Nonnegativity-enforced Gaussian process regression
2020-07-01AndrewPensoneultXiuYngXueyuZhu
Andrew Pensoneult, Xiu Yng*, Xueyu Zhu,*
a Department of Mathematics, University of Iowa, Iowa, IA 52246, USA
b Department of Industrial and Systems Engineering, Lehigh University, Bethlehem, PA 18015, USA
Keywords:Gaussian process regression Constrained optimization
ABSTRACT Gaussian process (GP) regression is a flexible non-parametric approach to approximate complex models. In many cases, these models correspond to processes with bounded physical properties.Standard GP regression typically results in a proxy model which is unbounded for all temporal or spacial points, and thus leaves the possibility of taking on infeasible values. We propose an approach to enforce the physical constraints in a probabilistic way under the GP regression framework. In addition, this new approach reduces the variance in the resulting GP model.
In many applications, evaluating a computational model can require significant computational resources and time. One approach to address this problem is to build a surrogate model with statistical emulators such as Gaussian processes (GP) regression [1]. We aim to design surrogate models that have low approximation error, and satisfy meaningful bounds on some physical properties. However, no such information is encoded in the standard GP regression method. Therefore, it can produce infeasible predictions.
Incorporating physical information in GP has been explored in many works of literature. For example, it is demonstrated in Ref. [2] that the mean prediction of a GP model satisfies a set of linear equality constraints provided the training data satisfy these constraints. A similar result holds for quadratic equality constraints under a transformation of the parameterization. Alternatively, linear equality constraints can be enforced by modeling the process as a transformation of an underlying function and imposing the constraints on that transformation [3].
Moreover, physical information in the form of differential operators can be incorporated in GP models [4–7].
Incorporating inequality constraints in a GP is more difficult,as the underlying process conditional on the constraints is no longer a GP [8]. To address this problem, several different approaches have been explored. The approach in Ref. [9] enforces inequality constraints at several locations and draws approximate samples from the predictive distribution with a data augmentation approach. Linear inequality functional (such as monotonicity) are enforced via virtual observations at several location within [10–14]. In Ref. [11], it is shown that when linear inequality constraints are applied to a finite set of points in the domain, the process conditional on the constraints is a compound GP with a truncated Gaussian mean. In Ref. [8, 15, 16],linear inequality constraints are enforced on the entire domain instead of a finite set of points by making a finite-dimensional approximation of the GP and enforcing the constraints through the choice of the associated approximation coefficients.
In this work, we focus on enforcing non-negativity in the GP model. This is a requirement for many physical properties, e.g.,elastic modulus, viscosity, density, and temperature. We propose to impose this inequality constraint with high probability via selecting a set of constraint points in the domain and imposing the non-negativity on the posterior GP at these points. In addition to enforcing non-negativity, this approach improves accuracy and reduces uncertainty in the resulting GP model.
The paper is organized as follows. We review the standard GP regression framework first, then present our novel approach to enforce non-negativity in GP regression, and provide numerical examples at last.
We introduce the framework for GP regression based on the descriptions in Ref. [17]. Assume we have y = (y(1), y(2),..., y(N))Tas the values of the target function, where y(i)∈R are observations at locationswhere x(i)are d-dimensional vectors in the domain D ∈Rd. We aim to use a GP Y(·,·) : D ×Ω →R to approximate the underlying target function. Typically, Y(x) is denoted as

where µ(·) : D →R and K (·, ·) : D ×D →R are the associated mean function and covariance function, i.e
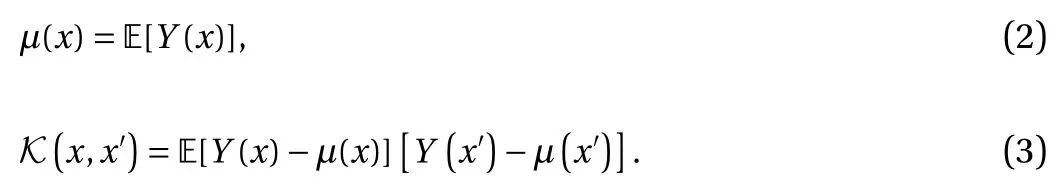
A widely used kernel is the standard squared exponential covariance kernel with an additive independent identically distributed Gaussian noise term ϵ with variance:
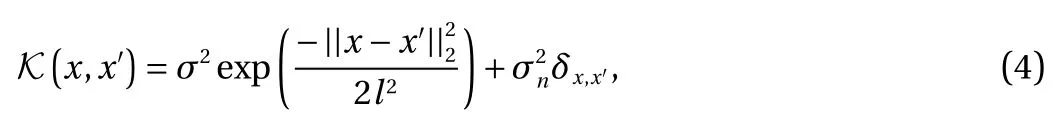
where δx,x'is a Kronecker delta fuction, l is the length-scale, and σ2is the signal variance. In general, by assuming zero mean function µ(x) ≡ 0, we use θ = (σ, l, σn) to denote the hyperparameters, and they are determined based on the training data.
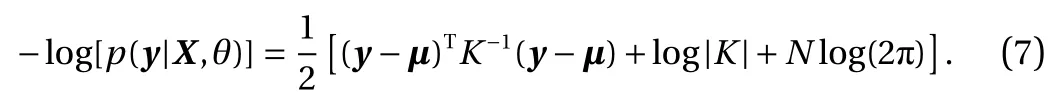
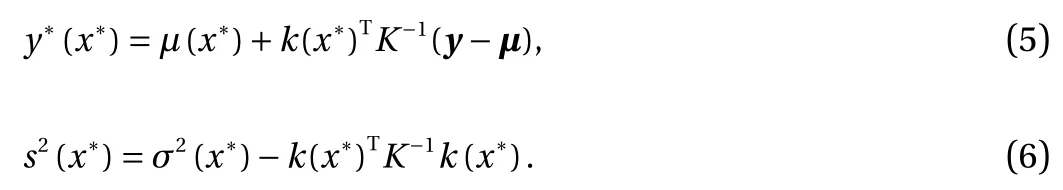
In particular, we enforce the non-negativity in the quantity of interest. We minimize the negative marginal log-likelihood function in Eq. (7) while requiring that the probability of violating the constraints is small. More specifically, for 0 < η ≪ 1, we impose the following constraint:
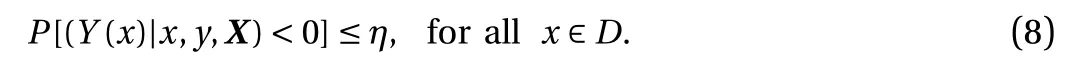
This differs from other methods in the literature, which enforce the constraint via truncated Gaussian assumption [8], or use a bounded likelihood function and perform inference based on the Laplace approximation and expectation propagation [18]. In contrast, our method retains the Gaussian posterior of standard GP regression, and only requires a slight modification of the existing cost function. As Y(x)|x, y, X follows a Gaussian distribution, this constraint can be rewritten in terms of the posterior mean y*and posterior standard deviation s:
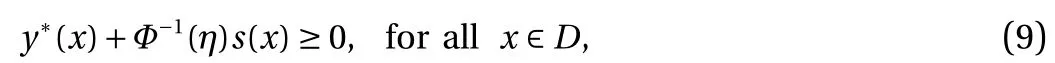
where Φ−1is the inverse cumulative density function (CDF) of a standard Gaussian random variable. In this work, we set η = 2.2%for demonstration purpose, and consequently Φ−1(η) = −2, i.e.,two standard deviations below the mean is still nonnegative.Therefore, we minimize the negative log-likelihood cost function subject to constraints on the posterior mean and standard deviation:
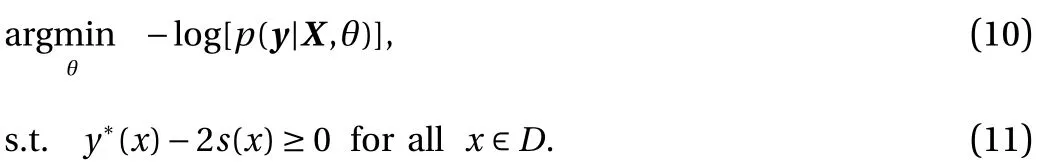
We note that Eq. (11) is a functional constraint and thus can be difficult to enforce. Instead, we enforce Eq. (11) on a set of constraint pointsOf note, these constraint points play similar roles as the aforementioned virtual observations[10–14].
Meanwhile, in practice, a heuristic on the distance of the posterior mean of the GP from the training data is applied to stabilize the optimization algorithm, as such to guarantee that it results in a model that fits measurement data. Subsequently, to obtain the constrained GP, we solve the following constrained minimization problem:
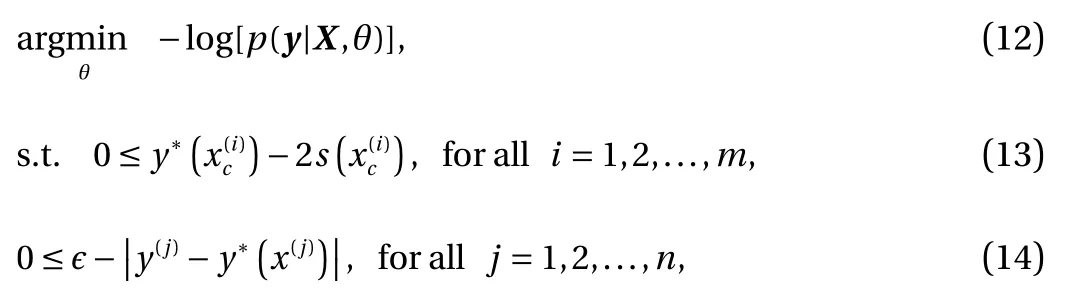
where ϵ > 0 is chosen to be sufficiently small. In the this paper,we set ϵ = 0.03. The last constraint is chosen so that the given solution fits the data sufficiently well.
We remark that compared with unconstrained optimization,constrained optimization is in general more computationally expensive [19]. However, if non-negativity approximation of the target function is crucial for the underlying applications, one may weigh less on the efficiency in order to get more reliable and feasible approximation within the computational budget.
We present numerical examples to illustrate the effectiveness of our method. We measure the relative l2error between the posterior mean y*and the true value of the target function f(x)over a set of test points
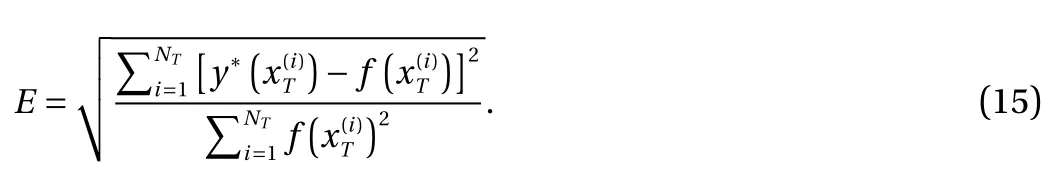
For the examples below, we use NT= 1000 equidistant test points over the domain D. We use the standard squared exponential covariance kernel as well as a zero prior mean function µ(x) = 0.We solve the unconstrained log-likelihood minimization problem in MATLAB using the GPML package [20]. For the constrained optimization, we use the fmincon from the MATLAB Optimization Toolbox based on the built-in interior point algorithm [21].
RemarkIf the method results in convergence to an infeasible solution, the optimization is performed again with another random initial guess (with a standard Gaussian noise added to the base initial condition, θ0= [log(l), log(σ), log(σn)] =(−3, −3, −10).
Example 1
Consider the following function:
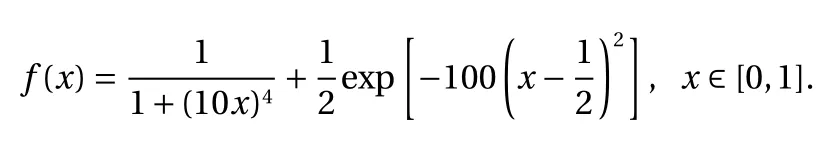
For our tests on this example, the training point set is
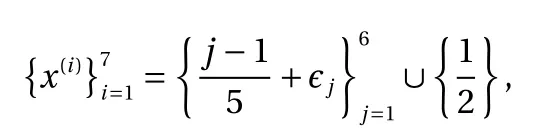
Figure 1a shows the posterior mean of the unconstrained GP with 95% confidence interval. It can be seen that on [0.65, 0.85],the posterior mean violates the non-negativity bounds with a large variance. In contrast, the posterior mean of the constrained GP in these regions no longer violates the constraints,as shown in Fig. 1b. Besides, the confidence interval is reduced dramatically after the non-negativity constraint is imposed.
To illustrate the robustness of the algorithm, we repeat the same experiment on 100 different training data sets as in Ref. [4].Figure 2a illustrates the distribution of the relative l2error over the 100 trials. It is clear that incorporating the constraint tends to result in a lower relative error in the posterior mean statistically.Figure 2b compares the percentage of the posterior mean over the test points that violate non-negativity constraint over the 100 trails. There is a large portion of the posterior mean by the unconstrained GP that violates the non-negativity, while the constrained GP preserves the non-negativity very well.
Example 2
Consider the following function:
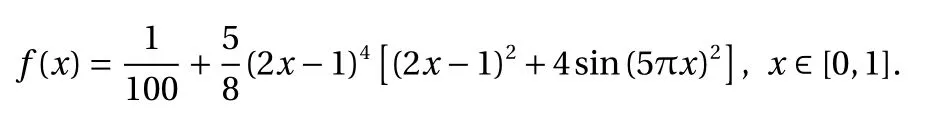
We train our constrained and unconstrained GP models over 14 training points at locations:
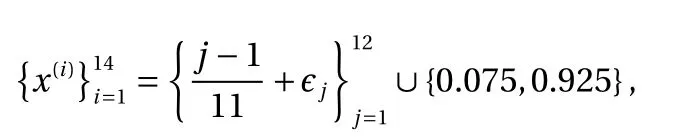
Figure 3a shows a 95% confidence interval around the posterior mean of the unconstrained GP. Notice that the posterior mean is less than zero near neighborhoods of 0.8. In contrast,the constrained GP doesn't violate the constraints as shown in Fig. 3b. The confidence interval of the posterior mean is also much narrower, which illustrates the advantage of incorporating the constraints.
Again, to show the robustness of the algorithm, we repeat the same experiment on 100 trials. Figure 4a shows the relative l2error over 100 trials. The constrained GP has a histogram more heavily weighted towards lower relative error in the posterior mean, compared to the unconstrained GP. Figure 4b shows that the posterior mean of the unconstrained GP violates the nonnegativity condition more frequently.
Example 3
The Korteweg−de Vries (KdV) [22] equation can be used to describe the evolution of solitons, which are characterized by the following properties: (1) invariant shape; (2) approaches a constant as t → ∞; (3) strong interactions with other solitons. We consider the KdV equation in the following form
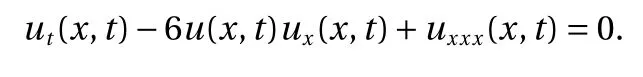
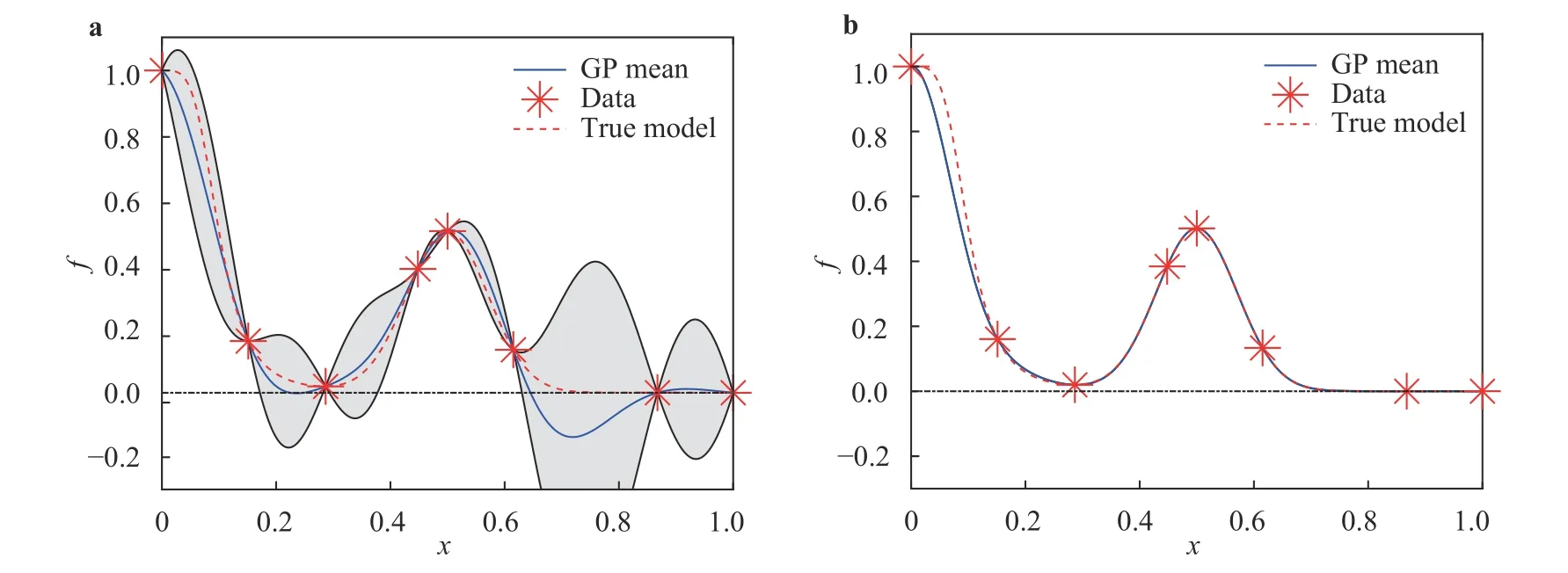
Fig. 1. Posterior mean and the corresponding 95% confidence interval of the GP models in example 1. a Unconstrained GP. b Constrained GP.
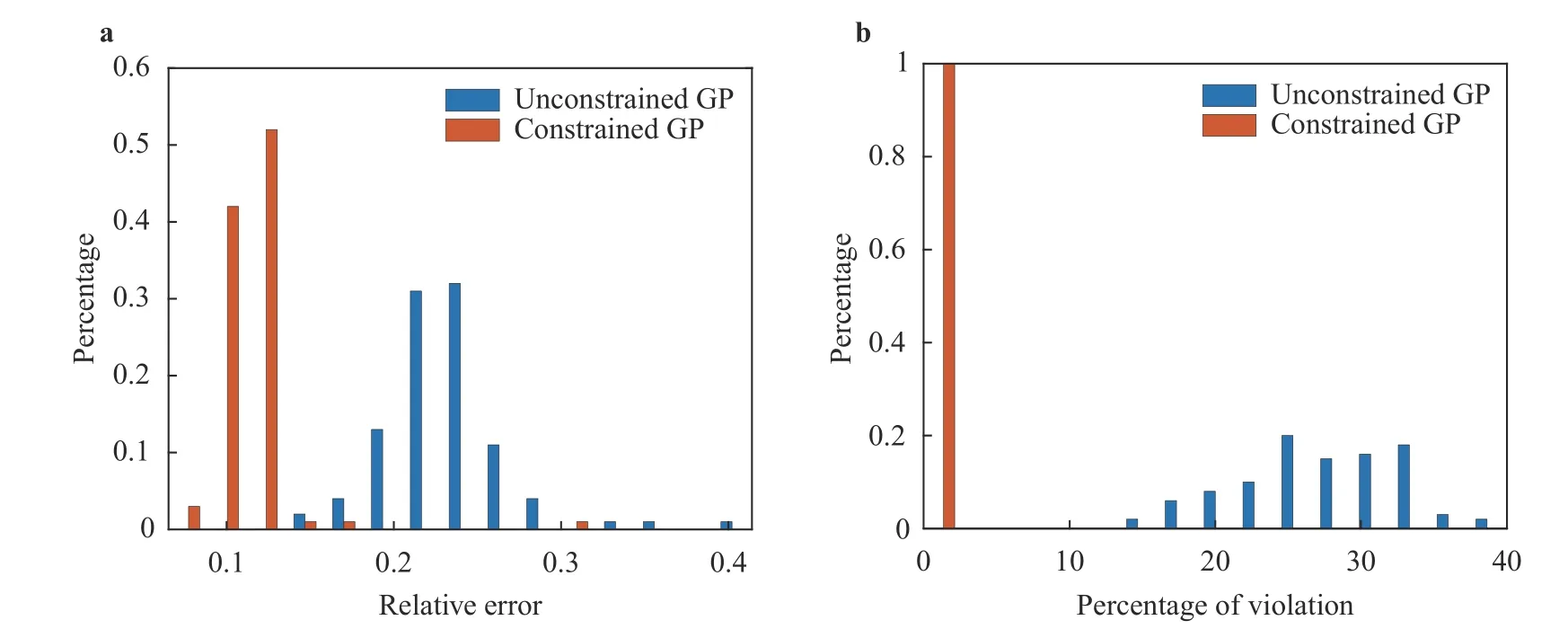
Fig. 2. a Normalized histogram associated with the l2 relative error between the GP mean and the true function over the test set based on 100 different training sets. b Normalized histogram associated with the percentage of the posterior mean over test points that violate the non-negativity constraint.
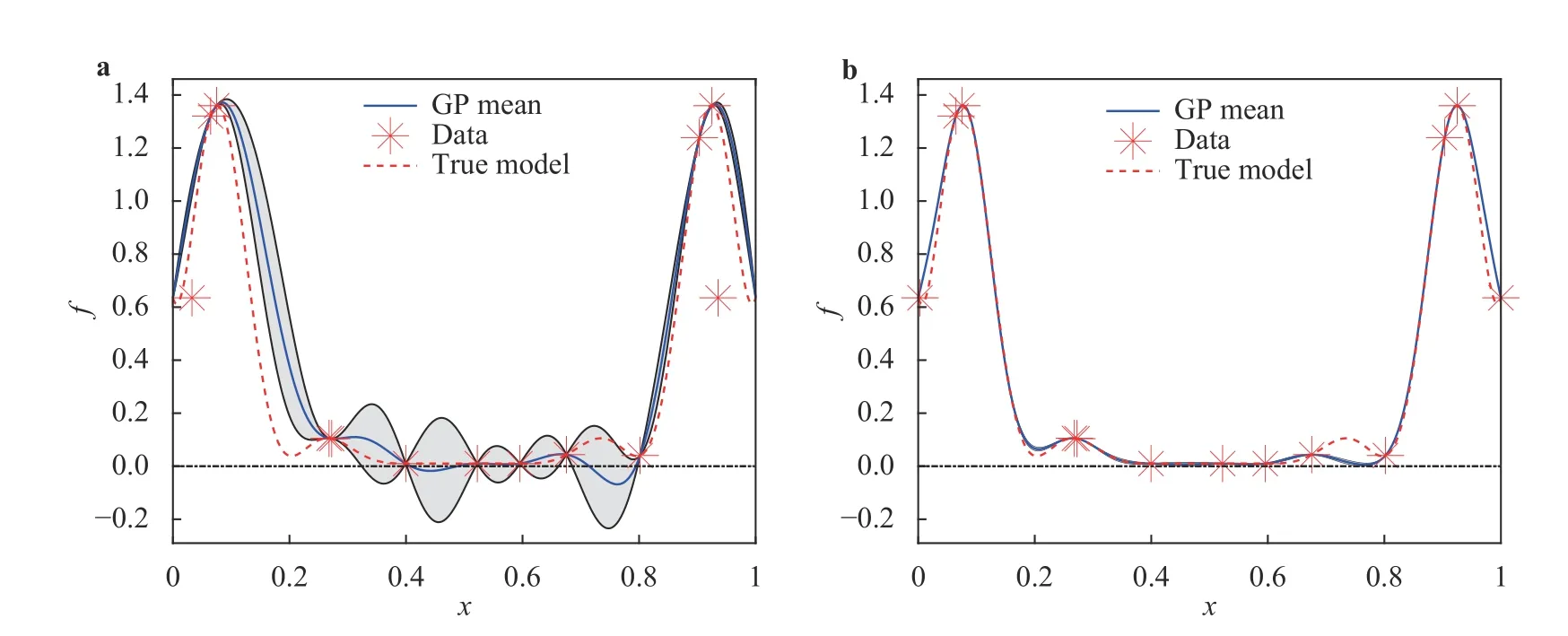
Fig. 3. Posterior mean and the corresponding 95% confidence interval of the GP models in example 2. a Unconstrained GP. b Constrained GP.
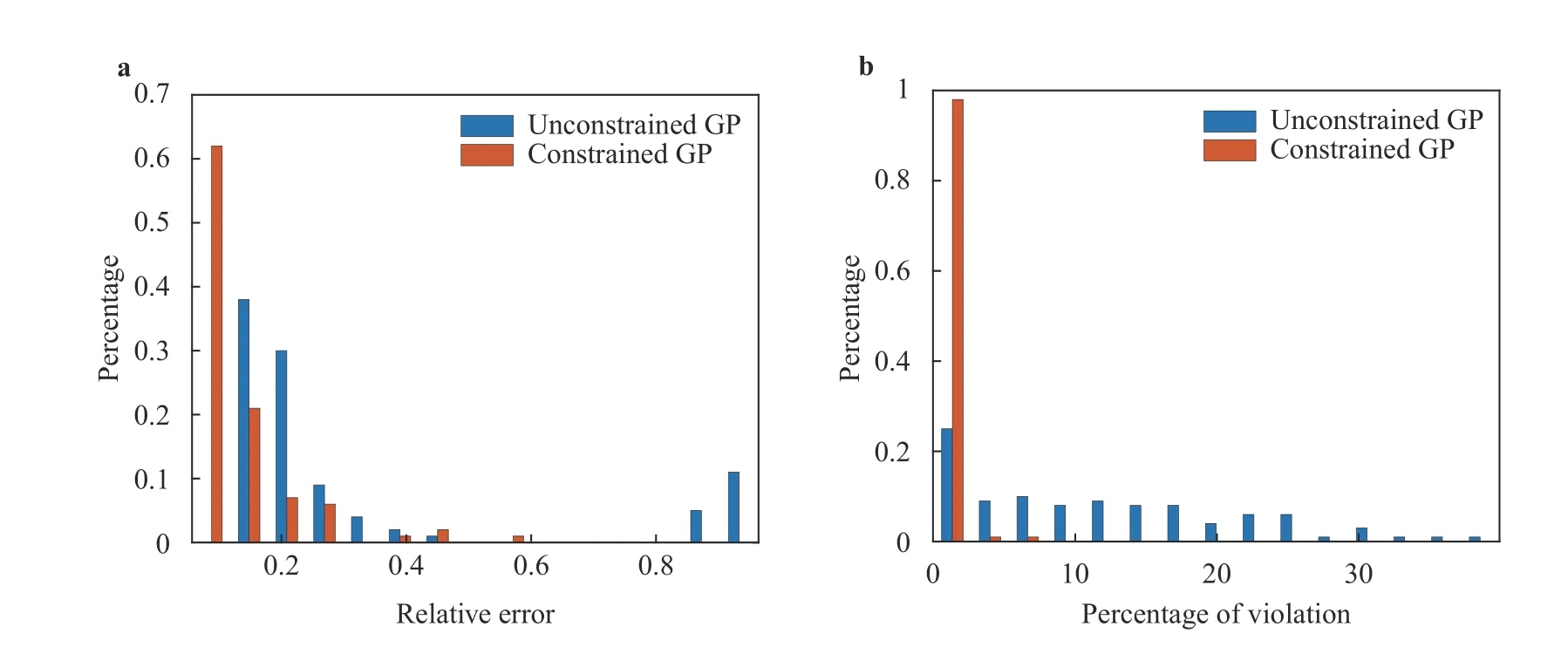
Fig. 4. a Normalized histogram associated with the l2 relative error between the GP mean and the true function over the test set based on 100 different training sets. b Normalized histogram associated with the percentage of the posterior mean over test points which violate the non-negativity constraint.
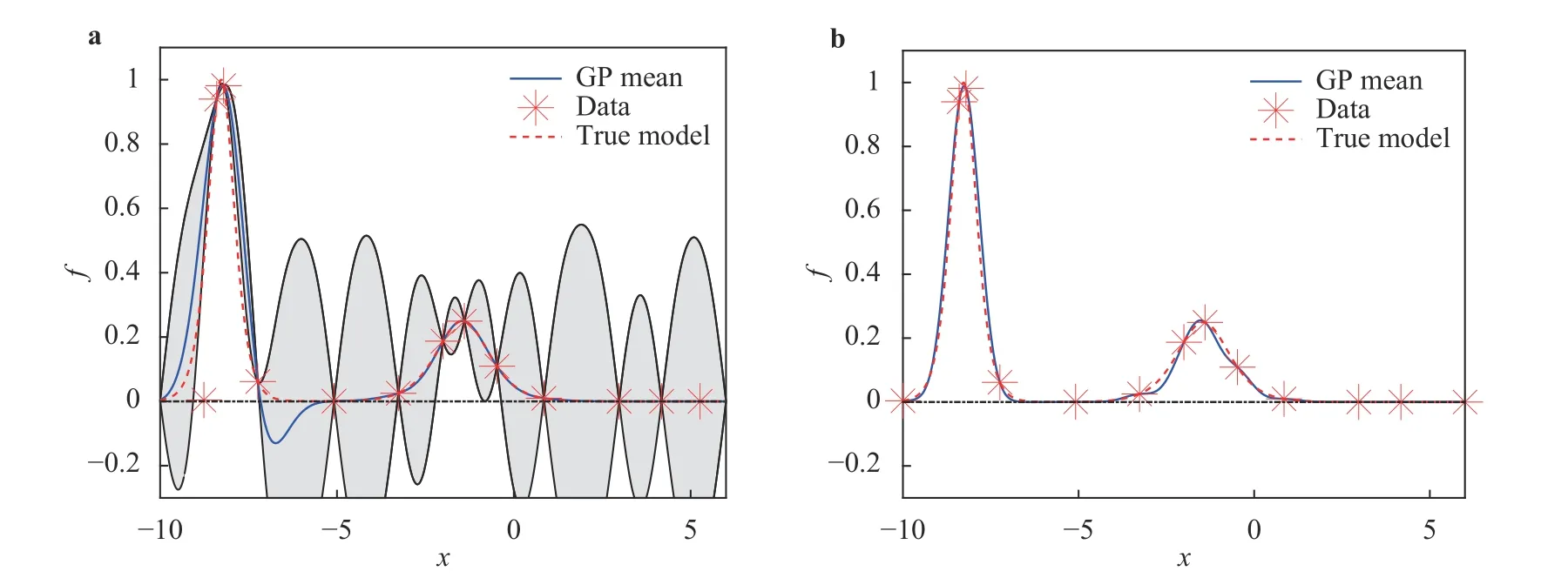
Fig. 5. Posterior mean and the corresponding 95% confidence interval of GP models approximating the two-soliton interacting system at t = −1 for a set training data set. a Unconstrained GP. b Constrained GP.
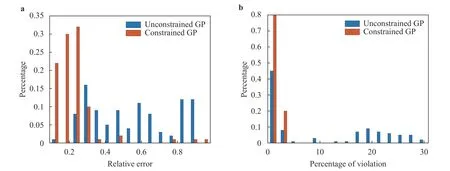
Fig. 6. a Normalized histogram associated with the l2 relative error between the GP mean and the true function over the test set based on 100 different training sets. b Normalized histogram associated with the percentage of the posterior mean over test points that violate the non-negativity constraint.
Under several assumptions on the form of u, an analytic solution can be found. For the case of two solitons, a (normalised)solution can be found in Ref. [22]:
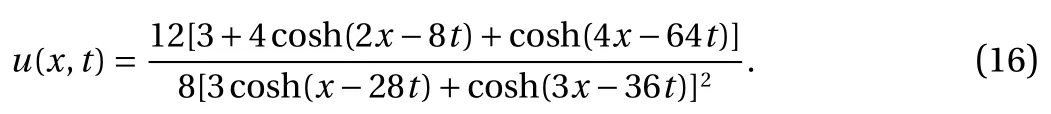
For this equation, u(x, t) > 0 for all x,t ∈R, we aim to approximate u(x, −1) using GP.
We train our constrained and unconstrained GP model based on 13 training points at locations:
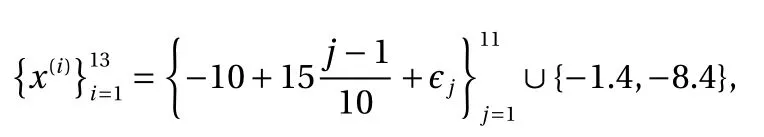
As can be seen in Fig. 5, the unconstrained GP violates nonnegativity around x = −7, which is avoided in the constrained GP.More importantly, the confidence interval of the resulting GP is dramatically reduced by imposing non-negativity constraint. In addition, Fig. 6a shows that the relative error is significantly reduced when we incorporate the non-negativity information. Of note, in this case, because the majority of the test points are near zero, the relative error is much more sensitive to approximation errors in these regions. Figure 6b illustrates that the constrained GP preserves the non-negativity with very high probability while the unconstrained GP violates the non-negativity much more frequently.
In this paper, we propose a novel method to enforce the nonnegativity constraints on the GP in the probabilistic sense. This approach not only reduces the difference between the posterior mean and the ground truth, but significantly lowers the variance,i.e., narrows the confidence interval, in the resulting GP model because the non-negativity information is incorporated. While this paper covers only the non-negativity bound, other inequality constraints can be enforced in a similar manner.
Acknowledgement
X.Y. Zhu's work was supported by Simons Foundation. X.Yang's work was supported by the U.S. Department of Energy Office of Science, Office of Advanced Scientific Computing Research as part of Physics-Informed Learning Machines for Multiscale and Multiphysics Problems (PhILMs).
杂志排行

Theoretical & Applied Mechanics Letters的其它文章
- Mechanistic Machine Learning: Theory, Methods, and Applications
- Deep density estimation via invertible block-triangular mapping
- Classifying wakes produced by self-propelled fish-like swimmers using neural networks
- Physics-constrained indirect supervised learning
- Physics-constrained bayesian neural network for fluid flow reconstruction with sparse and noisy data
- Reducing parameter space for neural network training