汉字亚词汇部件语音加工的P200效应 *
2020-07-20孔令跃
孔令跃 张 豹
(1 北京大学对外汉语教育学院,北京 100871) (2 广州大学教育学院心理学系,广州 510006)
1 引言
词汇识别是一个复杂过程,包括词汇水平和亚词汇水平上形、音、义等各种信息的激活与提取,其中亚词汇信息的作用机制、加工单位和激活时序等都是阅读研究领域内的重要问题。大量拼音语言的行为研究发现亚词汇信息如音节、字母位置等在词汇通达中起到重要作用(Grainger &Jacobs, 1993; Perea & Carreiras, 1998)。近年来,越来越多的研究者利用ERP技术高时间分辨率的优势对亚词汇加工的时间进程进行了探索,确定了几个与之相关的ERP成分,如早期成分P150、P200、N250及晚期成分N400(Carreiras, Gillon-Dowens, Vergara, & Perea, 2009; Dien, 2009; Savill &Thierry, 2012),认为这些ERP成分反映了从词汇视觉特征分析,到亚词汇水平的正字法表征(如字母和音节),再到整体词形或者语义表征这一系列单词的识别历程(Holcomb & Grainger,2006)。其中P150和P200总体上反映了亚词汇正字法信息的总体激活情况,前者可能反映了单词亚词汇成分的激活和视觉特征的最初加工,后者对形似词的数量非常敏感,可能反映了亚词汇水平上正字法的加工。这些研究结果加深了人们对亚词汇信息及其作用的认识并推动了词汇识别模型的构建和完善。
但是,目前研究者对早期成分P200所反映的词汇加工过程仍有争议(谢敏, 杨青青, 王权红, 2016)。P200是ERP的一个内源性成分,起始于150 ms,于200 ms达到顶峰,在275 ms结束,主要分布在额中部和顶枕叶(Kong, Zhang, Zhang, & Kang,2012; Kong et al., 2010; Liu, Perfetti, & Hart, 2003)。有些研究发现P200成分既与拼音文字的词形加工有关,也与其语音加工有关(Kramer & Donchin,1987; Misra & Holcomb, 2003; Rugg, 1987),但这些结果未能得到另一些研究的重复(Be nt in,Mouchetant-Rostaing, Giard, Echallier, & Pernier, 1999;Kutas & van Petten, 1994; Ziegler, Benraïss, & Besson,1999)。这些相互矛盾的研究结果可能与拼音文字系统的特性有关,也可能与研究者所操控的实验任务有关,但总体来说这反映了拼音文字词汇加工中,P200成分与字形和语音加工的联系并不稳定。
与拼音文字相比,汉字书写系统有一些显著的独特特征。首先,汉字是基本的书写单元,对应口语中的一个音节,而不是一个音素。因为汉语中没有对应于音素的解码单元,所以在汉语中没有形音对应规则(grapheme to phoneme correspondence)。其次,汉字由部件组成,而且这些部件自身可以单独成字,现代汉语中约80%以上的汉字都属于形声字(李燕, 康加深,1993)。形声字由功能上不同的声旁和义旁组成,义旁为整字提供语义线索,声旁通常为整字提供发音线索,但声旁的总体表音度为66.04%(陈原,1993),而且绝大部分声旁或者一部分义旁本身就是一个字,有其自身的发音和意义。
大量行为研究发现汉字的以上特性影响着汉字识别。比如,汉字识别中存在着发音规则性和一致性、部件位置、部件频率、形旁家族和声旁家族等效应,表明汉字亚词汇水平上的声旁和义旁的语音、位置、频率和家族大小等信息会在汉字识别早期影响词汇水平的加工(毕鸿燕, 胡伟, 翁旭初, 2006; 陈新葵, 张积家, 2012; 韩布新, 1998;Ding, Peng, & Taft, 2004; )。近期的ERP研究为上述行为结果提供了进一步的认知神经学证据(Hsu,Tsai, Lee, & Tzeng, 2009; Wu, Mo, Tsang, & Chen,2012; Yum, Law, Su, Lau, & Mo, 2014; Zhou, Fong,Minett, Peng, & Wang, 2014)。另外,ERP研究也发现了稳定地反映汉字词汇水平的形音加工的N170和P200,其中P200成分被视为汉字早期词汇水平形音加工的指标(Kong et al., 2010, 2012; Liu et al., 2003; Zhang, Zhang, & Kong, 2009)。
然而,早期成分P200与汉字亚词汇部件形音信息加工的关系还不清楚。这方面的研究不多且结果并不一致。对汉字亚词汇部件形音信息的加工可从多个角度进行考察。比如,语音的规则性,即亚词汇部件语音与整字语音是否一致;或者语音的一致性,即包含某一部件的所有汉字发音的异同程度。Hsu等(2009)考察了汉字一致性ERP效应变化,发现高一致性字比低一致性字产生更小的P200和更大的N400效应。该研究认为这可能是由于低一致性汉字的声旁激活了更多的包括这一声旁的汉字,导致早期词汇语音竞争更激烈,出现更大波幅的P200。据此提出两阶段汉字识别模型,认为P200和N400分别代表着汉字识别的早晚期两个加工阶段。其中P200反映了早期基于汉字声旁部件的形音交互加工的影响(Lee et al.,2007)。这一模型的解释主要着眼于声旁部件的正字法分析以及由该部件激活的多个词汇水平上的语音信息的竞争对P200效应的影响,而亚词汇部件自身的语音激活及其对P200效应变化的影响却不清楚。而且,模型关于语音竞争的解释仍然比较笼统,不能清楚地说明P200的产生机制的一些问题。比如,高一致性字有更多的相同语音激活,其语音激活在竞争中更强,但却产生减弱的P200效应。而且,低一致性字所在的同声旁家族中可能有很多相同读音的字,也可能该家族所有的字的读音都不同,这两种情况下的语音竞争有什么不同,产生的P200又是否一样?另一方面,Yum等(2014)严格控制了不同一致性条件下的规则和不规则字数量,同时考察汉字规则性和一致性的ERP效应,却发现一致性效应只出现在P200上,一致字比不一致字产生更大的P200效应。这一结果与Hsu等(2009)的结果完全相反。关于规则性,Yum等则发现规则字比不规则字诱发了更大的N170和N400,以及减弱的P200效应。这些分歧表明汉字亚词汇部件形音信息加工的脑机制及早期成分(如P200)的变化模式都还有待进一步的ERP研究来探讨。
除了规则性和一致性,汉字亚词汇部件的其它特征(如,部件可发音性)也可以用于探讨亚词汇语音信息加工的脑机制问题。简体汉字中,有很多汉字的部件(可能是声旁也可能是义旁)单独成字,可以按汉语拼音规则发音,但有很多不能单独成字,往往不发音(常称之为某种偏旁)。利用这一属性可从新的角度进一步考察汉字亚词汇部件语音加工的ERP效应模式。基于这一思路,本研究操控汉字部件的可发音性特征来探讨亚词汇语音加工与早期ERP成分P200的关系。关键实验材料为形似音异的合体字对,字对共享一个可发音或不可发音的部件(如,“吹-砍”、“扬-场”)。以往的研究表明形似字对能产生显著的P200效应(Kong et al., 2012; Liu et al.,2003)。如果亚词汇语音确实影响或调节着P200效应,则可以预期部件可发音和不可发音形似字对之间会出现P200效应差异。在规则性和一致性ERP研究数量少且存在分歧的情况下,部件发音与不发音形似字对是否存在P200效应差异这一结果将有助于进一步揭示亚词汇部件语音加工的ERP机制和特性,丰富和验证这方面的研究成果。
需要指出的是,以往考察亚词汇语音规则性和一致性的ERP研究主要使用命名和真假字判断任务,但是命名任务有可能会强化汉字的(尤其是部件)语音加工,使用真假字判断任务有可能会使被试更关注字的部件及其组合结构、强化部件的加工。对于探讨汉字亚词汇部件信息早期加工的实验来说,这两种任务都可能对被试加工和实验结果产生潜在不利影响。另一方面,大量研究证明,汉字识别过程中语音一定自动激活,即使实验任务不需要使用汉字的语音信息(Zhou &Marslen-Wilson, 2000)。因此,本研究使用以往研究中曾使用的语义一致性判断任务,让被试只对填充字对进行判断(Kong et al., 2010)。该任务中被试关注汉字的语义信息,避免了对汉字部件及其语音信息的有意关注,可以考察自动的汉字语音信息激活与加工,从而尽可能减少实验任务带来的潜在影响。而且使用该任务的ERP研究在汉字语音加工上有一致的发现,也表明了该任务在探测汉字语音加工上的有效性(Kong et al., 2010,2012; Zhou et al., 2014)。
2 实验
2.1 方法
2.1.1 被试
17名本科生(平均年龄为20.76岁,8名女生,9名男生)参加实验,视力或矫正视力正常,均为右利手,无相关实验经验。实验后获得一定报酬。
2.1.2 材料
所有实验用字选自常用的4574个字(北京语言学院语言教学研究所, 1986)。关键材料为部件发音和部件不发音高频字对。为了方便描述,每一字对中的第一个字称为启动字,第二个字称为目标字。所有字对均为形似音异字,启动字和目标字共享一个部件。部件发音和不发音字对各有35对,每对字对之间没有语义相关。实验中还包括24对形似音异但语义相关的字对(如, “瞅-瞧”)作为填充字对。每种条件下目标和启动字的笔画和字频都进行严格匹配,部件发音和不发音两种条件下材料的笔画和字频也完全匹配。所有目标字的部件家族大小都没有差异,都在2~15个之间,属于研究文献中界定的小家族(毕鸿燕等, 2006)。实验材料中可发音和不可发音字对目标字的一致性也严格匹配(0.25与0.26,p=0.832)。每个被试接受总共94对随机呈现的字对,见表1。
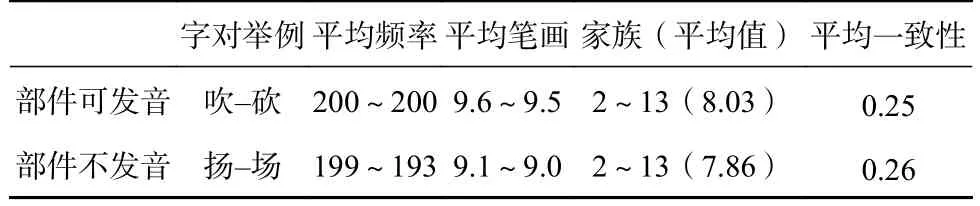
表1 实验字对信息
2.1.3 程序
实验在安静的独立单间内进行,被试坐在离屏幕约57 cm的位置。采用E-Prime1.0呈现刺激,收集和记录行为数据。实验流程图参见图1,每次测试开始时,首先在屏幕中央呈现一个“+”300 ms作为注视点,随之相继出现一个“启动字-目标字”字对,启动字140 ms,目标字呈现1500 ms,中间空屏360 ms后,要求被试看到目标字后,立即用右手食指又快又准地按空格键判断其与先前呈现的启动字是否语义相关,语义无关时无需按键,否则视为错误。反应完后目标字消失,进入下一测试。测试之间的时间间隔随机设置为1800、1900、2000、2100或2200 ms。实验过程中要求被试尽可能减少头动。正式实验之前先完成20个练习以熟悉实验程序和任务要求。
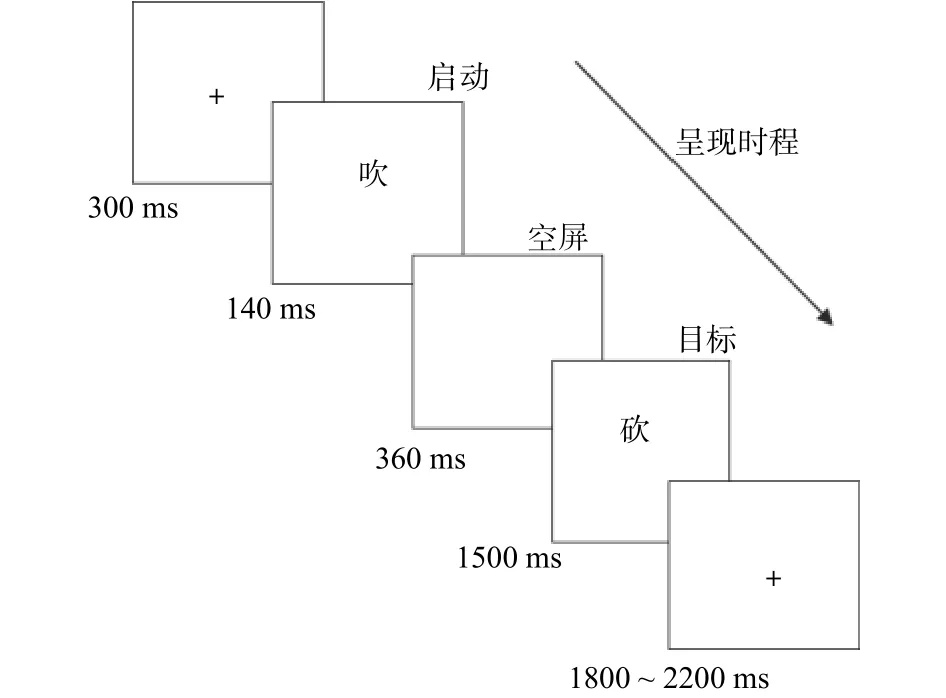
图1 实验刺激流程图
本研究实验设计为单因素(字对类型:部件发音、部件不发音)被试内实验设计。因变量为指定时窗的ERP平均波幅。
2.1.4 ERP记录
使用德国Brain Products公司的ERP记录与分析系统,按国际10-20系统扩展的64导电极帽记录EEG。接地点在Fpz和Fz连线的中点,垂直眼电(VEOG)通过放置于左眼上下1厘米处的一对电极进行记录。参考电极置于左右乳突,左乳突的电极作为在线参考电极,右侧乳突的电极作为离线参考电极。每个电极处的头皮电阻保持在5 kΩ以下,滤波带通为0.1~70 Hz,采样频率为500 Hz/导。
2.1.5 ERP数据分析
对连续记录的EEG进行离线迭加平均,分析窗口为目标字出现的-100~900 ms,用-100~0 ms作为基线进行矫正。自动校正VEOG,并将振幅超过75 μV的分段作为伪迹去除。只分析包含目标字且反应正确的测验的ERP数据,填充字对数据不纳入分析。图2为平均迭加后的ERP总平均波形图,可以看出,两种字对类型条件下都出现了显著的 N1(100~140 ms)、P200(180~300 ms)和N400(300~450 ms)。
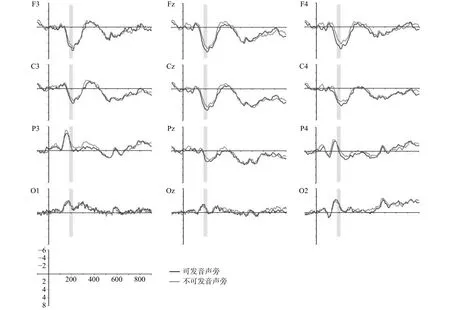
图2 部件发音与不发音条件下12个电极上目标字的平均ERP波
本研究主要关注P200,为了增加研究结果之间的可比性,数据分析时参照Kong等(2010)的研究,将P200分析时窗设定为目标字出现后180~210 ms,分析的电极包括Fz,F3,F4,Cz,C3,C4,Pz,P3,P4,Oz,O1,O2,分析指标为选定分析时窗ERP的平均波幅。所有的方差分析均使用Greenhouse-Geisser法进行较正。
2.2 行为结果
计算所有条件下的正确率发现填充字对的正确率为83.59%,部件可发音字对和部件不可发音字对的正确率分别为97.41%和96.12%。
2.3 ERP结果
2(字对类型)×12(电极)的重复测量方差分析结果发现:字对类型主效应显著,F(1,16)=12.18,p<0.005,η=0.43;部件发音字对的P200平均波幅显著大于部件不发音字对,电极位置主效应显著,F(11, 176)=14.34,p<0.001,η=0.47;两者交互作用边缘显著,F(11,176)=1.68,p=0.082,η=0.10。进一步的简单效应分析发现部件发音字对的P200波幅在额区、中央区及顶区的电极点上显著大于部件不发音字对(F3:p=0.070; P4:p=0.089; Fz, F4, Cz, C3, C4, P3, Pz:ps<0.05)。图3是两种条件差异波的脑地形图(可发音减去不可发音),表明亚词汇声旁的语音加工主要分布在头皮的额中区部分,这与汉字词汇水平的语音加工头皮分布基本一致(Kong et al., 2010)。
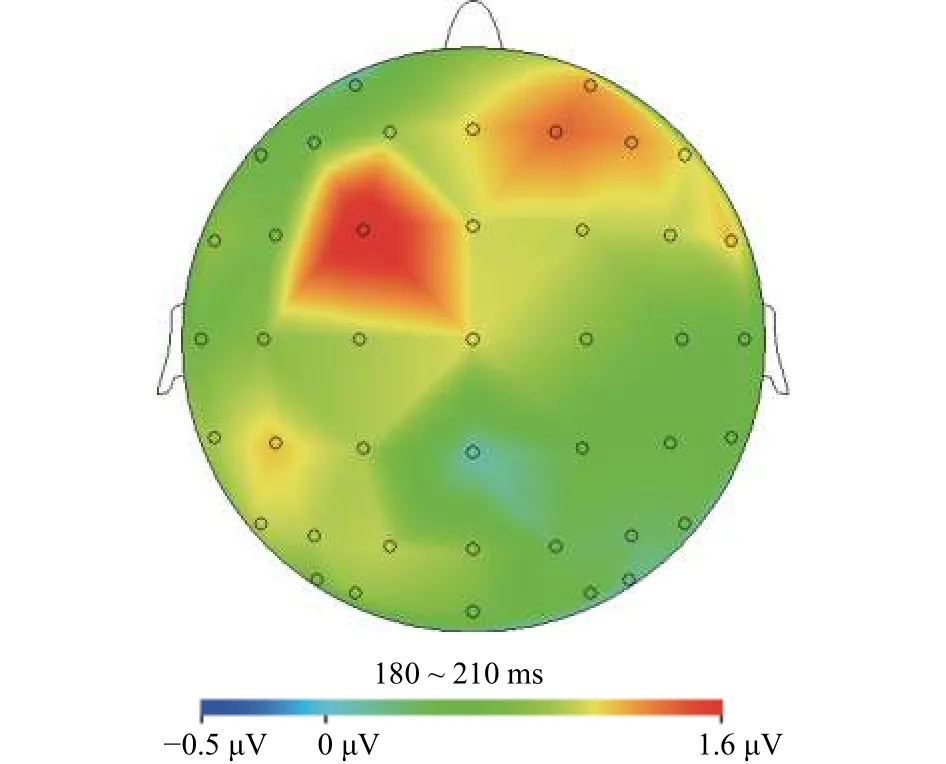
图3 部件可发音与不可发音条件下的ERP差异波脑地形图
3 讨论
亚词汇加工是词汇识别研究中的一个重要研究领域,汉字亚词汇加工同样如此,但近年来才出现一些相关的ERP研究。这些研究发现汉字亚词汇加工与ERP的早期成分如P150和P200以及晚期成分N400都有关系,研究者也尝试依据这些结果构建汉字识别的两阶段模型(Lee et al., 2007)。但是,模型的解释以及支撑证据都还面临着较多问题。比如,后续的研究发现,一致性ERP结果与支撑该类模型构建的关键实验结果完全不同(Yum et al., 2014)。因此,汉字识别的两阶段模型还有很多问题需要解决,亚词汇语音加工的ERP机制也还待进一步探讨。当前仍需要进一步考察汉字亚词汇部件加工与早期成分的确切关系及变化特性,以丰富和验证以往的这些研究结果和模型。
本研究尝试操控汉字亚词汇部件的可发音性来考查早期成分P200的变化,结果发现,与部件不发音的目标字相比,部件可发音的目标字产生了增强的P200。这可能是由于部件可发音目标字需要更多的认知加工资源来处理部件的语音信息及其与整字语音信息的关系。而包含不发音部件的汉字则只需要处理其整字水平的语音信息,需要较少的认知加工资源。这一结果通过语义相关判断任务获得,与以往采用词汇判断任务所得的结果一致(Yum et al., 2014)。因此,跨实验任务的一致性结果进一步表明P200对于亚词汇部件语音可发音性变化确实非常敏感,其效应受到该种语音特性的调节。综合以往关于汉字规则性和一致性的P200研究结果,可以确定P200能够稳定地反映亚词汇部件语音加工,其效应变化受到亚词汇各种语音特征的调节。此外,本研究中使用的实验材料都是高频汉字,实验结果也表明汉字亚词汇部件的语音激活非常快,这种快速的亚词汇部件语音激活不仅仅局限于低频字的识别中(Zhou et al., 2014)。
本研究结果有助于深入认识早期成分P200的变化与汉字形音加工之间的关系,进一步总结相应的P200变化模式。根据目前已有的关于汉字识别早期ERP成分的研究结果,可知P200的变化与以下几个因素有关:汉字读音规则性或一致性(Yum et al., 2014)、部件可发音性(本研究)、部件位置性(Wu et al., 2012)、汉字视觉相似性(Kong et al., 2012; Liu et al., 2003)和汉字词汇水平语音相似性(Kong et al., 2010; Zhang et al.,2009)。前四个因素反映了亚词汇部件形音信息的加工,后两个因素反映了词汇水平形音信息的加工。因此可以确定,P200是早期汉字词汇和亚词汇部件形音等信息加工的综合反映。词汇和亚词汇水平上的字形或语音信息都能单独调节其变化。
以往研究发现汉字的形、音信息对P200的影响存在差异。例如形异音同字对比非同音控制字对所激活的P200更强(如,“梏-雇”、“甥-雇”)(Kong et al., 2010; Liu et al., 2003),但音异形似的独体字对和合体字对都比形音皆异的控制字对诱发更小的P200,而且音异形似的合体字对的P200显著大于独体字对的(如,“目-且”、“读-续”)(Kong et al., 2012)。本研究结果进一步显示P200受到亚词汇部件语音加工的调节,部件可发音性导致更大的P200。这似乎说明Kong等(2012)研究中音异形似合体字对增强的P200可能是由亚词汇部件语音相似性的加工所致。也就是说,形似字对中若同时共享相同的亚词汇语音信息(如合体字共有部件),也会导致P200效应增大。
综上所述,可以尝试总结P200的变化特性,即在汉字识别的过程中,同一水平上的词汇或亚词汇信息加工,如字形加工会使P200减弱(Kong et al., 2010; Liu et al., 2003),但语音加工会使P200增强(Kong et al., 2012)。因此,形似音异字对可能诱发最小的P200波幅,形异音同字对可能诱发最大的P200波幅,而形似音同字对诱发的P200波幅则可能处于前两者之间。这一推测也能解释以往研究中发现的一致性P200效应(Yum et al., 2014),即一致字比不一致字导致更大的P200效应,原因在于其具有更多相同的词汇水平上的语音激活。另一方面,汉字词汇与亚词汇两个水平上的语音信息的相似性P200变化又不同于同一水平上的P200变化特征。当词汇和亚词汇两个水平上语音相同时(即规则字),会导致整字水平上的语音加工更快,因此会出现减弱的P200效应而非增强的P200效应(Yum et al., 2014)。概括而言,可以推测同一(词汇或亚词汇)水平上的字形相似性和语音相似性产生相反的P200效应变化,前者更小,后者更大;而词汇和亚词汇两个水平上的语音相似性产生更小的P200效应变化。这一变化模式不符合汉字识别两阶段模型的预测(Hsu et al., 2009; Lee et al., 2007),但更符合也能更合理地解释汉字规则性和一致性P200效应(Yum et al., 2014)。
另一方面,基于汉字加工的这些推测与拼音文字中的P200的研究结果存在差异(Barnea &Breznitz, 1998; Kramer & Donchin, 1987)。拼音文字中发现形音都不匹配的词对产生最大的P200效应,形异音同或音异形似时P200效应为中等水平,而形似音同时P200效应最小。这种不同书写系统之间的词汇加工P200效应差异的深层机制值得进一步探讨。
4 结论
本研究结果表明,P200对汉字亚词汇水平的语音信息加工非常敏感,其效应变化受到亚词汇部件语音特性的调节。而且,P200效应变化模式在汉字与拼音文字中可能存在着极大差异。
