 0;j (7) end for (8)end for (9)fori= 0;i (10) //计算预测值,NK为K近邻集合 (11)end for (12)fori= 0;i (13) //计算评价指标recall和precise (14) 计算recalli和precisioni; (15)end for (16) //计算评价指标平均值 本实验数据集选取自上海燃气集团2015年7月值2018年11月期间注册的部分用户个人信息和他们在这期间的历史行为记录,其中,包括4394名用户和60 130条行为记录。本实验算法使用Python语言编写,系统平台为Windows10系统。 评价推荐系统推荐质量的度量标准主要包括预测评分和TopN推荐两类,本文使用TopN推荐的精准率(Precision)和召回率(Recall)作为度量标准,同时,使用F1-Score同时兼顾准确率和召回率。 用户属性相似性的权重分配见表1,权重使用层次分析法计算得出,层次判别矩阵见表2。 表1 权重分配设置 表2 计算权重的判别矩阵 3.4.1 TopN推荐 本实验对算法进行仿真实验,实验过程中,用户推荐列表长度N=150,用户相似度计算的最近邻数目K在5到100之间。实验结果如图2和图3所示。 图2 推荐结果评价指标召回率和准确率 图3 推荐结果评价指标F1-Score 从图2和图3中可以看出,当最近邻数目K小于20时,推荐结果具有较高的准确率和召回率,同时F1-Score具有较高值,当K=16时推荐结果的F1-Score有最高值,同时召回率和准确率都具有较高的数值。而当K大于20后,推荐结果准确率和召回率均明显下降,F1-Score有相同下降趋势。因此,实验选择K=16为最佳最近邻数目。 3.4.2 不同相似性比较 本文算法中用户相似性是用户属性相似性和行为相似性融合得到的相似性计算结果,为了对比两种相似性融合得到的融合相似性对推荐结果对召回率和准确率的提高,本实验分别使用属性相似性、行为相似性和融合相似性推荐潜在的用户列表,实验结果的评价指标召回率和准确率如图4所示。 图4 不同相似性度量方法推荐结果对比 从图4中可以看出,当最近邻数目K小于20时,使用融合相似性的推荐结果准确率和召回率明显比只使用属性相似性和行为相似性更高。当K在20到40范围内,行为相似性推荐结果召回率出现稍高于融合相似性的情况,而准确率仍然是融合相似性更高。当K大于40时,融合相似性保持具有更高的准确率和召回率。另外,在最佳配置条件下(K=16),融合相似性对比属性相似性,召回率提升了68.4%,准确率提升了23.0%,而融合相似性对比行为相似性,召回率提升了25.5%,准确率提升了16.2%。实验结果表明,本文算法具有一定的有效性和准确性,而且使用融合相似性推荐结果更准确。 3.4.3 算法在冷启动条件下的表现 本实验测试本文算法在用户冷启动情况下的表现,从数据集中随机抽取300名用户,模拟新用户加入,冷启动情况下,用户访问方式的预测值使用平均值。实验结果召回率和准确率如图5所示。从图5可以看出,新用户加入时,融合相似性方法使用属性相似性可以得到有效推荐,本文算法一定程度上解决了冷启动问题。 图5 冷启动条件下推荐结果召回率和准确率 本文提出了一种用户相似度计算方法,利用了用户属性信息和隐式反馈行为数据,从用户属性和行为两个方面计算用户相似度,然后融合两种相似度综合度量用户相似性,解决了用户推荐中显式反馈数据缺失的问题,同时一定程度克服了协同过滤的冷启动问题。本文算法适用于具有用户信息和隐式反馈行为记录的协同过滤推荐。实验结果表明,上述方法对推荐结果具有一定准确性和有效性,并且,使用融合相似度对于用户相似度计算更加准确,推荐结果更精准,在冷启动情况下仍能够有效推荐。实验不足之处在于相似度计算过程中,行为相似度只根据用户行为数量计算,没有更充分挖掘用户行为隐藏的信息,需要进一步改进。
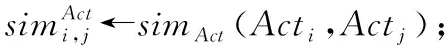
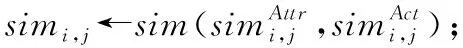
3 实验结果与分析
3.1 数据集和平台
3.2 评价标准
3.3 实验设置


3.4 实验结果

4 结束语
