基于LPCNet的语音合成方法研究∗
2020-07-13陈小东宋文爱刘晓峰
陈小东 宋文爱 刘晓峰
(中北大学软件学院 太原 030051)
1 引言
语音合成(Speech Synthesis)泛指将输入文本或音素序列映射输出为音频信号的技术。传统的语音合成方法,如参数式语音合成[1],使用参数模型对文本进行建模并从中生成语音,通常由文本分析前端、声学模型、持续时间模型和用于波形重建的声码器组成,需要广泛的领域专业知识来进行研究;拼接式语音合成[2],从语音库中挑选适当的语音单元,然后拼接以形成输出,但其需要的音库一般较大,灵活性有限。
近年来随着深度学习的不断发展和应用,基于Seq2Seq结构的模型被多个语音合成模型证明优于传统结构。Wang[3]等最早使用带有注意力机制的Seq2Seq方法尝试语音合成系统,但是需要一个预训练的HMM模型用于对齐;百度DeepVoice[4]的做法是仿照传统参数合成的各个步骤,将每一阶段分别用一个神经网络模型来代替;Char2Wav[5]可以直接输入英文字符进行合成,但仍是预测出声学参数,需要使用声码器进行合成语音;邱泽宇[6]等利用Seq2Seq架构,实现了中文的语音合成。Taco⁃tron 2[7]可以直接从图形或音素生成语音,该模型首先由一个循环Seq2Seq的网络预测梅尔声谱图,然后由一个改进的WaveNet[8]来合成这些声谱图的时域波形。WaveNet是一种基于神经网络的自回归方法,使用一种新的扩展因果卷积结构捕获语音信号中的长期时间依赖关系。WaveNet作为一个语音合成后端的模块,将前端字符映射为音素等一些人工的语言学特征转化为语音波形输出,它比传统WORLD[9]声码器更好地重构了原始语音中的相位信息,可以实现高质量的合成语音。但是这种自回归模型合成速度缓慢、复杂的网络结构,并且需要较大的模型尺寸。
本文针对Seq2Seq语音合成模型中WaveNet合成语音缓慢、网络结构复杂等问题,提出一种基于LPCNet[10]模型的语音合成方法,LPCNet模型基于WaveRNN[11]改进,它将神经网络合成与线性预测相结合,使用神经网络预测声源信号,然后应用LPC滤波器对其进行滤波,确保合成高质量语音的同时提高语音合成效率。
2 模型架构
本文提出的模型主要由两部分组成,一个引入注意力机制的Encoder-Decoder(编码器-解码器)框架声学模型,用于从输入的字符序列预测梅尔声谱的帧序列;一个LPCNet模型作为声码器,基于预测的梅尔声谱帧序列生成语音波形。
本文采用梅尔声谱图作为声学特征。以中文带调拼音序列作为输入,通过编码器首先将其转换为嵌入语言特征的隐层表征,然后在每一个解码步骤中通过注意力机制将其传输到解码器,解码器的递归网络接受隐层表征用以预测梅尔声谱图。最后,预测的梅尔声谱图通过LPCNet模型合成目标语音。图1显示了模型的总体架构。
2.1 注意力机制
注意力机制近年变得非常流行,并且在机器翻译[12]任务上表现得非常好。在语音合成中注意力机制有助于联合学习输出声音特征和输入序列映射的对齐。Tacotron2中,采用的是位置敏感注意力机制[13]。本文建议用Transformer模型[14]中更简单的Query-Key self attention来代替这种注意力机制。因为Query-Key self attention不仅能在训练过程中快速的学到对齐,而且比位置敏感注意力机制需要更少的参数。
在声学模型中,编码器中的元素序列由一系列的

图1 模型架构
给定 Q(Query)、K(Key)、V(Value),每个解码步骤的注意力概率通过点积计算。在使用点积运算进行相似度计算的基础上,缩小了d倍(d为输入字符的维度),其目的在于调节作用,使得内积不易过大。

其中T表示编码器中元素序列的长度。
2.2 声学模型
声学模型采用基于Seq2Seq的梅尔声谱图预测网络,主要由图1中的编码器和引入注意力机制的解码器两个神经网络组成,将输入序列转换为对应的梅尔声谱图。编解码器组合作为一个整体的网络,与传统的声学参数统计模型相比,能更准确的生成声学特征。
设y=[y1,y2,...,yt]表示网络输出的梅尔频谱序列。特征预测网络使用每个输出帧yt的条件分布来建模输入和输出特征序列之间的映射关系为
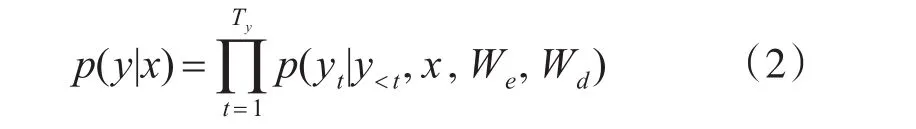
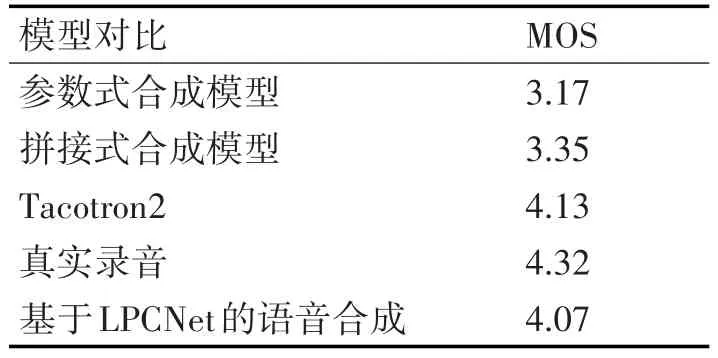
给定之前的输出帧y 编码器首先将输入拼音序列转换为512维的字符向量,然后通过三个卷积层对输入字符序列的上下文进行建模,每层卷积包含512个5×1的卷积核,后接批标准化(batch normalization)[15]和 ReLU激活函数,最终卷积层的输出被输入到双向LSTM层以生成编码特征。编码器将输入的字符序列x=[x1,...,xTx] 转 换 为 隐 藏 特 征 表 示 序 列h=[h1,...,hTh],如下所示: 具有注意力机制的解码器利用h,在输出帧上产生概率分布为 构建一个注意力机制接受编码器的输出,编码器的每次输出,注意力机制都将编码的序列概括为一个上下文向量c。在每个解码器步骤上使用注意力概率计算上下文向量c 解码器根据上下文向量c来预测输出梅尔声谱图的帧序列。首先将上一步预测出的声谱帧输入到双层全连接的“Pre-net”,每层有256个隐藏Relu单元以学习注意力,并在卷积层后应用概率为0.5 的 Dropout[16]进行正则化处理。然后,将上下文向量c和Pre-net的输出通过两个具有1024个单元的单向LSTM层,其中LSTM层之后是两个预测“完成概率”和目标频谱帧的投影层,用于预测完成概率表示生成后的序列是否到达最后一帧。在训练过程中,如果该概率超过0.5,就会自动停止生成声谱帧。 最后,为了提高生成精度,引入了5个卷积层的“Post-net”作为后处理网络,每层由512个5×1卷积核和一个批标准化处理组成。Post-net利用双向上下文信息对解码器预测的梅尔声谱图进行了细化,最后一层的输出叠加到卷积前的频谱帧上产生最终的结果。设 z=[z1,...,zTz]表示Post-net输出序列,这是模型的最终预测。在给定编解码器网络y输出的情况下,特征序列z的分布被建模为 其中Wp表示Post-net的参数。 声码器作用于从声学特征重构语音波形,是语音合成模型至关重要的一部分。传统基于数字信号处理的声码器速度很快,但是合成的语音质量较差,而基于神经网络的声码器语音质量更高,但在许多神经语音合成方法中,神经网络必须对整个语音生成过程建模,通常复杂度太高,无法实时。其中WaveNet利用自回归方法对一个数据流X的联合概率分布建立模型,对数据流X中的每一个元素x的条件概率求乘积。该模型使用过去的样本预测序列的当前值,对于一段未处理音频xt,构建的联合概率函数为 其中N为语音样本数量,h为影响分布的辅助特征,由于生成模型的自回归特点,WaveNet的生成速度非常缓慢。 根据Source-Filter(源-滤波器)的语音产生机理,语音产生过程主要分为激励源、声道响应两个独立的模块。在神经语音合成方法中,大多数由神经网络整体模拟激励源、声道响应,但实际上在建模时,用一个简单的全极点线性滤波器[17]就可以很好地表示声道响应,而使用神经网络实现却非常复杂。因此LPCNet模型以WaveRNN为基础加入LPC滤波器模块降低神经网络的复杂度,将对整个语音采样值建模的过程分解成线性和非线性两部分,线性部分通过基于数字信号处理的线性预测给出,神经网络仅需建模较小的非线性部分,这样就可以简化神经网络声码器。 语音相邻样本点具有很强的相关性,通常假设语音采样值是一个自回归过程,即当前时刻样本值可以近似由相邻历史时刻的样本值线性表示,设St为时间t时的信号,其基于之前样本的线性预测为 其中,ak是当前帧的线性预测系数,通过将梅尔频谱转换为线性频率功率谱密度,利用一个逆快速傅里叶变换将线性频率功率谱密度转换得到一个自相关函数,最后通过Levinson-Durbin算法计算得到。 把残差信号当作激励源,使用神经网络可以直接预测残差,通过由线性预测系数构成的全极点滤波器便可以恢复原始语音。为了和声学模型的输出保持数据一致性,将梅尔声谱图作为LPCNet的声学特征输入。LPCNet将数字信号处理和神经网络结合应用于语音合成中的声码器,可以在普通的CPU上快速的合成高质量语音,训练过程也会变得更加高效,有很好的研究意义。 实验操作系统为Ubuntu 14.04.1,显卡使用NVIDIA GeForce GTX 1080Ti,处 理 器 为 Intel i7-5200U,内存为8G,主频为3.2Hz,程序运行框架为Tensorflow 1.3.0平台。 实验使用了一个由一位专业女性演讲者录制的语音和韵律都很丰富的普通话语音数据库。数据库由5000个话语以及相对应的文本拼音标注组成(约6小时,分为训练、验证和测试三个子集,分别为4000,700和300个话语),数据采样率16kHz,位数16bit。 实验采用80维梅尔声谱图作为声学特征。为了计算梅尔声谱图,首先使用50毫秒帧大小,10毫秒帧移和汉明窗口函数对音频执行短时傅里叶变换。然后,使用范围从125 Hz~7.6 kHz的80个梅尔滤波器将STFT幅度谱转换为梅尔刻度,最后通过对数函数进行动态范围压缩。Ad⁃am优化器指定参数β1=0.9,β2=0.999,学习率初始设置0.001。批次规模(batch size)为32,使用预测和目标谱图之间的L2距离作为损失函数来训练整个网络。 为了减少误差,在训练过程中,通过教师强迫(Teacher force)[18]的方式训练模型,在解码步骤提供真实的梅尔声谱图,而不是模型预测的梅尔声谱图。为了保证该模型能够长期对序列进行学习,将教师强迫比从1.0(完全教师强迫)退火到0.2(20%教师强迫)。 实验分别使用客观和主观两种测试方式来评估合成语音的质量。首先,采用MOS评分法[18~19]对模型进行主观评估,MOS指标用来衡量声音接近人声的自然度和音质。将语音合成模型生成的样本提供给评估人员,并按1(差)到5(优)打分,分值间隔0.5,然后计算分数的算术平均值即为最终的MOS分数。 表1 不同模型的MOS评分对比 本文对参数式模型和拼接模型,以及Tacotron2模型做了对比,使用这些模型分别合成一组20个句子,并通过MOS测试将它们的得分与原始录音进行比较。每个句子由30名不同的测评者进行评估,表1显示了测试的结果。 由表1可知,基于LPCNet的语音合成模型和Tacotron2模型所生成的语音质量明显高于传统的参数式和拼接式合成模型,原因在于这两个模型的声学模型部分都是基于Seq2Seq的特征预测网络,它能更好地学习到声学特征。另外,它们的MOS得分几乎相等,并且接近于真实录音的分值,说明它们在合成语音的质量上都很优异,但是LPCNet模型的复杂度比Tacotron2的模型要低得多,所以基于LPCNet的语音合成模型比Tacotron2更高效。 对于客观评估方式,本文使用MCD(Mel Ceps⁃tral Distance)梅尔倒频率失真度[20],它通过测量预测梅尔倒谱与真实梅尔倒谱之间的距离来评估合成语音与真实语音的质量差距,距离越小越好。测试使用包含大约20min(300个句子)的验证集。 表2 不同模型的MCD值对比 从表2中可以看出,LPCNet模型的MCD值略小于Tacotron2模型,相比参数式模型和拼接式模型,表现则更为优异,可以得出基于LPCNet的语音合成模型合成的语音质量更接近于真实语音,相比其他三种模型合成的语音更自然。 为了确定不同声码器之间的性能差异,本文对声码器部分做了一个对比研究,同时采用前文介绍的声学模型,分别对参数化WORLD声码器和常规WaveNet声码器合成的语音样本进行了评估,其中WORLD声码器的中间声学参数包括基频、频谱包络和非周期性参数。 图2 各类声码器MOS评分 从图2可以得出,LPCNet与WORLD相比,在语音质量上有着巨大的差异,相比WaveNet还略有欠缺。然而,因为特殊的卷积框架和自回归采样方式,WaveNet具有缓慢的合成速度。而LPCNet结构更简单,合成速度更快,同样可以生成高质量的语音,所以LPCNet模型作为声码器合成语音的效率更高。 另一方面,测试合成验证集话语时,基于LPC⁃Net模型的方法平均生成3000个样本/s,相比之下,自回归采样的WaveNet方法平均产生257个样本/秒。本文所提出的方法合成语音的速度显著提高,它通过数字信号处理技术和神经网络的结合,使得合成语音速度比WaveNet更快,所以该方法有效解决了WaveNet神经声码器合成语音缓慢的问题。 本文提出一种基于LPCNet模型的语音合成方法,将梅尔声谱图作为声学特征,首先利用Que⁃ry-Key self attention注意力机制的Seq2Seq网络将输入字符转换为梅尔声谱图,然后将所生成的梅尔声谱图通过LPCNet模型进行语音波形的重构,生成了高质量的语音。经过研究得出以下结论: 1)本文基于LPCNet模型的语音合成方法,降低了基于Seq2Seq结构语音合成的模型复杂度。 2)通过将数字信号处理技术和神经网络相结合,合成语音的速度大大加快,实现了高效的语音合成。 3)将LPCNet模型作为声码器,合成的语音质量接近于WaveNet,并显著高于WORLD声码器。 4)与传统的参数式和拼接式语音合成模型相比,本文提出方法的合成语音主观评测MOS分数更高和客观评测MCD值更低。
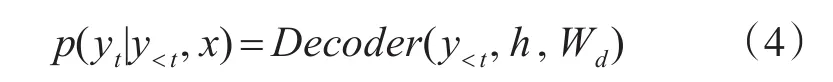
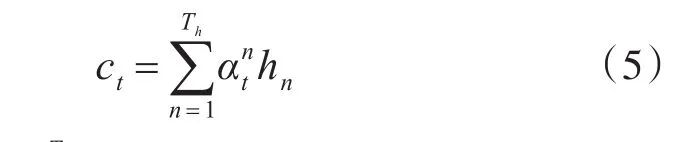
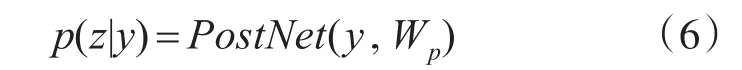
2.3 声码器

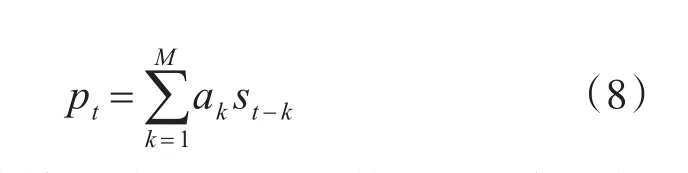
3 实验与分析
3.1 基本设置
3.2 实验评估

3.3 对比研究

4 结语
