大数据驱动下的老油田精细注水优化方法
2020-06-30贾德利刘合张吉群龚斌裴晓含王全宾杨清海
贾德利,刘合,张吉群,龚斌,裴晓含,王全宾,杨清海
(1.中国石油勘探开发研究院,北京 100083;2.中国地质大学(武汉)资源学院,武汉 430074)
0 引言
中国大多数油田为砂岩油田,为实现高产稳产和提高采收率的目的,油田一般采用注水开发且成效显著,中国水驱开发技术一直处于国际领先地位[1-3]。目前多数油田陆续进入了“双高阶段”,大庆、胜利等主力油田已进入特高含水阶段,剩余油高度分散、油水关系极其复杂,稳油控水难度大[4-6]。开发生产阶段,一方面长井段开采导致纵向上层间动用差异大;另一方面由于老井套损以及套变严重,导致平面上难以构成完善的注采井网[7-8];此外,由于储集层非均质性强,长期注水冲刷后形成优势水流通道,注入水无效、低效循环。上述问题严重制约了开发效果,提高采收率幅度下降,增加可采储量难度加大。因此,开展水驱油藏精细智能化分析研究对提高老油田采收率具有重要的工程意义。
笔者团队近些年攻关井下永置式层段调节、层段计量和井筒双向通信等核心技术,研制了分层注水实时监测与自动控制系列工艺,实现了注水井分层压力和流量的数字化实时监测及油藏注水动态监测的网络信息化,推进分层注水工艺向数字化、自动化、集成化方向发展[9-11],减少了单井层段划分日益精细后的测调工作量,解决了人员和设备投入大幅度增加导致的生产成本成倍增长的矛盾。更重要的是该成果可为实施精细智能油藏分析提供必要的工程基础和手段,本文结合分层注采监测的数据更加精准地开展油藏建模、历史拟合等分析,以降低对剩余油分布及注水效果预测的不确定性,达到进一步提高采收率的目的。
1 大数据应用于油藏分析的特点
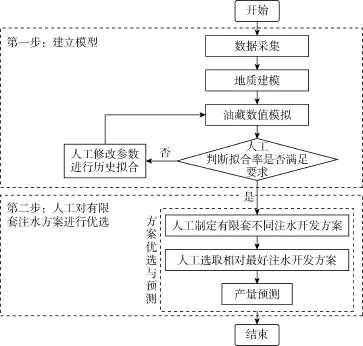
图1 传统注水方案优化模拟流程
传统注水优化方法建立在数值模拟的基础上,流程如图 1所示,首先根据油藏动静态数据建立地质模型,对油藏进行数值模拟,即根据油藏工程师的经验进行人工历史拟合,达到一定的拟合率后设计多套注水调整方案,再应用油藏数值模拟对每套方案进行产量预测,最终优选出一套较优的方案。该工程方法周期长、依赖于油藏工程师经验且优化方案有限,若融合大量动态注水生产数据将进一步增加数值模拟的计算量,此外在现有数模框架下无法充分利用动态数据。
近几年,大数据技术的发展为石油勘探与开发各技术环节的算法升级提供了新的启发,并且已经率先在提高测井与地震解释质量、采油工程功图优化、智能钻井等领域实现了富有成效的应用。将人工智能算法应用到油藏分析中,提高对油藏认识的精度,并据此提出更加高效的油藏工程实施方案成为新的研究目标。然而由于油藏作为测量、数据解释及方案实施的目标,在大数据算法应用上存在特殊的挑战:①油藏解释及观测数据在时空分布上具有高度的不均匀性;②对油藏地质特征及物性的认识存在高度的不确定性[12];③油藏动态测量数据极度单一和稀缺,尤其缺少直接服务于决策的测量数据,比如随时间变化的分层注水及产油/产水量。这些挑战直接导致机器学习算法无法获得足够的、有效的训练样本。
鉴于此,本文在传统的数值模拟及优化算法基础上,结合分层注采实时监测与自动控制工艺技术所监测的“硬数据”,提出一种大数据驱动下的老油田精细注水优化方法。首先利用数据同化算法对地质模型进行自动历史拟合,获得精细分层注采“硬数据”约束下的油藏流体饱和度和压力场的演化模型;然后在此基础上通过机器学习算法量化和评价井组(层段)注水的效果指标,分析注水调整方向,最终形式多井分层的优化注水方案。随着动态数据的不断增加和更新,本文的算法和流程能够深化对油藏非均质性及流动条带的认识,从而降低剩余油分布及注水效果预测的不确定性,不断优化精细注水调整方案。
2 系统方案设计
大数据驱动下注水优化模拟的整体流程与传统注水优化模拟流程一样分为两步,但每一步的实现均融入了大数据分析算法(见图2)。第一步建立油藏预测模型时融入了数据同化算法,使得地质模型参数场的校正可在持续的数据驱动下自动进行;第二步注水方案优化与预测过程中运用机器学习算法来量化和评价多井分层注水效果、分析注水调整方向,最终通过大数据智能优化算法求解最优注水调整方案。
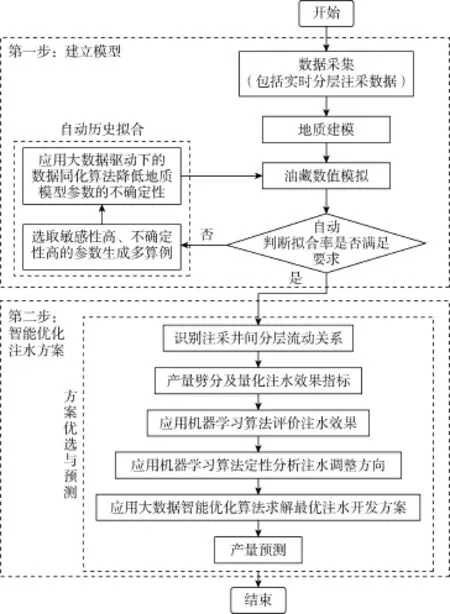
图2 大数据驱动下注水优化模拟流程
2.1 建立符合油藏地质及动态特征的模拟模型
采集油藏的静态数据及注采井层段累计流量、瞬时流量和压力等实时“硬数据”,应用地质建模技术建立油藏构造与静态属性模型。在地质模型基础上,借助数据同化算法,自动拟合出油藏数值模拟模型。本文采用集合卡尔曼滤波方法,根据生产动态数据对油藏模型进行调整和校正[13]。
传统的卡尔曼滤波方法是一种基于最小二乘估计原理,结合贝叶斯理论的参数反演方法。集合卡尔曼滤波方法是卡尔曼滤波方法的一种蒙特卡罗实现形式。首先根据先验信息产生一组初始模型(初始样本集合),利用该组模型平行地进行模型预测,并根据预测结果与实际生产历史之间的差异调整初始模型样本集合,即计算两者的误差协方差矩阵。逐步更新数值模型不确定参数,从而减小预测值与观测值之间的误差,该方法在处理大规模问题上有着明显的优势。
在拟合过程中,选择可靠性较低且对模拟结果较敏感的各小层基质孔隙度、渗透率、垂向渗透率与水平渗透率比值、初始油水界面毛管压力值(影响初始油水分布)4类参数作为待调整变量进行调整,根据地质背景和测井解释分析确定各参数的调整范围(见表1)。

表1 待拟合参数的取值范围
使用集合卡尔曼滤波方法进行历史拟合,设置20个实现,分4次进行数据同化。图3为拟合过程中所有实现的计算含水率与实际油藏综合含水率的对比曲线。可见随着同化的进行,计算结果迅速向实际数据靠拢,最后收敛到真实生产数据附近。在模拟过程中第24年开始的预测阶段各实现的表现与实际生产数据基本吻合,验证了拟合的正确性。
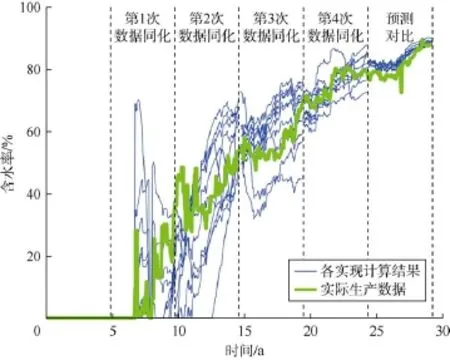
图3 拟合收敛过程
在拟合过程中,4类待调整参数也随着拟合的进行快速收敛,某主力小层 4个参数随数据同化次数的收敛情况如图 4所示。对该油藏的地质模型,孔隙度乘数、渗透率乘数、初始油水界面毛管压力收敛较好,说明敏感性极高;渗透率比值收敛较差,表明该油藏由于隔层发育,纵向连通性差,流体的纵向流动比例较小,因此不敏感。
选择拟合得到的最佳模型开展后续研究,该模型结果基本能够反映油藏开发过程及渗流规律。
2.2 智能优化注水方案
在拟合率达标的油藏数值模拟模型基础上,通过调整单井或各层段配注量,对区块的注采系统进行优化,达到控水稳油和减缓递减的目的,具体的优化目标包括提高区块产油量和降低区块含水率。该方法解决了人工仅能制定有限套方案进行优选的问题,方案优化分为6步。
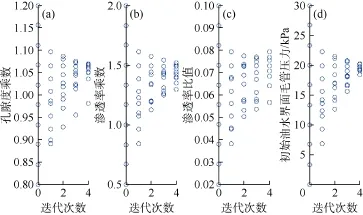
图4 待调整参数的收敛过程
2.2.1 识别注采井间分层流动关系
在上一步自动历史拟合得到的地质模型基础上,根据分层注采流动关系自动识别方法[14],计算区块历年分层注采井间的流动关系。该方法应用储集层物性、单砂体的展布与形态、断层形态与封闭性、生产动态资料、吸水产液剖面、油水井射孔及措施层位、油水井相对位置、示踪剂监测等资料进行自动识别,识别原则如下:①同一砂体中合适的井距井网下注采井间具有连通流动关系;②分布在不同砂体中的注采井不连通;③泥岩区的注水井或采油井不连通;④有封闭断层或泥岩区遮挡的注采井不连通;⑤砂体形态造成注采井间流动路径过长,则注采井间不流动或弱流动;⑥合适条件下注入水可以绕开遮挡物流动;⑦处于同一方向的二线油井难以受效;⑧油井可以多向受效;⑨合适的角度和井距条件下,一口注水井可以有多口油井受效;⑩注采井在某层不是同时为射开状态时不流动;⑪流线不能交叉。
2.2.2 量化井组注水效果指标
在识别分层注采流动关系的基础上,根据多层多向产量劈分技术[15]计算采油井分层分方向的产液量与产油量。该方法力求“用全和用准”老油田积累的各类生产资料,充分考虑井网分布特征、储集层静态物性、补孔改层措施、压裂措施、注采动态、吸水剖面、水淹层测井、压力恢复/降落、注采反应和压力分布等多种因素,结合分层注采井间的流动关系计算结果,应用渗流力学理论、油藏工程方法和油藏生产数据,对注水井的注水量和采油井的产液量及含水率进行分层分方向的劈分。
根据产量劈分结果,以注水井为中心分 3个级别量化注水效果。注水效果指标包括注水井周围的受效油井数、注水井驱出的液量和油量、注采比、耗水率、存水率、水驱指数、瞬时注水量和累计注水量等,还包括累计冲刷时间、注水强度等指标[16]。3级注水效果指标分别为:①注水井组全井注水效果指标,即以注水井全井为中心的注水效果指标;②注水井组层段注水效果指标,即以注水井的一个注水层段为中心的注水效果指标;③注水井组单层注水效果指标,即以注水井一个单层为中心的注水效果指标。以注水井组3个级别的耗水率为例,说明注水效果指标的计算方法。
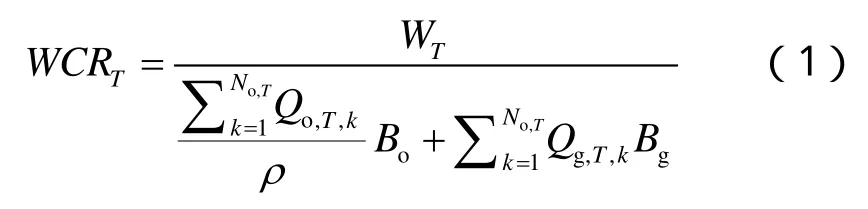
2.2.3 评价注水效果
应用机器学习的聚类算法对每个注水井组的所有注水效果指标进行聚类,分成好(大)、较好(较大)、中、较差(较小)、差(小)5类。如所有井组的耗水率分为好、较好、中、较差、差 5类;所有井组的注水强度分为大、较大、中、较小、小 5类,本文采用K-means算法对各种指标进行聚类。
2.2.4 定性分析注水调整方向
根据注水井组多个注水效果指标的评价结果,应用机器学习的聚类算法,实现注水井组中增注、减注、维持注水量的判断,构建定性分析注水调整方向的决策树(见图5)。
2.2.5 优化注水方案
本文多目标优化采用多目标粒子群优化算法。粒子群优化算法[16]是Kennedy和Eberhart通过模拟鸟群觅食过程中的迁徙和群聚行为而提出的一种基于群体智能的全局随机搜索算法。粒子群优化算法初始化为一群随机粒子(随机解),通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个极值以进行更新:粒子本身所找到的最优解,称为个体极值;整个种群目前找到的最优解,称为全局极值。经过多目标粒子群优化算法优化后,将得到一组非劣解粒子,作为“精英集”;通过小生境技术计算“精英集”中非劣解粒子的适应度值,聚集程度越大的粒子适应度越小,最终选取适应度最大的粒子作为最优解。
在确定区块总注入量、井组注水调整方向和配注量调整范围的基础上,针对两个优化目标,应用粒子群优化算法和小生境算法,对配注量进行优化,即依据产油量、含水率等指标定量优化增注井组(或井组层段)增注量和减注井组减注量。
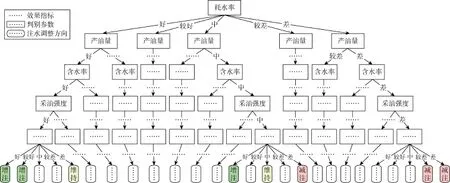
图5 决策树算法示例图(效果指标包括好、较好、中、较差和差;注水调整方向包括增注、维持注水量和减注)
2.2.6 预测产量
根据优化的配注方案,应用拟合好的油藏数值模拟模型预测区块的产油量和含水率等指标。
3 工程案例分析
以中国东部某复杂断块油藏为例,该区块含油面积2.93 km2,地质储量1.655×107t,共有42个小层,区块整体构造为两条北东走向的正断层夹持的地垒式长轴背斜,内部构造为两边高,中间低的地堑;储集层岩性以细砂岩、粉砂岩为主,岩性变化大,砂泥岩互层特征明显;物性属中孔中渗。区块开发分为 4个阶段,分别为:①产能建设、全面投产阶段;②细分开发层系、井网加密调整阶段;③合注合采、局部加密、含水率上升、产量递减阶段;④控水稳油阶段。目前区块井总数237口,其中油井开井数102口,水井开井数60口,区块综合含水率89.12%。根据地质情况和测井数据建立的研究区油藏地质模型共42个网格层、143 000个有效网格(见图 6)。通过自动历史拟合,获得了区块不同时期的含油饱和度分布(见图7)。该区块单井含水拟合率达到85%以上,图8所示为其中两口油井的计算含水率与实际含水率数据对比。基于拟合后的油藏地质模型,利用分层注采井间流动关系自动识别技术,计算历年各小层的注采流动关系(见图9)。
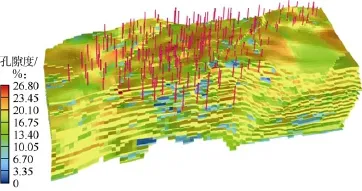
图6 示例区块地质模型
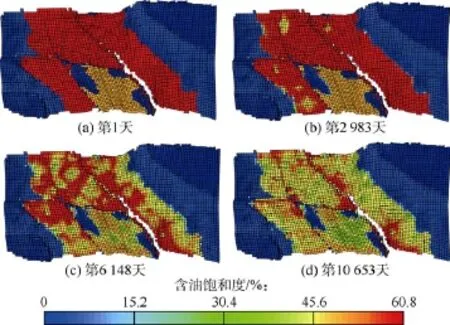
图7 示例区块某小层含油饱和度变化
在分层注采流动关系计算的基础上,根据多层多向产量劈分方法,计算每个注水井组的含水率、耗水率、产油量、产液量、注采比和动用油层总厚度等多项注水效果评价指标,图 10为所有注水井组采油井的含水率、产油量和耗水率指标对比图。应用机器学习的聚类算法,把所有注水井组的各注水效果指标聚成 5类(好、较好、中、较差、差),图11为所有注水井组耗水率、注采比、含水率和产油量聚类结果。根据注水效果评价结果,应用决策树算法,把所有注水井组评定为增注、维持、减注3类,结果如图12所示,其中187井是减注井、73井是维持井、95井是增注井。
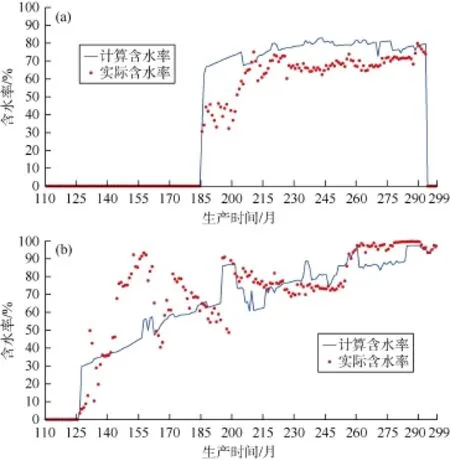
图8 两口单井实际含水率与计算含水率对比曲线
应用粒子群优化算法和小生境算法,对增注井和减注井的配注量进行优化,达到区块累计产油量较大、含水率较低的目标,示例区块优化后12个月内累计产油量比未优化时相对增加8.2%,配注量优化结果如表2所示。
根据优化的注水井组配注量,在12个月内不实施任何措施条件下,预测了区块的含水率与月产油量;同时预测了未进行注水优化时区块在未来12个月内的含水率与月产油量(见图13)。进行注水优化后区块在第12个月的综合含水率比未进行注水优化时区块综合含水率降低了1.11%,月产油量增加了1 138.2 t。
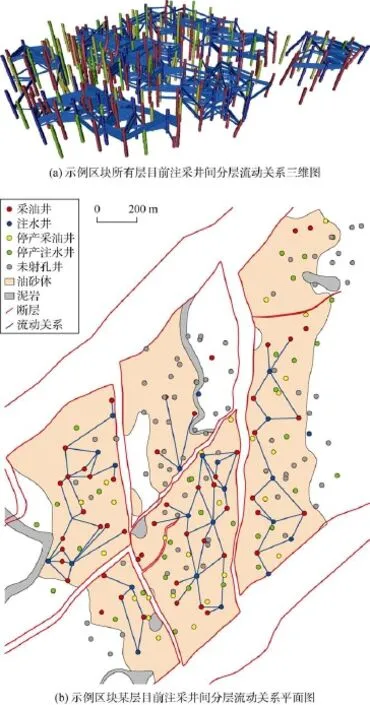
图9 示例区块目前注采井间分层流动关系
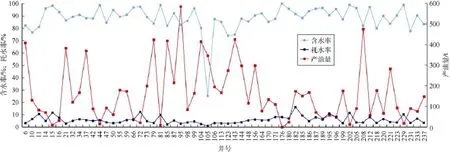
图10 示例区块采油井指标对比
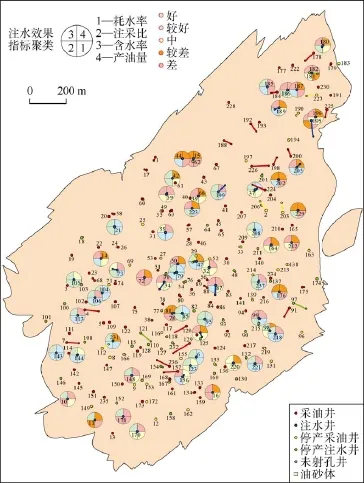
图11 注水效果定性评价结果
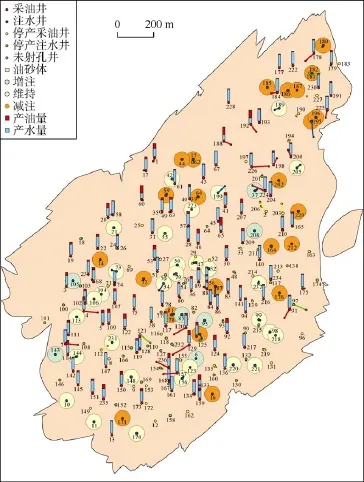
图12 注水调整方向分析结果
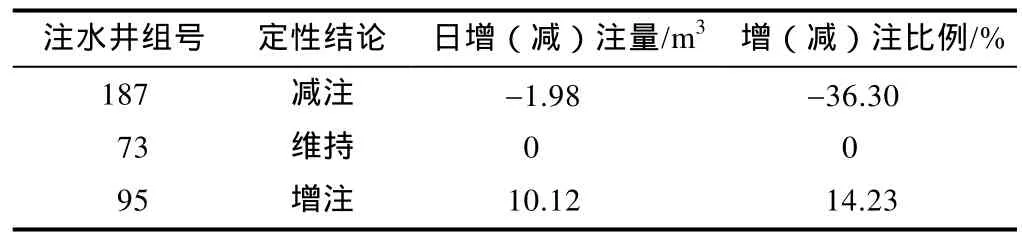
表2 定量优化配注量表
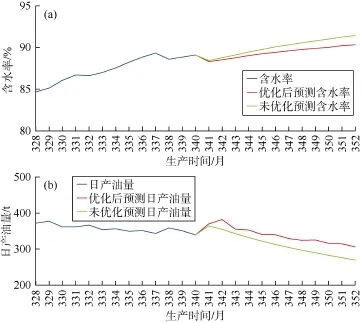
图13 示例区块含水率与产油量曲线
4 结论
针对水驱老油田分层注水的迫切需求,提出了大数据驱动下的精细注水方案优化方法:在动态生产数据的约束下,通过数据同化算法实现了地质模型参数的自动拟合;通过机器学习算法量化和评价多井分层的注水效果、分析注水调整方向;最终通过智能优化算法求解最优注水调整方案。与传统方法相比,该方法和流程充分利用了数据驱动和机器学习算法的自动化、智能化优势,数据模拟的拟合率可达到 85%,示例区块优化后12个月内的累计产油量与未优化时相比增加8.2%,将原来耗时耗力并无法保证效果的油藏历史拟合和注水方案优化工作通过机器学习算法高效完成,能够精准指导老油田精细注水方案的设计和实施。
随着第四代分层注水工艺技术的不断发展,井下永置式层段调节、层段计量和井筒双向通信等核心技术取得突破,获取了丰富的生产数据。在此基础上,结合大数据驱动下的老油田精细注水优化算法,可实现以注水方案设计、智能优化和同步调整为特色的油藏和采油工程一体化。
符号注释:
Bg——天然气体积系数;Bo——原油体积系数;k——油井序号;No——有流动关系的油井总数;ρ——原油密度,t/m3;Qg,T,k——注水井全井/某层段/某小层驱出的第k口油井相应层位的累计溶解气量,m3;Qo,T,k——注水井全井/某层段/某小层驱出的第k口油井相应层位的累计产油量,t;W——累计注水量,m3;WCR——耗水率。下标:T——表示3个级别,全井、层段或小层。
