基于随机游走的级联网络社区发现算法
2020-07-04王亮杨海陆陈德运
王亮 杨海陆 陈德运


摘要:随着Web 2.0的不断推广以及社交应用的不断普及,在线社交网络结构分析得到了各领域学者的广泛关注。社区是网络中内嵌的密集群组,保证了社区内部用户的强相关性和一致性,因此广泛应用于病毒防护、商品推荐等现实系统。本文提出一种基于随机游走的级联网络社区发现算法,主要解决非直连节点间的相似性度量问题。提出一种基于2-hop随机游走的局部可达性计算方法,通过对游走终点一致的节点进行层次聚类,社区结构可在较短的时间内迭代生成。实验结果表明,本方法在级联网络社区发现中具有较高的性能和效率,对星形社区具有较高的匹配性。
关键词: 级联网络; 社区发现; 随机游走; 层次聚类
【Abstract】 With the continuous promotion of Web 2.0 and the continuous popularization of social applications, the structural analysis of online social networks has attracted extensive attention from scholars in various fields. Community is a dense group embedded in the network, which ensures the strong correlation and consistency of users within the community. Therefore, it is widely used in virus protection, commodity recommendation, and other practical systems. In this paper, a cascade network community discovery algorithm based on the random walk is proposed to solve the similarity measurement problem of non-directly connected nodes. The paper proposes a local reachability calculation method based on 2-hop random walks. The community structure can be generated iteratively in a short time by hierarchical clustering of nodes with consistent endpoints. The experimental results show that this method has high performance and efficiency in cascaded network community detection and has a high matching to the star community.
【Key words】 cascaded network; community detection; random walks; hierarchical clustering
0 引 言
隨着5G技术的不断推广以及“互联网+”战略的积极部署,微信、微博等社交网络早已融入人们的日常生活及学习之中。更多的人选择在社交网络进行交流、发表观点,社交网络早已成为现实世界在网络空间的真实缩影,社交网络结构分析也因此成为各学科领域的研究热点和学术前沿问题。
社区结构(Community)是社交网络中的重要结构,社区内部用户之间的链接较为紧密,社区之间的用户链接较为稀疏。从这一角度来看,社区结构可以广泛应用于诸如商品推荐、病毒防护等应用系统。例如,可以对社区内部用户推荐相似的产品,或切断社区之间的联系降低病毒的传播范围等。级联网络是一种特殊的社交网络,微博网络就是典型的级联网络,这种网络中普遍存在星形结构(形成于对高影响力用户的大量关注),就使得社区内部节点可能不具有直接联系,这给社区识别任务带来了极大的挑战。
目前来看,基于随机游走的动态算法能够有效解决这一问题,其基本原理利用了社区结构对“游走者”的捕获作用。当“游走者”游走到社区边缘时,由于社区内部链接远大于社区间的链接,因此“游走者”有极大的概率再次游走回社区内部。由此可见,位于相同社区的两节点,其随机游走的探测路径应该具有较高的重叠性。Rosvall等人[1]引入一种信息论方法,揭示加权有向网络中的社区结构。通过将网络随机游走的概率流作为真实系统中的信息流,社区结构可以由概率流压缩生成。Huang等人[2]探讨随机游走思想在构建社区模块度函数中的应用。在这种方法中,模块度函数被定义为社区引起的马尔可夫随机游走和一个零概率模型的之间的差异。刘阳等人[3]提出一种边权预处理方法,根据多重随机游走对网络连接的遍历情况重新衡量网络边权。预处理后的边权作为网络拓扑的有效补充信息,能够将网络结构去模糊化,从而改善现有算法的社区发现性能。杨海陆等人[4]设计了一种基于2-hop互随机游走的异质网络节点相似性度量函数,通过将相似性函数推广到层次聚类并设计相应的相似矩阵校准方案,异质社区识别任务可以在较短的时间内迭代完成。辛宇等人[5]提出一种改进的语义社会网络重叠社区发现随机游走策略,以LDA(Latent Dirichlet Allocation)算法为基础建立语义空间,实现节点语义信息到语义空间的量化映射。在后续的研究中,Xin等人[6]提出适应性随机游走概念,将模型推广至动态社区识别任务。在最近的研究中,Okuda等人[7]提出了一种带约束随机行走相似性度量方法检测图的社区结构。其基本思想是随机游走能够途经相似节点的起始点属于同一社区的可能性较大。
上述方法在社区识别领域得到了普遍认可,但忽略了以下两方面要素。首先,没有对游走长度进行约束,这使得“游走者”能够捕获的信息处于不确定状态;其次,上述方法普遍拒绝“游走者”重复访问已经通过的顶点,而这一情况在密度较高的社区中是普遍存在的。
为了解决这一问题,提出一种基于2-hop结构探测的社区识别方法。基本思路是:如果“游走者”的起始点位于相同社区,则“游走者”能够囊括的2-hop探测节点集应该具有较高的重叠性。该思想充分考虑了节点的直接相似性和结构相似性,因此识别出的社区结构具有一定的稳定性。
1 定义及算法
3.2 真实网络社区识别结果
本部分选择新浪微博作为实验数据。由于新浪微博API存在爬取数量限制,因此使用Python编写了面向网页的微博爬虫程序,结果存于MySQL数据库中。
收集了2018年10月~2019年9月共12个月用户所发的微博帖子,选取任意网络节点作为初始爬取节点,采用自底向上的方法爬取初始节点的6层邻居结构。向上爬取的主要原因在于大多数微博用户的粉丝数量远远大于关注数量,因此如果向下爬取数据,广度优先会造成过大的时间开销。最终爬取到的数据量较为庞大,因此过滤掉了微博数少于50的用户以及关注数/被关注数少于5的用户。
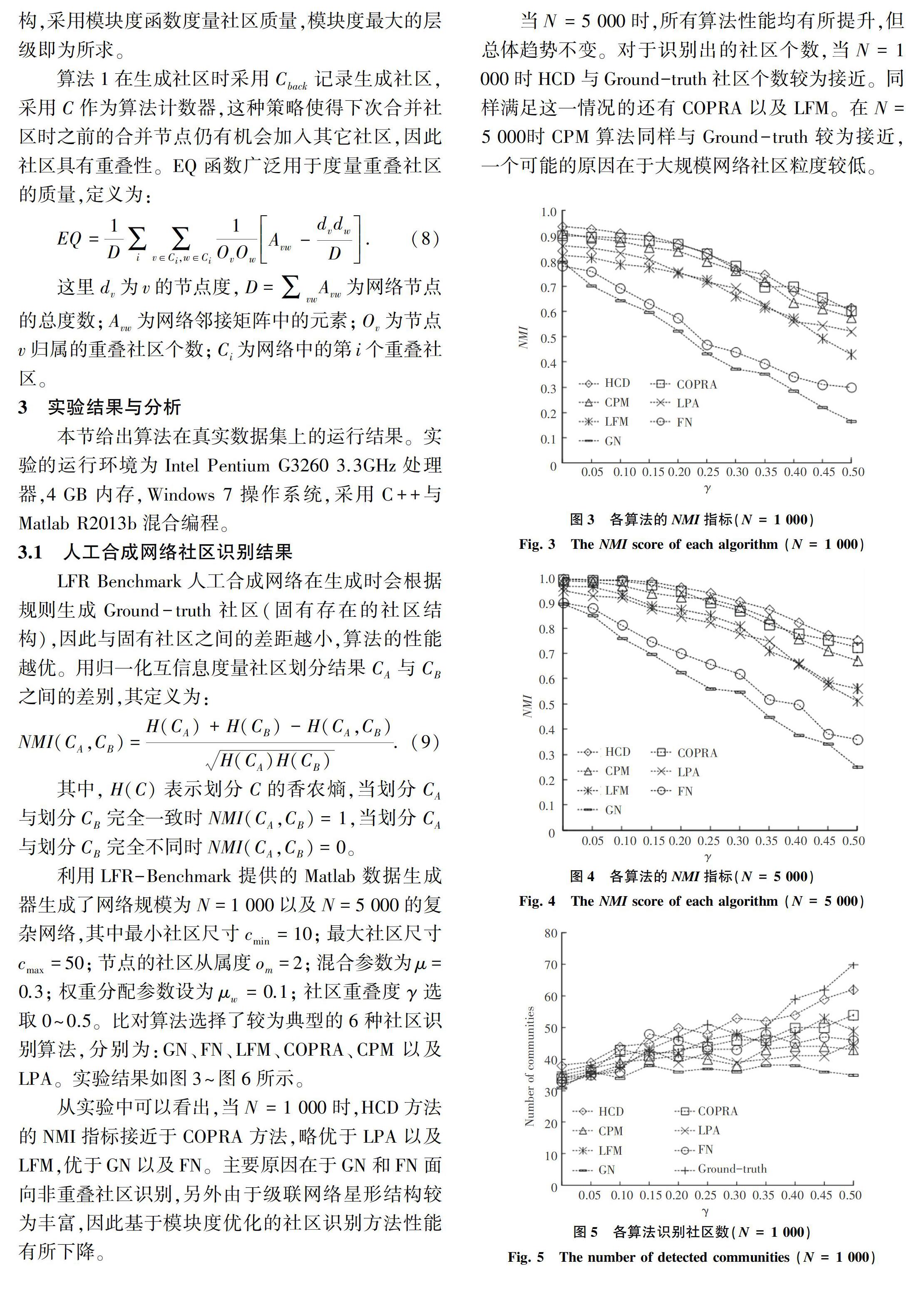
研究中关注于社区模块度以及社区个数,实验结果如图7、图8所示。
从实验结果来看,HCD算法的模块度函数略小于COPRA,优于其他5种方法。原因在于微博网络具有典型的级联特性,星形结构更加清晰,因此社区粒度普遍较低。HCD识别社区个数较少,这表明HCD的局部游走策略是有效的,并且具有较高的效率。
为了更清晰地给出HCD算法的社区识别结果,研究还选择了节点数较少的Football网络给出社区识别结果。如图9所示,HCD识别出的社区结构具有较低的粒度,但总体来看,仍然保证了较高的紧密性。
4 结束语
针对基于随机游走的社区识别方法无法有效识别级联网络中的星形社区这一问题,提出一种带约束随机游走的社区识别方法HCD。首先定义了随机游走的探测集合以及探测集重叠性度量函数,然后设计了一种面向社区迭代的相似性度量函数以及相似性矩阵校准方法,最后采用层次化聚类方法输出社区结果。在人工合成网络和真实网络上的实验结果表明,HCD算法能够有效地度量非直连节点之间的相似性,在星形社区识别中具有较高的性能和效率。
参考文献
[1] ROSVALL M, BERGSTROM C T. Maps of random walks on complex networks reveal community structure[J]. Proceedings of the National Academy of Sciences of the United States of America, 2018,105(4): 1118.
[2]HUANG L C, YEN T J, CHOU S C T. Community detection in dynamic social networks: A random walk approach[C]//International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2011). Kaohsiung,Taiwan:[s.n.],2011: 110.
[3]劉阳, 季新生, 刘彩霞. 网络社区发现优化: 基于随机游走的边权预处理方法[J]. 电子与信息学报, 2013, 35(10): 2335.
[4]杨海陆, 张健沛, 杨静. 利用2-hop随机游走进行异质网络社区发现[J]. 哈尔滨工程大学学报, 2015, 36(12): 1626.
[5]辛宇, 杨静, 谢志强. 基于随机游走的语义重叠社区发现算法[J]. 计算机研究与发展, 2015, 52(2): 499.
[6]XIN Y, XIE Z Q, YANG J, et al. An adaptive random walk sampling method on dynamic community detection[J]. Expert Systems With Applications,2016, 58: 10.
[7]OKUDA M, SATOH S, SATO Y, et al. Community detection using restrained random-walk similarity[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019: 1-1( Early Access ).
