MapReduce和Spark两种框架下的大数据极限学习机比较研究
2020-07-13宋丹丹翟俊海齐家兴
宋丹丹, 翟俊海,2, 李 艳,2, 齐家兴
1(河北大学 数学与信息科学学院,河北 保定 071002) 2(河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071002)
1 引 言
极限学习机(Extreme Learning Machine,ELM)是Huang等[1]提出的训练单隐含层前馈神经网络的一种算法,它与传统的算法不同,随机生成输入层到隐含层的连接权和隐含层结点的偏置,随后用Moore-Penrose伪逆方法求解隐含层到输出层的权值.研究人员只需手工控制隐含层节点的个数,调整参数的过程无需人工干预,收敛速度快,泛化能力强.
近十年来,ELM的理论和应用有了很大的发展.Huang等[2]证明了ELM具有很好的SLFNs通用逼近能力,利用常见的激活函数,就能够学习到所有参数,能够得到传统FNN的最优泛化边界.Wang等[3]利用初始局部误差模型(LGEM)研究了ELM的泛化能力.为应对不同的实际应用,研究人员提出了多种ELM的变体.例如,在ELM分类器优化方面,Bai等[4]提出了一种稀疏ELM(S-ELM),用不等式约束代替了传统ELM模型中的等式约束,大大减少了存储空间和测试时间.与支持向量机相似,带有不等式约束的S-ELM也会导致二次规划问题.然而,由于没有涉及偏置项,S-ELM在训练中比svm更有效.翟等[5]提出了一种改进灵敏度分析的在线自适应极限学习机算法,该算法引入了新型的计算灵敏度的方法,降低了算法复杂度和训练时间并提高了预测精度.在集成方面,Lan等[6]提出了一种在线序列ELM(EOS-ELM)集成,该集成以多个独立训练的OS-ELM的平均预测作为最终预测.EOSELM进一步提高了OS-ELM的预测精度,实现了ELM算法在线序列数据方面的扩展.翟等[7]提出了一种用模糊积分集成重复训练极限学习机的数据分类方法,与其他集成ELM不同,该方法能很好地刻画ELM基本分类器之间的交互作用,而且具有更好的泛化性能.处理噪声或缺失数据方面,Horata等[8]提出了三种改进的ELM算法:1)基于迭代重加权最小二乘(IRWLS-ELM)的ELM算法;2)基于多元最小边缘平方(mlt-ELM)的ELM;3)基于一步重加权mlt(rmlt-ELM)的ELM.在IRWLS中,通过M-estimate函数对训练数据进行迭代加权,通过降低异常值的权重,可以逐渐减小异常值的影响.在MLTS-ELM和RMLTSELM中,引入了基于最小协方差行列式(MCD)估计的多元最小二乘估计(MLTS),提高了ELM对异常值的鲁棒性.Man等[9]提出了一种基于有限脉冲响应的ELM模型,模型的输入权用有限脉冲响应滤波器方法确定,提高了ELM对噪声数据鲁棒性.在无监督学习方面,Huang等[10]将ELM推广到半监督和无监督学习的场景,提出了半监督ELM和无监督ELM,极大地扩展了ELM的适用性.Heeswijk等[11]提出了一种基于GPU加速的并行ELM集成方法,并用于解决大规模回归问题,取得了良好的效果.在ELM算法的表示学习方面,Kasun等[12]提出了一种基于ELM的表示学习的自编码器,该自编码器使用ELM学习的自编码器进行分层表示学习,形成了多层前馈网络.实验结果表明,该方法比深度信念网络和深度玻尔兹曼机要快几个数量级,所获得的精度与深度学习算法相比具有很强的竞争力.在应用方面,An等[13]提出了一种基于ELM的高效图像超分辨率方法,其目标是对输入的低分辨率图像进行处理,以生成高分辨率图像.张和李[14]提出了深度极限学习机的立体图像质量评价方法,该方法将立体图像数据经过稀疏自编码器预训练抽取图像特征,再输入ELM分类器进行训练,分类器的输出即为质量评分,提升了该模型的准确性和稳定性.徐等[15]提出了一种融合加权ELM和Adaboost的交通标志识别算法,该算法迭代更新训练样本权重,将ELM分类器作为AdaBoost的弱分类器,最终构造出最优的强分类器.该方法的优点是能够实现对训练样本和弱分类器的双重加权,提高了交通标志的识别精度.黄和王[16]提出了结合超限学习机和融合卷积网络的3D物体识别方法,该方法采用多层融合卷积网络提取特征,用半随机的ELM网络进行分类.与现有的卷积神经网络相比,有更好的效果和更短的训练时长.
针对大数据,传统的ELM算法已不能适应大数据环境的需要,针对这一问题,He等[17]提出了基于MapReduce的ELM.针对大规模图数据分类问题,Sun等[18]提出了一种基于分布式ELM的分类方法,提出的方法具有好的扩展性,而且易于实现.Yao和Ge[19]提出了一种分布式并行ELM和一种层次ELM,解决了用大数据进行多模式质量预测问题,取得了良好的效果.为了解决ELM在大数据环境中的可扩展性问题,Ming等[20]提出了两种ELM并行化变体.一种是基于局部数据的模型并行化ELM,另一种是基于全局数据的模型并行化ELM.基于开源大数据平台Flink,Chen等[21]提出了一种基于GPU加速的并行化层次ELM,并采用几种优化方法提高模型的并行性和可伸缩性.Duan等[22]提出了基于Spark的ELM.本文对基于MapReduce的ELM和Spark的ELM进行全面的比较研究,得出了一些有价值的结论.
2 基础知识
2.1 MapReduce
MapReduce是由谷歌最先提出,用于完成并行式计算的一种工具,其主要思想是“分而治之”,将要处理的数据随机发送至集群上的各个节点上,这些数据存放于集群的分布式文件系统HDFS(Hadoop Distributed File System)上.各个节点并行地处理在该节点上的数据,然后对各个节点的中间结果加以处理,输出处理结果.用户主要是通过MapReduce中的两个基本函数Map和Reduce来完成具体的大数据处理逻辑.在Map阶段将数据根据具体要求逐条处理,并以键值对的形式传送给Reduce阶段.Reduce阶段将键相同的值合并以文件的形式输出结果.
2.2 Spark
Spark是一种用于内存计算的大数据处理框架.它的设计理念中最重要的一点是改善大数据并行运算时网络数据流量承载过重和磁盘I/O开销过大的问题.在Spark中,弹性分布式数据集RDD(Resilient Distributed Dataset)是最重要的组成成分之一.RDD是一个抽象的数据结构,待处理的数据均被高度抽象至RDD中.从物理层面上分析,RDD将待处理的数据散布在集群的各个节点上,存储于内存或外存上,通过唯一的标识符对其进行操作;从逻辑层面上分析,待处理的数据块根据实际操作划分分区数.RDD通过算子操作分区,完成转换或行动操作,形成新的RDD.在Spark平台上的一切操作都是对RDD的操作.这些操作统分成两大类,被称为Transformation(转换)操作和Action(行动)操作.RDD中所有的转换操作都不会直接计算结果,都是延迟加载的操作.它们只是记住这些应用到基础的数据集(例如一个文件)上的转换操作.只有当发生一个要求返回给Driver的动作时,这些转换操作才会真正运行,这种设计使Spark更加有效率.MapReduce和Spark的差异性如表1所示.
表1 MapReduce和Spark平台特性对比
Table 1 Comparison of features of MapReduce and Spark platform

平台磁盘IO操作处理方式处理单元MapReduce生成中间文件,IO操作较频繁逐条处理一条数据Spark基于内存计算,IO操作较少分区处理RDD
3 ELM的并行化及其比较研究
本节重点介绍如何用MapReduce和Spark两种平台实现ELM的并行,并对这两种实现进行对比分析.
3.1 ELM算法
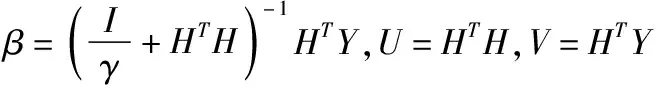
3.2 基于MapReduce的并行化ELM
用MapReduce实现ELM的并行化,关键是Map函数和Reduce函数的设计.算法1和算法2是计算U,V两个矩阵的Map函数和Reduce函数.
算法1.Map函数
输入:X={(xi,yi)|xi∈Rn,yi∈Rm,i=1,2,…,N},wj∈Rn,bj∈R,j=1,2,…,L.
输出:输出中间子矩阵U和V.
1.for(i=1;i<=L;i=i+1)do
2.H
3.end
4.for(i=1;i<=L;i=i+1)do
5. for(j=1;j<=L;j=j+1)do

7. context.write(triple(“U”,i,j),u
8. end
9. for(j=1;j<=m;j=j+1)do

11. context.write((triple(“V”,i,j),v
12. end
13.end
算法2.reduce函数
输入:键值对
输出:矩阵U和矩阵V.
1.键值相同的子矩阵u求和,得到最终结果矩阵U;
2.键值相同的子矩阵v求和,得到最终结果矩阵V;
3.输出U和V.
以MapReduce处理两条数据为例,详细的数据处理流程图1所示.

图1 基于MapReduce的ELM数据处理流程示意图
其中,
H1=[w1x11+b1,…,wLx1L+bL]
(1)
H2=[w1x21+b1,…,wLx2L+bL]
(2)
(3)
(4)
(5)
(6)
基于MapReduce的ELM算法执行流程如下:
1)将隐含层节点参数放置在集群缓存中;
2)在Map节点上执行的操作:
将数据x逐条输入至Map任务中,与缓存中的数据计算得出隐含层节点输出向量H;
计算U的子矩阵;
计算V的子矩阵;
将U和V的子矩阵按照键值对的形式输出至Reduce节点;
3)在Reduce节点上执行的操作:
将接收到的所有的U的子矩阵u按照矩阵加法得出新矩阵U;
将接收到的所有的V的子矩阵v按照矩阵加法得出新矩阵V;
输出U和V矩阵.
3.3 基于Spark的并行化ELM
用Spark实现ELM的并行化,关键是RDD的设计,用各种RDD处理数据的流程如图2所示.
根据图2,可以看出基于Spark的ELM执行流程:
1)第一次遍历:生成RDD并记录依赖关系
读取外部数据生成第一个RDD(TextFileRDD);然后执行Map转换操作对数据进行初步处理,将数据的类型转换成数组,得到MappedRDD,再执行Filter转换操作,剔除格式错误的数据(例如缺省值的情况),生成FilteredRDD,再将数据格式转换生成PairRDD,读成分布式行矩阵的形式,执行其内部自定义函数computeGramianMatrix和multipy,具体算子如下:先由mapPartition操作计算分区中得到mapPartitionRDD,再由转换操作ReduceByKey得到shuffledRDD,然后再次执行mapPartition操作得到新的mapPartitionRDD.所有的转换操作完毕,即在该次作业中所有RDD生成完毕,遍历结束.
2)第二次遍历:划分阶段
根据第一次遍历中RDD记录的依赖关系,从最后一次执行转换操作MapPartitionRDD向前执行,遇到窄依赖就将其并入阶段内部,遇到宽依赖就形成一个新的阶段继续遍历,直至向前遍历至TextFileRDD为止.如图2所示,划分成了两个阶段.
3)第三次遍历:按阶段顺序执行任务
由第二次遍历可知,划分出了两个阶段,顺序执行即可.

图2 基于Spark的ELM数据处理流程示意图

算法3.计算H矩阵
输入:训练集X={(xi,ti)|xi∈Rn,ti∈Rm,i=1,2,…,N},隐含层结点的权值和偏置wj∈Rn,bj∈R,j=1,2,…,L.
输出:隐含层节点输出矩阵H.
1.将训练集X按行划分成L个分区,隐含层权重矩阵W按列划分成L个分区;
2.//矩阵初始化;
3.value=0;
4.for(i=1;i<=L;i=i+1)do
5. for(j=1;j<=L;j=j+1)
6. //计算x[i]×w[j];
8. end
9.end
隐含层节点权重矩阵w按列分成L个分区,每一个完整的隐含层节点参数独立地放在一个分区中.也就是说,w的每个分区缓存相对应的隐含层节点的所有参数,为了有更多的本地计算,将待训练的数据集X按行分为L个分区,对于X来说,这将保证在每个分区中有1个或多个完整的训练数据;对于w来说,可以保证每个分区有1个完整的隐含层节点参数.计算矩阵H中元素的值时,只涉及到公式中训练样例所在的分区和对应隐含层节点参数所在的分区数,减少了网络的传输.计算结果是隐含层节点输出矩阵H,将其缓存在L个分区的内存中.

输入:矩阵H,主对角线均为γ的对角矩阵γL×L.

1.生成矩阵γL×L;
2.//矩阵初始化;
3.outValue=0;
4.//遍历H的每一个分区;
5.for(i=1;i<=L;i=i+1)do
6. //遍历H的每一个分区;
7. for(j=1;j<=L;j=j+1)do
10. end
11.end
12.//矩阵求和;
13.outValue=outValue+γL×L;

矩阵H分布在L个分区中,由U=HTH可知,矩阵U的计算可以解释为:Uij的求解相当于是矩阵H第i个分区与矩阵H第j个分区存放的数据做向量内积运算,其中i=1,2,…,L;j=1,2,…,L,即可得出得到矩阵U,此时U是一个L×L的小规模矩阵,与γL×L做矩阵加法即可得出γL×L的值.
算法5.计算矩阵V
输入:矩阵H,训练集类别矩阵YN×m.
输出:矩阵V.
1.将YN×m按列划分成m个分区;
2.//矩阵初始化;
3.outValue = 0
4.//遍历H的每一个分区;
5.for(i= 1;i<=L;i=i+1)do
6. for(j=1;j<=m;j=j+1)do
9. end
10.end
11.输出V.
矩阵H分布在L个分区中,由V=HTY可知,矩阵V的计算可以解释为:Vij的求解相当于是矩阵H第i个分区与矩阵Y第j个分区存放的数据做向量内积运算,其中i=1,2,…,L;j=1,2,…,m,即可得出得到矩阵V的值.
3.4 基于MapReduce和Spark的并行ELM的比较
3.4.1 两种算法实现的相同点

3.4.2 两种算法实现的不同点
基于MapReduce机制计算矩阵UL×L时,是对于每一个样例x经过与隐含层节点矩阵H计算后得到一个L×L的子矩阵Ui,将所有样例(即N个样例)经过计算后得到的N个L×L子矩阵U1,U2,…,UN进行矩阵加法运算,结果即为矩阵U.此时,存在中间结果的输出,即存在内存→硬盘→内存的数据流动,网络开销不可避免,同时存在子矩阵的叠加过程,计算V矩阵同上;MapReduce并没有生成完整的H矩阵,而是逐条处理数据,这是由自身机制造成的;一次MapReduce操作就算出了U和V矩阵,有较强的并行力度.
基于Spark机制计算矩阵UL×L时,这个矩阵中所有元素均是对应位置分区里存放元素的向量内积运算,在此过程中只涉及两个分区内部元素的相互作用,网络开销较少,且求得即为最终结果,不存在子矩阵加和的情况,计算矩阵V同上;隐含层节点输出矩阵H在Spark平台上是并行完成的,从逻辑上讲,生成了完整的矩阵H,从物理层面上讲,矩阵H中的元素散落在各个分区中;矩阵U和V模块内部是并行执行的,模块间串行操作,并行度相对较弱.
4 实验结果及分析
4.1 实验结果对比分析
4.1.1 并行ELM算法在MapReduce和spark平台上执行时间对比
在2个UCI数据集和3个人工数据集上,对基于MapReduce的ELM和基于Spark的ELM进行了对比分析研究.其中三个人工数据集均由高斯分布产生,第一个人工数据集是二类数据集,服从的概率分布是:
第二个人工数据集是三类数据集,服从的概率分布是:
第三个人工数据集是四类数据集,服从的概率分布是:
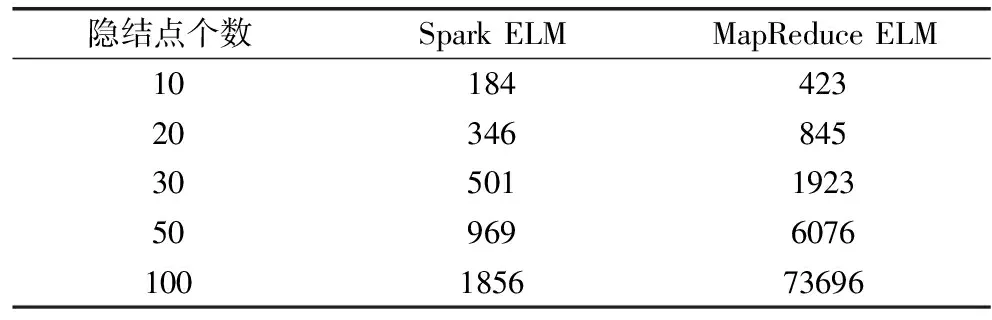
该实验是在拥有1个主节点和7个从节点的云计算平台上进行的,在云计算平台上搭建了Hadoop和Spark两个运行环境,云计算平台节点的基本配置信息和功能规划如表2和表3所示,主机的基本配置如表4所示,实验所需数据集的基本信息如表5所示.实验将从训练数据维度、训练数据规模和隐层节点个数三个方面作为实验参数对含有10、20、30、50、100个隐含层节点的ELM网络模型,比较了基于MapReduce和Spark的并行ELM算法的执行时间,实验结果列于表6~表10中.对实验结果进行分析,得出了结论:基于Spark的ELM算法的效率远远高于基于MapReduce的效率,随着隐含层节点个数逐渐增多,Spark平台的优势愈加明显.在下一节中,我们将从理论层面分析产生该现象的原因.
表2 云计算平台节点的基本配置信息
Table 2 Basic configuration of the nodes of the cloud compution platform

配置项目配置情况处理(CPU)InterXeonE5-46032.0GHz(双核)内存8GBRDIMM硬盘1TB网卡Broadcom5720QP1Gb网络子卡网络设备华为S3700系列以太网交换机操作系统Ubuntukylin13.04云计算平台Hadoop-2.7.3,Spark-2.1.0JDK版本Jdk-7u71-linux-i586Scala版本Scala-2.11.0
表3 云平台的节点功能规划
Table 3 Role assignment of the nodes of the cloud computing platform

主机名IP地址节点类型master10.187.86.242NameNode,Master,ResourceManagernode110.187.86.243DataNode,Worker,NodeManagernode210.187.86.244DataNode,Worker,NodeManagernode310.187.86.245DataNode,Worker,NodeManagernode410.187.86.246DataNode,Worker,NodeManagernode510.187.86.247DataNode,Worker,NodeManagernode610.187.86.248DataNode,Worker,NodeManagernode710.187.86.249DataNode,Worker,NodeManager
表4 主机基本配置信息
Table 4 Basic configuration of the host

配置项目配置情况处理器(CPU)IntelXeonCPUE5-16503.5GHz内存16GB硬盘500G操作系统Win10JDK版本jdk-8u144-windows-x64MapReduce程序环境Eclipse-Phtotn-Releae-4.8.Scala版本Scala-2.11.0Spark程序环境Eclipse-4.7.0
表5 实验数据集
Table 5 Basic information of data sets

数据集类别数属性数节点类型Gauss1221000000Gauss2321200000Gauss3431000000Covtype754581012Skin23245057
表6 两种算法在Gauss1数据集上实验结果的对比(单位:s)
Table 6 Comparison of experimental results of two algorithms on data set Gauss1(s)
隐结点个数SparkELMMapReduceELM1018442320346845305011923509696076100185673696
表7 两种算法在Gauss2数据集上实验结果的对比(单位:s)
Table 7 Comparison of experimental results of two algorithms on data set Gauss2(s)

隐结点个数SparkELMMapReduceELM102262302041919933060747945010656025100223571458
表8 两种算法在Gauss3数据集上实验结果的对比(单位:s)
Table 8 Comparison of experimental results of two algorithms on data set Gauss3(s)

隐含层个数SparkELMMapReduceELM1019520520353690305181478508844205100190032442
4.1.2 并行ELM算法在MapReduce和Spark平台上speedUp指标和sizeUp指标对比
以gauss3数据集的0.1倍作为本实验的原始数据集,我们将对基于MapReduce和Spark平台的ELM算法进行并行性能的评估.实验中采取的训练数据集分别是原始数据集的5倍、8倍和10倍,同时在并行度为7、14、28的平台上运行隐层节点个数为10、20、30的ELM并行算法,根据speedUp指标和sizeUp指标对两种大数据平台进行比较说明,实验结果如图3和图4所示.
speedUp(m)=程序运行在1台设备上的执行时间/程序运行在m台设备上的执行时间
sizeUp(m)=程序处理m倍的数据集执行时间/程序处理原始数据集执行时间
表9 两种算法在Skin数据集上实验结果的对比(单位:s)
Table 9 Comparison of experimental results of two algorithms on data set Skin(s)
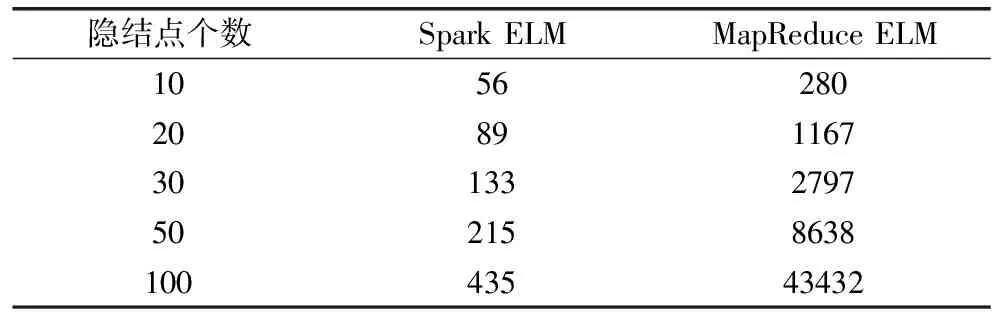
隐结点个数SparkELMMapReduceELM10562802089116730133279750215863810043543432
表10 两种算法在covertype数据集上实验结果的对比(单位:s)
Table 10 Comparison of experimental results of two algorithms on data set covertype(s)
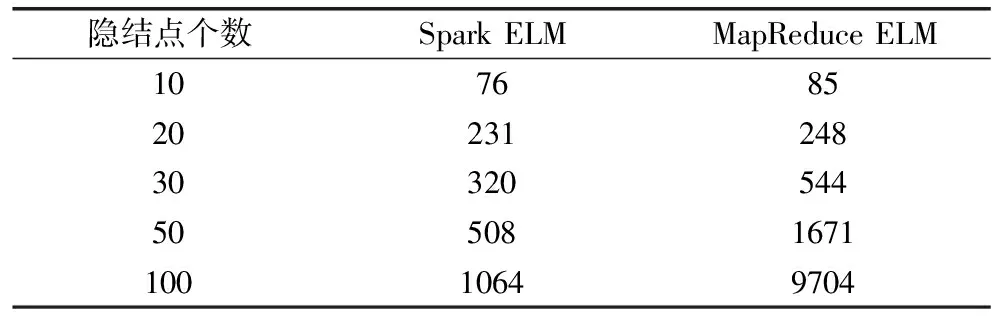
隐结点个数SparkELMMapReduceELM107685202312483032054450508167110010649704
图3是隐层节点分别是10、20、30,并行度分别是7、14、28的ELM算法在大数据平台MapReduce和Spark平台上的对比情况,结果显示:基于Spark平台的ELM算法的speedUp值总体高于基于MapReduce平台的ELM算法的speedUp值,随着隐层节点数的增多,这种差异更加突出.speedUp折线图近似于一条直线,且斜率有减小的趋势这是因为并行计算将不可避免的增加在不同机器上的数据交换,造成时间的浪费.图4是隐层节点分别是10、20、30,训练数据集分别是原始数据集的5倍、8倍、10倍.由图4可知,基于Spark平台的ELM算法的sizeUp值总体低于基于MapReduce平台的ELM算法sizeUp值,也就是说,训练的数据集规模越大时,Spark平台上数据处理效率越突出.这是因为Spark是一种基于内存计算的大数据平台,中间结果可以缓存至内存中,且只有RDD的行动算子才会触发计算,相较于MapReduce平台,不存在中间数据流动至HDFS的情况,数据IO操作较少,但在MapReduce平台上随着隐层节点增多时,在算法执行过程中会存在更大规模的矩阵运算,这将导致更大规模的数据IO操作,造成严重耗时.

图3 大数据平台的SpeedUp性能对比

图4 大数据平台的sizeUp性能对比
4.2 理论分析
在本节中,针对MapReduce和Spark这两种大数据框架,受文献[23]的启发,我们从算法执行时间、同步次数、读写文件数目和分类器的泛化性能4个方面进行比较和分析.
4.2.1 算法执行时间对比分析
基于大数据平台的ELM算法执行时间T为:T=Tr+Ts+Tt+Tw(其中Tr表示文件读取时间,Ts表示中间数据排序时间,Tt表示中间数据传输时间,Tw表示文件写出时间).其中,Tr=文件读速度×输入文件大小;Tw=文件写速度×输出文件大小.
基于不同大数据框架下的并行ELM运行机制,导致程序执行时间的差异.不同的只是大数据处理平台,而程序的输入数据和输出数据、网络传输速度以及文件读写速度在实验中作为常量存在,其差异造成的影响忽略不计.此时Tr和Tw在这两种大数据平台下的ELM算法中的值近似相同,其差异并不是本文中要研究的重点,在此不进行详细分析.主要对Ts和Tt在两个大数据平台下的差异进行精要阐述说明.
a)基于大数据平台的ELM算法Ts中间数据排序时间的比较
对于Spark平台来说,不存在中间数据排序这一过程,故而:
Ts-spark=0
而对于MapReduce平台来说,每次执行shuffle操作时,对中间数据的排序过程是必不可少的,目的是通过对中间数据的排序,实现初步的归并操作这一步骤,确保一个Map任务最终只有一个有序的中间数据文件输出,缓解网络传输压力,具体过程如下:在Map阶段,对每一分区的数据分别进行排序,若共有P个Map任务,每个Map任务负责处理p条数据,采用快速排序的机制进行排序,则:
Ts-mr=Plogp
此时:
Ts-mr>Ts-spark
b)基于大数据平台的ELM算法Tt中间数据传输时间的比较
在中间数据传输时间的比较中,我们主要从数据传输数量和数据存放位置两方面进行比较说明.基于MapReduce的shuffle机制,在Map任务结束后传至Reduce端之前,会存在文件合并的情况,这是MapReduce独有的特色,因此当MapReduce和Spark平台处理相同的数据时,MapReduce平台的中间数据传输量会小于Spark的中间数据传输量.当传输速率相同时,则存在:
Tt-mr-Files Spark是一种基于内存计算的大数据平台,即所有的操作都是基于RDD的操作,中间数据也是以RDD的形式在内存中运算并存储,这是由Spark自身的机制决定的.MapReduce从硬盘上读取数据,经过Map计算后产生的中间数据以文件的形式存储于分布式文件系统HDFS上,然后再从HDFS上读取并进行Reduce计算.显而易见,这比Spark的中间数据传输时间要长得多.所以: Tt-mr-io>Tt-spark-memory HDFS读取操作的时长远远大于内存操作,因此: Tt-mr-Files+Tt-mr-io>Tt-spark-Files+Tt-spark-memory 综上所述,可得: Tt-mr>Tt-spark 根据以上两方面的分析,可得出结论ELM算法在MapReduce平台上的运行时间大于在Spark平台上的运行时间. 4.2.2 同步次数对比分析 同步操作要求当前阶段中的所有节点都执行完毕才开始下一阶段.在MapReduce框架下,所有的Map节点都完成之后,Reduce阶段才开始执行,这是典型的同步操作.一次MapReduce操作,记一次同步.根据前面的分析可知,在基于MapReduce框架下的ELM算法,并行操作主要是进行矩阵H、矩阵U和矩阵V的运算,它主要是通过一次MapReduce操作实现了这三个矩阵的计算,因此,同步次数是1. 由前面基于Spark框架下的ELM算法流程可知,首先并行计算出矩阵H,矩阵H计算完毕后,执行矩阵U和矩阵V的计算,这二者的计算可同时执行,因此算法实现过程中的同步次数是2. 4.2.3 读写文件数目对比分析 在MapReduce框架下,由于存在分区内部排序操作,分区间的数据用偏移量标记,可以将每一个Map中不同分区间的数据汇总成一个大的中间数据文件,即一个Map对应一个中间文件.所以在MapReduce中,读写文件数目是Map任务的数量.但在Spark平台上,RDD是以分区为单位并行执行的,所以在Spark中,读写文件数目取决于RDD的分区数.尽管并行ELM算法在这两个大数据平台上的具体实现有所差异,但这并不是导致读写文件数目不同的原因,这是由大数据平台自身的机制造成的.在MapReduce中,待处理的数据集逐条输入至Map任务中,在每个Map任务中,根据实际需求生成一个大的数据文件,写入HDFS中;Reduce节点再从HDFS中读取这些文件,根据不同的需求执行不同的操作.在基于MapReduce框架下的ELM算法中,并行操作主要是进行矩阵H、U和V的运算,它通过一次MapReduce操作实现了这三个矩阵的计算,读写文件数目等于Map任务数目,读写文件数目只与该算法执行过程中Map任务数目有关;在Spark平台上的一切操作都是对RDD的操作,以图2为例,数据划分为3个分区进行并行处理,每个分区对应一份数据文件,数据经过TextFileRDD后,将数据分成3份,读入3个文件中进行并行操作,当数据经过mapPartitionRDD后,同一个文件中的数据会进入shuffleRDD中不同的分区,这就会导致mapPartitionRDD每个分区中的一个数据文件拆分3个子数据文件,分别对应shuffleRDD中不同的分区,实现文件的reduceByKey操作,此时读写文件数目为3+3+3+3+3×3+3=24.其中,分区数3是可手动控制的超参数,如当分区数重置为4时,文件读写数目=4+4+4+4+4×4+4=36.Spark平台读写文件数目只与RDD中的分区数有关. 4.2.4 分类器的泛化性能对比分析 基于MapReduce和Spark平台的并行ELM,使用了相同的方法计算从隐含层到输出层之间的参数矩阵β,即在这两个大数据平台下,计算两个中间结果矩阵U(即HTH)和矩阵V(即HTY),当所有的相关参数均相等时,用该算法对相同的训练数据训练分类器,显而易见,训练出的分类器也是相同的,它们的泛化性能一致.因此在这两个平台下,相同的测试数据会得到相同的精度. 本文通过对基于MapReduce和Spark平台的两种并行ELM进行比较研究,得出如下结论:1)从算法实现层面上看,这两个大数据平台均并行计算了矩阵H、U和V,计算过程大致相同;2)基于Spark的ELM的执行效率远远高于基于MapReduce的ELM的执行效率,而且从大数据平台理论层面和并行指标speedUp,sizeUp证明了这一结果的必然性;3)基于MapReduce的ELM在同步次数方面优于Spark平台的ELM;4)从读写文件数目来看,基于MapReduce的ELM需要读写文件数目与Map任务个数有关,而基于Spark的ELM读写文件数目与分区数有关;5)从分类器泛化能力来看,两种并行ELM并无差别.5 结束语
