机器学习背景下非现场审计模型的构建及应用
2020-07-06朱宇龙刘森袁阳春张君陈灏生
朱宇龙 刘森 袁阳春 张君 陈灏生


摘 要:随着信息技术的发展,企业业务系统日益完善,积累了大量的企业数据资产,而机器学习等新兴技术的出现,为处理海量数据带来了可能性,也为非现场审计提供了技术基础。应用机器学习技术创建相应的非现场审计模型,能够有效地提高审计工作的效率,扩宽审计覆盖面,并为加强审计监督提供了新途径。本文介绍了应用朴素贝叶斯和K-means聚类两种机器学习算法构建的非现场审计模型的原理及实践经验。
关键词:机器学习;非现场审计;朴素贝叶斯;K-means
应用机器学习相关算法构建审计模型辅助非现场审计,是近年来大数据审计工作的发展趋势。在企业数据平台的基础之上,审计业务人员和数据分析人员紧密协作,运用统计分析、数据挖掘等工具,开展以业务数据为基础的非现场审计模型的构建工作,从而更加有效的完成审计目标。
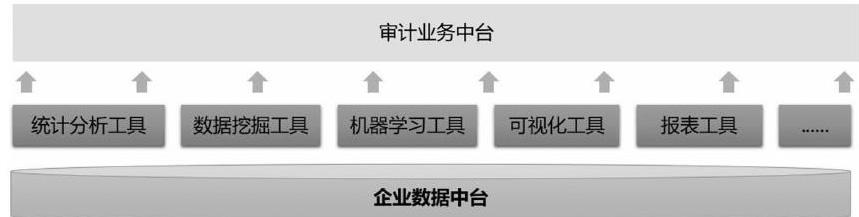
一、应用机器学习技术在数据中台的基础之上构建审计业务中台
(一)审计业务中台
大数据时代,企业的发展伴随着企业业务的多元化,各大企业也都致力于企业的数字化转型。企业数据中台是为了解决业务数据孤岛问题,统一数据治理和数据资产管理,以达到技术降本、应用提效、业务赋能的目标;企业数据中台是企业的数据枢纽,是横向跨专业、纵向跨层级的各类企业数据资源汇聚中心、数据资产转化中心、数据价值发掘中心,是企业数字化转型的重要支撑。审计业务中台是以大数据分析、人工智能等作为技术支撑,在企业数据中台的基础上,直接面向审计对象构建审计模型,识别评估企业风险,辅助审计人员梳理审计线索,圈定审计重点,实现从“大海捞针”式的随机抽样审计到依托审计模型的“精准撒网”式审计的转变,拓展审计的宽度、高度、深度,提升审计效率和质量。
(二)非现场审计
非现场审计是为一个或多个审计对象提供综合审计数据分析建模服务。通常可以面向全域的业务对象,具有一定大数据特征,是一个典型的数据应用和数据价值发现场景。若采用传统现场审计作业方式同时对多个审计对象开展审计业务,不仅对人员的需求量大,而且审计项目实施过程中辨别风险、分析问题的工作量也很大,甚至在审计工作成果汇总阶段,会存在不同对象审计定性不一致的风险,若采用基于机器学习的非现场审计,则可通过结合历史审计经验,构建审计数学模型,在全量数据的基础之上,统一运行,并根据模型结果识别审计问题,能够显著提高审计覆盖面和审计效率。当前非现场审计模型的构建主要依托于资深审计业务人员的审计策略,并基于国家法律法规和企业规章制度识别审计规则,运用机器学习算法构建数学模型,达到识别数据异常点的目标,为审计工作提供线索,审计人员再通过线索查找不合规的异常情况。
二、非现场审计工作的开展方式
机器学习在非现场审计工作中的应用主要分为分为五个步骤:审计需求分析、审计模型设计、审计数据准备、审计模型开发、审计应用。从技术架构上看,非现场审计依托企业数据中台,运用统计分析、数据挖掘、机器学习、自助可视化等工具构建审计业务中台,推进非现场审计工作。
技术架构图如下图所示:
(一)审计需求分析
为了发挥出高质量数据的审计价值,必须充分考虑实际审计项目的应用需求,才能有效地為审计现场提供有力的支撑。在进行需求梳理过程中,主要由各单位审计部门通过研讨会、现场摸底调查和电话访谈等方式对审计应用现状开展需求调研工作,主要调研目前各业务数据归集情况、数据分析应用情况、数据范围、应用范围、功能需求范围等。
(二)审计模型设计
根据审计工作流程和研究的业务领域,将模型设计工作分为五部分:算法初选、数据样例设计、训练方案、评价体系、应用界面设计。算法初选主要根据需求分析结果初步进行算法选取,基本明确建模范围;根据需求分析结果进行样例设计,作为数据样例和实际应用数据的采集准备依据;训练方案是指在系统提供数据样例的基础上,应用机器学习进行数据处理和算法分析;评价体系是对机器学习训练成果进行多维度的评价方案,选取最合适的机器学习算法公式;应用界面是审计模型的成果展示界面,应用界面设计侧重于面向审计业务人员的人机交互行为习惯,提供简单明了的数据图标展示和模型结果数据导出功能。
(三)审计数据准备
数据准备工作指从原始业务数据到形成最终数据集的所有操作,主要包含数据的收集、清洗和转换工作。在审计需求分析和审计模型设计的基础之上,明确数据准备范围,然后进行数据清洗和转换操作,在数据准备阶段通常要处理的数据问题有:数据的不唯一性、格式上不统一、非法值、特征依赖、缺失值、错误拼写等。数据准备任务可能要进行多次、没有规定的固定顺序,整体花费时间占整体建模工作50%到80%的时间。
(四)审计数据建模
审计模型开发包含模型训练、模型质量评估和模型部署三个子环节,模型训练通常依托存量数据,进行算法的选择和参数的调优;模型质量评估是针对算法的执行结果和实际情况进行比对,得到模型的准确度等评估指标,只有通过质量评估且执行效率高的模型,才具有模型部署应用的价值。模型部署是指将模型部署到正式环境,进行常态化的运营,按需或定时输出模型结果。
(五)审计应用
非现场审计模型可以应用在两种场景下:场景一,业务驱动的审计项目实施场景,审计部门结合开展的审计项目,将成熟的模型直接应用到审计现场,辅助缩小审计范围,提高审计效率。场景二,数据驱动的常态化的日常监控场景,随着审计模型构建的越来越完善,模型的精准度也逐步提高,不仅扩宽了数字化审计的覆盖面,也大幅度提高了审计的质量和效率,即可在审计模型的基础之上开展常态化的审计监控工作,进一步提高审计部门快速识别企业风险的能力。
三、实证研究
(一)基于朴素贝叶斯算法下的资产异常识别
企业的资产管理业务系统包含大量资产数据,包括资产类别、使用保管人、资产变动、资产状态、资产折旧值等。依据资产部门的日常运维工作和历史审计经验可识别出四类资产异常:资产归类异常、资产管理异常、资产数据完整性异常和资产数据准确性异常。本实例运用朴素贝叶斯算法,通过数据收集、特征值提取、分区训练和质量评估等步骤,准确识别资产异常情况,辅助资产域的审计工作。
1.数据收集及特征值属性选取
取某待审计公司建筑业务资产数据作为样本量,总计12万左右,有覆盖性和普遍性,现分为以下四大类资产异常,特征值与选取标准详见下表:
资产异常特征描述特征值选取资产归类异常资产描述与类别不匹配资产编码、资产类别、资产状态、数量、计量单位
资产管理异常管理要求未执行资产类别、使用保管人、数量、资产变动方式资产数据完整性异常关键资产属性数据为空资产描述、数量、计量单位、资产原值、累计折旧、使用年限资产数据准确性异常资产数据不准确资产类别、资产原值、账面净值、累积折旧额
经过综合分析确定11个特征值并分为两类:①离散型变量,即不以数据体现,需要文字描述部分,包括资产类别、资产描述、资产变动方式、资产状态、计量单位、使用保管人等;②连续型变量:可从以数字区间取值且有连续性,包括数量、使用年限、资产原值、账面净值、累计折旧额。
2.数据清洗
通过设置公式筛选将无意义、不成立的等式进行剔除,因为此类数据可直接反映资产数据异常,可直接作为异常结果处理,例如资产原值≤0、累计折旧<0、账面净值<0、资产原值—累计折旧额—账面净值<0等无财务意义的数据,清洗后留存数据量为82891个样本。
3.数据替代
由于机器学习模型无法分析语义,因此在离散型变量必须采用可识别的数据替代这些文本描述类型,例如资产状态如果分为①待报废②报废③在运④退运⑤未投运⑥库存备用⑦现场留用,即可以实现数字代换。这种分类只能体现静态状态,不能分析其成因,但可以反映其异常并引起注意,具有分析价值。
4.区分训练集与测试集
数据分为58023个训练集(70%样本量)和24867个测试集(30%样本量)(测试集计99470条数据),进行训练模型和评价模型的反复演算。
实验数据:
利用贝叶斯分类器进行训练,根据条件概率p(yi|x)的大小判断待分类项:
5.模型质量评估
利用朴素贝叶斯算法进行建模与预测分析,预测结果如下:
识别率=(13282+42008/13282+5570+5453+42008)×100%=83.3773167%
通过计算发现,准确率与样本数量有关,样本数量越多,准确率越高,此外样本的选取特征还可以进一步扩大其关联关系,并对连续型变量作进一步采样区分特征属性,可以略微提高朴素贝叶斯模型的准确率。
(二)运用K-means聚类算法识别企业财务报销费用异常
企业的财务报销数据量巨大,通常有差旅费、住宿费、会议费等,形式多种多样,且非常零碎,在审计工作中,财务审计占比非常高,如果采用人工的方式核查,抽样率较低,且效果不佳,本实例运用K-means算法进行报销费用的聚类分析,并识别各类别群体的特征,重点分析离群数据,辅助发现报销费用的异常情况,分析过程如下:
1.数据抽取
选择分析观察窗口,抽取观察窗口内的全部人员报销明细,对于后续新增的人员报销信息,以后续新增的新的时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据。
从报销系统数据库中抽取n个人员的分析观察窗口下的全部报销数据,共计r条记录,其中包括acc_no、register_from、real_name、报销日期、报销次数、异常时间存在报销次数、观察期内报销总金额、观察期内报销总笔数、报销金额、报销笔数、异常时间报销金额、异常时间报销笔数等属性。
2.数据探索分析
对数据进行缺失值及异常值分析,分析数据的规律及异常值,查找各属性的空值个数、最小值、最大值,根据箱型图观察报销金额的异常情况。
原始数据中数据属性太多,选择与指标相关的属性,删除与其不相关、弱相关或冗余的属性,例如:acc_no、register_from、real_name等属性。
3.数据变换
需要通过原始数据来进行属性构造,具体的计算方式如下:
(1)无报销天数占比=无报销天数/观察期天数;
(2)异常报销天数占报销天数比=异常时间存在报销天数/观察期天数;
(3)异常时间段报销金额占比=异常时间报销金额/观察期内报销总金额;
(4)异常时间段报销笔数占比=异常时间报销笔数/观察期内报销总笔数;
(5)单笔为100倍数占比=报销金额单笔额度为100的倍数的笔数/观察期内报销总笔数;
(6)单笔金额额度异常的占比=单笔金额在该用户的报销金额范围中是异常的笔数/观察期内报销总笔数。
6个指标的数据提取后,对每个指标数据的分布情况进行分析,并对数据进行标准化处理。
4.模型构建
模型主要有兩部分组成,第一部分根据人员报销数据的6个指标数据,对人员进行聚类分群。第二部分结合业务对每个人员群进行特征分析,分析其报销特点,并对人员群进行排名。
5.聚类特征分析
利用K-means聚类算法进行建模与预测分析,预测结果如下:
采用k-means对人员报销数据进行分群,可通过如下手肘法来确定K的取值,在K=4时,出现肘点,因此K=4,分成4类。
分群1特点:该类人员无报销天数占比在95%以上占比较大,异常时间段报销情况基本不存在,且报销金额也较少,异常单笔金额笔数也较少,可以认为该类人员为不活跃人员。
分群2特点:该类人员无报销天数占比在75%以上,且报销金额占比在50%左右,而单笔报销金额存在异常的笔数占比在3%~8%,存在异常金额报销情况。
分群3特点:该类人员无报销天数占比在75%以上,且报销金额占比在50%左右,而单笔报销金额存在异常的笔数占比低于10%占多数,存在异常金额报销情况。将该人员分为报销比重较大人员。
分群4特点:该类人员无报销天数占比在25%以下及60%以上占比较大,且有90%以上的报销天数都存在异常时间段报销;在异常时间段的报销金额占比为50%,异常时间段的报销笔数占比在40%占比较大,而单笔报销金额存在异常的笔数占比低于15%占多数,存在异常金额报销情况。将该人员作为重点观察人员。
四、机器学习在非现场审计中的前景展望
(一)机器学习方法用于提升数字化审计能力前景
从上文的机器学习模型建立情况来看,证明在非现场审计领域中,使用机器学习方法构建审计模型,能够解决非现场审计工作的三个主要问题:①人工查证;②规则查证;③审计疑点识别;而且机器学习方法所建立的数学模型在此类数据工作方面能够实现经验留存,具有较强的推广性。
应用机器学习方法建立数学模型技术,能够促进被审查对象提供清晰、有效的审计原始数据,更为直接地体现审计工作中隐藏的财务风险,有效地避免被审计对象数据作假,规范审计过程。除此以外,基于数字化审计得出的审计结果有样本性与研究价值,对同类数据的后续参考借鉴意义较客观。
(二)机器学习方法在审计工作中应用现存问题
目前机器学习方法建立数学模型技术遇到的最大问题就是如何解释其中的逻辑和推理的客观性问题,因为只有基础分类属于人工决策的内容,常常被认为是黑盒模型,向非专业的工作人员或决策者们解释起来很困难,他们很难理解模型是怎样工作并做出决定的,因此在模型设计的逻辑判断标准上要本着国家会计制度的基础原则,增加非现场审计机器学习模型的可信度,绝不能因为第三方的客观要求而背离审计基本原则,使模型丧失基本计算性能和准确性。
五、结语
机器学习技术为非现场审计模型应用实践带来了机会,复杂且难以人为识别的模型算法可以通过机器学习技术进行训练,从而扩大非现场审计模型的容量。在审计实践中,机器学习技术是需要在深入业务需求分析的基础上结合多种算法和分析工具进行综合的应用。基于机器学习的非现场审计模型的应用,显著降低了现场审计人员的投入、提高审计效率、扩大了审计对象范围,有效推动了审计方式的进步。
参考文献:
[1]吕劲松,等.基于数据挖掘的商业银行对公信贷资产质量审计研究[J].金融研究,2016,(07).
[2]王會金,陈伟.非现场审计的实现方法研究[J].审计与经济研究,2005,(05).
[3]易仁萍,王昊,朱玉全.基于数据挖掘的审计模型框架[J].中国审计,2003,(03).
