基于TPOT的信用卡逾期识别算法
2020-06-30杨怡滨
杨怡滨

【摘 要】文章提出了一种基于自动机器学习(Automatic Machine Learning)框架TPOT的信用卡逾期识别算法。通过K-近邻、决策树、支持向量机、随机森林、多层感知神经网络、TPOT自动机器学习这6种算法构建了信用卡逾期识别模型,进而以准确率、精确率、召回率、混淆矩阵、F1值为基准进行不同模型的性能评价。经反复的实例论证和理论测算,该框架相较于传统机器学习,平均准确率达到80%以上,能够在节省参数调节时间的基础之上,获得更佳的效果。
【关键词】信用卡逾期;AutoML;自动机器学习;TPOT;遗传编程
【中图分类号】TP181 【文献标识码】A 【文章编号】1674-0688(2020)03-0092-04
0 引言
隨着国民生活水平提高,超前消费的理念逐渐深入人心,信用卡作为超前消费的工具受到越来越多人的青睐,相关金融机构也乘此机会大力发展信用卡业务,使得信用卡发卡量陡增。与此同时,信用卡风险管理并未能及时跟上市场的脚步,尤其是个人信用评估方面,更是远落后于市场发展水平。传统的个人信用评估模型多数是基于统计计量的模型,能够高效处理线性问题,但金融相关的计量通常是复杂的非线性决策问题,而且具有模糊特质,因此近年来机器学习技术开始受到研究人员的高度关注[1]。
国外研究学者在21世纪初就对机器学习进行信用卡风险管理做了详细研究。例如Tony Bellotti等人在2009年发表的文献中使用了支持向量机进行信用卡风险评估,并发现违约风险的重要特征[2];Amir E.Khandani等人在2010年提出了使用非线性非参数模型构建消费者信用风险预测模型[3]。机器学习模型在国外已成为信用卡风险管理的重要手段之一。国内对机器学习进行信用卡风险评估也做了不少研究。李建平等人早在2004年就对支持向量机和银行当时使用的个人信用评估方法做了对比[4]。
目前,众多专家学者在信用卡风险管理领域研究最多的机器学习模型是支持向量机,对于其他模型则较少涉及,同时模型效果也非常依赖专家学者本身的业务水平和对模型的理解。综合来看,信用卡风险管理模型的效果主要受限于两点:一是模型选择,二是模型理解和调优。针对上述两点,本文详细阐述了TPOT自动机器学习框架的结构与实现原理,并在此基础之上使用对比法,构建基于自动机器学习的信用卡风险管理模型,论证模型的有效性。
1 TPOT自动机器学习框架
自动机器学习是在传统机器学习的基础之上衍生出的一种机器学习方法。它并非新的机器学习算法,而是一种能够对算法进行自动选择、参数进行自动优化的方法。自动机器学习借鉴了诸多机器学习的知识,例如遗传编程(Genetic Programming)、贝叶斯优化(Bayesian optimization)、元学习(Meta learning)、迁移学习(Transfer learning)等[5]。TPOT(Tree-based Pipeline Optimization Tool)是宾夕法尼亚大学遗传算法实验室开发的一个自动机器学习框架[6]。它能够智能地探索数千种可能来自动化机器学习中最烦琐的部分,从而找到最适合当前数据情况的算法及其参数[7]。其整体功能如图1所示。
图1是一个典型有监督机器学习的流程[8]。在模型构建之前,进行数据清理、特征选择、特征构造,并构建新特征,并通过特征预处理将数据变换至更适合的建模要求。然后选择合适的算法与模型,并进行模型参数的调节与优化。最后通过混淆矩阵、精确率等指标验证与评估模型的性能。图1中深色区域表示TPOT框架自动执行的步骤。
1.1 机器学习算法
TPOT框架在实际模型训练过程中使用的机器学习算法主要包括特征预处理、分解、特征选择、模型选择4个部分[7],所有算法绝大部分都基于Python语言的scikit-learn[9]机器学习框架。TPOT框架各部分主要内容如下。
(1)预处理主要用于变换数据,包括数据标准化(Standard Scaler)、数据缩放(Robust Scaler)、多项式特征构造(Polynomial Features)。
(2)分解使用的是一种名为RandomizedPCA的随机SVD的主成分分析变种。
(3)特征选择部分包含4种方法,分别是采用递归特征消除策略的RFE;选择最佳前n个特征的Select KBset;选择最优前n%特征的Select Percentile和移除不符合最小方差阈值特征的Select Percentile。
(4)模型选择部分包含的模型有分类与回归两个方向,几乎囊括了scikit-lean中的所有分类回归算法,例如DecisionTreeClassfier(决策树分类器)、DecisionTreeRegressor(决策树回归器)、RandomForestClassifier(随机森林分类器)、RandomForestRegressor(随机森林回归器)、LogisticRegression(逻辑回归)、LinearRegression(线性回归)、KNeighborsClassifier(K-近邻分类器)、GaussianNB(高斯朴素贝叶斯)等。
1.2 遗传编程
使用正确的预处理方法、模型能够在极大程度上解决目标问题,但是由于模型过多,如何选择合适的模型,调节合适的参数就会耗费大量的时间[10]。针对模型选择和参数调优的问题,TPOT使用了遗传编程。
Koza,De Jong等人发展了遗传编程的概念[11,12]。遗传编程是在遗传算法的基础之上发展出来的一种利用自然进化的原理进行程序进化的编程方法,它与遗传算法的最大区别在于其个体是可以执行的程序而非字符串[13]。
在標准的遗传编程方法中,程序的表现形式是语法树[13]。遗传编程能够通过合理的途径实现“树”的生长。在遗传编程中,“树”代表一些互有关联的指令与函数,可以操作给定初始结构(键合图)的形态与参数,从而让简单的键合图生长发育为满足设计要求的方案。因为在遗传编程中,个体的长度是开放式的变长表示,所以特别适合于键合图的开放式的结构空间搜索[14]。
遗传编程的整体步骤如下:随机生成一个初始种群,构成最优化问题搜索空间,该种群每个个体均为树状结构,且适用于给定问题环境;然后计算每个个体的适应度,通过遗传算子处理适应度较高的个体,通过复制、突变、交叉等遗传操作对种群不断进行迭代和优化,产生下一代群体。经过不停迭代,直至下一代满足目标函数且稳定后为止[15]。
种群中每个个体的大小、结构和内容都是动态变化的,这是由遗传操作来实现的[15]。其中,复制操作的目的主要是保证优秀个体的持续性,该操作整体可分为两步:{1}选择第N代的某个体;{2}将它原封不动的保留给N+1代。
突变操作的主要作用是保证种群结构足够丰富,扩充种群结构的多样性。其操作流程是将种群中某些样本个体的树状结构的某个分支替换为一个随机出现的结构。
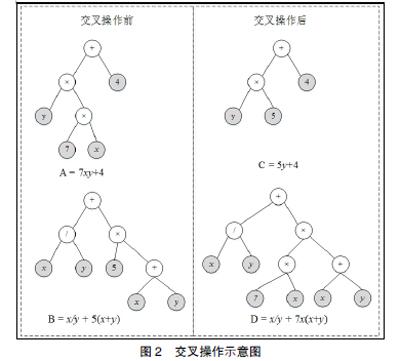
交叉操作类似生物界的有性繁殖,能够为种群产生基因更优秀、生命力更强的个体(如图2所示)。{1}随机选择两个个体A、B作为父辈个体;{2}分别确定父辈个体的交叉点;{3}将父辈个体拆分为交叉部分和剩余部分;{4}将A的剩余部分和交叉部分分别与B的交叉部分和剩余部分构成两个新的个体C与D。
1.3 TPOT实现
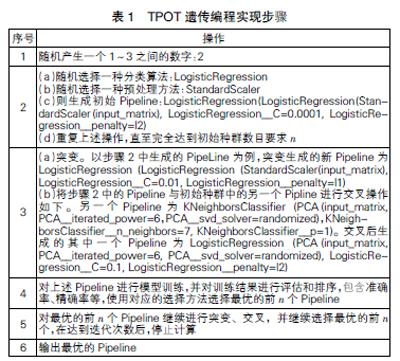
在TPOT中,具体遗传编程实现以Pipeline为基础,使用了DEAP[17]这一Python库。对应遗传编程步骤,TPOT中实现的遗传编程步骤如下:首先随机生成不同深度的树类构建初始种群(初始Pipeline),如果树的深度为1,则从已有的分类或者回归模型中随机选择一个放入树的顶端;如果树的深度大于1,就从预处理、特征选择中选择对应的算子加入Pipeline中,并进行参数初始化。然后评估初始Pipeline的适应性,对初始Pipeline进行交叉、突变等操作。其中,Pipeline的种群突变操作主要通过增加Pipeline的内容或者更换其中的参数实现。交叉则是选取两个Pipeline,对里面的内容进行互换,但是两个Pipeline的类型要相同。整体流程见表1。
表1中的步骤、各项参数具体见表2。
2 实验与结果分析
研究所使用的数据为公开数据集default of credit card clients[18],该数据集涉及的特征主要有信用卡额度、性别、学历、婚姻、年龄,以及最近半年的还款记录、最近半年的账单金额、最近半年的还款金额等,共计23个特征,30 000个样本。研究时,将数据划分为2个部分,其中训练集样本数目为24 000个,测试集样本数目为6 000个。
2.1 基于TPOT的信用卡逾期识别
通过混淆矩阵可以用来查看基于TPOT构建的信用卡逾期识别模型的性能优劣,尤其是针对识别错误的样本,效果更是一目了然(见表3)。
根据混淆矩阵可以得出当前模型的精确率、召回率、F1值及对应的加权均值(见表4)。
由表3、表4可知,基于TPOT构建的信用卡逾期识别模型性能非常突出,加权后的精确率、召回率、F1值均达到0.80以上,表明模型具有一定的有效性及适用性。但同时也需要注意,由于样本基数相对较小,模型效果与理想效果还有一段距离。
2.2 对比分析
为验证TPOT构建的模型的效果,使用K最近邻、决策树、支持向量机、随机森林、多层感知神经网络5种算法与之进行对比,得到算法的诊断结果见表5。
综合考虑上述模型的准确率、加权平均精确率和加权平均召回率,TPOT构建的模型在信用卡逾期中均表现出最优的诊断效果。故可以认为,TOPT对于信用卡逾期识别有良好的效果。
3 结语
本文使用TPOT自动机器学习框架,通过比较K-近邻,决策树、支持向量机、随机森林、多层感知神经网络和TPOT构建的模型,最终证明相比于其他机器学习算法对于信用卡逾期识别具有更好的诊断效果。该框架的不足之处在于所用的建模算法均为有监督学习,暂时不支持无监督学习,且受scikit-learn的限制,本身预处理方法偏少。
参 考 文 献
[1]李睿.信用评估与信用卡欺诈侦测的智能决策系统研究[D].广州:华南理工大学,2011.
[2]Bellotti T,Crook J.Support vector machines for credit scoring and discovery of significant features[J].Expert systems with applications,2009,36(2):3302-3308.
[3]Khandani A E,Kim A J,Lo A W.Consumer cre-
dit-risk models via machine-learning algorithms[J].Journal of Banking & Finance,2010,34(11):2767-2787.
[4]李建平,徐伟宣,刘京礼,等.消费者信用评估中支持向量机方法研究[J].系统工程,2004(10):35-39.
[5]涂同珩,金炜东.基于自动机器学习流程优化的雷达辐射源信号识别[J].计算机应用研究,2019(1):191-193.
[6]Olson R S,Bartley N,Urbanowicz R J,et al.Evaluation of a tree-based pipeline optimization tool for automating data science[C].Proc of Genetic and Evolutionary Computation Conference,2016:485-492.
[7]Olson R S,Moore J H.TPOT:A tree-based pip-
eline optimization tool for automating machine lear-
ning[J].Journal of Machine Learning Research,2016,64:66-74.
[8]周志華.机器学习[M].北京:清华大学出版社,2016.
[9]Swami A,Jain R.Scikit-learn:Machine Learning in Python[J].Journal of Machine Learning Research,2012,12(10):2825-2830.
[10]黄宜华.大数据机器学习系统研究进展[J].大数据,2015(1):4-8.
[11]Koza J R,Koza J R.Genetic programming:on the programming of computers by means of natural selection[M].MIT press,1992.
[12]De Jong K A.On Using Genetic Algorithms to Se-
arch Program Spaces[C].ICGA,1987:210-216.
[13]刘亚杰,古天龙,徐周波,等.基于改进遗传编程的并行装配序列规划[J].计算机集成制造系统,2013,
19(6):1238-1248.
[14]Niekum S,Barto A G,Spector L.Genetic programming for reward function search[J].IEEE Tr-
ansactions on Autonomous Mental Development,2010,2(2):83-90.
[15]蒋毅恒,白焰,朱耀春,等.基于遗传编程的智能建模方法及应用[J].微计算机信息,2008,24(12):
150-152.
[16]涂同珩.基于自动机器学习的雷达信号识别研究[D].成都:西南交通大学,2018.
[17]Fortin F A,Rainville F M D,Gardner M A,et al.DEAP:Evolutionary algorithms made easy[J].Journal of Machine Learning Research,2012,13(7):2171-2175.
[18]Yeh I C,Lien C.The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients[J].Expert Systems
with Applications,2009,36(2):2473-2480.
