一种针对复杂排班的考勤指标统计方法
2020-07-04王明兴朱荣晨韩玮朱竹芳
王明兴 朱荣晨 韩玮 朱竹芳


摘要:倉储、物流、工厂车间等,通常通过设置班次来进行工作时间安排。在上班时间不固定、存在跨天排班、考勤机不分进出、刷卡记录存在重复或漏刷卡等特殊情况时,很难对刷卡记录进行分类,从而直接影响了考勤指标计算的准确性。本文针对这种情况提出了一种根据排班时间对刷卡数据进行分类和考勤计算方法。经实践证明,可以准确高效的计算出各种考勤指标。
关键词:考勤系统;复杂排班;刷卡数据分类
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)15-0028-02
1引言
现有的考勤解决方案,大多针对生物识别或电子身份识别在考勤中的应用进行研究,对复杂情况下的考勤数据清理、分类及计算的研究比较少。但在一些特殊情况下,如仓储、物流、车间等行业的操作人员上下班时间具有很大的不确定性,具体表现在上班时长不固定、上班开始时间不固定,所以一般会通过排班来确定这类人员的考勤时间。而现在流行的一些考勤设备如人脸识别设备往往比较昂贵,当上班区域较多、区域间距离较远时,如果针对进和出分别安置设备,就会直接导致成本的上升。而且上班时间的不确定性,又导致了不能按照时间来对考勤设备进行虚拟的出入划分。所以,当不使用可以区分进出的考勤机时,考勤数据的进出识别就变得很困难,再加上存在重复刷卡和漏刷卡等特殊却常见的情况,问题就变得更加复杂。
考勤系统作为现代化企业不可或缺的人员管理系统,使用率极高,有很大的市场空间。不同企业之间的考勤系统虽然架构不同,但是仍然有许多相似之处。所以如何提高系统的普使性和复用性,在系统改动较少的情况下,满足各种用户各种场景的需求,对一套考勤系统进行推广也尤为重要㈣。本文针对复杂考勤场景提出了一种,根据排班时间对考勤刷卡数据进行清理、分类和计算的方法,经实践证明,可以准确高效地完成复杂场景下的考勤指标计算,同时可以有效提高系统的适用性。
2模型定义
2.1数据源设定
为了适应更多的使用场景,综合考虑各种可能出现的特殊情况。对本文讨论的模型进行如下设定:
1)人员上下班时间根据排班时间确定,未设定的使用缺省排班设置;
2)存在跨天的排班,排班的开始时间不固定;
3)两个排班之间不存在重叠部分;
4)原始刷卡记录不分出入;
5)存在重复刷卡的现象;
6)存在漏刷卡的现象;
7)历史排班可能调整,调整后要能够正确计算出新结果。
8)历史刷卡数据可能存在人工补录的情况,补录后要能够正确计算出新结果。
2.2存储模型
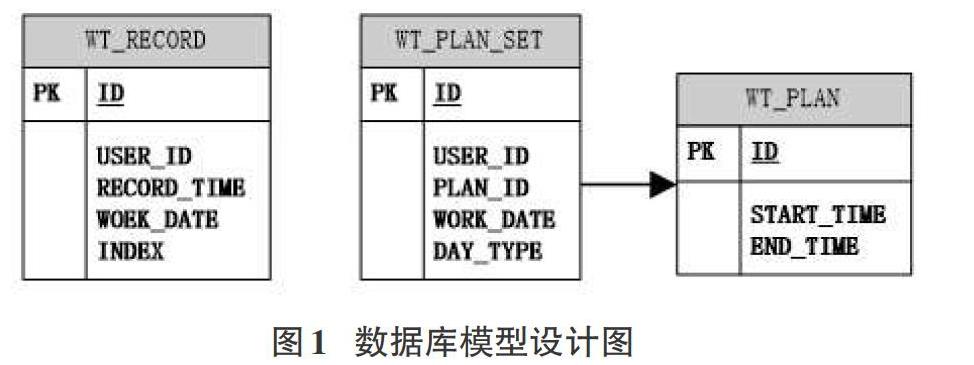
设计数据库存储模型如下图1所示。
原始刷卡记录的字段work_date和index为空值,用于在数据分类之后存储分类信息。work_date对应考勤日期,index对应当日的第几段排班。
2.2计算模型
由于存在跨天排班的情况,所以计算存在滞后性,在实际中一般滞后一天,即在T天计算T-1天的考勤,为了计算T-1天的考勤,先对数据进行如下整理:
1)对所有的刷卡记录按时间升序排列,形成刷卡数据集合
最后由公式可以计算出T+1天的对应的所有缺勤时间段,同理可以得出其他考勤指标的全天时段。
4结束语
本文针对不分进出且存在跨天多次任意排班的复杂场景进行刷卡数据清理和格式化的算法设计,经实践证明可以很大程度上解决打卡数据的有效性判断及进出划分的问题,对于边界处的模糊数据也具有较好的分辨性能。解决了复杂场景下考勤计算的重要环节,具有效率高、准确性好、适用性广的优点。
