跳读是基于副中央凹词的部分加工还是完全加工? *
2020-07-20张慢慢张志超臧传丽
张慢慢 张志超 臧传丽
(1 教育部人文社会科学重点研究基地天津师范大学心理与行为研究院,天津 300387) (2 天津师范大学心理学部,天津300387) (3 学生心理发展与学习天津市高校社会科学实验室,天津 300387)
1 引言
在阅读过程中,读者不会从头到尾注视每一个字或词,有些字或词直接被跳过,并没有被注视,即词跳读(word skipping)(白学军, 刘丽萍,闫国利, 2008)。在拼音类文字阅读(如英文)中,约三分之一的词会被跳读(Rayner, 1998),研究显示,对目标词的跳读会随着词长变短(Rayner, Slattery, Drieghe, & Liversedge, 2011)或词频增加(Rayner & Fischer, 1996)或语境预测性增大(Balota, Pollatsek, & Rayner, 1985)而增多。跳读受起跳位置(launch site, 即跳向一个词前的最后一次注视位置与该词的距离)的影响也很大,起跳位置越近,跳读率越高(Brysbaert & Vitu, 1998;Drieghe, Rayner, & Pollatsek, 2005)。中文阅读过程中词跳读现象也非常普遍,例如单字词的跳读率在40%~50%之间,双字词的跳读率为14%左右,三字词的跳读率只有4%左右(白学军, 曹玉肖, 顾俊娟, 郭志英, 闫国利, 2011; Zang, Fu, Bai, Yan,& Liversedge, 2018),主要影响因素有笔画数、词长、词频和预测性等(Liversedge et al., 2014;Rayner, Li, Juhasz, & Yan, 2005; Zang, Fu et al.,2018)。研究表明,绝大多数被跳读的词都是通过副中央凹预视或者语境信息提前获得了某种程度的加工(Zang, Zhang et al., 2018)。
那么,副中央凹词加工到何种程度会引起跳读?对该问题的解释主要源于两种理论。一种是序列注意模型(sequential attention shift, SAS)中的代表—E-Z读者模型(Drieghe, 2008; Rayner,Ashby, Pollatsek, & Reichle, 2004; Reichle, 2011;Reichle & Drieghe, 2013; Schotter, Reichle, & Rayner,2014)。该模型认为,词汇加工是严格按照序列方式进行的,每次只加工一个词。该模型对跳读的解释为:对当前注视词n完成熟悉度检验(L1)后,会触发对词n+1的第一次可变眼跳计划(M1),同时词n进入词汇通达(L2)。当词n的L2阶段完成后,注意会从词n转移到词n+1上,开始对词n+1进行熟悉度检验(眼睛仍在词n上),如果对词n+1的熟悉度检验足够快,而且眼跳程序仍然处于对词n+1的第一次可变眼跳计划中,此时就会撤销对词n+1的眼跳计划,重新制定对词n+2的眼跳计划,词n+1将被跳读。该模型认为只有副中央凹词n+1被完全识别或即将发生完全识别才会被跳读。
另一种是注意梯度指引模型(guidance by attentional gradient, GAG)中的代表—SWIFT模型(Drieghe, Desmet, & Brysbaert, 2007; Drieghe et al.,2005; Engbert & Kliegl, 2011),该模型认为注意是按空间梯度分布在若干词上的,词汇加工是平行的,读者可以同时加工若干个词。同时眼跳是自发产生的,激活程度最大的词会成为下一次眼跳的目标(词的激活程度与加工难度有关)。该模型对跳读的解释为:在激活区域内,多个词同时竞争加工资源,加工困难的词会占用更多的注意资源,分配到其他词的注意资源就会变少。加工相对容易的词,激活程度就小,成为下一个眼跳目标的可能性越低,被跳读的可能性就越大。该模型认为即使副中央凹词n+1没有被完全识别,也会被跳读。
以上两种模型对跳读的争论主要集中在被跳读词的加工程度上,SWIFT模型认为词n+1即使没有达到E-Z读者模型假设的加工程度也会被跳读,比如词n+2的激活程度大时会增加词n+1被跳读的机会。对被跳读词的加工程度的考察也得到不同结论。Balota等(1985)使用边界范式(该范式由Rayner在1975年提出,即在目标词左边设置一个隐形边界,当注视点在该隐形边界之前时,目标位置呈现可操纵的预视内容;当注视点越过该隐形边界时,预视内容被目标词取代)考察了预测性与副中央凹视觉信息对跳读的影响。实验中设置高预测词(cake)和低预测词(pies)两种类型的目标词,根据目标词设置五种预视类型:一致预视(cake-cake, pies-pies)、词形相似的非词预视(cake-cahc, pies-picz)、语义相关真词预视(cake-pies, pies-cake)、词形不相似的非词预视(cake-picz, pies-cahc)、违背语境的无关真词预视(cake-bomb, pies-bomb)。其中高预测词(即可以通过前文语境直接推测出该词)对该词的加工是完全的,词形相似的非词只提供词的部分信息。结果显示,词形相似的非词预视和一致预视的跳读率没有差异,表明跳读是基于副中央凹词的部分加工。但是Drieghe等(2005)认为该实验材料中预视词的平均长度较长,而英文中长词相对于短词更不容易被跳读,导致整体跳读率偏低,会产生地板效应。基于此,该研究把实验中长度多于六个字母的词剔除,对高预测目标词设置了一致预视(liver)、低预测预视(heart)、语义违反的真词预视(files)、与高预测词形相似的非词预视(livor)、与高预测词形不相似的非词预视(heant)、正字法违背的非词预视(frhos)共六种预视条件。结果显示一致预视下对目标词的跳读比词形相似的非词预视更高,这表明词跳读是基于副中央凹词的完全加工。从以上两个研究可以看出,词长可能是拼音文字阅读中关于词跳读加工程度研究结果不一致的原因。
拼音文字中的单词长度分布不均匀,从1个字母长度到20多个字母长度不等(臧传丽, 鹿子佳, 白玉, 张慢慢, 2018),在视觉空间分布上有很大变异性,由于视敏度限制,副中央凹词的加工程度在很大程度上受单词空间分布的制约。与之相比,中文在考察词跳读时可以有效避免该问题。一方面,中文文本中字与字之间没有空格,所占的空间相同,而且在固定的单位空间内,每个汉字的字形和复杂性不同;另一方面,中文词长相对集中,常用双字词占72%,单字词占6%(臧传丽等, 2018; Li, Zang, Liversedge, &Pollatsek, 2015)。这些特征使得中文文本单位空间内的信息密度更大,读者在有限的空间内可能会获得更多信息,对副中央凹词可能有更多的预加工(王穗苹, 佟秀红, 杨锦绵, 冷英, 2009)。那么,在视觉空间分布相对集中、信息较密集的中文文本中,词跳读到底是基于副中央凹词的部分加工还是完全加工?本研究将以中文文本为考察对象,在良好控制词空间分布的前提下,以单字词作为预视目标,通过使用边界范式来操纵预视程度:高预测预视、低预测预视、与高预测词正字法相似预视、与高预测词正字法不相似预视。其中,正字法不相似预视条件为控制条件,没有提供任何有效预视信息;正字法相似预视条件只提供目标词的正字法信息(部分加工);高预测预视则提供了目标词的全部信息(完全加工)。研究假设,根据SWIFT模型观点,如果词跳读基于部分加工,那么正字法相似预视与高预测预视在跳读率上没有显著差异,且正字法相似预视的跳读率显著高于正字法不相似预视;根据E-Z读者模型观点,如果词跳读是基于副中央凹词的完全加工,那么高预测预视的跳读率显著高于正字法相似预视,且正字法相似预视的跳读率与正字法不相似预视没有显著差异。
2 方法
2.1 被试
天津师范大学82名在校学生(13名男生)参加了实验,平均年龄22±2岁。所有被试的母语为汉语,且没有阅读障碍。被试的视力或者矫正后的视力正常,参加实验前均不知道本次实验的目的。实验后每人获得一定报酬。
2.2 实验设计
通过操纵目标词的预视类型,形成单因素四水平(高预测性预视、低预测性预视、与目标词正字法相似假字预视、与目标词正字法不相似假字预视)的被试内实验设计。
2.3 实验材料
从基于电影对白编制的汉语字词语料库(Cai &Byrsbert, 2010)中选取36对词(均为单字词,且词性为名词)分别编入相同的句子框架中形成高预测-低预测词对。句子的平均长度为19字,高预测性词的词频为25.88±21.10次/百万,低预测性词的词频为25.34±20.05次/百万,二者没有显著差异,t(35)=0.32,p>0.05。使用Windows 10系统中专用字符编辑程序分别创造出36个与目标词正字法相似的假字以及不相似的假字。本研究参考了Drieghe等(2005)的做法(变换目标词的倒数第二个字母来实现对正字法相似预视的操纵,正字法相似程度约为79%),通过变化1~2笔画来实现对正字法相似预视(相似程度为88%)的操纵,其中有15个字通过增笔画、13个字通过减笔画、8个字保持笔画数不变来实现。四种预视条件的笔画数没有显著差异,F(3, 140)=0.06,p>0.05。实验中使用边界范式呈现四种预视,当注视点越过边界时,预视词被目标词替代,具体示例如图1。
请50名天津师范大学在校学生对含有高、低预测性词的句子进行通顺性评定。选用5点等级评定量表,“1”代表“非常不通顺”,“5”代表“非常通顺”。高预测预视的通顺性(M=3.76,SD=0.43)与低预测预视的通顺性(M=3.69,SD=0.39)没有显著差异,t(35)=1.14,p>0.05。
另请20名天津师范大学在校学生对目标词的预测性进行评定,让被试根据句子前半部分信息来填补后面的内容,结果显示高预测词被猜中的概率大于或等于50%(M=69.66%,SD=14.52%),低预测词被猜中的概率小于6%(M=0.29%,SD=1.22%),高预测预视的预测性显著比低预测预视高,t(35)=28.14,p<0.001。
2.4 实验仪器
采用加拿大SR公司生产的EyeLink1000塔式眼动仪记录被试的眼动轨迹,该仪器的采样率为1000 Hz,实验材料以25号宋体呈现在电脑显示器上,显示器的刷新率为150 HZ,分辨率为1024×768像素,被试距离屏幕约为65 cm,每个字的视角约为 1.1°。
2.5 实验程序
每个被试都是单独施测,首先在被试机前调整到最舒服的坐姿,把下巴放在眼动仪的下巴托上。实验开始前让被试理解显示屏上的指导语,然后对眼睛进行三点校准。为保证被试理解实验过程,正式实验之前有8个练习句,其中有4句设置“是”或“否”判断题。正式实验中除实验句,还有24句填充句,同时设置20个判断题来确定被试是否认真阅读句子,所有句子均随机呈现。整个实验大约持续20分钟。
3 结果
被试阅读理解的平均正确率为96%(SD=4%),表明被试整体上很好地理解句子的意思(其中3名被试的数据因正确率较低被剔除)。首先删除短于80 ms或长于1200 ms的注视点。再根据以下标准(王永胜等, 2018; Zhang, Liversedge, Bai, Yan, &Zang, 2019)筛选句子:(1)删除总注视点少于3个的句子;(2)删除由于一些偶然因素(被试眨眼、头动等因素)导致追踪记录有问题的句子;(3)删除注视时间超过3个标准差之外的数据;(4)删除边界变化或注视目标词时眨眼的数据,以及边界变化延迟的数据。最终删除的数据占总数据的9.51%。
分析指标包括首次注视时间、单次注视时间、凝视时间、总注视时间以及跳读率(闫国利等, 2013)。在R语言环境下,使用R Studio(R Core Team, 2018)中的线性混合模型(Bates,Mächler, Bolke, & Walker, 2015)对眼动数据进行分析。其中,预视类型为固定因素,被试和项目为交叉随机因素。根据马尔可夫链蒙特卡罗算法(Markov-Chain Monte Carlo)得出事后分布的模型参数作为显著性的估计值(b),能同时反映来自被试和项目中的变异(Baayen, Davidson, & Bates,2008)。在运行模型时,对注视时间指标进行log转换,对跳读数据直接进行logistic LMM分析。
3.1 目标词分析
以目标词为兴趣区,对目标词的眼动指标进行分析(见表1)。在跳读率上,高预测与低预测预视条件之间没有显著差异(b=0.14,SE=0.14,z=1.00,p=0.319);正字法相似预视条件下的跳读率显著高于高预测预视条件(b=0.47,SE=0.15,z=3.21,p=0.001);正字相似预视条件下的跳读率显著高于正字法不相似预视条件(b=0.63,SE=0.14,z=4.53,p<0.001),说明副中央凹正字法信息影响读者对词跳读的决定。
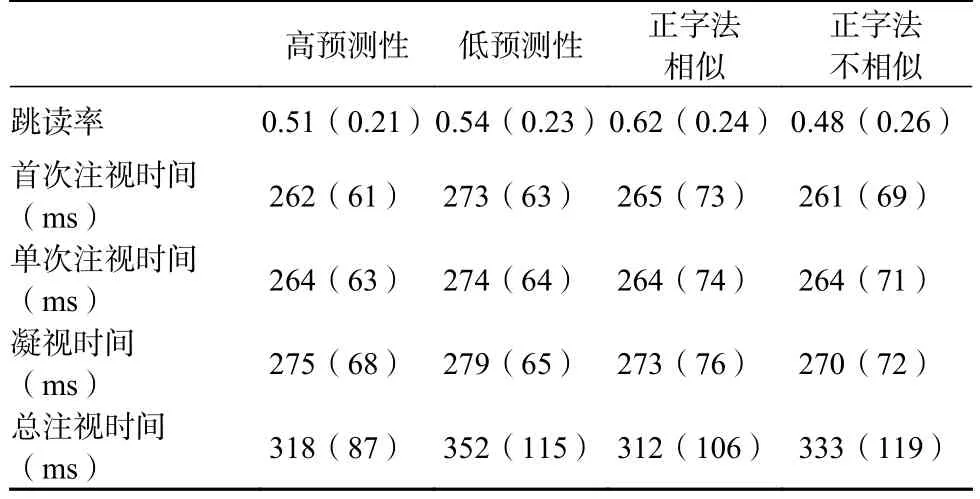
表1 不同预视条件下目标词的平均跳读率和注视时间
尽管本实验主要关注跳读率上的效应,但对目标词上的注视时间分析可以了解不同预视类型对副中央凹信息加工的影响。结果显示,在首次注视时间、单次注视时间和凝视时间上,高预测与低预测预视之间没有差异(|t|s<0.87,ps>0.05),但是低预测预视下的总注视时间显著长于高预测预视(b=0.09,SE=0.04,t=2.22,p=0.027)。在所有时间指标上,正字法相似预视与高预测预视以及正字法不相似预视与高预测预视均没有显著差异(|t|s<0.89,ps>0.05),正字法相似与正字法不相似条件也没有显著差异(|t|s<1.29,ps>0.05)。
3.2 起跳位置对目标词跳读的影响
Brysbaert和Vitu(1998)研究发现跳读与起跳位置有密切的关系。为更明确起跳位置对跳读的影响,按照中位数(1.28字)把起跳位置分成远(M=2.49,SD=1.21)和近(M=0.67,SD=0.36)两个类别再进行分析(结果见表2)。结果显示起跳位置近时对目标词的跳读率显著高于起跳位置远的情况(b=1.46,SE=0.11,z=13.71,p<0.001)。起跳位置与预视类型(高预测vs.正字法相似)之间有边缘显著交互作用(b=0.48,SE=0.27,z=1.84,p=0.066),然而贝叶斯分析结果并不支持该交互作用。也没有发现其他预视类型与起跳位置的交互作用(|z|s<1.47,ps>0.05)。
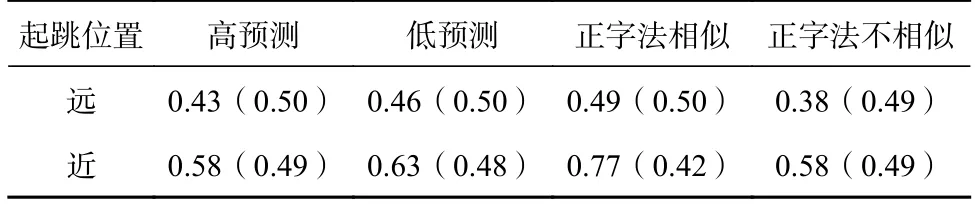
表2 不同预视条件下起跳位置远和近时的跳读率
4 讨论
本研究考察中文阅读中词跳读是基于副中央凹信息的完全加工还是部分加工。结果显示正字法相似预视下对目标词的跳读率显著高于正字法不相似预视,且不受起跳位置的影响。以往研究采用边界范式在时间指标上稳定地发现了预视效应(白学军, 刘娟等, 2011; Schotter, Angele, &Rayner, 2012),而本研究却没有在时间指标上发现该效应。由于本研究关注词跳读问题,选用单字词以期获得充足的跳读数据,然而注视和跳读是一种权衡关系(trade-off),对目标词跳读越多则意味着获得注视越少。结果确实发现单字词的跳读率非常高,平均为0.54,导致时间指标上的数据相对较少,这可能是没有发现典型预视效应的原因。事后分析发现,在首次注视时间上的统计检验力为0.13,单次注视时间上的统计检验力为0.28,凝视时间上的统计检验力为0.20,总注视时间上的统计检验力为0.65。在跳读率上典型预视效应的统计检验力接近1.00。这表明,在跳读率上的统计检验力足够强(统计检验力不低于0.8表示足够,小于0.8表示不足),结果非常可靠;但同时也意味着在注视时间指标上没有发现典型的预视效应极可能是由统计检验力不够所造成的。
本研究发现正字法相似预视下对目标词的跳读率显著大于正字法不相似预视,而Drieghe等(2005)发现正字法相似预视与正字法不相似预视在跳读率上没有差异。这种差异可能由中文文本与拼音文字的书写特性不同所致。与拼音文字相比,中文文本之间没有空格,视觉信息空间分布相对集中和密集,中文读者可以提取更多的副中央凹信息(王穗苹等, 2009)。本研究中正字法相似预视与目标词的相似程度很高,意味着中文读者可以提取到更多正字法信息,进而造成读者对相似预视的跳读高于不相似预视。结合假设,如果词跳读是基于副中央凹信息的完全加工,那么高预测预视的跳读率显著高于正字法相似预视;如果词跳读基于部分加工,则二者没有差异。但出乎意料的是,本研究发现正字法相似预视下的跳读率显著高于高预测预视,这表明被试并没有根据完全的词汇识别进行跳读。本研究试图寻找可能的影响因素,比如起跳位置,尽管正字法相似与高预测以及正字法相似与正字法不相似下的跳读率差异在起跳位置近时有大于起跳位置远的趋势,但是并没有达到统计学上的显著,即起跳位置没有显著调节副中央凹预视对跳读的影响。造成该结果的原因目前还不清楚,但至少该结果说明相似的正字法信息足够引起读者跳读,否则相似预视下对目标词的跳读不会高于不相似预视。以后还需要更进一步的研究来验证。
另外,实验还假设,如果高预测预视下的跳读率显著高于低预测预视,则说明预测性在副中央凹信息加工中发挥了作用,读者可以利用语境信息在副中央凹中完全识别该词。然而结果没有发现高预测与低预测在跳读率上有显著差异,这与Rayner等(2005)的研究结果不同。原因可能是,该研究的材料是中文双字词,而本研究中使用的是中文单字词,单字词的跳读率很高(Liversedge et al., 2014),在本研究中,高、低预测预视条件下的跳读率达到50%以上,且当起跳位置近时,高预测和低预测的跳读率达到60%左右。如此高的跳读率,可能造成了天花板效应,导致高、低预测预视条件下的跳读率差异不明显。但高预测条件下的总注视时间显著低于低预测条件,这说明预测性在词汇加工晚期阶段比较明显。
拼音文字阅读研究显示,词长可能是导致词跳读问题研究结论不同的原因,本研究对副中央凹预视的操纵限制在单字词空间内,避免了词长可能带来的影响,结果显示正字法相似的跳读率显著高于正字法不相似,这在一定程度上符合SWIFT模型对词跳读的解释(Engbert & Kliegl, 2011)。根据SWIFT模型,在知觉广度里的词可以同时被加工,词的激活程度是一个动态过程:先上升,达到峰值,再下降;激活程度与词的加工难度有关:容易加工的词,其激活程度较低;难度最大的词,其激活程度最大,更容易成为下一个眼跳目标(Drieghe et al., 2005)。相对于正字法不相似预视,正字法相似预视加工更容易,其激活程度相对较低,被跳读的概率更高。根据E-Z读者模型,只有对词n+1完成了词汇通达,达到完全加工,才会取消对词n+1的眼跳计划,即对词n+1产生了跳读(Reichle & Drieghe, 2013)。按此推测,相似预视下对目标词的跳读率应低于高预测预视,且相似预视与不相似预视下的跳读率没有差异。然而,本研究发现相似预视下对目标词的跳读率并没有低于高预测预视,且相似预视下的跳读率高于不相似预视,该结果不支持E-Z读者模型的观点。
Drieghe等(2005)在操纵正字法相似预视时,只改变了高预测词中的一个字母却导致了比高预测条件更低的跳读率。而本研究通过类似的操纵,即在汉字笔画数整体上增加或减少1~2画或只对笔画进行变化(不增加也不减少笔画数),却没有发现相似的结果。本研究认为,正字法相似预视提供的正字法信息导致了部分加工,实验结果也发现正字法相似预视的跳读率显著高于正字法不相似预视,从理论上而言,该结果支持部分加工的观点。然而,目前还不能直接做出定论。根据Yan等(2012)关于省笔画对中文句子阅读的研究,省略15%笔画数的汉字与正常汉字有着一样的平均阅读时间,这意味着删除一定量的笔画数不影响整体阅读。而且,中文的表意特性使得中文读者对汉字的识别可以从形直接激活义(陈宝国, 王立新, 彭聃龄, 2003)。而本研究中对正字法相似预视的操纵使笔画数的增加量、减少量或变化量约占目标词笔画数的11.83%。从这一角度来看,本研究中的正字法相似预视被读者加工的程度可能会接近或等同于目标字,即接近完全加工的程度,从而导致正字法相似预视的跳读率显著高于正字法不相似预视。未来研究需要更细致地操纵副中央凹信息类型以区别不同类型信息的加工程度,进一步探讨中文跳读是基于副中央凹词的部分还是完全识别。
5 结论
在本实验条件下得出以下结论:在中文阅读中,从副中央凹提取的正字法信息足够引起读者作出跳读的决定,在一定程度上支持词跳读是基于部分加工的观点。
