基于顺序验证提取关键帧的行为识别
2020-07-04张舟吴克伟高扬
张舟 吴克伟 高扬


摘要:人类行为识别作为视频分类中的重要问题,正成为计算机视觉中的热门话题。由于视频信息较多,有的视频冗余信息过量,判别性帧较少,因此如何无监督地提取关键帧对于行为识别至关重要。为此,本文提出了一种新的基于顺序验证的关键帧提取方法,并将其应用到行为识别中。首先,本文定义了一种顺序验证的模块,验证局部区间中帧的顺序,学习局部区间中帧的关键性描述,接着将其整合得到整段视频中每一帧的关键性描述;其次,根据学习到的视频帧关键性描述提取关键帧;最后通过实验讨论分析提取多少关键帧对行为识别最有利。实验结果表明,本文的方法在UCF-101上可以达到95.40%,在HMDB51上可以达到68.80%,均优于当前的一些先进的方法。
关键词: 行为识别; 关键帧提取; 顺序验证; 关键性描述
【Abstract】 As an important issue in video classification, human action recognition is becoming a hot topic in computer vision. Since there are many video information, some videos have redundant information and few discriminative frames, so how to extract key frames unsupervised is very important for action recognition. To this end, the paper proposes a new key frame extraction method based on order verification and apply it to action recognition. First, this paper defines an order verification module that verifies the order of frames in a local interval, learns the key description of the frames in the local interval, and then integrates them to obtain the key description of each frame in the entire video; Second, key frames are extracted based on the learned key descriptions of the video frames; Finally, the paper discusses experimentally how many key frames are extracted to be most beneficial for action recognition. Experimental results show that the proposed method can reach 95.40% on UCF-101 and 68.80% on HMDB51, which are all better than some current advanced methods.
【Key words】 action recognition; key frame extraction; order verification; key description
0 引 言
视频中的人体行为识别是计算机视觉领域的一项既基础又具有挑战性的任务,最近几年正被广泛应用于视频监控、人机交互、医疗看护等领域[1]。这个任务是指从视频序列中提取相关的视觉信息,并用合适的方式表达出来,然后通过对视觉信息的解释来分析和识别人类的行为模式。真实的视频大多以人类活动为背景,在视频某些时间段里背景比较复杂,很难准确、鲁棒地识别人类行为,因此行为识别仍是一个复杂的问题。
现有的深度学习模型,将行为识别任务视为多分类问题。其早期研究关注于利用卷积神经网络(CNN)来学习视频中行为的深度表达,包括双流CNN模型[2],隐双流CNN 模型[3],以及3D-CNN 模型[4]。卷积神经网络擅长于捕获场景的空间信息,然而其对时序信息的捕获能力不强。现有深度学习模型通常使用循环神经网络(RNN),尤其是长短期记忆网络(LSTM)模型来描述行为中时序信息。现有行为识别的难点在于,目标动作仅仅占长视频中的一小部分,同时运动目标被大量的背景信息干扰,因此,从长视频中提取行为发生的有效信息,成为行为识别的关键问题。
针对现有方法无法有效区分视频中时序背景混杂信息,导致行为识别准确率和效率不高的情况,研究发掘了一种基于长视频序列顺序验证的新的关键帧提取方法,并将这种方法应用到行为识别中去。 在此方法中,通过抑制视频中的低质量时序信息,学习到具有辨别性的视频帧的表示,提高行为表达的判决能力,从而实现可靠的行为识别。综上所述,本次研究做出以下贡献:
(1)本文提出了一种新的基于顺序验证提取关键帧的行为识别方法。其中,這种关键帧机制用于去除低质量背景复杂的冗余帧,然后将这种关键帧机制应用到行为识别任务中。
(2)本文设计了一种顺序验证的方法来学习视频帧的关键性描述。首先验证局部区间中帧之间的顺序关系,获取局部区间中帧的关键性描述;然后以某种方式结合各阶段局部区间中帧的关键性描述,得到整段视频中每一帧的关键性描述。
(3)本文进一步将关键帧提取应用到了行为识别上,并在UCF101和HMDB51这2个公认的数据集上进行实验验证。实验结果表明,在UCF101上提取12帧关键帧表现最好,识别精度为95.40%,在HMDB51上提取10帧关键帧表现最好,识别精度为68.80%,均优于目前大部分先进的方法。
1 相关工作
视频相比图像来说信息更加丰富,但是一个视频序列中冗余信息太多,如何高效准确地提取关键帧的信息对于很多任务都是至关重要的。与此同时人类行为识别是计算机视觉领域一个长期存在的课题,也是当今一个研究热点。在这部分,分别介绍了关键帧提取和行为识别两方面的相关工作。
(1)关键帧提取。许多早期的关键帧提取方法依赖于使用基于管道的分割,此类方法通常提取光流和SIFT特征。较早的方法[5]通过视频的光流检测了连续帧之间的相似性的局部最小变化。之后的方法通过在特征提取中使用关键点检测[6-7]改进了这一点,后者通过SIFT描述符提取局部特征,并汇总了关键点以实现视频中的关键帧提取。但是,所有这些方法都具有以下缺点:当相同的内容再次出现在视频中时,就可能会提取相似的关键帧。另一类方法是将视频帧的特征(如HS颜色直方图)聚类成组。这些方法通过从每个组中检测有代表性的帧来确定视频中的关键帧。Zhuang等人[8]提出了一种基于视觉内容和运动分析的关键帧非监督聚类方法。Vázquez等人[9]提出了一种基于频谱聚类的关键帧检测方法,该方法构建了一个图来捕获图像视频序列中的特征局部性,而不是依靠由2个图像之间共享的特征所计算出的相似性度量。最后由于CNN在图像分类中的流行,已将CNN引入视频的关键帧提取中。Mahasseni等人[10]首先將生成对抗网络(GAN)应用于视频中的关键帧提取。
(2)行为识别方法。同时,CNN在图像分析任务中深度特征提取的成功,为视频中行为分类的研究提供了灵感。CNN侧重空间模式的提取,可以有效增强行为特征在空间域上的表现能力,比如在ImageNet[11]数据集上预训练的Vggnet[12]、GoogleNet[13]和ResNet[14],并将其用作特征提取器。此外,Zhu等人[3]提出了一种新型的Hidden Two-stream CNN架构,隐式地捕获相邻帧之间的运动信息。Wang等人[15]提出了一种新的架构,称为外观-关系网络(ARTNet),以端到端的方式学习视频表示,ARTNet是通过堆叠多个SMART块来构建的。Shou等人[16]提出了一种轻量级的生成器网络,该网络减少了运动矢量中的噪声,捕获了精细的运动细节,实现了一种更具鉴别性的运动线索(DMC)表示。但是由于CNN对时序信息的捕获能力不强,而RNN具有学习帧之间时序关系的强大能力,尤其是LSTM网络由于其灵活的门机制,可以避免在反向传播过程中梯度消失或梯度爆炸。Li等人[17]提出了一个新颖的框架,通过结合CNN和LSTM来学习视频中的时序动态特征,从而达到增强行为识别的效果。Ng等人[18]通过实验证明,相较于传统的双流方法[2],加入LSTM整合时序信息可以显著提高行为识别的准确率。
(3)关键帧提取用于行为识别。视频并非每一帧都有对行为识别有利的信息,因此去除冗余帧,将关键帧机制加入行为识别任务有着重大的意义。Wang等人[19]提出了一种从视频序列中提取人类动作识别关键帧的新方法,主要利用研究提出的一种自适应加权亲和传播算法(SWAP),以提取关键帧,最后结合SVM进行行为识别。但是这种方法对识别精度贡献并不大,只是改善了识别速度。Zhou等人[20]提出一种实时的行为识别方法,通过这种从视频帧的时间窗口中检测关键帧的新算法来提高识别速度,再采用隐马尔可夫模型(HMM)来分析检测到的关键帧的时间关系,从而保证识别的准确性。同样,为了弥补高斯混合隐马尔可夫模型(GMM-HMM)需要定义高斯混合模型(GMM)和隐马尔可夫模型(HMM)分类的数量,从而引起的识别速度下降,Li等人[21]提出了一种基于关键帧的GMM-HMM运动识别方法,使用最小重建误差方法来确定关键帧的数量,从而减少GMM和HMM分类的数量提高识别速率。Zhao等人[22]提出一种新的基于关键帧提取和多特征融合技术的行为识别方法,既利用关键帧机制解决了数据冗余的问题,又通过多特征融合不同流的信息,提高了识别精度。Zhu等人[23]通过挖掘视频中关键帧所在视频段来提高识别正确率。Kar等人[24]采用含有时空网络和MIL框架的双流CNN来检测视频中得分较高的关键帧,进而应用于行为识别。
受到文献[25-26]采用顺序验证来进行行为识别的启发,且目前没有基于顺序验证来学习关键帧的方法,本文提出一种顺序验证的方法,提取视频中的关键帧,去除冗余信息,进而再将这种新的关键帧提取方法用于视频中的行为识别,实验结果表明本文的方法取得了较好的识别正确率。
2 模型框架
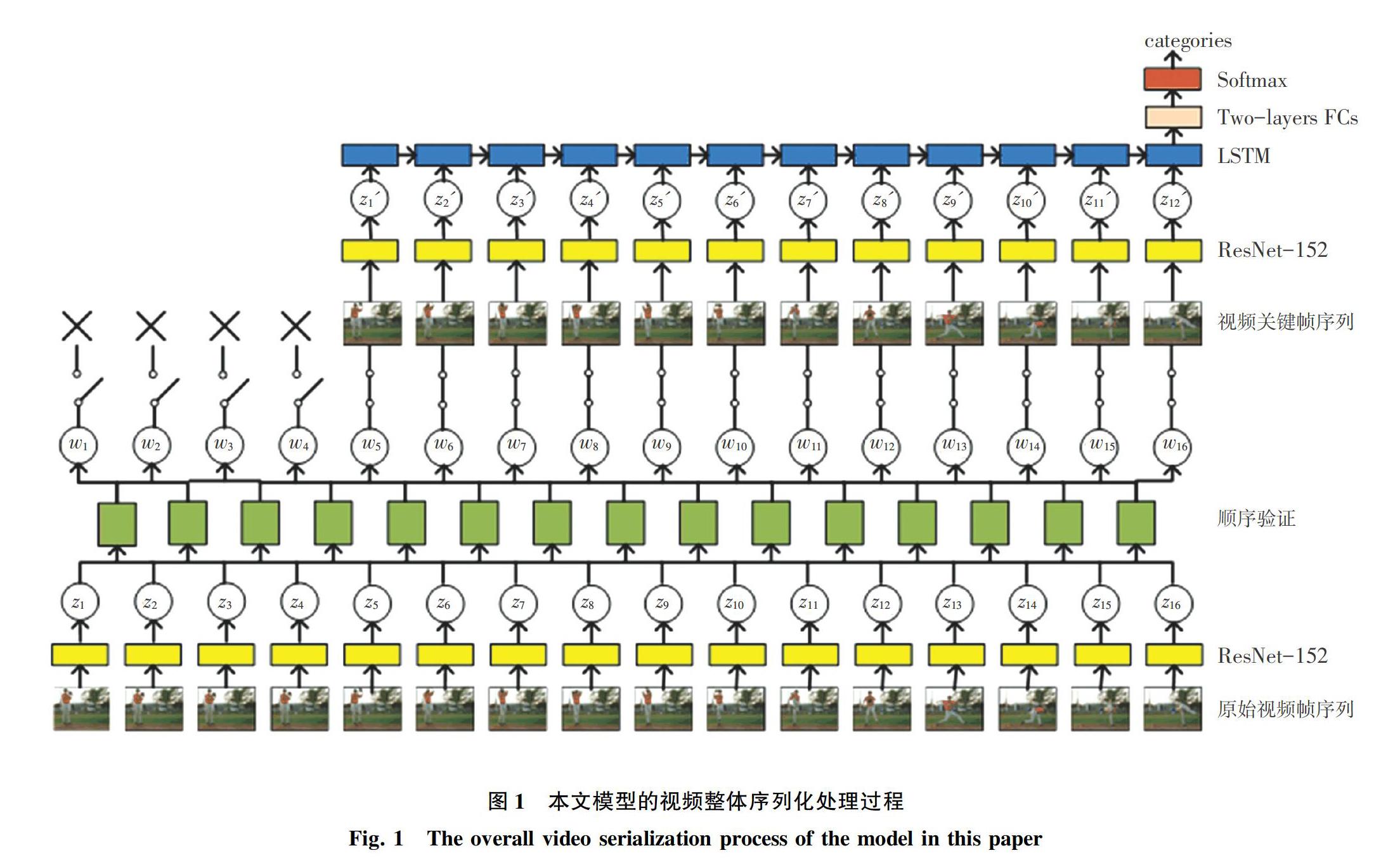
在本节中,首先对所提出的方法给出简要论述,然后将本文方法的每个部分进行详细阐明。这里,以UCF101数据集为例,研究得到的本文模型的视频整体序列化处理过程如图1所示。相应地,行为识别的网络架构可以分为以下4个模块:提取CNN特征(2.1节);顺序验证(2.2节);学习关键帧(2.3节);最终的行为识别(2.4节)。首先,采用CNN是因其在图像特征提取方面的成功应用;其次,设计了一个局部的顺序验证模型,通过对局部顺序验证结果的分析,计算局部区间中帧的关键性描述;再者,将局部区间中帧的关键性描述相结合,形成整段视频中帧的关键性描述,并进行关键帧提取;讨论截取关键帧的数目,提取出相应数目的关键帧;最后,设计了一种新的基于顺序验证的关键帧提取的行为识别框架来识别人类的行为。
本文模型的主要创新价值在于:
(1)提出了一种新的基于顺序验证的关键帧提取方法,并将其用于视频的行为识别中。
(2)为了有效估计视频帧的关键性,设计了一个顺序验证模块来验证局部视频段中帧之间的顺序。将局部视频段的长度设置为2个连续视频帧,通过对局部顺序验证结果的分析,计算局部区间中帧的关键性描述;再者,将每段视频内局部区间中帧的关键性描述相结合,形成整段视频中每一帧的关键性描述,并排序。
(3)为了达到最佳的识别效果,进行了多组对比实验分析提取关键帧的数目,最终确定在UCF101上每段视频提取12个视频帧,在HMDB51上每段视频提取10个视频帧。
2.1 特征提取
识别视频中的行为往往不需要通过视频中的所有帧,只需选择一些帧组成序列来代表这个视频。因此将一个有L帧的视频分成16=L/α个非重叠的单元,每个单元包含α个连续的帧。然后在每个单元中选择第一帧,组合形成帧序列V={vt},(t=1,2,…,16)。研究中提取这些视频帧的外观特征用于行为表达,为此,本文使用在ImageNet数据集上预训练好的ResNet-152模型,对已经重新调节大小为224×224的RGB图像序列进行预处理,对于第t帧提取输入最后一层全连接层之前的结果作为最终特征:zt,在此基础上,通过时序SVM网络对特征序列进行建模。
2.2 顺序验证
所提出的顺序验证模块如图2所示。由图2可知,该模块具有3个主要组成部分:二元组采样;使用时序SVM进行局部区间顺序验证得到局部区间内视频帧的关键性描述;将局部区间内视频帧的关键性描述整合到整段视频中,得到每个视频帧最终的关键性描述。对此可做阐释分述如下 。
3 实验
本节中,首先对数据集做了整体概述,然后阐述本文的实验过程及评价标准,最后對实验结果进行说明及讨论。
3.1 数据集
本文方法所用的数据集为UCF101[27]和HMDB51[28]。UCF101数据集包含13 320个视频,分为101个类别,使用9 990个视频用于训练,剩下的3 330个视频用于测试。UCF101数据集在行为类别方面提供了多样性,并且在目标外观和姿态、背景杂乱、光照条件等方面存在巨大的变化。
HMDB51数据集中包含6 849个视频,共51个行为类别,本文选取4 794个视频用于训练,其余的2 055个视频用于测试。HMDB51数据集在物体外观和人物姿态等方面变化多样,具有行为识别研究的挑战性。
3.2 实验设计及评价标准
为了准备训练特征集合,首先,依次提取各视频的RGB视频帧,并将分辨率重新调整为224×224。其次,使用ImageNet数据集上预训练的ResNet模型,提取外观特征,具体来说,本文取ResNet输入最后一层全连接层之前的特征作为LSTM模型的输入特征,该特征的大小为1×2 048,即LSTM模型的隐状态和记忆状态的维度为2 048。
本文实验所采用的PC机配置为Intel Core i7-5960X、CPU 3 GHz×8 cores RAM 8 GB、图像显卡为2张NVIDIA GeForce GTX 1080 Ti、Linux16.04操作系统。深度学习框架为Pytorch[29]。训练时,使用Adam算法,迭代次数为50,批处理大小为128,学习率初始化为10-3。
本文采用识别正确率,作为行为识别的评价标准,即统计一个类别中的所有视频的预测标记被识别为真实标记的数值,与预测视频总数的比值,作为该类别的识别正确率;最后使用所有类别正确率的均值,作为本文方法的识别正确率。
3.3 实验结果及分析
本文与当前比较先进的行为识别方法进行了对比, 根据加入关键帧机制与否,可以分为以下2组:
(1)带有关键帧机制的模型,包括:传统的双流CNN模型Two-stream mode[2],使用 CNN 进行还原分辨率隐式运动预测的模型Hidden Two-Stream[13],双流通道的时间池化模型Beyond Short Snippets Models[5],轻量级的生成器网络DMC-Net[16],通过堆叠多个可以同时对外观和时间关系进行建模的SMART模块的ARTNet[15]模型。
(2)带有关键帧机制的模型,包括挖掘识别关键帧所在视频段进行行为识别的模型 Key Volume Mining[23],使用深度网络获得的特征经过Adaptive Pooling的方法进行关键帧提取的AdaScan[24]行为识别模型。
不同方法的识别性能对比见表1。由表1分析可知,与当前一些优秀方法相比,本文方法所得到的识别正确率更高。相比于不带关键帧机制的方法而言,本文将关键帧提取加入到行为识别中去,在识别的过程中,因为减少了冗余帧,大大提升了识别的效率和准确率;相比于带关键帧的模型,本文先是精确定位到具有判别性的帧,相较于Key Volume Mining方法定位到关键帧所在视频段更为精确,再者较AdaScan采用pooling的方式对视频帧的关键性进行判定从而在测试过程中舍去冗余帧,本文既考虑前后帧之间的时序关系采用一种新的方法来判别帧的关键性,又通过LSTM的结构将视频中新的时序关系加以整合,显著提升了识别正确率。为了更进一步证明本文加入关键帧机制对行为识别贡献显著,本文在UCF101和HMDB51两个数据集上进行了消融实验,结果见表2。
通过表2可以看到:
(1)本文提出的关键帧机制在UCF101数据集上,随着从初始的16帧按照关键性描述由低到高逐一去除冗余帧,识别正确率一路上升,直到去除4帧时达到最高的识别正确率95.40%,此后继续去除则造成识别正确率下降,所以提取12个关键帧能达到最佳的识别效果;同理,在HMDB51数据集上,提取10个关键帧能达到最佳的识别效果。
(2)在UCF101和HMDB51两个数据集中,本文提出的加入关键帧机制的行为识别模型的行为识别正确率全面优于无关键帧机制的行为识别模型,UCF101上提升了4.2%,HMDB51上提升了5.1%。由此说明本文所提出的关键帧机制可以有效地提取有辨别性的特征,从而可以增强行为的表达。
2.2節中学习到了视频中每一帧的关键性描述,接着就是要进行关键帧提取,本次研究用实例图来表现关键帧提取的结果,如图3所示。在UCF101和HMDB51数据集中,分别随机选取代表3种行为的视频,观察其帧序列中每一帧的关键性描述,进而了解提取关键帧的过程。图3(a)上、中、下三组分别表示的行为是“Baseball Pitch”、“High Jump”和“Balance Beam”,图3(b)上、中、下三组分别表示的行为是“Throw”、“Kick Ball”和 “Golf ”。每组图片中,第一行表示原始视频帧序列;第二行表示视频帧对应的归一化之后的关键性描述,数字越大,代表这一帧关键程度越高;第三行尝试去除关键性最低四帧后重新组合的视频帧序列,即提取出的关键帧序列。
分析图3可以看出,前后两帧几乎没有变化的动作帧,关键程度都比较低,进而本文的模型会抓取对判别该行为贡献较大的帧、即关键程度较高的帧,更加体现本文模型的判别能力。
4 结束语
针对现有基于视频整体结构建模的行为识别方法,无法有效区分关键帧与冗余帧,造成行为表达效率低下,行为识别准确率不高的问题,本文提出了一种基于顺序验证提取关键帧的行为识别模型。通过在UCF101和HMDB51两个公认数据集上进行实验验证,可以证明本文的顺序验证模块能够识别关键帧,提高了行为表达的判决能力。在UCF101和HMDB51两个公认数据集上进行实验验证,与现有多种优秀的行为识别方法进行比较。实验结果表明,本文方法优于现有大部分行为识别方法。未来可以预期的是,本文的方法可以应用于更加复杂的视频场景中,如大型监控场景下的视频理解,异常检测等,将有助于维护公共安全等领域。
参考文献
[1] POPPE R. A survey on vision-based human action recognition[J]. Image and Vision Computing, 2010, 28(6): 976.
[2]SIMONYAN K , ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[J]. Computational Linguistics, 2014, 1(4):568.
[3]ZHU Yi , LAN Zhenzhong, NEWSAM S , et al. Hidden two-stream convolutional networks for action recognition[J]. arXiv preprint arXiv:1704.00389, 2017.
[4]JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(1): 221.
[5]KULHARE S, SAH S, PILLAI S, et al. Key frame extraction for salient activity recognition[C]//2016 23rd International Conference on Pattern Recognition (ICPR). Cancun,Mexico:IEEE, 2016: 835.
[6]LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91.
[7]GUAN Genliang, WANG Zhiyong, LU Shiyang, et al. Keypoint-based keyframe selection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2012, 23(4): 729.
[8]ZHUANG Y, RUI Y, HUANG T S, et al. Adaptive key frame extraction using unsupervised clustering[C]//Proceedings of International Conference on Image Processing. ICIP98 (Cat. No. 98CB36269). Washington DC,USA:IEEE, 1998, 1: 866.
[9]VZQUEZ-MARTN R, BANDERA A. Spatio-temporal feature-based keyframe detection from video shots using spectral clustering[J]. Pattern Recognition Letters, 2013, 34(7): 770.
[10]MAHASSENI B, LAM M, TODOROVIC S. Unsupervised video summarization with adversarial LSTM networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI:IEEE, 2017: 202.
[23]ZHU W, HU J, SUN G, et al. A key volume mining deep framework for action recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE,2016: 1991.
[24]KAR A, RAI N, SIKKA K, et al. Adascan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI, USA:IEEE,2017: 3376.
[25]MISRA I , ZITNICK C L , HEBERT M . Shuffle and learn: Unsupervised learning using temporal order verification[C]//14th European Conference on Computer Vision(ECCV). Amsterdam, The Netherlands:dblp ,2016:524.
[26]LEE H Y , HUANG J B , SINGH M K, et al. Unsupervised representation learning by sorting sequences[C]//IEEE International Conference on ComputerVision (ICCV). Venice, Italy:IEEE,2017:1.
[27]SOOMRO K, ZAMIR A R, SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[J]. arXiv preprint arXiv:1212.0402, 2012.
[28]KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition[C]//2011 IEEE International Conference on Computer Vision(ICCV). Barcelona, Spain:IEEE, 2011: 2556.
[29]PASZKE A, GROSS S, MASSA F, et al. PyTorch: An imperative style, high-performance deep learning library[C]//33rd Conference on Neural Information Processing System(NeurIPS 2019). Vancouver, Canada: NIPS, 2019: 8024.
