基于异质网络层次注意力机制的基因功能预测
2020-07-17万美含朱扬勇
万美含,熊 贇,朱扬勇
(1.复旦大学 计算机科学技术学院,上海 200433; 2.上海市数据科学重点实验室,上海 200433;3.上海先进通信与数据科学研究院,上海 200433)
0 概述
基因是具有功能性的DNA片段[1]。由于可通过功能产物的表达或基因表达调控来影响生物体性状[2],因此确定基因的功能是生物学中的核心问题之一,其对了解疾病的生化过程、识别和验证新药物的靶点等都具有重要意义[3]。
基因组测序的快速发展使得生物数据库中基因和基因组序列的数据规模爆炸式增长,但其中有大量的基因功能仍是未知的[4]。因此,通过已有的基因特性信息对基因的功能进行预测是目前的研究热点。
目前,已有大量的基因功能预测方法被提出,总体可归为两类:一类是基于guilt-by-association原则的方法,即与相似的生物物质(如疾病)相连的基因应共享相同的功能[5],通过融合不同类型的生物数据,构建一个与基因功能相关的网络来预测基因的功能[6];另一类是基于基因本体(Gene Ontology,GO)的方法,即基因本体通过结构化的术语以分子功能、生物过程和细胞成分3种属性来描述基因,如文献[7-9]利用基因本体计算不同基因之间的相似度,实现对基因功能的准确预测。本文结合上述两类方法,将基因本体数据作为基因节点的属性,使用多种数据源构建一个基因功能相关异质信息网络。
近年来,注意力机制受到学者的关注[10],且在各个研究领域得到广泛应用。在异质网络表示学习方面,文献[11]构建了HAN模型,通过引入层次注意力机制进行异质网络节点表示学习,文献[12]在其基础上使用节点结构特征信息构建了HANE模型,但该模型仅适用于无节点属性的异质网络。本文将HANE模型扩展到属性异质信息网络(Attributed Heterogeneous Information Network,AHIN)中,构建一个具有节点属性的基因功能相关异质信息网络,并在此基础上提出基于层次注意力机制的基因节点表示学习方法HAGE。
1 相关定义
本文通过结合多种类型的公开数据集,构建一个具有节点属性的基因功能相关异质信息网络,并在该网络上应用基于层次注意力机制的网络表示学习方法,为每一个基因节点生成一个节点嵌入向量,该向量可用于后续的基因功能预测任务。对上述过程中使用的相关概念进行形式化定义:
定义1异质信息网络[13]是具有多种节点类型或(和)多种边类型的网络,表示为G=(V,E,T),其中,V是节点的集合,E是边的集合。同时,φ:V→Tv是节点到节点类型的映射,φ:E→Te是边到边类型的映射,Tv和Te是预设的节点和边的类型,并满足|Tv|+|Te|>2,T=Tv∪Te。
由于本文使用的异质信息网络是基于基因-疾病关系网络、基因-miRNA关系网络和miRNA-疾病关系网络生成的,因此其中包含3种节点类型(基因、疾病和miRNA)和3种边类型(基因-疾病关系、基因-miRNA关系和miRNA-疾病关系)[14]。
定义2网络模式[15]是定义在节点类型和边类型上的一个有向图,表示为SG={Tv,Te}。
本文构建的基因功能相关异质信息网络的网络模式如图1所示。
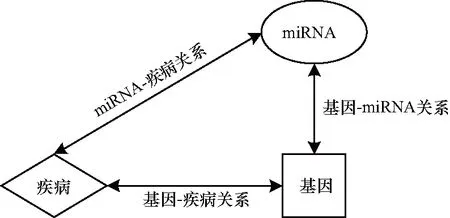
图1 基因功能相关网络模式

本文中使用的元路径及其含义如表1所示。

表1 基因功能相关网络中的元路径及其含义
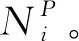
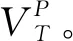

2 HAGE模型结构
在基因功能相关异质信息网络的基础上,本文提出基于层次注意力机制的基因节点表示学习方法HAGE,为每一个节点学习一个节点嵌入向量。HAGE模型主要包括3个部分,即节点特征抽取、节点层次的注意力机制和元路径层次的注意力机制。
2.1 节点特征抽取
给定一个异质信息网络G=(V,E,T)以及元路径集合{P1,P2,…,Pm},对于V中的每一个节点vi,本文从2个方面考虑该节点的特征:节点的属性信息ai以及该节点在网络中的结构特征fi。
在构建的基因功能相关网络中,基因节点属性ai来自于基因本体数据,将每个基因对应的本体术语转化为multi-hot编码并作为基因节点的属性。
对于节点网络中的结构特征fi,本文使用基于元路径的连接分布来描述。在异质网络中,不同的元路径具有不同的语义信息,因此,不同元路径下相同节点间的连接分布也是不同的。对于同一对基因节点A和B,其通过元路径基因-疾病-基因连接的路径与通过元路径基因-miRNA-基因连接的路径完全不同,并且路径的权重和数量也不同,因此,其连接分布也完全不同。
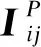
(1)
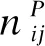
下面对连接强度矩阵IP进行归一化,作为节点结构特征矩阵FP:
(2)
最后,将每个节点vi的节点属性与其基于元路径的结构特征进行拼接并作为节点的特征向量:
(3)
2.2 节点层次的注意力机制
首先在节点层次上使用注意力机制来学习基于元路径邻居节点的重要性,并通过聚合这些拥有不同权重的邻居节点得到新的特征向量,即如果基因A具有功能f,其邻居节点中功能与功能f相同或更近似的节点应具有更大的权重,通过聚合不同邻居节点的嵌入向量及其权重来更新基因节点A的嵌入向量。
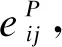
(4)
其中,anode是一个深度神经网络,代表节点层次的注意力机制。对于给定的元路径P,基于该路径的所有邻居节点共享anode。
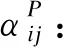
(5)
其中,σ是激活函数,W是权重矩阵,aP是基于元路径P节点层次的注意力向量。
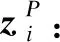
(6)
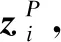
(7)
给定一系列元路径的集合{P1,P2,…,Pm},基于节点特征向量并利用节点层次的注意力机制可以得到m组新的节点特征向量{ZP1,ZP2,…,ZPm}。
2.3 元路径层次的注意力机制
基于节点层次的注意力机制可以得到不同元路径下新的节点特征向量,为得到最终的节点嵌入向量,需要对不同元路径下的节点特征向量进行融合。
在异质网络中,不同的元路径代表不同的语义信息,因此,需要为不同的元路径分配不同的权重。使用一个元路径层次的注意力机制[11]来学习不同元路径的重要程度βP。给定元路径的集合{P1,P2,…,Pm}以及基于节点层次注意力机制得到的新的节点特征向量{ZP1,ZP2,…,ZPm},为每个元路径Pi学习一个权重系数βPi,定义为:
βPi=ameta(ZPi)
(8)
其中,ameta是一个深度神经网络,代表元路径层次的注意力机制。不同的元路径将学习到不同的权重,对基因功能预测任务更重要的元路径将具有更大的权重。
为学习不同元路径的重要程度,首先对基于节点层次的注意力机制得到的节点特征向量进行非线性变换,然后将变换后的特征向量与元路径层次的注意力向量q的相似度作为元路径的重要程度。因此,对于元路径Pi,其重要程度wPi表示为:
(9)
其中,W是权重矩阵,b是偏置向量,q是元路径层次的注意力向量。
得到每条元路径的重要程度wi后,对它们进行归一化处理,得到每条元路径的权重系数βi:
(10)
对不同元路径下的节点特征向量进行融合,得到最终的节点嵌入矩阵Z:
(11)
为提高模型的精度,本文增加一个全连接层用于分类,并利用部分有标签的节点对模型进行优化,使用交叉熵作为损失函数:
(12)
其中,VL为拥有标签的节点集合,Yl为节点的标签,Zl为该节点的最终节点嵌入矩阵,C是分类器的参数。最后通过反向传播对模型进行优化,学习节点的节点嵌入向量。
2.4 HAGE算法描述
注意力的计算可以在所有节点和元路径下单独计算,因此,HAGE模型支持并行运算。给定一个元路径P,节点层次的注意力机制时间复杂度为O(VPF1F2K+EPF1K),其中,VP是节点的数量,EP是基于元路径的节点对的数量,K是多头注意力机制的数量,F1是节点特征的数量,F2是输出的节点嵌入向量的维度。总体的时间复杂度与节点数量以及基于元路径的节点对呈线性关系。
HAGE模型的算法描述如下:
算法1HAGE算法
输入异质信息网络G=(V,E,T),元路径集合{P1,P2,…,Pm},节点属性集合{ai,i∈V},多头注意力机制数量K
输出节点嵌入矩阵Z
for i∈V do
end
for Pi∈{P1,P2,…,Pm} do
for k=1,2,…,K do
for i∈V do
end
计算节点层次的特征向量
end
拼接得到节点层次的嵌入向量
end
计算元路径层次的权重系数βPi;
end
反向传播并更新HAGE模型的参数;
return节点嵌入矩阵Z
3 实验结果与分析
3.1 实验数据集
本文构建的具有节点属性的基因功能相关异质信息网络使用以下数据集:
1)使用DisGeNET[19]数据集构建基因-疾病关系网络。每条边的权重根据可靠性设为0~1,选取数据集中权重在0.3以上的3 833条基因-疾病关系来构建网络。
2)使用miRTarBase[20]数据集构建基因-miRNA关系网络。miRTarBase是一个手工收集的经过实验验证的miRNA及其靶基因关系的数据集,选取其中7 150对经过蛋白质印迹法以及报告基因分析验证的基因-miRNA关系,并将权重设为1。
3)使用2个数据集构建miRNA-疾病关系网络。第1个数据集来自文献[21]提供的242条miRNA-疾病关系;第2个数据集来自miRNet[22]数据集,选取其中疾病名称可以对应到OMIM编号的666条miRNA-疾病关系。将2个数据集进行融合,去除重复数据后,共有267个miRNA和59个疾病组成的878条miRNA-疾病关系。由于可信度较高,因此将权重设为1。
4)使用基因本体GO数据库[23-24]中得到所有基因节点的本体信息,将其作为基因节点的节点属性,共得到4 402个基因节点的基因本体信息。
5)使用MSigDB[25]基因集数据库中的基因家族作为节点的标签。MSigDB将数据库中的基因集按照PubMed中文献的定义进行分类,同一家族的基因具有相似的功能性,它们具有同源性或者生物化学活性。结果总共有1 185个基因节点获得了所属的基因家族标签。
实验数据集具体描述如表2所示。

表2 实验数据集描述
3.2 对比算法
为评估本文方法的性能,选取以下算法作为对比方法:
1)GraphSAGE[26]。GraphSAGE通过聚集局部邻居节点的特征来学习节点的节点嵌入向量。本文使用平均聚合器版本的GraphSAGE来证明为不同邻居节点以及元路径分配不同注意力的重要性。
2)GAT[27]。GAT是一个基于注意力机制的同质网络表示学习方法,其注意力系数通过单层前馈神经网络学习。本文在不同元路径上使用GAT,选择表现最好的作为最终结果。
3)HAGE w/o struc。HAGE w/o struc是HAGE的变种,其仅使用节点属性作为节点初始特征向量,不考虑节点在网络中的结构特征。
4)HAGE w/o node。HAGE w/o node是HAGE的变种,其不使用节点层次的注意力机制,仅为不同的基于元路径的邻居节点分配相同的权重系数。
5)HAGE w/o meta。HAGE w/o meta是HAGE的变种,其不使用元路径层次的注意力机制,仅为不同的元路径分配相同的权重系数。
3.3 实验设置
随机初始化模型参数,并且使用Adam[28]作为模型的优化器。其中,学习率设置为0.001,正则化参数设置为0.005,多头注意力机制数量K设置为8,元路径层次的注意力向量q的维度为128,最终的节点嵌入向量维度为128。实验运行环境为64位Linux系统,GPU为NVIDIA GTX 1080 Ti。
3.4 节点分类
本文使用Micro-F1、Macro-F1、Average Precision 和AUC作为模型评价指标,实验结果如表3所示。
由表3可以看出,在Micro-F1、Macro-F1、Average Precision和AUC这4种不同的指标下,HAGE模型的分类效果均为最优。相比于GraphSAGE和GAT 2种同质网络表示学习方法,HAGE由于考虑异质网络的特点即不同元路径具有不同的语义信息,为不同的元路径分配不同的权重,因此能够取得更好的分类性能。与HAGE w/o struc、HAGE w/o node和HAGE w/o meta相比,HAGE的分类效果均有所提升,由此表明同时考虑网络结构特征、节点层次以及元路径层次注意力机制的重要性。
3.5 模型性能分析
为分析本文模型的效率性能,构建不同规模的属性异质信息网络进行实验,结果如表4所示。
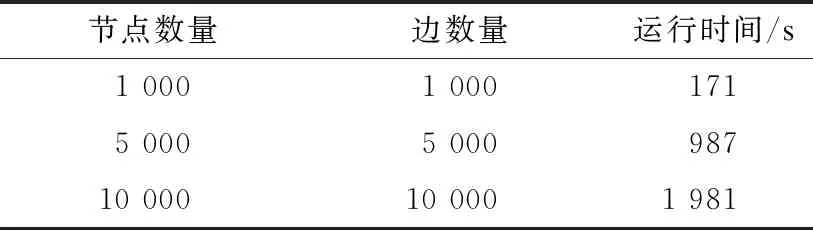
表4 本文模型时间效率
3.6 参数敏感性分析
对实验中使用的参数敏感性进行测试,研究不同参数对模型结果的影响。
1)多头注意力机制数量
为测试多头注意力机制的效果,设置不同K值进行测试,当K=1时退化为单头注意力机制,实验结果如图2所示。可以看出,随着K值的增加,AUC的值也得到提升,当K=8时模型的分类性能最好。
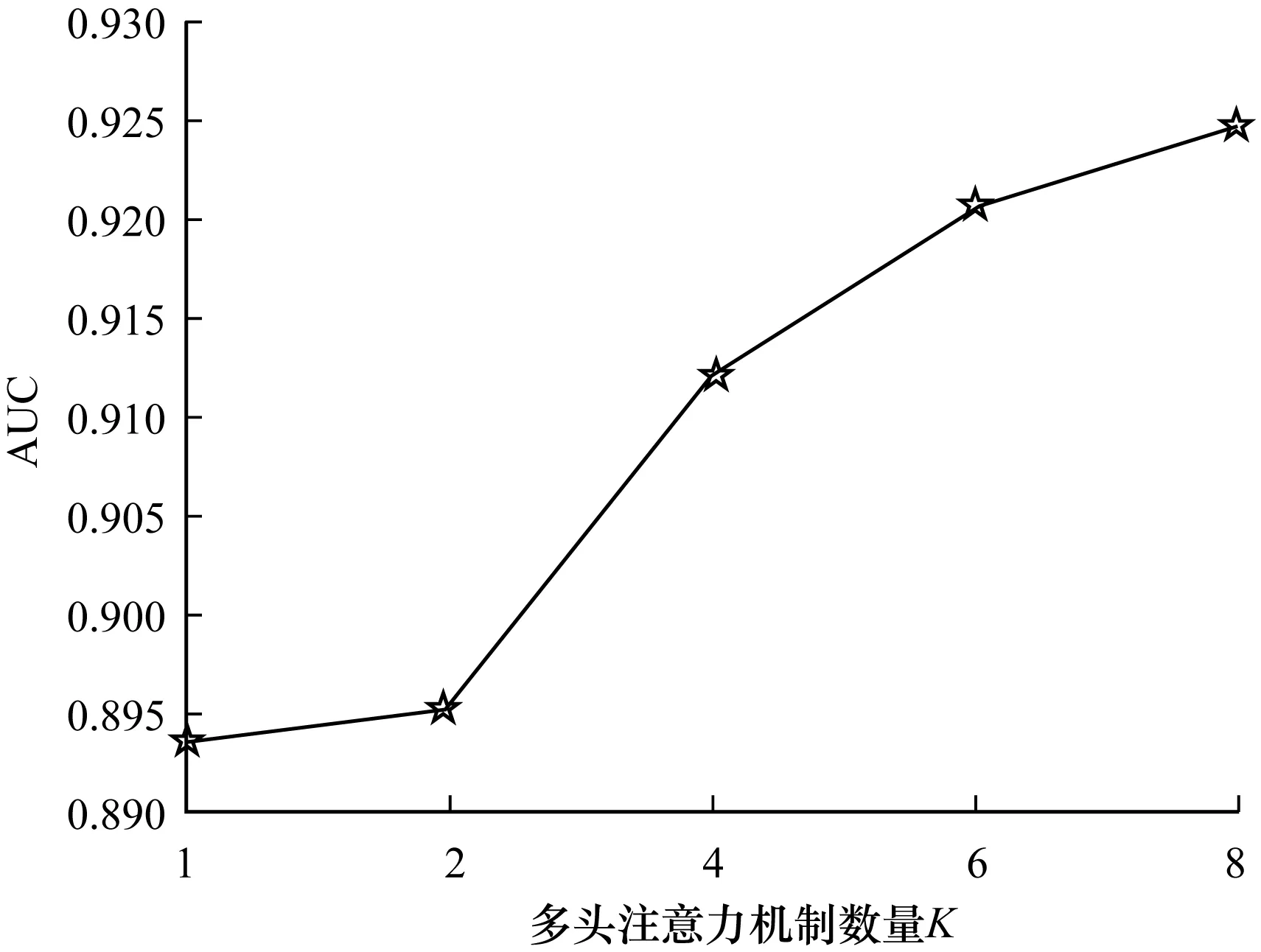
图2 多头注意力机制数量对AUC的影响
2)元路径层次的注意力向量维度
元路径层次的注意力机制的分类效果受元路径层次的注意力向量q的影响,因此,在不同维度的注意力向量q下进行测试,实验结果如图3所示。可以看出,当注意力向量q的维度为128时,模型的分类性能最好。
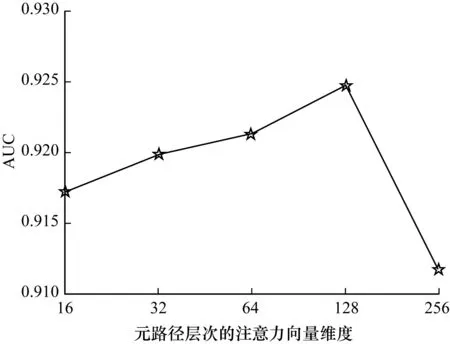
图3 元路径层次的注意力向量维度对AUC的影响
3)节点嵌入向量的维度
模型的分类效果受最终的节点嵌入向量Z维度的影响,因此对不同维度的节点嵌入向量Z进行测试,实验结果如图4所示。可以看出,模型的分类性能在维度为128时效果最好,后续随着维度的继续增加,AUC略微降低。
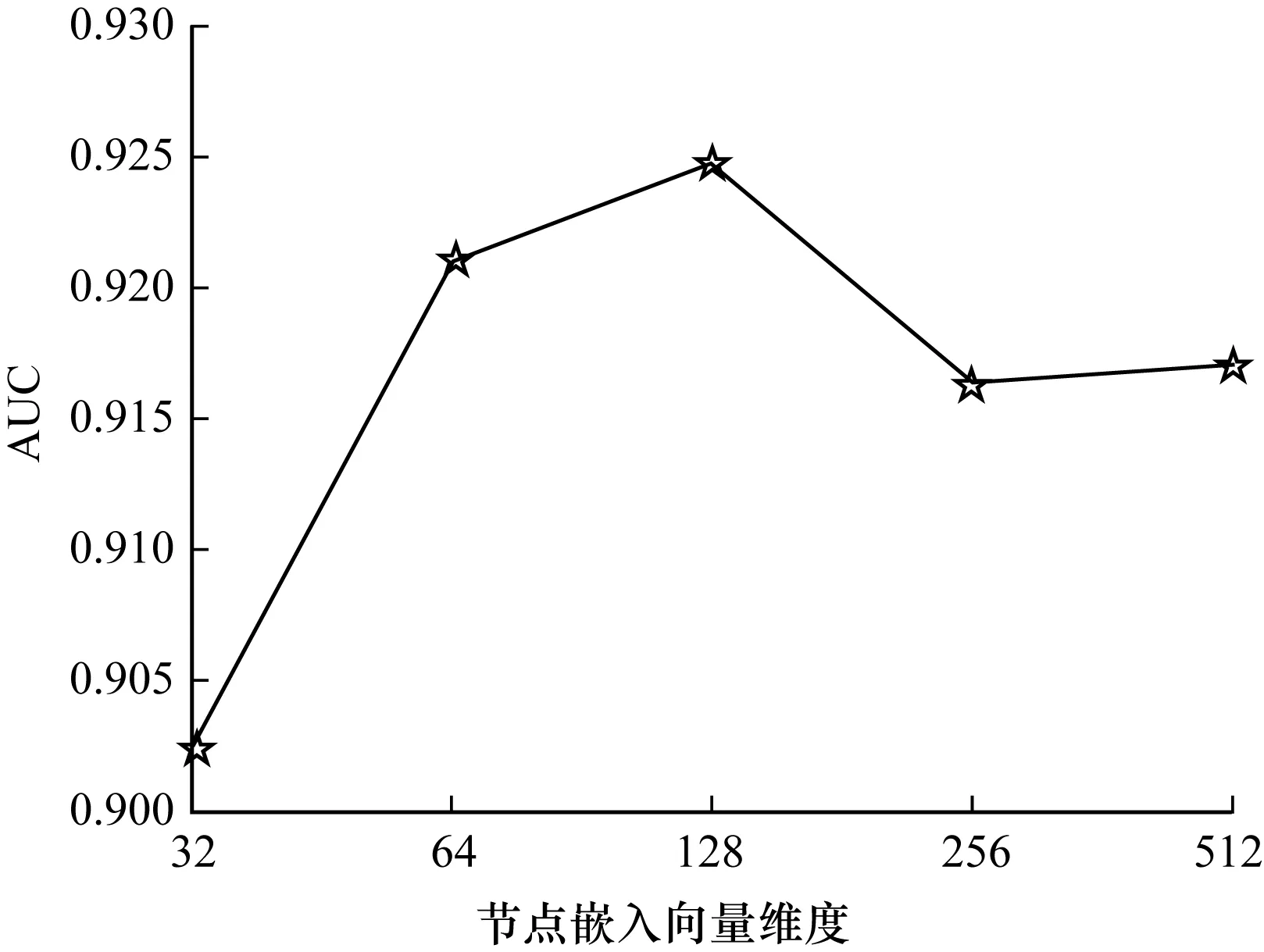
图4 节点嵌入向量维度对AUC的影响
3.7 注意力机制性能分析
在学习基因节点的嵌入向量时,本文考虑了不同元路径下的邻居节点以及元路径的重要性,并为它们分配不同的权重系数。为更好地理解权重的意义,分别从节点层次注意力机制以及元路径层次注意力机制方面进行分析。
1)节点层次注意力机制
本文以基因CHEK2为例,其基于元路径基因-疾病-基因(GDG)的邻居如图5所示,注意力权重系数如图6所示。其中,基因CHEK2、BRCA2、RB1、BRCA1和TP53同属于家族tumor suppressors(抑癌基因),RNASEL属于家族protein kinases(蛋白激酶),HOXB13属于家族homeodomain proteins(同源域蛋白),PIK3CA属于家族oncogenes(致癌基因)。
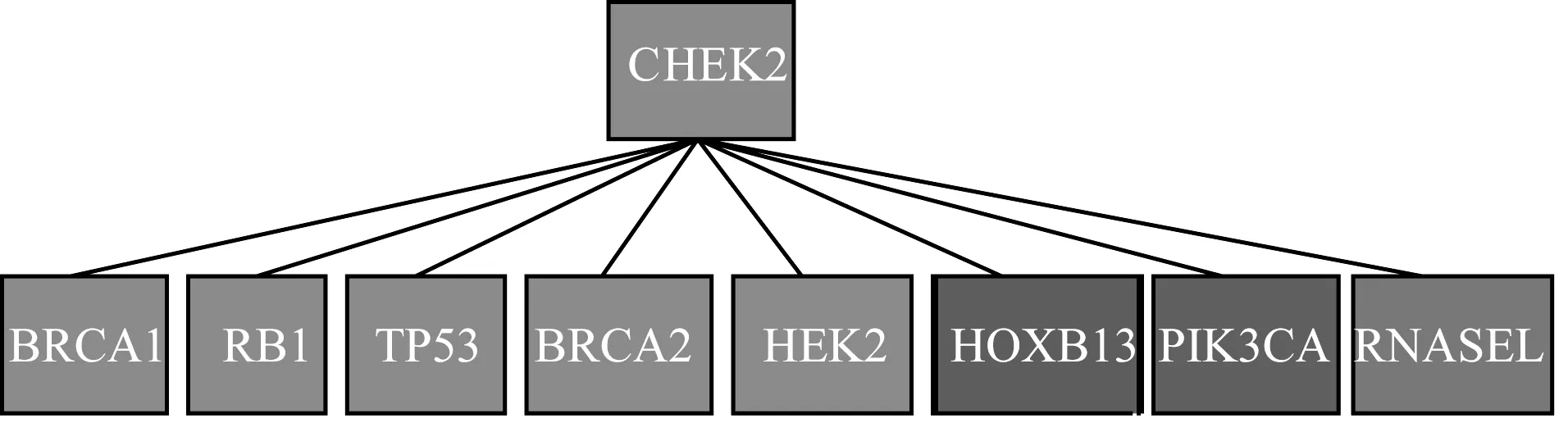
图5 基因CHEK2在元路径GDG下的邻居
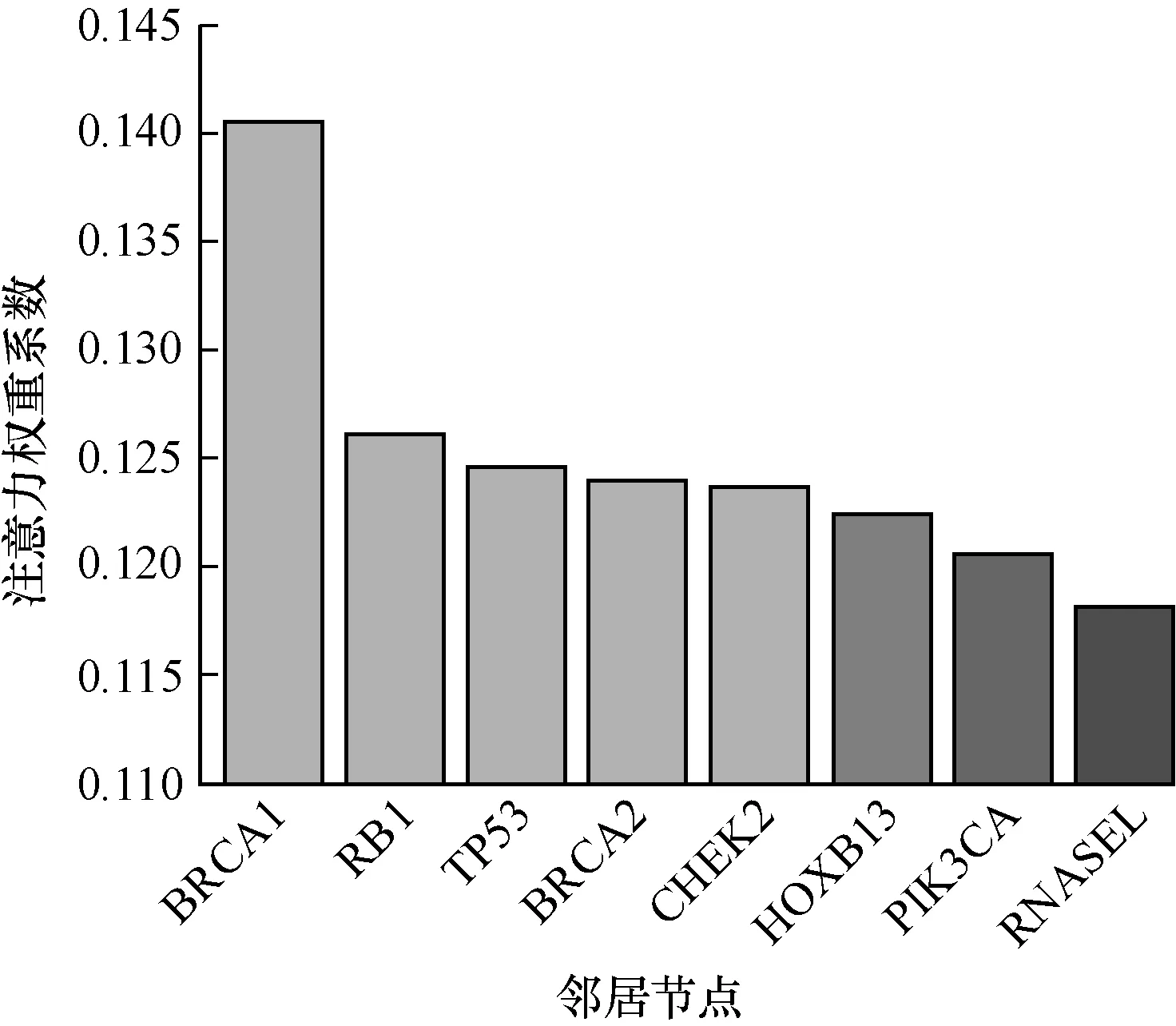
图6 基因CHEK2邻居的权重系数分布
从图6可以看出,具有相同或相似功能的同家族的邻居基因节点的权重系数较大,其他家族的邻居基因节点权重系数较小。其中BRCA1的权重最高,文献[29]指出CHEK2和BRCA1参与的DNA修复有关,与乳腺癌发生有较密切的关系,因此,它们之间的功能关联更密切。由此可见,本文模型可以较好地学习到基因节点层次的重要性。
2)元路径层次注意力机制
为分析模型学习到的不同元路径的权重系数是否反映了该元路径对基因功能预测任务的重要性,对比仅使用该元路径进行基因功能预测的结果以及该元路径的注意力权重系数,结果如图7所示。
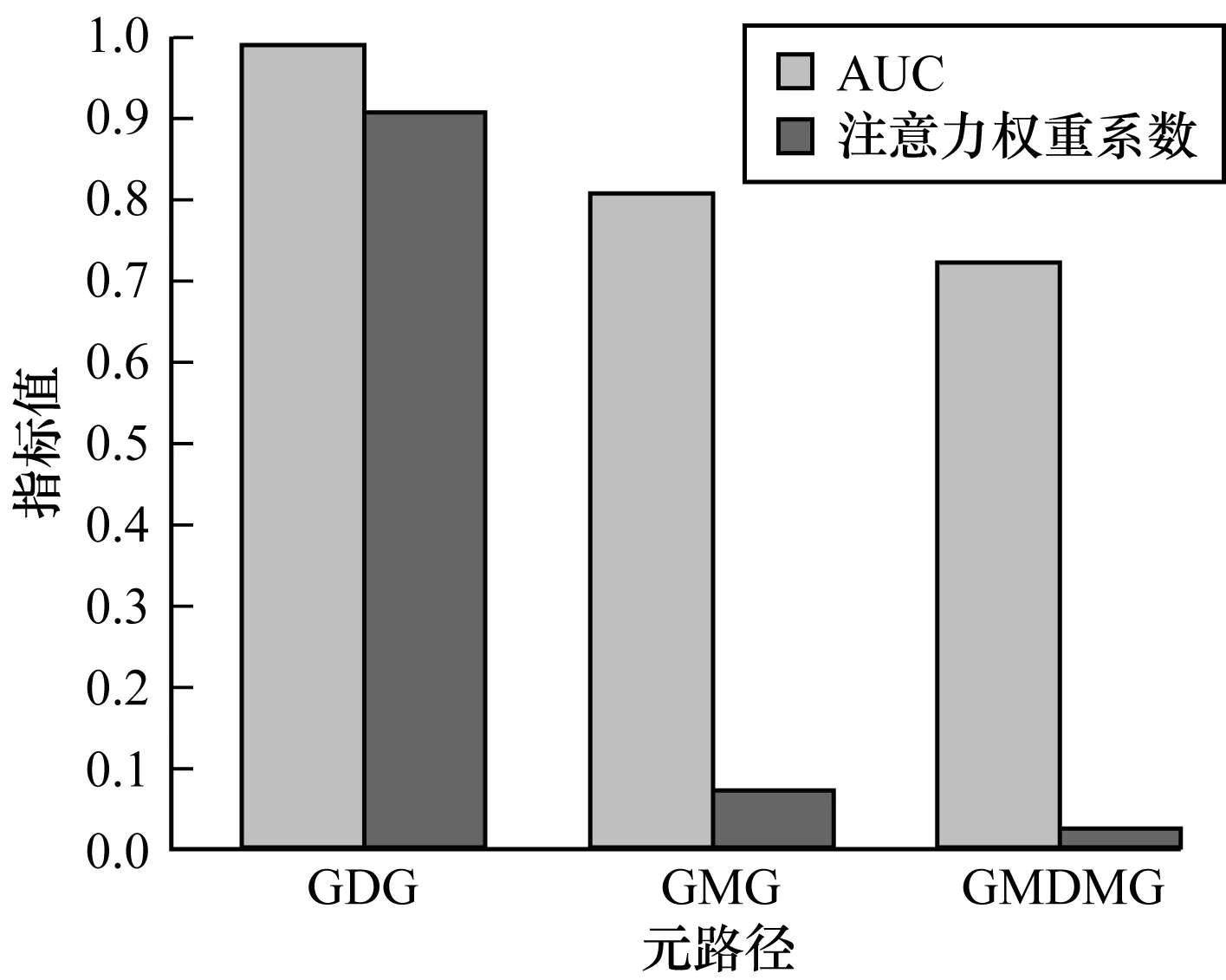
图7 3种元路径的AUC与注意力权重系数对比
由图7可以看出,单个元路径的预测结果与该元路径的注意力权重系数是成正比的,即该元路径单独进行基因功能预测时得到的AUC越高,其注意力权重系数越大。由此可见,本文模型能够较好地学习到不同元路径对基因功能预测任务的重要性。
4 结束语
本文提出基于异质网络层次注意力机制的基因节点表示学习方法HAGE。结合不同来源的数据集构建一个具有节点属性的基因功能相关网络,使用节点属性以及节点在网络中的结构特征作为节点初始向量,并通过层次注意力机制为每一个基因节点学习一个节点嵌入向量,将其用于后续的基因功能预测任务。实验结果表明,与GraphSAGE、GAT等方法相比,本文方法能够取得较好的预测效果。下一步将把本文方法拓展到不同的生物数据集中进行预测,如蛋白质交互网络、miRNA基因共表达网络和代谢网络等。
