基于卷积神经网络约束编码的图像检索方法
2020-07-13杨红菊陈庚峰
杨红菊,陈庚峰
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
近几年来,基于内容的图像检索方法被广泛应用,并得到深入研究[1-5],更是将这一成果应用到人们的生活。图像检索是基于给定一个实例,在候选数据库中寻找与之特征相似的图像,其主要包括特征提取和相似度计算。特征的表达能力对检索性能至关重要,并且其占用的磁盘存储空间和相似度计算消耗的硬件资源也会影响图像检索的效率。提取一种既具有较强区分度的图像特征向量,又能减少存储空间及相似度计算所消耗的时间,一直以来是研究者们关注的重点。
传统的图像特征提取方法在过去取得了较好的结果,例如局部二进制模式(Local Binary Pattern,LBP)[6],方向梯度直方图(Histograms of Oriented Gradients,HOG)[7],尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)[8]等,由于受到设备的限制,这些方法不能够很好的捕获到图像特征和语义信息。
基于深度学习的卷积神经网络在图像特征提取上更加高效。一些相关研究表明,基于多个非线性映射层的卷积神经网络在图像检索[1-5],分类[9-10],检测[11]等相关领域取得了巨大突破。卷积网络旨在构建输入数据和标签之间的映射关系抽取图像的整体语义信息。不仅如此,基于深度模型的循环网络在语音识别[12-13]和自然语言领域[14-15]也被深入研究。这些突破性的进展均归功于深度学习模型强大的非线性拟合能力。而基于深度学习的卷积网络在图像检索领域也有着广泛的研究和应用。Krizhevsk等人[9]利用神经网络中全连接层得到的特征进行图像检索,效果有所提升。Babenko等人[16]通过主成分分析将全连接层特征从高维映射到低维,提高了效率,但其采用的两段式特征提取方法丢失了某些潜在的语义信息,从而削弱了网络的特征编码能力。Xia等人[17]提出了CNNH的图像检索方法,首先构造图像的相似矩阵,然后将其分解得到的向量作为标签,把图像编码为维度较低的二进制向量。但是构造相似度矩阵需要消耗巨大的计算机资源。Lin等人[18]通过添加编码层更有效的学习到图像的二进制特征,设定阈值来获得输出,以此提高效率。Yang 等人[19]对编码层进行约束,提高特征编码能力。Zhu等人[20]提出DSTH方法,通过探索辅助上下文模态来直接扩充离散图像哈希码的语义,对哈希码施加离散约束,比特不相关约束和比特平衡约束,保证了语义转移并避免信息丢失。Zhong等人[21]提出AgNet不仅可以进行基于图像的图像检索还可以进行基于文本的图像检索,使得图像检索可以跨模态。不同于文献[16-21]的网络模型, Lai等人[22]使用NIN (Network in Network) 架构提取编码特征,同时使用三元损失函数将相同标签的图像映射到距离较近的空间,提取图像的编码特征,取得了较好的效果。文献[16-22]提出的方法虽然提高了图像特征的编码能力,但并没有考虑到阈值操作产生的特征损失。
本文提出基于卷积神经网络的约束哈希编码的图像检索方法(Deep Constraint Binary Code,DCBC),在 fc1层的后面添加一个分类层fc5解决由于sigmoid操作所导致的特征损失,同时添加约束到编码层以提升编码特征的区分度。
1 约束编码哈希网络架构
本节介绍约束编码网络架构及对应的损失函数,使用二进制向量替换全连接层高维图像特征向量来表示图像潜在的语义特征,并且在分类误差的基础上添加了两种损失函数更新网络权重,以便更好地提取图像的语义信息。
1.1 网络架构
卷积网络由若干个非线性映射层组成,主要包括卷积层、池化层和全连接层。输入图像经过卷积层和池化层之后得到相应的特征图。卷积层[23](Convolution layer,conv)通过卷积核提取图像的局部特征,例如纹理、颜色等。池化层(Pooling layer,pool)对卷积层的特征图进行下采样操作。全连接层(Fully Connection layer,fc)将卷积层的特征图扁平化处理,由三维的特征图转化为一维的向量,实现局部语义信息到全局特征的转换。

图1 约束编码网络架构图
约束编码网络架构如图1所示,主要包含卷积层和全连接层。卷积层的网络架构和AlexNet网络相同,卷积核提取图像的三维局部纹理特征,将输入图像通过最大池化层进行下采样操作。最后一个卷积层和第一个全连接层fc1连接,该层有4 096个神经元,使用一维向量刻画图像的全局语义信息。fc1后包含两个分支,一个将图像编码为维度较低的哈希特征,称之为fc2层。fc2层将高维的全连接层编码为低维的特征向量。fc3层使用非线性sigmoid将fc2层的神经元编码为0到1之间,fc3层也称之为编码层。fc4的神经元个数和图像的类别相同,用于图像分类。另一个分支直接在fc1后添加一个分类层fc5,该层的神经元个数和fc4相同,防止由编码层的级联低维映射和sigmoid函数造成的编码特征损失。
约束编码网络在编码层fc3的基础上添加相应的约束条件提升编码特征之间的区分度。同时在fc1层后又添加一个fc5层,解决编码层的低维映射和非线性映射产生的分类误差。在测试阶段,给定输入图像I,对应的编码特征如式(1)所示。
(1)

1.2 损失函数
约束编码网络的损失函数主要由分类损失、编码约束和编码损失组成。编码约束对编码层的特征向量添加相应的约束条件,提升编码层向量和其他类别特征的区分度。编码损失是指由编码层产生的分类误差,本质上是一个分类损失。
1) 分类损失:分类损失就是预测标签和真实值之间的误差。如表达式(2)所示:

(2)
其中zj表示分类层中第j个神经元的激活值,m代表神经元的个数,即图像类别。
2) 编码约束: 编码层的特征由fc2层经过非线性映射sigmoid计算得到,神经元的数值分布在0到1之间。每个神经元的数值表示对某个潜在语义特征的刻画程度。数值越大,表示该图像对应的特征表现能力越强。例如,当前的神经元数值为0.01,表示该图像不具备该特征,对应的0.9则反之。由于神经元的变化范围较小,不同类别图像特征之间的区分度较低,导致特征编码能力较弱。为了提高特征的编码能力,需要尽可能地提高不同类别图像特征之间的区分度。
编码约束旨在增强图像特征的区分度,如果该图像并不具备某个语义信息,则强制其神经元的编码数值趋近于0,而不是在保持在0.5这种中立的状态。本文通过最大化编码层特征和0.5之间的欧式距离解决该问题。如式(3)所示:i表示图像的索引,N表示批处理的大小,w表示网络的训练参数。

(3)
公式(3)虽然能够增强编码特征的区分度,但是却会出现每个神经元的数值全部都趋向于0或者1这种特殊情况,削弱网络特征的编码能力。本文通过最小化编码层的特征均值与0.5之间的欧式距离以解决该问题。如表达式(4)所示,其中mean表示求均值操作。

(4)
综合式(3)和(4)得到最终编码约束,如公式(5)所示。由于公式(3)和公式(4)的优化方向不一致,因此在目标函数的优化过程中,将公式(3)取反和公式(4)相加得到编码约束的损失函数。可以认为公式(4)是公式(3)的约束条件。
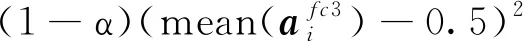
(5)
3) 编码损失:编码损失是指由编码层产生的分类误差。从sigmoid曲线图可以发现这种非线性映射会导致梯度消失,如果将这些低维映射进行级联则会损失分类精度。本文通过建立分支网络,在第一个全连接层fc1后添加一个分类层fc5,并计算分类误差来解决问题。
L(w;α)=L(cls-fc4)+L(cls-fc5)+αL(constraint)
(6)
综上所述,网络的总损失由分类误差L(cls-fc4),编码约束L(constraint)和编码损失L(cls-fc5)三部分组成。如公式式6所示,其中α表示编码约束对应的损失权重。本文将在第2节研究该参数的选定对网络分类的影响情况。
2 实验
本文实验基于开源的深度学习框架Caffe[24]实现,采用随机梯度下降优化目标函数。其中每个批处理大小为64,学习率0.001,momentum为0.9,权重衰减因子设定为0.000 5, 全连接层中dropout因子设定为0.5,使用ImageNet数据集训练得到的权重[9]初始化网络的卷积参数,超参数α设置为0.8。对于深度哈希的方法,训练网络时统一把图像放缩为256×256,直接使用原图像提取特征,对于非监督学习方法均采用512维的GIST[25]特征学习哈希编码特征。
2.1 实验数据
CIFAR-10:常用的分类数据集之一,该数据集共包括6万张图像,分为10个类,每个类有6 000张图像,其中50 000张训练样本和10 000张测试样本,大小为32×32。数据集总共有6个批次,其中5个为训练批次,剩余1个为测试批次,每个批次下有10 000个图像。从每个类别下随机选取1 000张图像作为测试集。把每个类别下剩余的5 000张图像随机分配到5个训练集上,可以不等份的进行分配但保持每个批次下的总数不变。5个训练集之和包含来自每个类的正好5 000张图像。
Caltech-256:是一个物体识别数据集也用作分类,该数据集是加利福尼亚理工学院收集整理的数据集,该数据集选自Google Image 数据集,并手工去除了不符合其类别的图片。数据集包含257个类别,总计图像个数30 607张,从每个类别中选出10张图像作为测试集,其他的作为训练集。在检索过程中,使用测试集合的数据作为待查询样本,训练集的数据作为候选样本。
2.2 性能评估
本文使用查准率和平均查准率(mean Average Precision,mAP) 作为网络性能的评估指标,如公式(7),(8)所示,分别为查准率和平均查准率。通过和DH(Deep Hashing)[18],SSDH(Supervised Semantics-preserving Deep Hashing,SSDH)[19],ITQ(Iterative Quantization,ITQ)[26],LSH(Locality-Sensitive Hashing,LSH)[27]编码方法的比较。LSH深度哈希编码方法在网络的后端插入一个全连接层,SSDH仅对编码特征进行了条件约束,学习图像的哈希编码。
precision=(a/b)×100%
(7)
a表示检索属于同一类别的个数,b表示检索图像总数。

(8)
|Q|代表查询个数,j代表查询索引,mj表示检索图像个数,k表示相似度排序的图像索引,count(k)代表索引k之前的实例中,标签正确的图像个数。平均准确率可以理解为精确度曲线和召回率曲线所形成的面积。精确率表示检索返回的样本中正样本的个数返回图像个数的比例,召回率表示检索返回的样本中正样本的个数和数据库中总的正样本个数的比例。理想情况下精确率随着召回率的增长而变大,但实际情况下两者往往成反比。
2.3 CIFAR-10
本小节使用CIFAR-10数据集评估约束编码网络的分类和检索性能。分别采用24、32、64位的编码特征表示图像潜在的语义信息。
如图2a所示,表示检索返回的图像个数和检索精确度,从图中可以看出,本文的DCBC编码方法在检索精确度上明显高于SSDH和DH方法。对于编码位数是否会影响检索精确度,本文分别测试了24、32、64位编码特征下的精确度。如图2b所示,发现检索精度随着编码位数的提升而增加,并且在其他方法上也有相同的效果。
表1表示不同方法在CIFAR-10上的平均查准率。通过数值数据表明相比于传统LSH和ITQ哈希方法,本文DCBC编码方法具有很大的优势。通过与DH和SSDH深度哈希方法的比较,DCBC编码也具有更好的查准率。对于SSDH,高出0.32个百分点,这是因为在对编码进行特征约束的同时也考虑到所产生的特征损失。

表1 CIFAR-10数据集上的平均准确率
为了明确参数α对网络分类性能的影响,选取64位编码特征进行实验。由于编码约束两部分的损失权重和为1,所以本文将仅仅对一部分进行分析验证。
如表2所示:表示编码约束权重α对网络分类性能的影响, 本文分别设定α为0.2,0.5,0.8和1.0。可以发现在α=0.5时,网络的分类性能最好,当α=0.8时,分类性能稍微比0.5下降一点,但也有一个相对较好的分类性。但是当α=1时,分类性能有所下降,这是因为α的作用是增加提取特征的区分度,使得编码层的神经元激活值距离0.5越远越好。当α=1时,神经元的激活值几乎全为0或1,导致梯度消失从而降低了网络的特征编码能力。当a=0.2时,神经元的激活值又几乎全为0.5,这样使得网络丧失区分特征能力。实验表明通过对哈希编码进行约束,可以增加特征区分度以及提高特征提取能力。
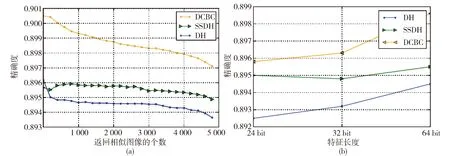
图2 CIFAR-10的检索精度示意图

表2 CIFAR-10分类精度
2.4 Caltech-256
如图3a和3b所示,在Caltech-256数据集上进行相同的实验,发现SSDH在相似图像的个数上的平均查准率和在不同特征长度的精确度高于DH和SSDH。
本文对不同长度的编码特征在平均查准率上进行评估,从表3可以看出在数据集Caltech-256上,SSDH的平均查准率低于DH,而DCBC约束编码的平均查准率依然高于另外的两个方法,表明本文提出的编码方法学习到的图像特征表达能力要优于SSDH和DH。

表3 Caltech-256平均查准率
2.5 DCBC编码特征数值分布直方图
为了可视化DCBC编码网络中编码层的神经元数值分布,本文从Caletch-256三个类别下随机选出三张图像分别在DH,SSDH,DCBC方法下实验得到他们的编码层的特征值直方图,如图4所示。第一列代表原图,二三四列分别表示的是DH,SS-DH,DCBC模型分布图。从图中可以发现DCBC方法在0和1两端有一个较均匀的分布,而SSDH和DH则都集中于两端。从第一张图AK47的直方图中,可以发现DCBC学习到的特征分布在0.1~0.3和0.7~0.9之间,而其他的两种方法学习到特征都偏向于0.1和0.9。无论是图3的检索精确度还是图4中的特征值分布,直观地显示了本文DCBC编码方法能够更好地学习到图像的语义特征。
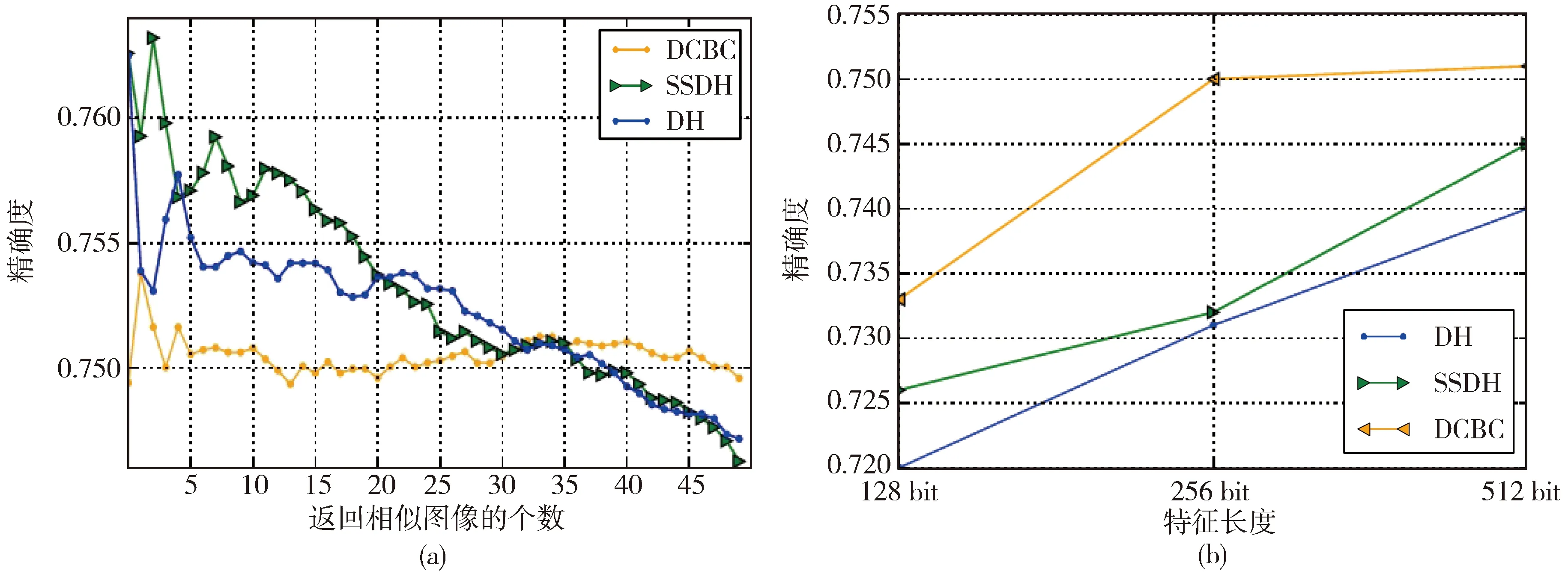
图3 Caltech-256的检索精度示意图

图4 不同编码方法产生的二进制特征的数值分布直方图
以上在数据集CIFAR-10和Caletch-256上的实验表明,本文的基于卷积神经网络约束哈希编码的检索方法有一个更好的处理效果。同时将阈值操作和编码约束产生的损失用于更新网络权重,有利于网络学习到更加有效的特征。
3 小结
本文在传统的深度哈希编码网络中添加了两个全连接层提取图像的二进制特征:在使用编码约束提升特征之间的区分度的同时使用编码损失防止产生梯度消失的风险。下一步,我们将寻找一种更为合适的损失函数,并且引入attention 模型[28-29]对于不同的图像区域赋予不同的权重进行特征编码,进一步提升图像的特征表达能力。
