Alluxio数据随机访问方法的研究
2020-07-06魏占辰黄秋兰孙功星刘晓宇
魏占辰,黄秋兰 ,孙功星,刘晓宇,王 轶
1.中国科学院 高能物理研究所,北京 100049
2.中国科学院大学,北京 100049
1 引言
随着信息技术的发展,与人类生产、生活密切相关的数据呈现爆炸式的增长,大数据逐渐成为推动技术变革和时代发展的关键。数据量的增长使数据处理和存储技术得到蓬勃发展,如何高速访问并统一管理数据,成为数据分析师和软件工程师首要解决的问题,因此Alluxio[1]应运而生。
Alluxio 是一个新兴的、以内存为中心的分布式存储系统,面向大数据生态圈,被设计成为计算程序访问内存数据以及底层存储系统数据的统一接口[2]。Alluxio能够与多种底层存储系统(例如HDFS、GlusterFS、Ceph)和计算框架(例如Hadoop MapReduce、Spark)兼容,使大数据应用得到极大的性能提升。因此Alluxio在互联网领域中得到了广泛的应用,引起了科研人员的极大兴趣。目前,Alluxio 的研究内容主要集中在Alluxio 的 应 用[3-5]、提 高 Alluxio 的 可 用 性[6]和 改 进Alluxio的缓存策略[7]等方面。
与HDFS设计理念一致,Alluxio简化了文件系统实现,提供Java 接口支持文件的随机读取和顺序写入,不支持文件的随机写入[8]。但在某些大数据应用中,尤其是科学计算等数据分析应用通常需要支持随机读写(例如高能物理中广泛使用的ROOT 框架[9])。由于科学计算历史久远,部分代码难以快速修改适应Alluxio 数据访问接口。虽然Alluxio 支持通过FUSE 挂载到根文件系统上,但挂载后的文件系统仍不支持随机写入[10],并且FUSE本身性能较差,严重制约了读写性能。因此在这些领域,Alluxio的应用受到了一定限制。另外,传统的基于Java 数据流接口无法灵活利用现有的新式高性能数据访问技术(例如内存映射、Java NIO等),仍有较大性能提升空间。
本文针对Alluxio 不支持数据随机写入的问题,在现有数据访问模式基础上,提出一种新的Alluxio 数据随机访问机制。该机制能够使传统程序适应新的存储系统,用户也可以利用该机制在数据分析时灵活使用各类数据访问技术,从而提高数据读写时的效率。
2 相关研究情况介绍
Alluxio采用了主-从式架构,架构如图1所示,主节点AlluxioMaster 管理文件系统的元数据,包括文件基本信息、数据块及副本情况、工作节点情况等;从节点AlluxioWorker 管理本机实际存储的数据块副本,监控存储空间大小,按照一定策略调整副本,同时也负责与底层存储系统的数据传输。Alluxio可映射底层存储系统的文件结构,管理底层存储系统的数据,使用Alluxio接口读取数据时能够在Alluxio 中自动缓存一份数据。Alluxio 使用了动态副本机制,其副本数量随着分布式系统中数据访问情况和节点存储空间情况动态增加或减少。
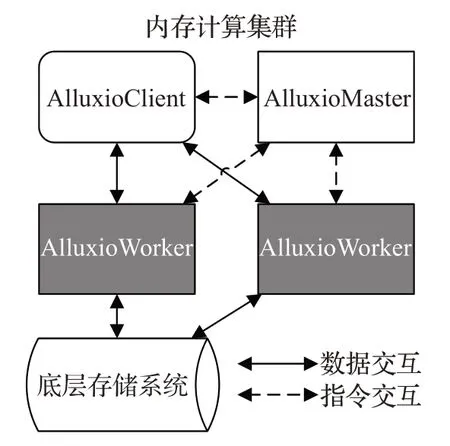
图1 Alluxio文件系统结构图
Alluxio 提供基于Java 语言的数据访问接口,文件数据被抽象为数据流,Alluxio 的文件管理单位为数据块(Block),读写过程如图2、图3所示,具体步骤在图中以序号标出,其中虚线箭头表示各组件间的指令交互,实线箭头表示数据交互。在读取数据时,客户端首先向AlluxioMaster请求文件元数据,通过元数据可获知文件的位置以及副本情况。如果该文件在本地有副本数据(即本地数据块命中),则直接打开该文件进行读写;如果不存在本地副本数据,则通过本地AlluxioWorker 向有副本的节点或底层存储系统请求数据(即远程数据块命中或底层存储系统数据块命中),并在本地创建一个副本,读取数据的同时向本地副本写入相应数据。当写入数据时,客户端通过本地AlluxioWorker 创建一个副本,并直接向其写入数据,根据写入策略,AlluxioWorker还将决定是否向底层存储系统写入该数据,以及以同步还是异步方式向底层存储系统写入数据。若Alluxio-Worker发现本地存储空间不足,则会按照一定策略清除部分副本数据,以满足新副本的写入所需的存储空间。如果在数据读写过程中,客户端所在节点没有本地AlluxioWorker,则所有数据传输均通过网络向相关节点通信,并且不会在本地创建任何副本。

图2 Alluxio标准数据读取流程图

图3 Alluxio标准数据写入流程图
3 Alluxio随机读写机制的设计与实现
当Alluxio 客户端和AlluxioWorker 不在同一节点时,数据访问完全通过网络,失去了使用内存缓存数据的优势,因此在使用本文的Alluxio随机读写机制时,需要保证Alluxio客户端运行在Alluxio集群内。由于数据随机读写的场景大多需要保证文件完整、不被拆分,同时为保证随机读写应用场景和Alluxio场景下文件含义的一致性,本文仅讨论一个文件只包含一个数据块的情况下的数据随机读写。
本文提出的Alluxio随机读写机制是在原有的数据访问基础上实现的,通过改变副本数据创建、缓存的时机,将对Alluxio 文件系统中的文件读写转化为对本地缓存数据块的读写。在使用Alluxio随机读写时需要两步:(1)获得Alluxio文件及数据块与本地缓存的数据块映射关系,本文设计了AlluxioService模块完成该功能;(2)执行计算任务的用户程序完成对本地数据块的访问。由于数据块在本地以文件形式存储在ramfs 或tmpfs文件系统中,因此可以选择通过read、write等系统调用进行文件读写或者使用内存映射技术访问文件数据,从而获得随机读写的支持、更好的访问效率和更大的灵活性。
3.1 数据写入过程
Alluxio 的数据写入过程分为文件创建、数据块申请、数据写入、数据块提交、文件关闭等几个过程,如图4所示,详细步骤以序号标出,虚线箭头表示指令交互,实线箭头表示数据交互。在写入文件时,AlluxioService首先会向AlluxioMaster 发送文件创建请求(FileCreate-Request),在Alluxio 文件系统的名字空间中加入该文件,并收到AlluxioMaster返回的URIStatus对象(文件元数据)。然后AlluxioService 向AlluxioMaster 为该文件请求分配一个新的数据块,获得该数据块ID,并向本地AlluxioWorker 发送创建本地数据块请求(LocalBlock-CreateRequest),AlluxioWorker 负责为该数据块预留足够的存储空间,返回响应(LocalBlockCreateResponse),响应信息中包含了数据块的本地临时存储路径。通过该路径,用户程序通过本地文件系统对该文件进行随机数据写入。在数据写入完成后,AlluxioService向Alluxio-Worker 发送数据块完成请求(LocalBlockCompleteRequest)关闭数据块,AlluxioWorker将其移动到固定存储位置,并向AlluxioMaster注册提交该数据块信息。在所有数据块提交完成后,AlluxioService 向AlluxioMaster发送关闭文件请求(FileCompleteRequest),AlluxioMaster 更新该文件的元数据,此时该文件的所有数据及元数据信息都可以在Alluxio中访问。

图4 Alluxio数据随机写流程图
3.2 数据读取过程
Alluxio 的数据读取过程为获得本地数据块的路径进行文件读写,若所访问文件没有本地数据块时,则先完成本地数据块的缓存。首先AlluxioService向Alluxio-Master请求文件的元数据信息,得到URIStatus对象,该对象中包含了该文件的所有数据块ID。通过数据块ID,AlluxioService 再向 AlluxioMaster 请求某个数据块的基本信息,得到BlockInfo对象,该对象中包含了该数据块的所有位置情况。根据数据块存储位置情况,有本地数据块命中、远程数据块命中、底层存储系统数据块命中三种不同的处理方式。
3.2.1 本地数据块命中
当数据块位置信息中包含本地的AlluxioWorker时,表明本节点上缓存了该数据块。AlluxioService 通过向本地AlluxioWorker 发送打开本地数据块请求(LocalBlockOpenRequest),得到响应(LocalBlockOpen-Response),其中包含该数据块对应的本地文件路径,用户程序由此读取本地文件系统中的数据,如图5 所示,各步骤以序号标出,虚线箭头表示指令交互,实线箭头表示数据交互。
3.2.2 远程数据块命中

图5 本地数据块命中数据读取流程图
当数据块位置信息不为空,但不包含本地的Alluxio-Worker 时,表明可通过网络将该数据块从其他Alluxio-Worker 缓存至本地。AlluxioService以数据写入的方式创建一个本地数据块,随机选择一个存有该数据块副本的AlluxioWorker 请求数据写入本地,然后与本地数据块命中时的方式一致,获得本地数据块的存储路径,具体过程如图6 所示,各步骤顺序以序号在图中标出,虚线箭头表示指令交互,实线箭头表示数据交互。

图6 远程数据块命中数据读取流程图
3.2.3底层存储系统数据块命中
当数据块位置信息为空时,表明数据位于底层存储系统中。此时AlluxioService以数据写入的方式创建一个本地数据块,通知AlluxioWorker 从底层存储系统读取数据并写入该数据块中,然后与本地数据块命中时的方式一致,获得本地数据块的存储路径,详细过程如图7所示,各步骤顺序以序号形式标出,其中虚线箭头为指令交互,实线箭头为数据交互。
3.3 高效读写本地数据块文件
为进一步提高数据的访问性能,本文在提供本地数据访问时引入了内存映射技术,从而获得更好的访问效率。

图7 底层存储系统数据块命中数据读取流程图
3.3.1内存映射技术概述
内存映射[11]是操作系统内核提供的将文件内容映射到进程线性地址空间的技术,是POSIX 标准接口之一,对应系统调用为“mmap”。内存映射技术主要用于提高IO性能,操作系统使用该技术加载进程及动态库,用户也可以使用该技术进行高效的进程间数据共享。
3.3.2与文件读写接口对比
为减少对磁盘等低速存储设备的反复读写,保护设备,提升IO 性能,Linux 内核使用了页缓存机制在内存中保存访问过的文件数据(除DirectIO 模式外)。由于页缓存在内核地址空间中,因此会有额外的一次数据拷贝。内存映射技术将文件的读写转换为内存地址空间的访问,无需额外的系统调用(如read、write等),减少了数据拷贝次数[12],因而比传统文件读写更高效。
当用户进程在顺序读取文件时,内核会根据一次读取数据的大小预读数据到页缓存中,以提高读取性能。当使用内存映射技术时,虽然内核将文件数据直接映射到了进程地址空间中,但该段空间是不包含任何页的线性区,访问数据时会首先触发缺页中断,中断处理程序“请求调页”并读入数据之后,才能够完成访问[13]。随着硬件技术的发展,缺页中断的处理开销已经大于内存数据拷贝。因此,在顺序读取文件时通过合理的读取方法,read调用能够获得比内存映射更好的性能(在4.1小节可得到验证)。
3.4 Alluxio随机读写机制的特点分析
基于以上的分析,Alluxio 新式随机读写机制能够为用户带来高效性和便捷性,使用户在集群环境中充分利用内存加速计算性能。除此以外,新式接口还保证了以下特性。
(1)完全数据本地化:通过预先缓存的策略,新式接口保证了任何读写情况下的数据本地化,使依赖于本地文件系统路径的传统数据分析程序得以运行。用户能够便捷地将原有算法或程序移植到Hadoop、Spark等分布式平台中,从而快速实现文件级并行化。
(2)可靠性:新式接口完全依赖于原有的数据访问机制,并未打破Alluxio 的数据访问流程,因此使用新的机制成功完成的数据读写过程不会带来新的可靠性问题。
(3)容错性:如果在读取本地数据过程中发生异常,不会对数据和Alluxio系统造成任何影响。如果在写入本地数据时发生异常,则会通知用户程序进行数据重写,AlluxioWorker会定期清理未正确关闭的数据块。在读取远程数据及底层存储系统数据时需要先在本地进行数据缓存,发生异常时,处理方法与数据本地写入时一致。

图8 数据本地化写入性能对比图
4 实验测试及结果分析
本文提出的Alluxio数据随机读写机制是在Alluxio 1.6.1版本基础上实现。经过进一步调研,新式数据读写机制依赖的原有数据访问机制在更新版本的Alluxio中没有变化,因此能够适配更新版本的Alluxio。
本文的实验环境是一个5 节点组成的集群,包括1个 AlluxioMaster 节点和 4 个 AlluxioWorker 节点。为方便测试Alluxio集群运行情况,还部署了Hadoop-2.7.5和Spark-2.4.0,共4 TB的HDFS存储空间,使用Spark自带的Standalone模式进行任务调度。AlluxioMaster、NameNode和 Standalone Master 部署于主节点上,AlluxioWorker、DataNode 和Standalone Worker 部署于从节点上,各个节点的软硬件情况如表1所示。
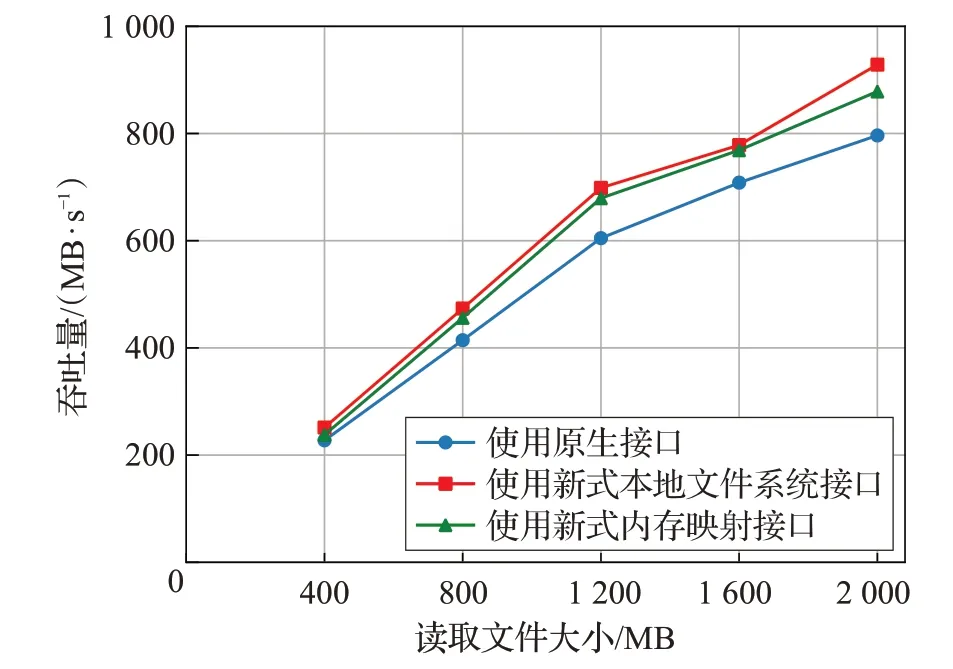
图9 数据本地化读取性能对比图

表1 测试集群软硬件环境
为验证Alluxio 新式数据随机读写接口的性能,本文在测试环境中对其进行了测试,内容包括:Alluxio新式接口的读写性能、集群作业读写性能测试和Alluxio在实际应用中的性能测试。
4.1 读写性能测试
本文通过测试读写不同大小文件时的数据吞吐量,对比Alluxio原生接口和新式接口读写数据的性能。测试过程分为数据写入和读取两部分,由于数据写入过程为完全本地化的,而数据读取有本地化和非本地化两种情况,因此测试过程分为本地化写入、本地化读取和非本地化读取进行,测试情况如图8、图9、图10所示。
由图中可知,在数据本地化写入时,使用新式接口通过文件系统写入数据和Alluxio原生接口写入数据时的性能基本一致,而使用新式接口以内存映射方式写入数据时,可获得约138.6%~247.6%的性能提升。在数据本地化读取时,使用新式接口可获得约12.4%~16.6%的性能提升。在数据非本地化读取时,由于新式接口先要将数据完整缓存至本地才能读取,因此整体性能比原生接口下降了6.2%~11.2%。
4.2 模拟集群作业测试
为测试Alluxio原生接口和新式接口在集群中的整体读写性能,本文在Spark 上实现了一个简单测试用例模拟集群作业读写。测试文件为大小1 GB的二进制随机数据文件。模拟读测试为读取该文件数据,对数据求余并按余数统计随机数的出现次数。模拟写测试是使用随机数生成器生成该文件。图11和图12为各项测试的性能对比,并行任务数与作业处理的文件数一致,以单个任务的平均执行时间评估性能。

图11 集群作业读取性能测试图

图12 集群作业写入性能测试图
由图中可知,使用本文提出的Alluxio 数据随机访问接口,不仅能够满足数据的读写需求,还能够进一步提升计算性能。在使用新式接口读取数据时,通过本地文件系统访问数据的性能提升了约2%~4%,使用内存映射访问数据的性能提升了约22~26 倍。在使用新式接口写入数据时,通过本地文件系统访问数据的性能提升了约32.8%~39.2%,使用内存映射访问数据的性能提升了约8~9倍。
4.3 实际应用测试
高能物理计算是典型的数据密集型计算,通常采用计算和存储分离的模式[14],由计算节点构成计算集群,通过高速网络从存储系统中访问数据,存储系统通常采用高性能分布式文件系统如Lustre 和GlusterFS,挂载到计算集群中,使各个节点的文件系统结构一致。作业调度系统对用户提交的作业进行统一调度和管理,为保证作业高吞吐量,调度系统对作业所用计算资源进行了限制。计算、存储分离的模式在高并发场景下,网络的性能和拥塞程度成为计算的瓶颈,因此高能所也在探索基于Hadoop计算与存储结合的高能物理计算模式[15]。
实际应用测试选用了高能天体物理中的高海拔宇宙线实验(Large High Altitude Air Shower Observatory,LHAASO)[16]数据触发判选软件进行测试,每个源文件大小约为1 GB,包含约4 000 万个物理事例,该程序需要在这些事例中筛选出可能有物理意义的事例。数据处理过程受传统计算集群的资源限制被划分为5 个步骤,对应5 个数据处理子程序,子程序之间的中间数据通过文件进行传递。
本实验在原有软件基础上使用了Spark实现了文件级并行的分布式LHAASO 数据触发判选程序,测试过程对比了使用Alluxio、HDFS 和Lustre 存储中间数据情况下的性能,如图13所示,并行任务数与作业处理的文件数一致,以单个任务的平均执行时间评估性能。

图13 高能物理作业性能测试对比图
由图中可知,在实际的高能物理作业中,使用Alluxio 能够有效提升作业整体的性能。与使用HDFS存储中间数据相比,使用Alluxio 能够提升17.7%~192.0%的性能;与Lustre 相比,使用Alluxio 能够提升115.2%~490.0%的性能。
5 结束语
本文针对Alluxio不能满足特殊场景下的数据随机访问,以及Alluxio 原生接口不能完全发挥内存性能的问题,深入研究了Alluxio的数据读写过程,提出了一种新的高性能数据访问方法。通过改变数据访问和缓存的时机,将对Alluxio 中的文件访问转化为对本地内存文件系统中的文件访问,并在此基础上使用内存映射技术提供更高性能的数据读写接口,从而实现了数据的随机访问和高性能读写。在数据读写测试和实际应用测试中,该方法在保证数据随机访问的正确性同时,取得了很好的性能提升。Alluxio的高性能数据随机访问接口对于在以高能物理为代表的科学大数据应用中的使用和推广具有重要意义。
