基于布谷鸟搜索优化算法的多文档摘要方法
2020-07-17周诗源王英林
周诗源,王英林
(上海财经大学 信息管理与工程学院,上海 200433)
0 概述
随着移动互联网的快速发展,网络中的信息量呈指数级增长,大量资讯、知识、视频、音乐等资源可供用户选择,信息过载问题日益突出,而文档摘要是解决信息过载的有效方式。文档摘要[1]是指在不丢失原文主要内容的前提下创建摘要的过程[2],其能够提供相关信息的快速导向,帮助用户确定文档是否具备可读性,因此成为近年来研究的热点问题。
根据摘要生成过程中的文档数量,可将摘要分为单文档摘要[3]和多文档摘要[4],由于多文档摘要的搜索空间大于单文档摘要,因此提取重要句子的难度更大。为生成包含原始文档重要信息句的最优摘要,文献[5]设计基于整数线性规划的概括式多文档自动摘要方法,优选出每个主题下的重要主题语义信息,生成新的摘要句,并对候选摘要句进行润色加工,解决了生成概括式摘要的信息覆盖和可读性问题。文献[6]提出一种基于K最近邻句子-图模型的动态文本摘要方法,根据K近邻规则构建一个双层句子图模型,使用基于密度划分的增量图聚类方法对句子进行子主题划分,并结合时间因素提高句子新颖度以抽取动态文摘。文献[7]使用粒子群优化(Particle Swarm Optimization,PSO)算法设计单文档摘要器,通过内容覆盖度和冗余度特征的加权平均,获得目标函数,进而设计文档摘要器。文献[8]提出一种句子话题重要性计算方法,通过分析句子与话题的语义关系,判断句子是否描述了话题的重要信息,同时设计一种基于排序学习的半监督训练框架。此外,现有研究采用PSO算法[9]、差分进化(Differential Evolution,DE)算法[10]、遗传算法(Genetic Algorithm,GA)[11]、LDA主题模型[12]及子主题划分模型[13]等自动生成文档摘要。鉴于布谷鸟搜索(Cuckoo Search,CS)算法[14-15]在多目标优化问题中的性能优势,本文提出基于CS算法的多文档摘要方法,主要过程包括预处理、输入表示和摘要表示。
1 多文档摘要
多文档摘要是从多个文档中自动创建一个简明文档(称为摘要)的过程。多文档摘要过程具体包括预处理、输入表示和摘要表示3个步骤,处理流程如图1所示。摘要系统的输入为多个文档,先对这些文档进行预处理,再通过输入表示和摘要表示提取最终摘要。
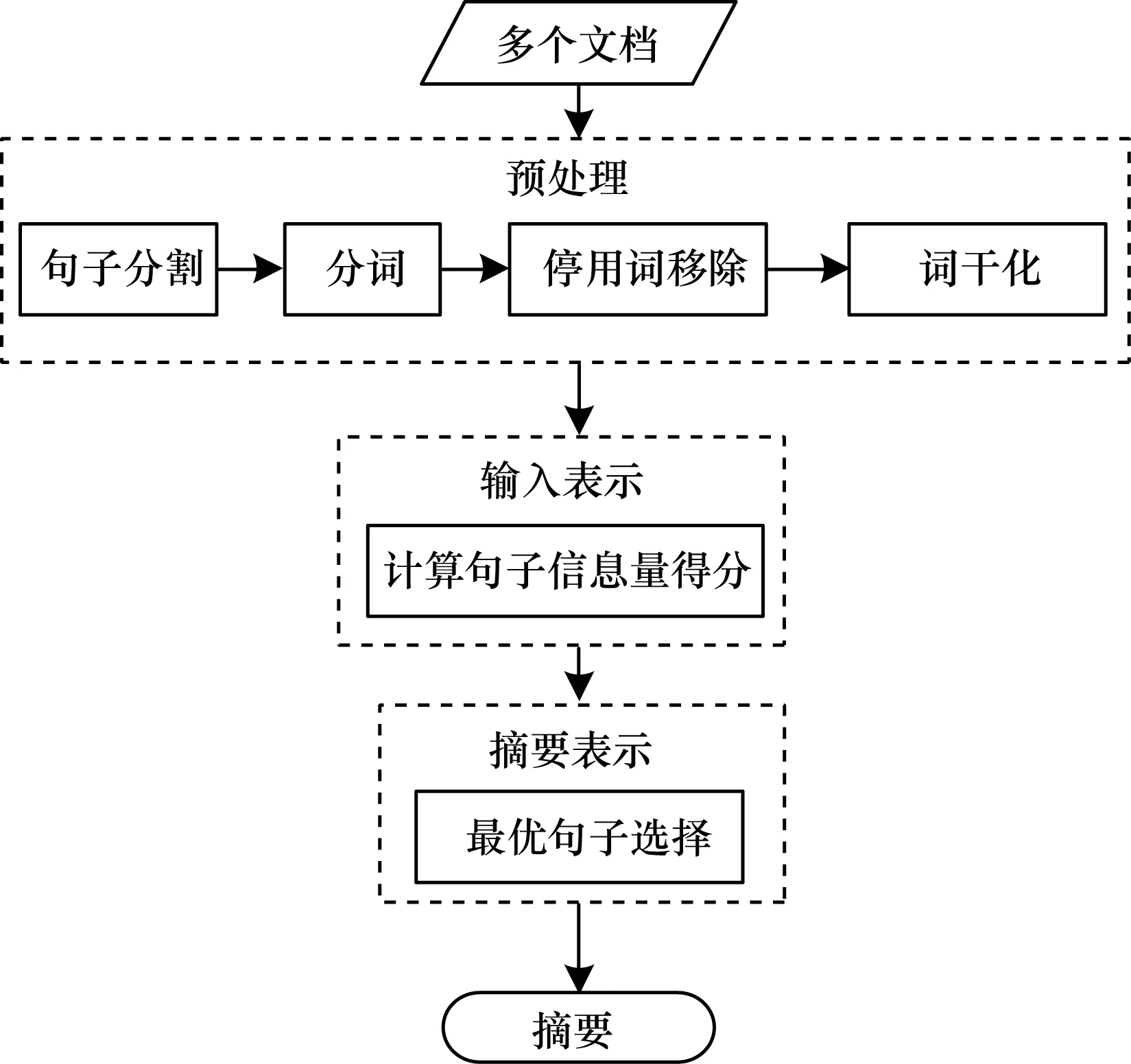
图1 多文档摘要处理流程
1.1 预处理
预处理流程如图2所示,具体步骤如下:
1)句子分割:从输入的文档集合中,将每个文档D单独分割为D={S1,S2,…,Sn},其中,Sj表示文档中的第j个句子,n表示文档中的句子数量。
2)分词:将每个句子的术语标记为T={t1,t2,…,tm},其中,tk(k=1,2,…,m)表示D中出现的不同术语,m表示术语数量。
3)停用词移除:将文档中出现频率较高但没有实际检索作用的词进行移除,如“的”“了”“在”等。
4)词干化:将句子转换为词的基本形式。

图2 预处理流程
1.2 输入表示
在输入表示阶段,使用预处理后的数据计算每个句子的权重(术语频率之和),即句子信息量得分,将句子信息量得分作为算法输入,其流程如图3所示。
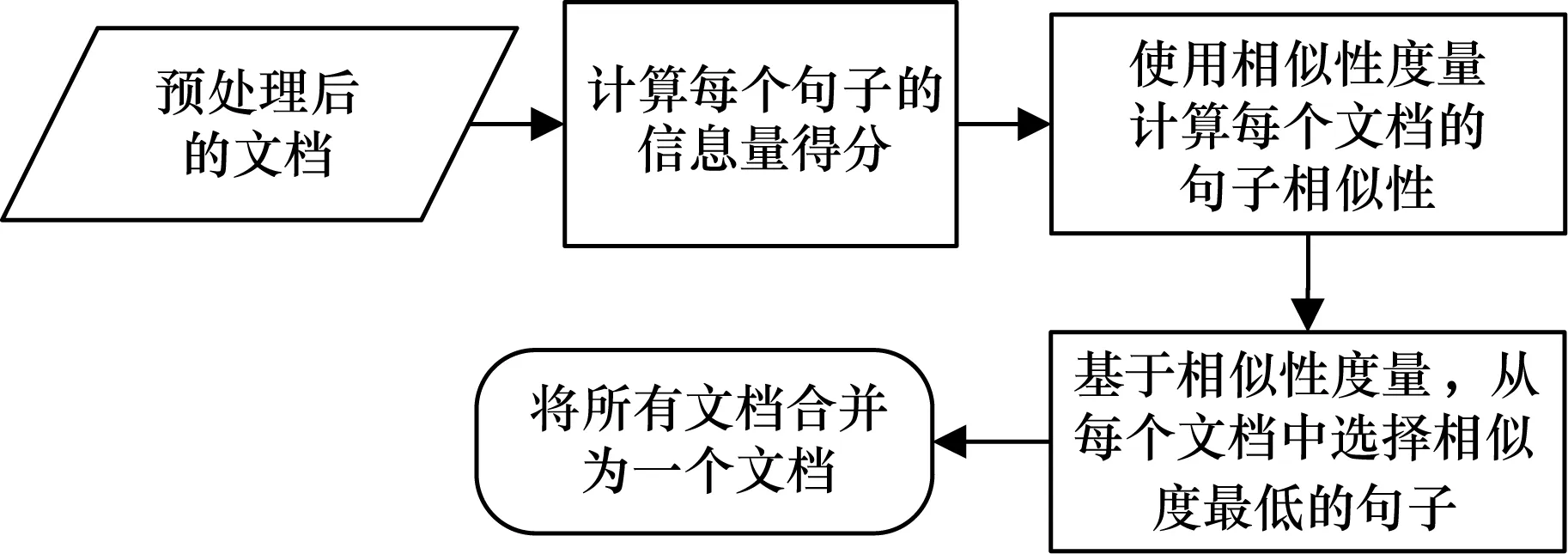
图3 输入表示流程
1.3 摘要表示
摘要表示的目的是为文档集合生成包含有用信息的摘要。在最优句子的选择过程中,基于预定义阈值对CS优化算法得出的句子信息量得分进行比较,选出能够代表摘要的重要句子,其流程如图4所示。
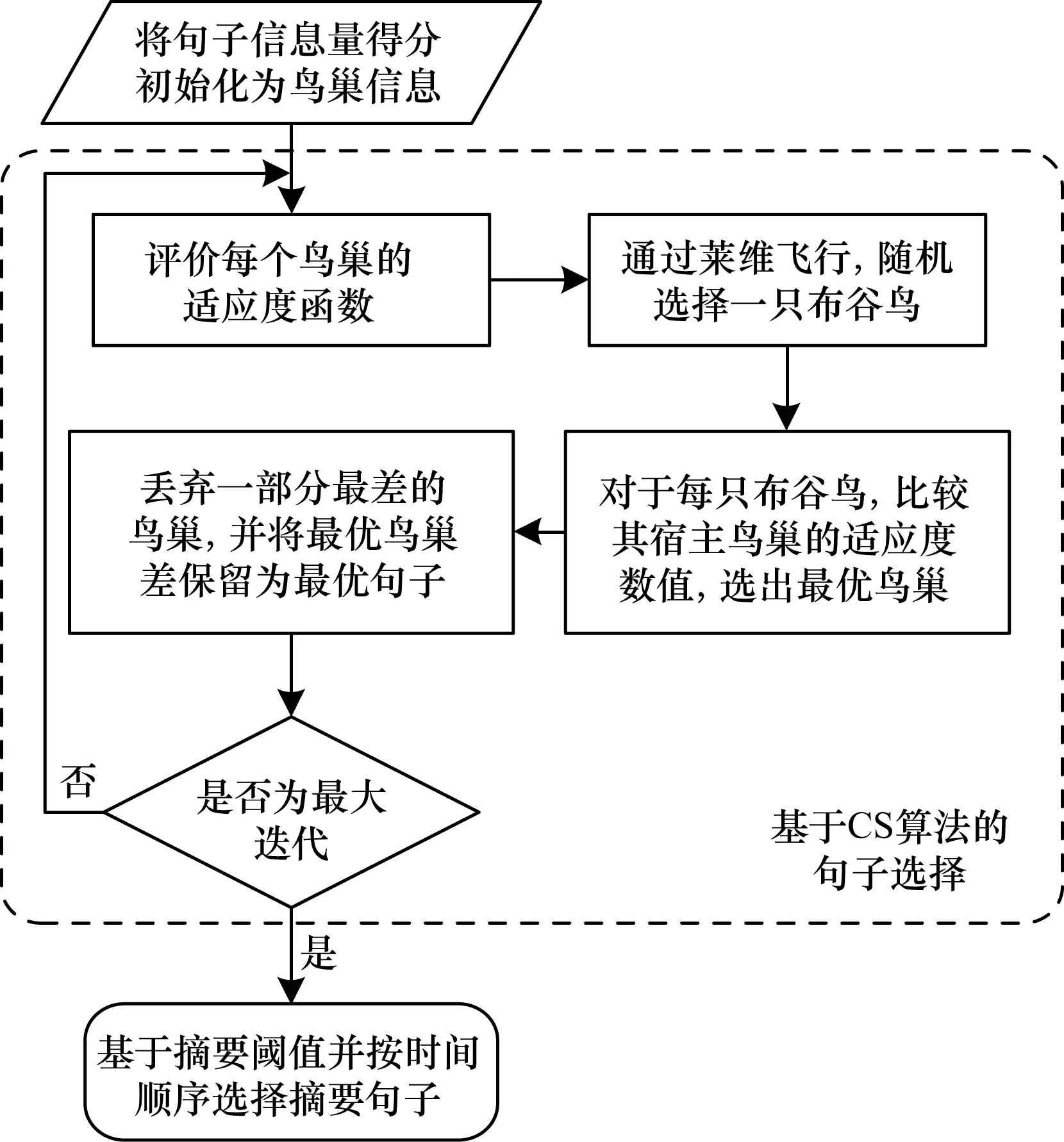
图4 摘要表示流程
2 基于CS优化算法的多文档摘要
2.1 CS优化算法
CS算法[16]是一种启发式进化算法。布谷鸟是一种具有激进繁育策略的鸟,成年布谷鸟将卵产在其他鸟类的鸟巢中,由宿主鸟代为孵化和育雏。CS算法将鸟巢视为候选解,每个布谷鸟仅可产一枚卵,表示一个新的候选解。标准CS算法包含3个理想化规则:1)每个布谷鸟在一个随机鸟巢中产一枚卵,代表一个解集;2)鸟巢中包含的最优卵将传递至下一代;3)可用鸟巢数量固定,一只宿主鸟发现一枚寄生卵的概率为Pa。当满足条件时,宿主鸟可以丢弃寄生卵或放弃其鸟巢并在其他地方新建一个鸟巢。
在实际应用时可使用CS算法的最简单形式,其中每个鸟巢只有一枚卵,在此情况下无需区分鸟巢、卵和布谷鸟,因为鸟巢、卵和布谷鸟均为一一对应关系,而且该算法可扩展至更复杂的情况,其中每个鸟巢中存在多个卵,代表一个解集。
(1)
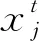
另外,使用莱维飞行执行全局随机游走,其全局收敛性已得到证明[16]。莱维飞行包含连续随机步[17],其特征为一连串快速跳跃,计算公式为:
(2)
其中,α表示步长,其与优化问题的规模成正比(即α>0),⊗表示乘法中的逐项移动,Levy(λ)表示从莱维分布中提取的随机数。
本文基于CS优化算法的多文档摘要方法具体步骤如下:
步骤1采集一个多文档集合M,M={D1,D2,…,DN},其中,每个Di表示集合M的单个文档,Di的长度表示为句数,不同文档包含不同句数。
步骤2使用句子分割、分词、停用词移除和词干化对每个文本文档Di进行预处理。
步骤3使用式(3)计算出每个预处理后文档Di的句子Sj的信息量得分ISjk,即通过词频之和推导出的句子权重。
ISjk=tfjk×loga(n/nk)
(3)
其中:ISjk表示每个句子Sj相对于术语tk的信息量得分;tfjk表示术语频率,即术语tk在句子Sj中的出现次数;nk表示包含术语tk的句子数量;loga(n/nk)表示用于句子检索的向量空间模型中的逆句频率。
步骤4使用式(4)计算出预处理后文档Di的句间相似度。
(4)
步骤5基于相似度阈值,选择每个Di中相似度最低的句子。
步骤6将选出的每个Di中所有相似度最低的句子合并为单个文档Dinput。
步骤7初始化CS参数,例如种群大小、寄生卵被发现率(Pa)、步长因子(Sf)和莱维指数(λ)。
步骤8在指定搜索空间内,将句子信息量得分作为每只布谷鸟的鸟巢信息,每个鸟巢对应给定优化问题的一个候选解。
步骤9使用式(3)针对给定问题计算每个鸟巢的适应度函数fi。
步骤10利用式(2)得到新的鸟巢种群。
步骤11计算出与新鸟巢相对应的适应度函数fj,并将其与旧鸟巢的适应度函数fi进行比较。
步骤12若fj优于fi,则使用新候选解替换旧候选解。
步骤13在新种群中,选择Pa性能较差的一部分鸟巢,将这些鸟巢替换为指定搜索空间内随机生成的新鸟巢。
步骤14为新鸟巢计算适应度函数。
步骤15基于适应度数值,记录当前种群集合中性能最优的鸟巢。之后,将这些鸟巢与前代最优鸟巢相比,选择其中性能最优的鸟巢。
步骤16若未达到最大迭代次数,则返回步骤9。
步骤17基于预定义的句子相似度阈值从文档中按时间顺序选择句子。
CS算法的时间复杂度计算主要集中于适应度函数f的计算[18],在本文中对文档预处理过程为步骤1~步骤6,适应度函数包括旧鸟巢的适应度函数fi(步骤9)以及新鸟巢相对应的适应度函数fj(步骤10、步骤14)。当适应度函数f的自变量阶数比n高时(n表示文档中的句子数量),算法执行一次的时间复杂度为O(f(n)),当适应度函数f的自变量阶数与n相同或低于n时,时间复杂度为O(n)。在考虑终止条件的情况下,总体时间复杂度为O(f(n)+n)。CS算法的空间复杂度较低,假设一个句子的存储空间为一个存储单元,对于包含n个句子的文档,执行文档摘要操作的空间复杂度为O(n)。
2.2 目标函数建立
文本摘要的目标是最大化生成摘要的信息量,降低冗余并保持可读性。因此,本文基于多个目标,从文档集合中建立摘要,通过内容覆盖度、衔接性和可读性以优化摘要,即创建3个子函数fcov(S)、fcoh(S)和fread(S),构成目标函数f(S)。
f(S)=fcov(S)+fcoh(S)+fread(S)
(5)
一个摘要中应包含相关句子集合以覆盖文档集合的主要内容,并通过信息量得分最高的句子反映文档的主要内容,因此摘要的内容覆盖度fcov(S)定义为:
fcov(S)=Sim(Si,O),i=1,2,…,n
(6)
其中,O表示句子集的主要内容中心,O={O1,O2,…,On},Oi为每个文档的句子加权平均数。通过对Si和O之间的相似度进行评价,以衡量句子的重要程度。若相似度数值越高,则内容覆盖度越高。
摘要句子之间的衔接性是指句子层面和段落层面的概念联系,有助于更好地理解全文。若摘要衔接性fcoh(S)数值越高,则意味着句子间的联系越紧密,其定义为:
fcoh(S)=1-Sim(si,sj),i,j=1,2,…,n且i≠j
(7)
摘要可读性是指从集合D中选出能够最大化句间关系的子集S。若fread(S)的数值越高,则摘要的可读性越强,其定义为:
fread(S)=Sim(si,sj),i,j=1,2,…,n且i≠j
(8)
3 实验结果与分析
通过实验对本文多文档摘要方法进行性能测试,并在DUC开源基准数据集(DUC2006和DUC2007)上比较本文方法与基于双层K最近邻(Double-layer K Nearest Neighbor,DKNN)算法[6]和PSO算法[9]的多文档摘要方法的性能。实验环境为MATLAB 2011b,实验平台为4核Intel酷睿i5处理器,3.2 GHz内存,Windows 7操作系统,并且使用ROUGE工具对摘要结果的ROUGE得分进行分析。
3.1 实验数据集
本文使用DUC开源基准数据集对文本摘要结果进行评价。DUC数据集的参数设置如表1所示。在数据预处理阶段,通过比较可用的停用词表,从原始文档中移除不重要的词语,并使用词干分析器提取术语词干。
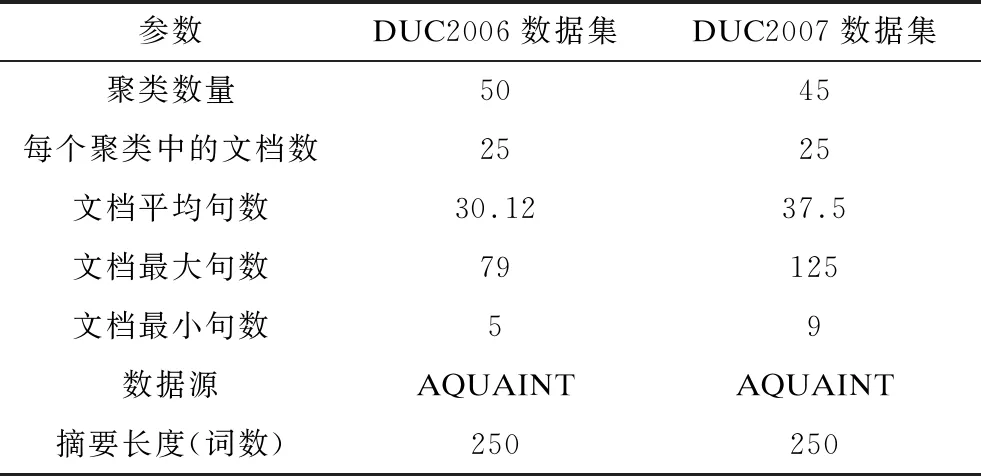
表1 DUC数据集参数设置
3.2 实验控制参数
由于控制参数以应用为导向,因此不存在固定赋值,而是通过大量仿真实验推导出参数值,本文方法、基于DKNN和PSO的多文档摘要方法的参数设置如表2所示,其中:Vmin、Vmax分别表示粒子群的最小速度和最大速度;C1、C2为加速系数,分别表示粒子向自身极值和全局极值推进的加速权值;W表示惯性权值;SMP表示DKNN的最优k值;CDC表示步长因子;SRD表示距离因子;MR表示两层KNN的混合率;w表示DKNN的近邻样本权重;C表示默认近邻对象个数。
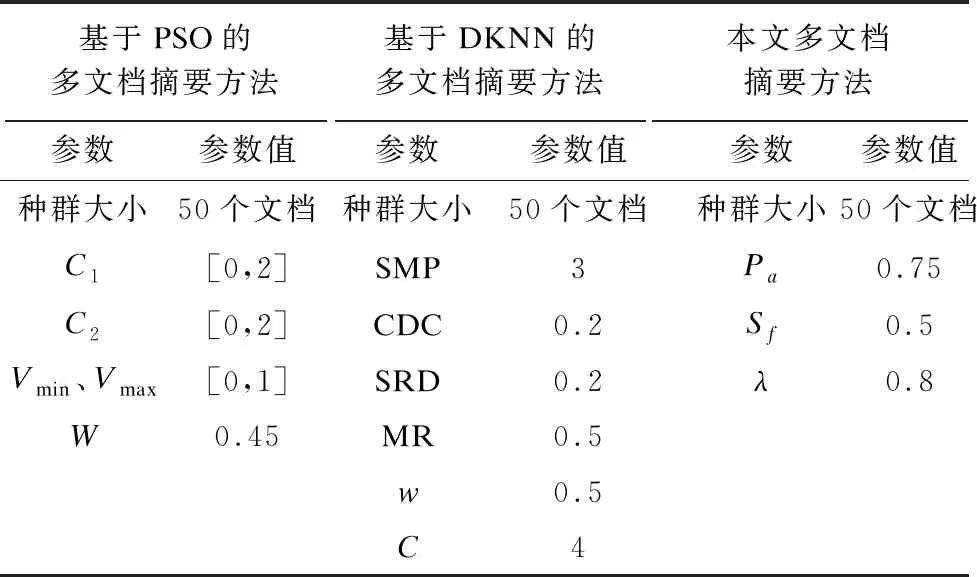
表2 3种多文档摘要方法的参数设置
3.3 摘要评价指标
本文使用敏感度(Sen,又称真阳性率)、阳性预测值(Positive Predictive Value,PPV)和摘要准确度(Sacc)指标对摘要方法进行评价。指标的定义基于候选摘要Candsum(使用本文方法生成的摘要)、参考摘要Refsum(人工生成的摘要)、真实句子Truesen(Candsum和Refsum中共同出现的句子)和不重要句子LSsen(Candsum或Refsum中均未出现的句子)。
敏感度定义为:
(9)
其中,|Truesen|表示真实句子的长度,|Refsum|表示参考摘要的总长度,参考摘要为人工生成,可信度高,用于评估来源摘要。式(9)还可看作是真阳性样本数与真阳性样本数和假阴性样本数的比值。敏感度反映了摘要方法生成的摘要质量,其值越大表示质量越高。
阳性预测值定义如下:
(10)
其中,|Truesen|表示真实句子的长度,|Candsum|表示候选摘要的总长度。式(10)还可以看作是真阳性样本数与真阳性样本数和假阳性样本数的比值。阳性预测值表示生成的摘要与原始文档集合相同的概率,高相似度和低相似度的摘要均不会被记录在内,因此该指标为针对特定情况。
摘要准确度用于综合评价本文方法生成摘要的准确性,是最重要的评价指标。摘要准确度越高,表明生成的摘要与原始文档集合的相似性越高,其定义如下:
(11)
3.4 ROUGE评价
本文使用文献[19]开发的ROUGE-1.5.5工具包作为文本摘要的评价度量工具。ROUGE包括ROUGE-L、ROUGE-N和ROUGE-S等多种工具,用于衡量生成摘要与人工摘要之间的文法(N-gram)匹配。在工具包中,ROUGE-N度量与比较两种摘要的N-gram并计算匹配数量:
(12)
其中,N表示N-gram的长度,Countmatch(N-gram)表示候选摘要和参考摘要中同时出现的N-gram最大数量,Count(N-gram)表示参考摘要中的N-gram数量。
本文使用ROUGE-N(ROUGE-1和ROUGE-2)度量对摘要性能进行评价,其度量与人工判断存在高度相关性。ROUGE-1衡量系统生成摘要和人工创建摘要之间的一元分词的重叠情况,ROUGE-2则比较二元分词的重叠情况[20],通过摘要的内容覆盖度、衔接性和文本可读性完成ROUGE-N的评价。ROUGE度量值越高,表明其生成的摘要与原始文档集合的相似度越高。
表3给出了基于PSO的多文档摘要方法、基于DKNN的多文档摘要方法和本文多文档摘要方法在DUC2006和DUC2007数据集上,ROUGE-N(ROUGE-1和ROUGE-2)的F度量值的最差值、平均值和最优值统计结果。通过比较DUC2006数据集的F度量值可以看出,对于这3种方法,ROUGE-1的最优F度量值为0.411 27~0.431 10,ROUGE-2的最优F度量值为0.078 40~0.139 86。在DUC2007数据集上,ROUGE-1的最优F度量值为0.409 67~0.424 30,ROUGE-2的最优F度量值为0.076 20~0.103 40。虽然该数值取决于所使用的数据,但是可以明显看出,本文多文档摘要方法在两个数据集的ROUGE得分中均得到了较高的F度量值,这充分说明了CS算法在摘要表示过程中的特征搜索优势,相比于PSO算法,可以得到更优的搜索解。

表3 3种多文档摘要方法基于ROUGE-N的F度量值比较
表4给出了基于PSO的多文档摘要方法、基于DKNN的多文档摘要方法和本文多文档摘要方法在DUC2006和DUC2007数据集上,ROUGE-N(ROUGE-1和ROUGE-2)度量的召回率、精度和F度量值比较。表5给出了基于PSO的多文档摘要方法、基于DKNN的多文档摘要方法和本文多文档摘要方法在DUC2006和DUC2007数据集上的敏感度、PPV和摘要准确度比较。通过对ROUGE-N的文档摘要度量和指标进行分析得出,与基于PSO的多文档摘要方法和基于DKNN的多文档摘要方法相比,本文多文档摘要方法在两个数据集上均得到了更好的ROUGE-1和ROUGE-2结果,其原因为本文所采用的CS算法更加适用于多文档摘要的特征搜索,ROUGE-N的F度量值不受召回率和精度的影响,并且摘要准确度也不受敏感度和PPV的影响。
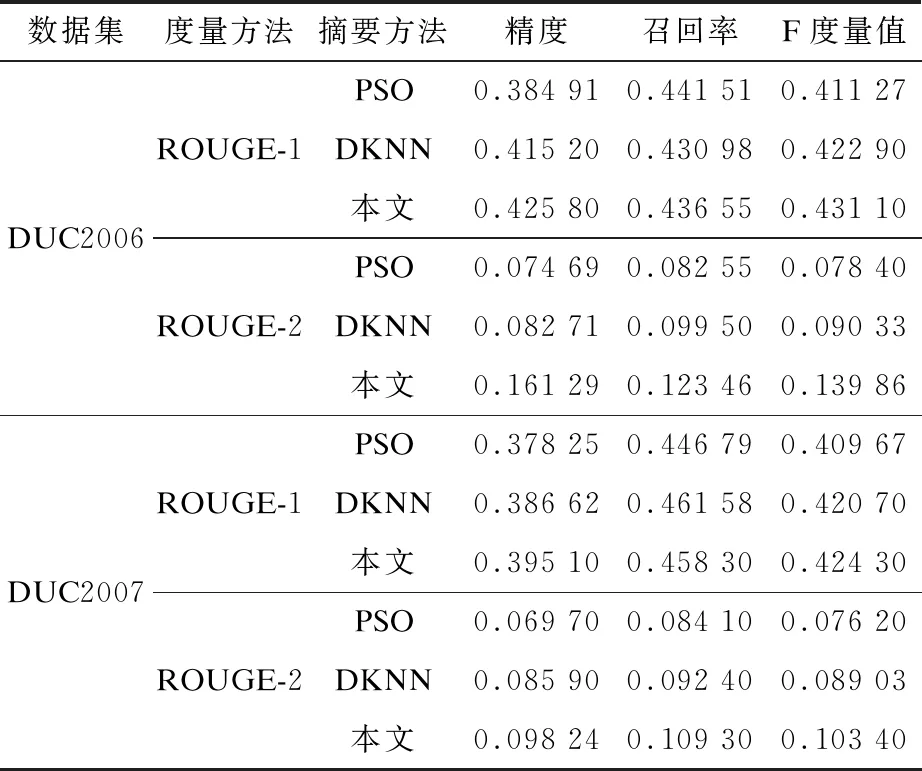
表4 3种多文档摘要方法的精度、召回率和F度量值比较

表5 3种多文档摘要方法的敏感度、PPV和准确度比较
3.5 衔接性分析
衔接性是自动摘要的重要属性,一般是指句子之间(甚至一个句子的不同部分)的联系程度能够支持读者理解其中的含义。摘要中的衔接性并不仅指句子的语法正确性,还包括句子层面和段落层面的联系。由此可知,前后句的衔接有助于更好地理解完整文本,通常使用余弦相似度计算摘要衔接性得分。图5给出了3种多文档摘要方法在DUC2006和DUC2007数据集上的衔接性得分。可以看出,在两个数据集上,本文多文档摘要方法的衔接性得分均高于基于DKNN[6]和PSO[9]的多文档摘要方法。
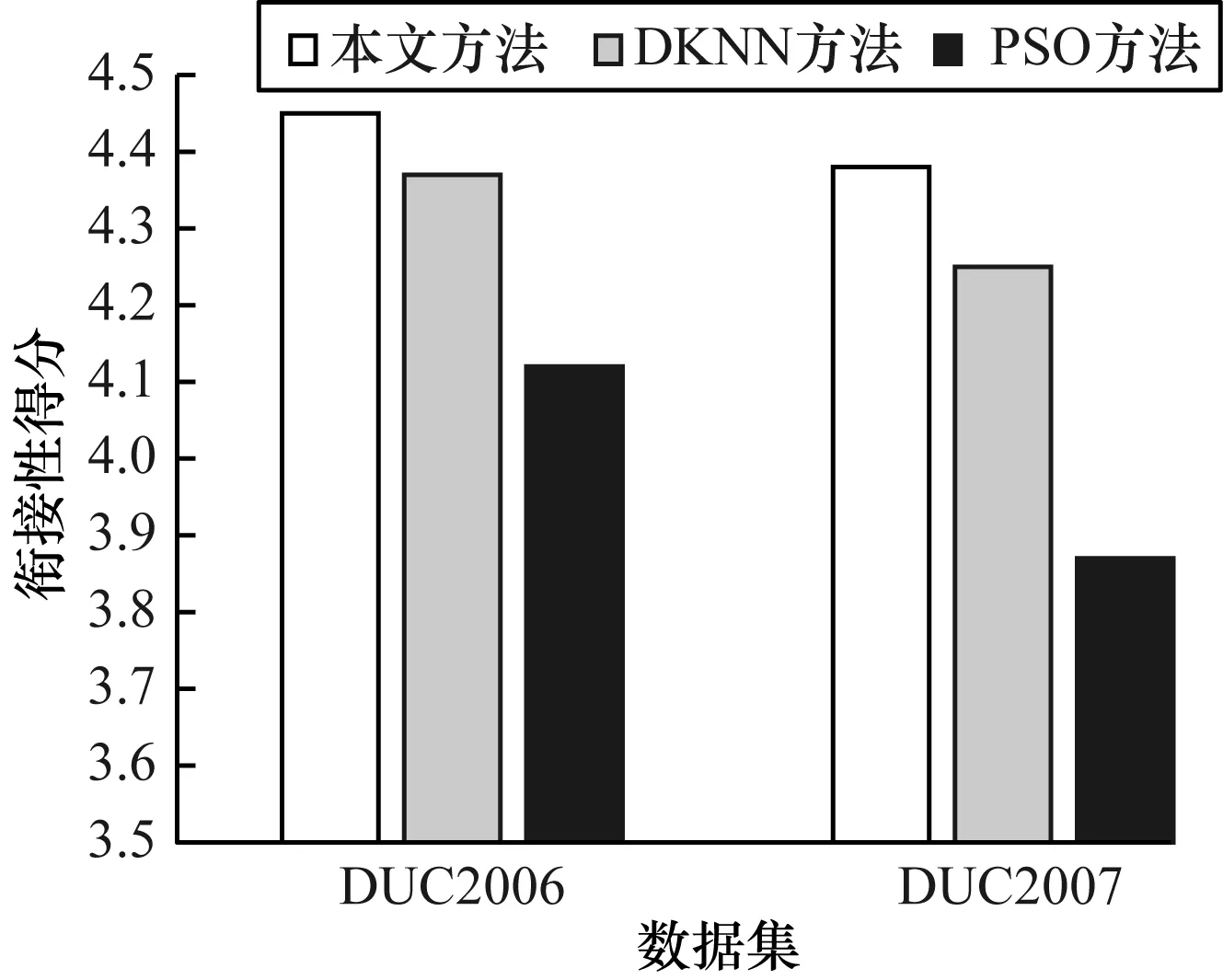
图5 3种多文档摘要方法的衔接性得分比较
3.6 可读性分析
可读性是内容的可辨识和理解程度,取决于句子平均长度、句中包含的新词数量以及文章中使用语言的语法复杂度等因素。常用的可读性评价指标有Flesh Kincaid难度级数(FKGL)、Gunning fog(FOG)得分、SMOG指数、Coleman Liau(CL)指数和自动易读性指数(Automatic Readability Index,ARI)等[21]。以上评价指标都是数值越高,可读性得分越高,即生成的摘要更易于阅读和理解。图6和图7分别给出了在DUC2006和DUC2007数据集上3种多文档摘要方法的可读性得分。可以看出,在DUC2006数据集上,本文多文档摘要方法在CL、FOG、SMOG和ARI指标上的得分均优于基于PSO和DKNN的多文档摘要方法,在FKGL指标上3种多文档摘要方法得到了几乎相同的结果。在DUC2007数据集上,本文多文档摘要方法的可读性得分均高于其他两种方法。
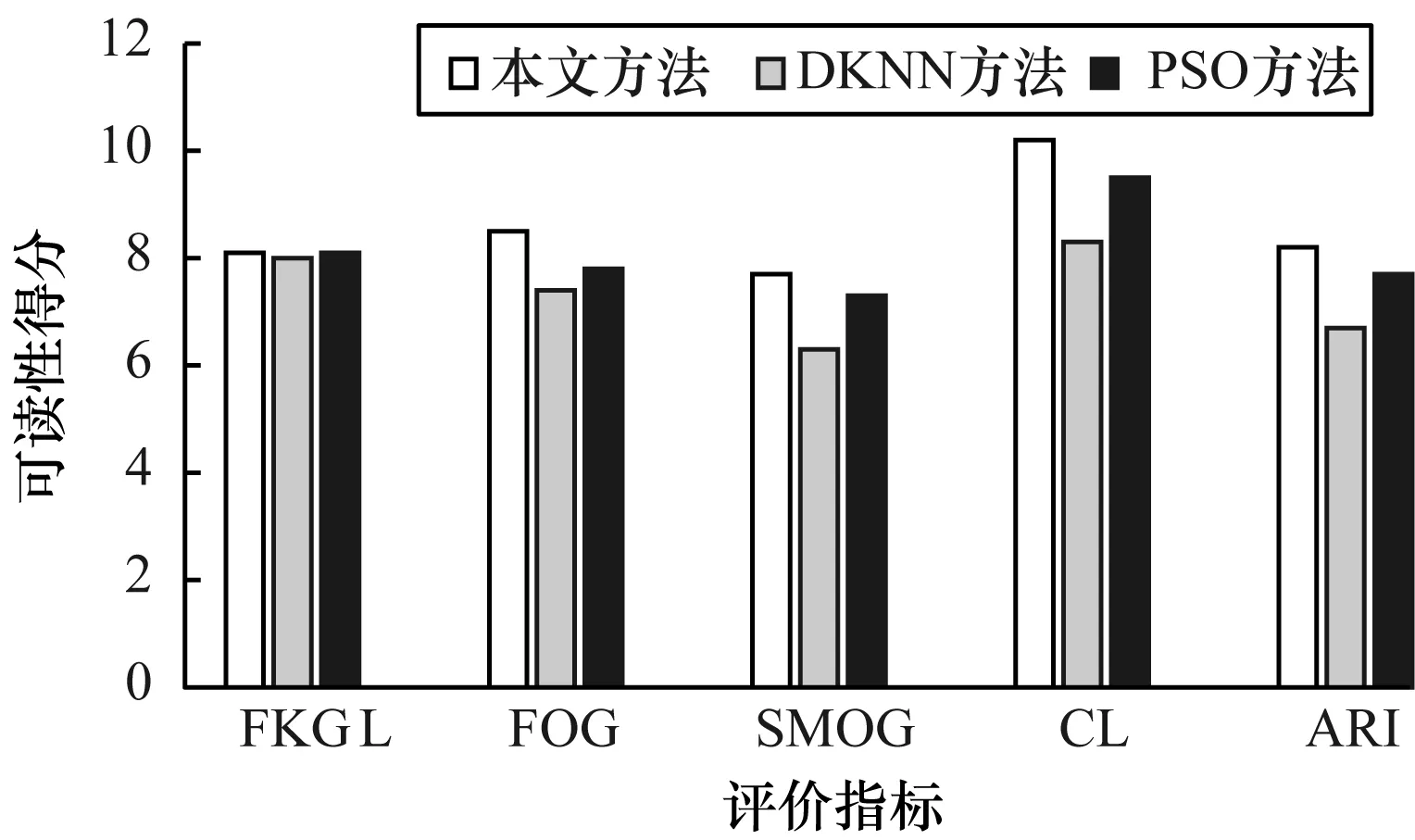
图6 3种多文档摘要方法在DUC2006数据集上的可读性得分比较
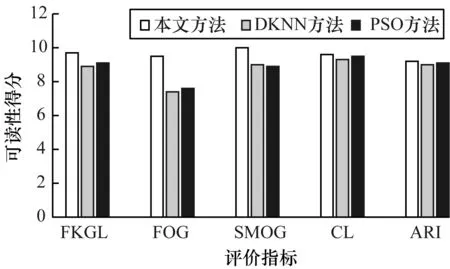
图7 3种多文档摘要方法在DUC2007数据集上的可读性得分比较
4 结束语
本文提出一种基于布谷鸟搜索优化算法的多文档摘要方法,先对输入的多个文档进行预处理,再通过输入表示和摘要表示提取文档摘要,并对摘要的内容覆盖度、衔接性和可读性进行优化。实验结果表明,与基于PSO和DKNN的多文档摘要方法相比,本文多文档摘要方法能最大化摘要信息量,降低冗余并保持可读性。后续将优化布谷鸟搜索算法的参数设置,并使用模拟退火算法、蚁群算法等启发式算法进一步提升本文多文档摘要方法的整体性能。
