一种基于DBSCAN算法的提升互联网网站归属判定准确率的方法
2020-07-18于佳华
◆于佳华
(国家计算机网络应急技术处理协调中心黑龙江分中心 黑龙江 150001)
从20世纪60年代美国的APPANet到今天的国际互联网,网络技术得到了迅猛发展,越来越多的组织和个人接入互联网。包括网络终端、网络设备、网络服务等在内的网络资产已被广泛应用于各类政府、企事业单位的日常业务工作,极大地提高了工作效率,促进了业务工作的发展,但也带来了许多问题和隐患。随着单位网络规模的不断扩大,网络资产及其所包含的漏洞类型不断增多,给单位网络安全管理带来了巨大压力[1]。
网站是网络资产中的一类特殊而重要的资产,互联网上除了存在大众所熟知的门户网站、娱乐网站、购物网站外,更存在着大量的电子政务、自动化办公、金融服务等网站,这些网站归属于不同的政府、企事业单位,掌握清楚这些网站的归属对于网络安全工作,尤其是漏洞普查、漏洞通报、风险预警等具有重要的意义。
1 研究现状
目前确定网站归属主要有网站备案信息判定和页面信息判定两种方法。
1.1 网站备案信息判定
网站备案是根据国家法律法规要求,网站的所有者向国家有关部门申请的备案,主要有工信部 ICP备案和公安部联网备案[2]。备案信息包括单位名称、单位性质、网站名称等。目前工信部 ICP/IP地址/域名信息备案管理系统、公安部全国互联网安全管理服务平台、站长之家等网站提供网站备案信息查询服务,用户输入域名或备案号,可查询到备案单位。
网站备案信息判定主要存在如下几个问题,一是有的单位的门户网站等主要网站进行了备案,但OA等次要网站未进行备案;二是很多未绑定域名的网站未进行备案;三是很多域名到期后,未进行备案撤销,导致域名被其他单位或个人申请并绑定新的网站,出现备案单位与网站归属单位不一致的情况。
1.2 页面信息判定
页面信息判定主要是通过页面上显示的标题、版权等信息,判断网站的归属。比如很多政府机关、高校、企业的网站都会在页面显著位置展现网站的归属及用途,这些信息可以准确识别网站的归属单位。
页面信息判定方法主要存在如下几个问题,一是很多通用网站如ERP管理系统、考勤系统、防火墙系统等,页面上只显示了厂商的信息,无归属单位信息;二是有些仿冒诈骗网站,页面故意显示所仿冒单位信息,给人误导;三是某些单位为了避免监管机构通报,特意在页面上隐去可识别本单位信息的内容。
综上,目前网站归属领域常用的网站备案信息判定和页面信息判定两种方法,都存在某些情况下无法判定属或者判定错误的问题。
2 基于DBSCAN算法判定互联网网站归属的方法
本文将无监督聚类算法 DBSCAN[3]应用于互联网网站归属判定领域,通过对网站的备案信息和页面基本信息进行特征提取,分类别进行特征量化,再使用聚类算法进行分析,实现网站归属单位的自动化判定。方法的流程示意图如图1所示。
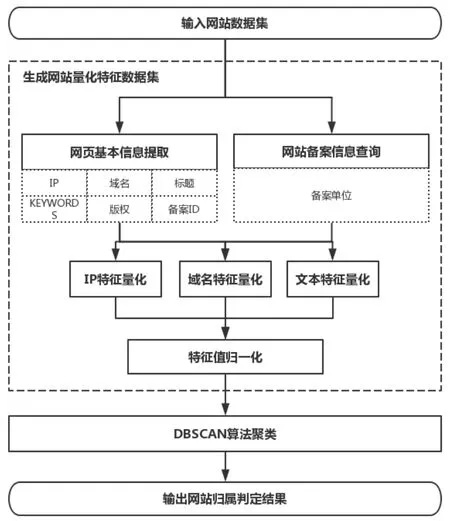
图1 流程示意图
2.1 基础信息提取
对于待判定归属单位的网站URL集合,逐个网站进行如下计算。
首先是提取两类网站基础信息:
(1)页面基本信息提取,提取网站的 IP、域名、标题、KEYWORDS、版权、备案ID等。本文使用自主编写的爬虫工具提取这些信息。
(2)网站备案信息查询。通过工信部ICP/IP地址/域名信息备案管理系统、公安部全国互联网安全管理服务平台、站长之家等平台查询网站的备案单位信息。根据实践只有通过域名查询数据较为准确,因此只需对绑定域名的网站执行本步骤。
大部分网站不是上述所有类别信息都能提取到,提取过程遵循能提取尽量提取的原则,提取不到信息的特征用空字符串表示。基础信息提取完成后,对于任一网站会形成原始特征向量FOwebsite,由IP、域名、标题、KEYWORDS、版权、备案ID、备案单位等七类特征组成。
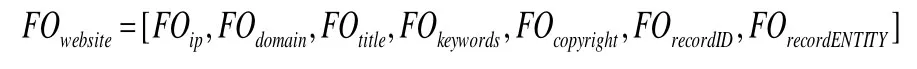
其中,IP特征为点分十进制的IP地址表示形式,域名特征为一组用点分隔的字符串,其他特征为文本特征。
2.2 特征量化及归一化
对这七类特征分别进行特征量化,将每类特征转化为可代表其特征的具体数值。
(1)IP特征量化
对IP原始特征FOip进行如下计算,得到IP量化特征FQip。
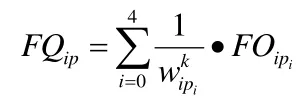
其中,wip为IP特征的权重向量,k为指数参数。FOipi为点分十进制IP地址的每一位数值。通过本算法实现IP地址越相邻,计算后的IP量化特征值越相近。
(2)域名特征量化
对域名进行预处理,先将域名原始特征FOdomain通过 M ozilla Public Suffix List数据[4]过滤掉域名中的公共后缀字符串,再将域名进行逆序反转,得到域名预处理特征FOPdomain。
将FOPdomain进行如下计算,得到域名量化特征FQdomain。

其中,wdomain为域名特征的权重向量,k为指数参数。FOPdomaini为预处理域名特征向量FOPdomain的每一位字符。通过本算法实现域名越相似,计算后的域名量化特征值越相近。
(3)文本特征量化
针对标题、KEYWORDS、版权、备案ID、备案单位这五类文本特征都采用相同方法进行特征量化,使用文本原始特征FOtext统一代表这些类特征的原始特征。
首先利用北京理工大学张华平博士的汉语分词系统ICTCLAS[5],对这批网站的所有文本原始特征进行分词,得到分词库WSL。
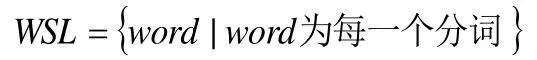
对文本原始特征FOtext依据分词对文本特征进行如下计算,得到文本预处理特征FOPtext,为n维的特征向量,每一位取值为0或1,n为WSL的大小。
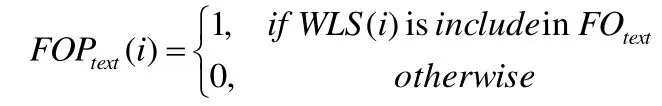
将文本预处理特征 进行如下计算,得到文本量化特征。FOPtext FQtext

经过以上三类特征的量化处理,得到该网站的量化特征向量FQwebsite。
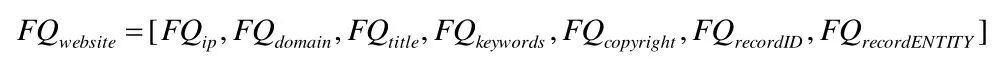
再将各类特征值再映射到同一量纲下的[0,1]区间,本文使用python语言sklearn模块的normalize函数来实现。最终得到该网站归一化特征向量FNwebsite。
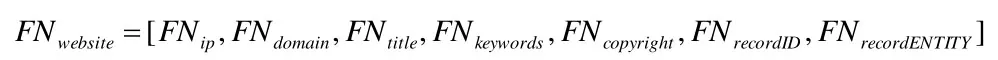
反复执行以上步骤,直到所有网站都生成一个归一化特征向量,最终得到数据集合FNS。
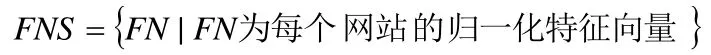
2.3 聚类分析
DBSCAN是一个比较有代表性的基于密度的聚类算法,它将簇定义为密度相连点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类[2]。
本文对数据集合FNS使用DBSCAN算法进行聚类分析,通过调整关键参数扫描半径Eps和最小包含点数MinPts对聚类效果进行调节,形成聚类簇,同一簇下的网站即归属同一单位。本文使用python语言sklearn模块的DBSCAN函数来实现。聚类效果如图2所示。

图2 聚类效果图
3 实验
3.1 实验数据集
互联网网站归属单位判定领域,目前还没有权威机构数据集。本文以某机构2016年组织的某区域信息系统登记的数据为实验数据集,该数据及包含党政机关、能源、金融、医疗卫生、教育等多个行业的200个网站。
3.2 实验方法
对同一数据集,分别以网站备案信息判定、页面信息判定和DBSCAN算法判定三种方法进行网站归属的判定,准确率定义为某一方法可准确识别出归属单位的网站数目占数据集中网站总数目的比值。
3.3 实验结果
实验结果如表1所示,可以看出,本文提出的基于DBSCAN算法的互联网网站归属判定方法可以较大提升网站归属单位判定的准确率。

表1 不同方法准确率对照表
5 结束语
本文提出的基于DBSCAN算法的互联网网站归属判定方法,用于解决网络资产探测领域中网站资产的归属单位判定问题,通过对网站的基础信息进行量化特征提取,使用聚类分析算法实现网站归属的自动化判定,有效提升了归属单位判定准确率。
