Stacking算法在医疗健康数据中的应用研究
2020-07-18丁伟民

摘 要:文章分析了基于Stacking的算法框架,提出了一种基于Stacking的集成学习算法,在两种疾病数据集上,实验结果表明,该方法性能良好。
关键词:集成学习;随机森林;堆栈
1 分类挖掘技术在疾病辅助诊断上的应用
近年来,越来越多的学者将分类挖掘技术应用于疾病的輔助诊断上,如刘文博等[1]提出了一种迭代随机森林算法,对糖尿病数据进行预测。金强等[2]提出,应用改进的BP神经网络算法,提高乳腺癌诊断准确率。本文提出了一种基于堆栈的集成学习算法,应用于肝脏疾病和皮肤疾病数据的分类预测,为临床诊断、个人健康提供有效的决策依据与帮助。
2 基于Stacking的集成学习算法
Stacking通常是一个两层结构:0层和1层。0层在底层,选择训练多个不同类型的基础分类器生成元级数据;1层应用元级数据训练形成元分类器。元数据通过K折交叉验证的过程生成,由基础分类器对输入实例的预测结果和实例的真实类标号组成。其中,基础分类器的输出有两种方式:类标号、类概率分布。研究证明,基于类概率分布的Stacking算法性能比较好。学者们提出了许多基于类概率分布的Stacking算法,如Stacking-MLR等[3]和Stacking-MDT等[4]。本文选择基础分类器输出的类概率分布作为元数据的组成部分,并选择Randomforest(RF)作为元分类器,构建集成算法Stacking-RF。
3 数据集与评价准则
实验在两个公共数据集上进行,包括肝脏疾病数据集(Hepatitis)和皮肤疾病数据集(Dermatology)。两个实验数据集信息如表1所示。
实验采用准确率衡量集成算法的性能。准确率表示正确分类实例数与全体实例数的比值。
4 实验与分析
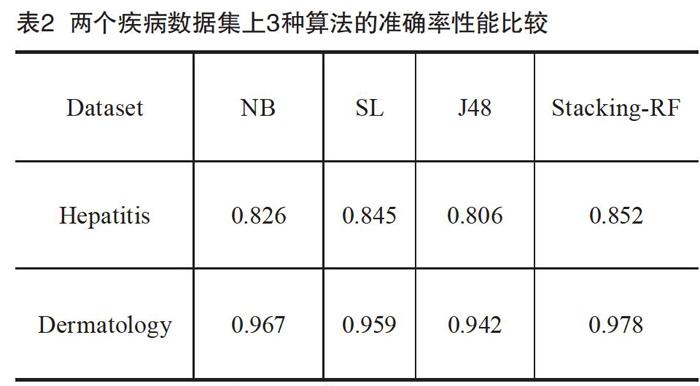
实验选择的3个基础分类器:NaiveBasye(NB),SimpleLogistic(SL)和J48,元分类器为Randomforest(RF),实验数据如表2所示。
从表2可以看出,本文提出的集成算法Stacking-RF在准确率性能指标上,均优于3个个体分类器NaiveBasye,SimpleLogistic和J48。如在Hepatitis,Stacking-RF优于准确率最高的个体分类器SimpleLogistic 0.8%。同样,在数据集Dermatology,Stacking-RF均优于3个个体分类器。因此,本文提出的集成算法Stacking-RF在两种疾病数据集上表现了良好的性能。
5 结语
首先,本文详细分析了基于Stacking的算法框架;其次,提出了一种基于Stacking的集成学习算法;最后,在两种疾病数据集上进行实验,结果表明,本文提出的集成算法性能表现良好。
[参考文献]
[1]刘文博,梁盛楠,秦喜文,等.基于迭代随机森林算法的糖尿病预测[J].长春工业大学学报,2019(6):604-611
[2]金强,高普中.人工神经网络在乳腺癌诊断中的应用[J].中国普外基础与临床杂志,2019(5):625-630.
[3]TING K M,WITTEN I H.Issues in stacked generalization[J].Journal of Artificial Intelligence Research,1999(10):271-289.
[4]TODOROVSKI L,DZEROSKI S.Combining multiple models with meta decision trees[C].Paris:4th European Conference on Principles of Data Mining and Knowledge Discovery,2000.
[6]袁梅宇.数据挖掘与机器学习-WEKA应用技术与实践[M].北京:清华大学出版社,2010.
作者简介:丁伟民(1979— ),男,汉族,山东潍坊人,讲师,硕士;研究方向:计算机应用技术。
