基于Scrapy的水利数据爬虫设计与实现
2020-07-09游攀利杨琳喻淼
游攀利 杨琳 喻淼


摘要:为解决目前各级水利部门数据共享能力弱、数据格式不统一的问题,建立了一种水利数据整合方法。针对互联网公开的水利数据特点,结合水利行业标准规范,介绍了基于Scrapy框架设计和开发的水利数据爬虫,并规范化存储数据。在总结各种水利数据的获取和解析原理及方法基础上,提出了使用Scra-pyd部署爬虫和SpiderKeeper管理爬虫的方法,并成功应用于长江大数据中心的建设,为水雨情预警、防汛抗旱、应急管理提供了重要支持。
关键词:水利数据;网络爬虫;Scrapy;数据采集
中图法分类号:TP391
文献标志码:A
DOI:10. 15974/j .cnki.slsdkb.2020.05.014
水利信息化经过多年的发展,全国各水利厅局及流域机构积累了大量的水利数据,包括水雨情数据、水质数据、水涝灾害数据、遥感数据、防汛抗旱知识和应急管理知识等,这些数据可为防汛抗旱决策支持、水利工程建设、水文水资源研究等提供重要支持[1]。然而,水利数据分散在各水利机构内,结构复杂、种类繁多,即便是同一种类的业务数据,数据结构也有所差异,阻碍了水利数据的开发、利用与研究。因此,本文从各水利政务网站的公开数据人手,结合水利部发布的数据库规范设计数据库表,以水雨情数据为例,基于爬虫框架Scrapy设计和开发水利爬虫,着重介绍了各种水雨情网页的获取和解析过程,包括Scrapy Selector CSS选择器解析HTML结构数据、正则表达式解析JavaScript数据、获取和解析Ajax数据、Selenium结合浏览器驱动解析网页加密数据等;并对爬取的数据进行规范化存储,最后使用SpiderKeeper对分布于不同服务器的爬虫进行统一管理。
1 网络爬虫
网络爬虫( web crawler),又称作网络机器人(web robot)或网络蜘蛛(web spider),是以一定的规则自动抓取互联网资源的计算机应用程序[2]。网络爬虫通常由调度器( scheduler)、下载器(download-er)、解析器(parser)、待爬行队列(URL queue)4个部分组成,如图1所示[3-4]。调度器首先将设定的初始URL传递给下载器,下载器从互联网下载信息并传给解析器,解析器根据既定规则提取信息和待爬取的URL,提取的信息经处理后存人数据库或文件,URL经去重后传输给待爬行队列.等待调度器调用,循环往复[5-7]。
网络爬虫分为通用( General Purpose)网络爬虫和聚焦(Focused)网络爬虫[8]。通用网络爬虫又称作全网爬虫,爬取整个互联网资源以供搜索引擎建立索引;聚焦网络爬虫又称作主题网络爬虫,爬取用户需要的特定主题网页(经相关网站许可)收集数据,并在标注出处的前提下加以数据分析、用于建模及展示。水雨情爬虫为聚焦网络爬虫,目标是爬取各级水利部门网站公开的水雨情信息。
网络爬虫技术伴随着搜索引擎共同发展,在网络爬虫发展初期,开发者需考虑很多底层功能的实现,例如,模拟HTTP请求、下载网页、解析数据、队列管理等。搜索引擎面对的问题日趋复杂,促使爬虫程序的编写难度越来越大。为了提高爬虫的编写效率,逐渐出现了网络请求库urllib、urllib2、re-quests等和解析库Xpath、Beautiful Soup、pyquery等,进而抽象出模块的概念,有了爬虫框架的雏形。此时,开发者虽不需考虑这些常用模块的实现,但仍需考虑爬虫的流程、异常处理及任务调度等。对于今后进一步出现的pyspider、scrapy等爬虫框架,开发者只需考虑爬虫的业务逻辑部分。而且,pyspi-der、scrapy的可配置性更高,异常处理能力更强,故水利数据采集系统采用scrapy作为爬虫框架。
2 Scrapy框架
Scrapy是使用Python语言实现的一种爬虫框架,它将网络爬虫工程化、模块化,帮助开发人员方便地构建网络请求、解析网页响应,从而快速实现特定业务的爬虫[8-9]。Scrapy基于Twisted异步网络库处理网络通讯,实现了分布式爬取。
2.1 Scrapy组件
Scrapy爬虫框架结构如图2所示[10],包括以下6个主要组件:
(1)Scrapy引擎(engine)。负责控制数据在组件中流动,并在相应动作发生时触发事件,是整个框架的核心。
(2)调度器。从Scrapy引擎接受请求,并将其加入到队列中,以便之后请求它们时提供。
(3)下载器。接受请求,负责获取数据并提供给引擎,而后提供给爬虫。
(4)爬虫。用户编写的针对特定业务的爬虫程序,定义了初始请求网址、网页的爬取逻辑和解析规则,用于发起初始请求和解析返回的数据并提取项目(Item,定义了爬取结果的数据结构,可对应web开发中的实体类)和生成新的请求,每个爬虫负责处理某个特定或一些网站。
(5)项目管道(Item Pipeline)。负责处理爬虫提取出来的项目,典型的处理有数据清洗、验证数据完整性、数据重复及数据持久化(例如按指定格式保存到文件或存取到数据库中)。
(6)中间件(middleware)。包括下载器中间件( downloader middleware)和爬虫中间件(spider mid-dleware)。下载器中间件是在引擎与下载器之间的特定钩子( specific hook),主要处理引擎发过来的请求,用户可编写程序扩展Scrapy的功能,以自定义的方式协调下载器的工作;爬虫中间件是在引擎与爬虫之间的特定钩子,处理爬虫的输入响应(response)和输出条目及请求。同下载器中间件一样,用戶可扩展Scrapy功能,以协调爬虫工作。
2.2 Scrapy数据流
Scrapy的数据流向是由引擎控制的,数据流动的过程如下:
(1)引擎找到处理该网站的爬虫,向爬虫请求初始要爬取的URL,根据URL解析域名。
(2)引擎从爬虫中获取到第一个要爬取的URL,并通过调度器以请求的形式调度。
(3)引擎向调度器请求下一个要爬取的URL。
(4)调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载器中间件转发给下载器。
(5)-旦页面下载完毕,下载器生成该页面的响应,并将其通过下载器中间件发送给引擎。
(6)引擎从下载器处接收到响应,并通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应,解析数据并封装成条目,返回条目及新的请求给引擎。
(8)引擎将爬虫返回的条目给项目管道处理,将新的请求加入到调度器的待爬队列中。
(9)重复步骤(2)~(8),直到调度器中没有请求,待爬队列为空,或者满足自定义的停止条件,引擎则关闭该网站,爬行结束。
通過多个组件的分工协作、组件对异步处理的支持,Scrapy充分利用了带宽,提高了数据爬取效率。
3 水雨情爬虫设计
3.1 网页获取
爬虫设计的首要工作即是得到获取目标数据的网络请求。访问水雨情网页,查看网页的源代码会发现,其中可能根本不存在水雨情数据,这是因为现在很多网页是由JavaScript渲染出来,原始的HTML代码可能只是一个仅有水雨情表头的表格。向网站发送一个HTTP请求,返回的就是网页源代码。综合分析各级水利部门网站公开的水雨情网页,存在以下几种情况。
(1)网页源代码中的HTML代码包含目标数据,该网页的URL就是获取目标数据的URL;
(2)网页源代码中的JavaScript代码包含目标数据,该网页的URL就是获取目标数据的URL;
(3)网页源代码不包含目标数据,通过Ajax加载数据渲染网页,Ajax请求的URL即是获取目标数据的URL;
(4)网页源代码不包含目标数据,通过JavaS-cript算法生成数据渲染网页,该网页的URL即是获取目标数据的URL;
(5)网页源代码不包含目标数据,网页数据被加密,该网页的URL即是获取目标数据的URL;
(6)网页源代码不包含目标数据,而是使用if-rame嵌入另一个HTML网页展示数据,这种情况下,为了确认获取目标数据的URL,需再次分析,以确定是上述(1)~(5)中的哪种情况。
3.2 数据解析
确定获取目标数据的URL之后,使用Scrapy模拟HTTP请求,对返回的响应数据进行解析。根据响应的不同,解析方式也不同。对于3.1节中的情况(l),需要解析的是HTML结构数据,使用Scrapy的Selector CSS选择器进行解析;对于情况(2),由于JavaScript数据不是结构化的,通常使用正则表达式进行解析;对于情况(3),需要解析的是JSON数据;对于情况(4)和(5),通常JavaScript的算法规律并不容易找到,即使找到,花费的时间代价太大,若网页数据加密,分析难度更大,所以这两种情况通常采用Selenium或PhantomjS来驱动浏览器加载网页,直接获得JavaScript渲染后的网页,做到“可见即可爬”,接下来解析HTML结构数据即可,与(1)的解析方式相同[11]。对于情况(6),iframe嵌入网页的数据解析,只需分析iframe嵌入的网页源代码即可,后续步骤与(1)~(5)相同。具体的数据解析如下。
(1)HTML结构数据解析。以重庆水利水务网“水文管理”模块下的“今日八时水情”(URL为http: //slj .cq.gov.cn/swxx/jrbssq/Pages/Default.aspx)为例,如图3所示。查看源代码,发现目标数据已包含在HTML代码结构中,可利用CSS选择器进行解析。例如使用Scrapy shell提取寸滩和武隆水文站的水位数据,可分别使用如下代码进行提取,如图4所示。
需要注意的是,由于代表站占据了第2行的第1列,所以寸滩的水位数据在第2行的第5列,而武隆的水位数据在第4行的第4列。
(2)JavaScript数据解析。以长江水文网的“实时水情”(http://www.cjh.com.cn/)为例,如图5所示。分析网页的源代码,目标数据是通过标签嵌入的URL(http://www.cjh.com.cn/sqindex.html)加载的,分析此HTML的源代码,发现目标数据包含在Ja-vaScript代码中(见图6),其作为一个JSON字符串赋值给了一个JS变量,这种情况使用正则表达式获取目标数据最为方便,如图7所示。
(3)Ajax数据解析。以湖北省水利厅网站的“水旱灾害防御”模块的“江河水情”栏目(http://113.57.190.228: 8001/web/Report/RiverReport)为例,该栏目展示了湖北省56个河道水文站当天08:00的水位、流量信息,如图8所示。目标是从表格中解析出实时数据(水位、流量)和防洪指标数据(设防水位、警戒水位和历史最高水位),查看江河水情网页的源代码发现表格中并没有相关数据。打开Chrome开发工具.选择Network选项卡,通过XHR筛选出Ajax请求,选定请求,点击Headers可查看请求和响应的头部详情。分析可知,请求类型为GET,请求URL为http://113.57.190.228: 8001/Web/Report/GetRiverData? date=2019-11-11+08%3AOO,请求的参数只有1个date,参数值经过了HTML URL编码,表示的是ASCII字符“:”,所以真实的参数值为:2019-10-30 08:00。据此,可以使用Scrapy模拟Ajax请求,如需获取历史数据,只需要按照一定规则改变date参数即可。点击Preview可预览返回的JSON数据,如图9所示,对照网页数据可知每个字段的业务意义。
(4)加密网页数据解析。以江苏水情信息(http://221.226.28.67:88/jsswxxSSI/Web/Default.ht-ml? m=2)为例,使用如图10所示代码即可获取表格数据。后续使用HTML结构数据解析方法即可,不再赘述。
3.3 爬取对象定义
Scrapy的条目类用来定义爬取的对象。综合分析各级水利部门网站公开的河道水情信息,并结合水利部发布的SL323-2001《实时水雨情数据库表结构与标识符》数据库规范,对于河道水文站爬虫,用StRiverltem定义爬取对象,需定义的属性有:测站编码、时间、测站名称、河流名称、水位、流量、设防水位、警戒水位、保证水位和历史最高水位。
3.4 数据存储
爬虫将解析的数据封装成条目之后交给项目管道,进行数据持久化。数据持久化的方式有多种,可直接本地化存储为文件,如TXT、CSV、JSON等,也可保存至Oracle、MySQL等关系型数据库或者MongoDB、Redis等非关系型数据库。本文采用MySQL,根据爬虫对象StRiverltem设计河道水情数据表结构,如表1所示。
爬取的数据保存至MySQL数据库,结果如图11所示。
3.5 异常处理
爬虫执行一段时间后,可能会出现“403 Forbid-den”的錯误,这是因为IP访问频率过高,网站采取了反爬措施,检测到某个IP单位时间内访问次数超过某个设定的阈值,就会拒绝服务。解决办法包括使用代理和降低访问频率,鉴于水利数据每天更新数量不多,可采用降低访问频率办法采集历史数据,在采集一个时间段的数据后,程序停顿1-2 s。如果采集的是实时数据,水文网站每天更新的数据量并不多,通常不会出现访问频率过高的问题。
网站反爬的措施还包括登录、验证码和返回动态网页等。水雨情等水利数据通常是公开的,无需登陆和输入验证码即可访问。如果确有登录和验证码的要求,需在爬虫业务逻辑内增加登陆模块,并使用图象识别或接入打码平台进行验证码识别,成功登陆后获取cookies信息再对数据进行处理。若服务器返回的是动态网页,使用前述Selenium进行处理,不再赘述。
4 系统部署
在完成Scrapy爬虫程序的编写和测试之后,将其部署在Scrapyd服务器中。Scrapyd是由Scrapy官方提供的用于部署Scrapy爬虫的服务,用户可通过它提供的HTTP JSON API控制爬虫。Scrapyd本身提供了一个简单的UI界面,用户使用任何1台能连接到Scrapyd服务器的计算机即可上传、启动、停止爬虫并查看运行日志,而不必登录到Scrapyd服务器。但是,这个界面过于简单,且1台Scrapyd服务器仅有1个界面,多台即有多个界面,不能进行统一管理。
水利数据涉及主题非常多,对应的爬虫数量很大。为了提高爬虫的性能,通常将不同业务的爬虫部署在不同的Scrapyd服务器上。为了实现对爬虫的统一管理,要使用SpiderKeeper和Scrapyweb,两者均可实现一键部署和定时任务,都是对Scrapyd提供的接口的二次封装。SpiderKeeper是一款可扩展的爬虫服务可视化管理工具,可快速向多个Scrapyd服务器部署爬虫,监控爬虫执行情况,通过仪表盘管理爬虫,并定制运行策略。Scrapyweb比SpiderKeep-er功能更丰富(例如异常情况邮件通知),但稳定性不及SpiderKeeper,SpiderKeeper可以应付大规模的爬虫集群。本文采用SpiderKeeper对爬虫进行统一管理。
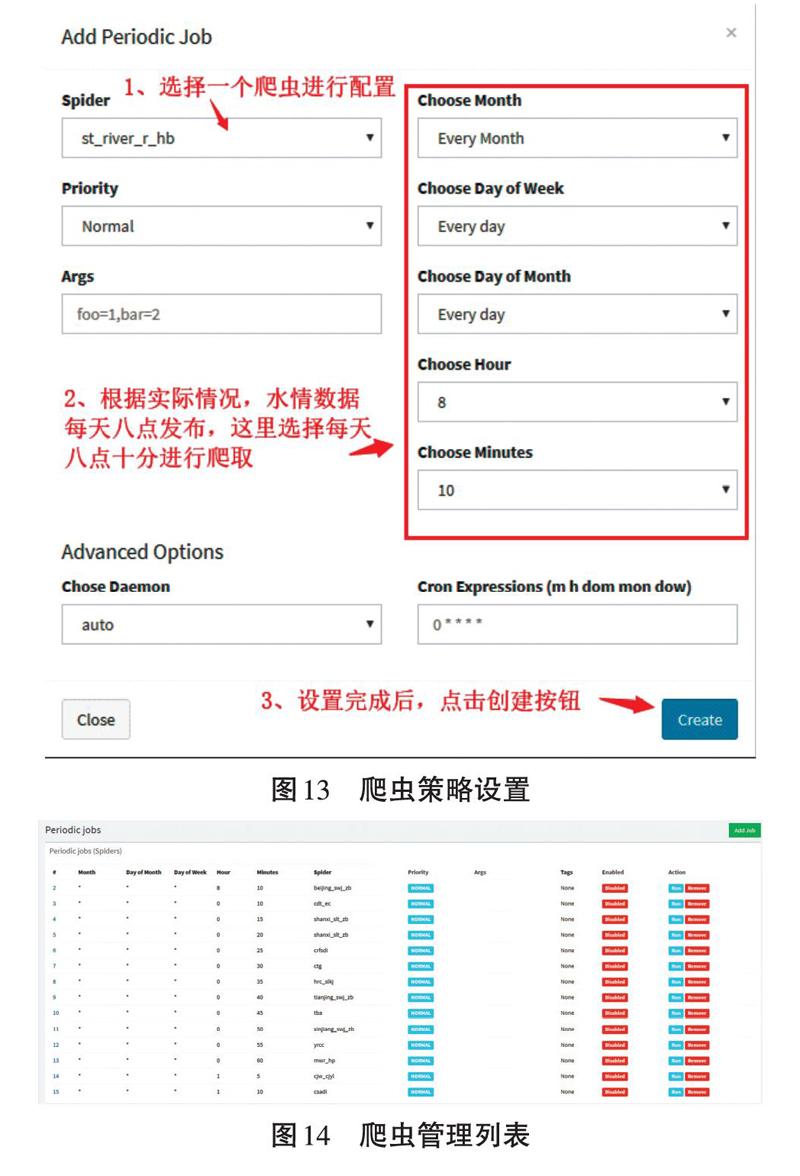
使用SpiderKeeper设置爬虫分两步,首先创建一个条目,然后添加1个定时任务,如图12所示。1个爬虫对应1个定时任务,定时策略又根据业务数据的发布情况决定,如图13所示。完成对所有爬虫的设置之后,可对爬虫进行关闭、运行一次和删除操作,如图14所示。
5 结语
本研究基于Scrapy的水利数据爬取,以水雨情为例,将各水利厅局及流域机构公开的水雨情数据解析分为HTML结构数据、JavaScript数据、Ajax数据和加密数据4类。详细介绍了解析方法和原理,并将提取到的水雨情数据进行规范化存储,可为水利一张图和使用大数据方法研究水雨情预警、防汛抗旱、应急管理提供数据支持。
参考文献:
[1] 张驰恒一.基于多数据源的水利数据获取及大数据服务[D].西安:西安理工大学,2018.
[2]Castillo C.Effective web crawling[Jl. ACM SIGIR Fo- rum, 2005 .39(1): 55-56.
[3]刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007,24(10):26-29.
[4]周德懋,李舟军.高性能网络爬虫:研究综述[J].计算机科学,2009,36(8):26-29.
[5]于娟,刘强.主题网络爬虫研究综述[J]计算机工程与科学,2015,37(2):231-237.
[6]Rungsawang A,Angkawattanawit N.Learnable Lopic-spe-cific web crawler[J].Journal of Network&Computer Ap-plications, 2005, 28(2): 97-114.
[7] Kozanidis L.An Ontology-Based Focused Crawler[Cl//Intemational Conference on Natural Language and Infor-mation Systems: Applications of Natural Language to In-formation Systems. Springer-Verlag, 2008: 376-379.
[8]李乔宇,尚明华,王富军,等.基于Scrapy的农业网络数据爬取[J].山东农业科学报,2018,50(1):142-147.
[9] 马联帅.基于Scrapy的分布式网络新闻抓取系统设计与实现[D].西安:西安电子科技大学,2015.
[10]
Scrapy developers. Scrapy Architecture overview[DB/OL].
https: //doc.scrapy.org/en/latest/topics/architecture. html, 2018。
[11]杜彬.基于Selenium的定向网络爬虫设计与实现[J]金融科技时代,2016(7):35-39.
(编辑:李慧)
作者简介:游攀利,男,工程师,硕士,主要从水利信息化建设及软件开发工作。E-mail: youpanli@cjwsjy.com.cn
