基于改进极限学习机模型的岩质边坡稳定性评价与参数反演
2020-06-30胡焕校张天乐
邓 超,胡焕校,2,张天乐,余 童
(1.中南大学地球科学与信息物理学院,湖南 长沙 410083;2.湖南有色资源与地质灾害探查 湖南省重点实验室,湖南 长沙 410083;3.中南大学数学与统计学院,湖南 长沙 410083; 4.长沙理工大学,湖南 长沙 410076)
0 引言
滑坡是边坡物质与能量释放的一种动力学形式。滑坡每年导致的生命财产损失高于泥石流、洪水、风暴等自然灾害,且超出我们的普遍认知[1-2]。世界范围内经报道的巨大滑坡主要集中在发展中国家。在发展中国家,滑坡导致的损失约是国民生产总值的0.5%[3]。我国山岭坡地众多,地质环境复杂,滑坡已成为我国严重的地质灾害之一。根据中国地质调查局官网信息,每年可预测的滑坡占滑坡总量不足20%,因此迫切需要一种简单、快捷、可靠、低成本的方法来判断边坡的稳定性。岩质边坡滑坡能量更巨大,破坏性更强,因此岩质边坡稳定性评价成为专家学者们共同关注的焦点之一[4-6]。
鉴于线性的Mohr-Coulomb(M-C)准则不能准确的反映岩体破坏的非线性特性[7],因此广义的非线性Hoek-Brown(H-B)经验准则在岩质边坡稳定性分析中广泛应用[8]。但在工程实践中,岩质边坡稳定性分析还存在许多问题,如现有的适用于岩质边坡稳定性分析的软件一般基于M-C准则而不够准确、快捷[9]。HOEK E等[10-11]为使H-B准则适用于各种岩土工程软件,对非线性H-B准则进行修正,求解岩体的等效黏聚力和摩擦角,虽可采用M-C准则对边坡稳定性进行分析,但转换过程稍显复杂。因此,本文采用H-B准则参数作为岩质边坡稳定性分析的参量。
大数据智能计算技术以其高效、快速的自主学习和准确的预测能力等优点得到飞速发展,并在各个领域广泛应用[12]。世界上每年都有大量的边坡需要进行稳定性评价及滑坡防治,这些工程和研究实例提供了大量有价值的经验数据和研究数据。因此,许多专家学者利用这些有价值的数据,基于智能计算技术,对边坡稳定性进行评价和预测[13-15]并反演未知的边坡参数[16],以提高边坡稳定性评价的精确性和效率。一般以反映边坡综合性状的安全系数(F)来作为边坡稳定性评价的重要指标。智能计算模型依赖于获取的一系列反映边坡综合性状的参数,并以边坡参数作为输入变量,以安全系数F作为输出变量。LI等[16]和DENG等[17]的研究表明基于极限学习机模型(ELM)的智能计算对边坡变形和稳定性分析具有明显的优势。本文基于ELM模型结合变量遗忘因子(FOS),提出一种正则化的在线序列极值学习机模型(FOS-ELM),应用贝叶斯信息准则(BIC)优选H-B准则参数及边坡几何力学参数来预测边坡稳定安全系数(F)的最优输入组合,对岩质边坡稳定性进行评价和预测。FOS-ELM算法无须预设控制变量,对优化问题的影响很小,且随着边坡输入数据的增加无需重新训练,具有更好的泛化能力,避免了异常点和过度拟合问题,克服了其他智能计算模型的缺点。对比分析了ELM与FOS-ELM模型预测岩质边坡稳定性的精确性,论证了输入变量7因素BIC最优组合的科学性,为大数据智能计算在岩质边坡稳定性评价中的应用提供了一种新方法。鉴于岩土勘察仅能获得有限的试验数据,具有费用高、周期长[18],测量不确定性、转换模型不确定性[19]等缺点,且难以真实反映岩体参数的空间变异性[20],采用不同赋值的全参数输入模型(FOS-ELM-M7)作为边坡参数反演计算模型,对岩质边坡的参数进行反演计算,为岩质边坡的参数快速估计提供了一种新的方法。
1 模型设计
1.1 确定变量
控制岩质边坡稳定性的主要因素是岩体中具有不同力学性质和规模的结构面。HOEK等[8]提出了最新版本的节理岩体强度的广义经验准则,可表示为:
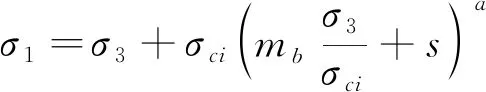
(1)
式中:σ1、σ3——分别表示为岩石破坏过程中的最大、最小主应力;
σci——岩石单轴抗压强度;
mb、s和ɑ——岩体材料常数;
mb和s——岩体的经验参数;
s——用于量化岩体的破碎程度指标。
mb、s和ɑ可由下式得到:
mb=miexp[(GSI-100)/(28-14D)]
(2)
s=exp[(GSI-100)/(9-3D)]
(3)
α=1/2+1/6(e-GSI/15-e-20/3)
(4)
mb、s的值取决于地质强度指标(GSI)与岩体扰动因子(D),ɑ的值仅取决于GSI。GSI的值(10≤GSI≤100)采用节理化岩体强度与力学参数估计的地质强度指标GSI法确定;D值大小取决于工程经验(0≤D≤1),原状未扰动岩体D=0,扰动岩体D=1;mi(1≤mi≤35)是一个与岩石类型有关的材料常数,可通过岩石三轴试验拟合得到,也可以根据岩石类型确定。
如前所述,H-B准则具有非线性特征,能较好地反映节理岩体的强度特性,但其应用也具有一定的局限性[21-22]。基于GSI指标的H-B准则适用于图1中I组和III组的岩体,即完整岩体和节理组数不少于3的岩体[9]。文中搜集的1 235例岩质边坡均为重节理岩体,属第三类。
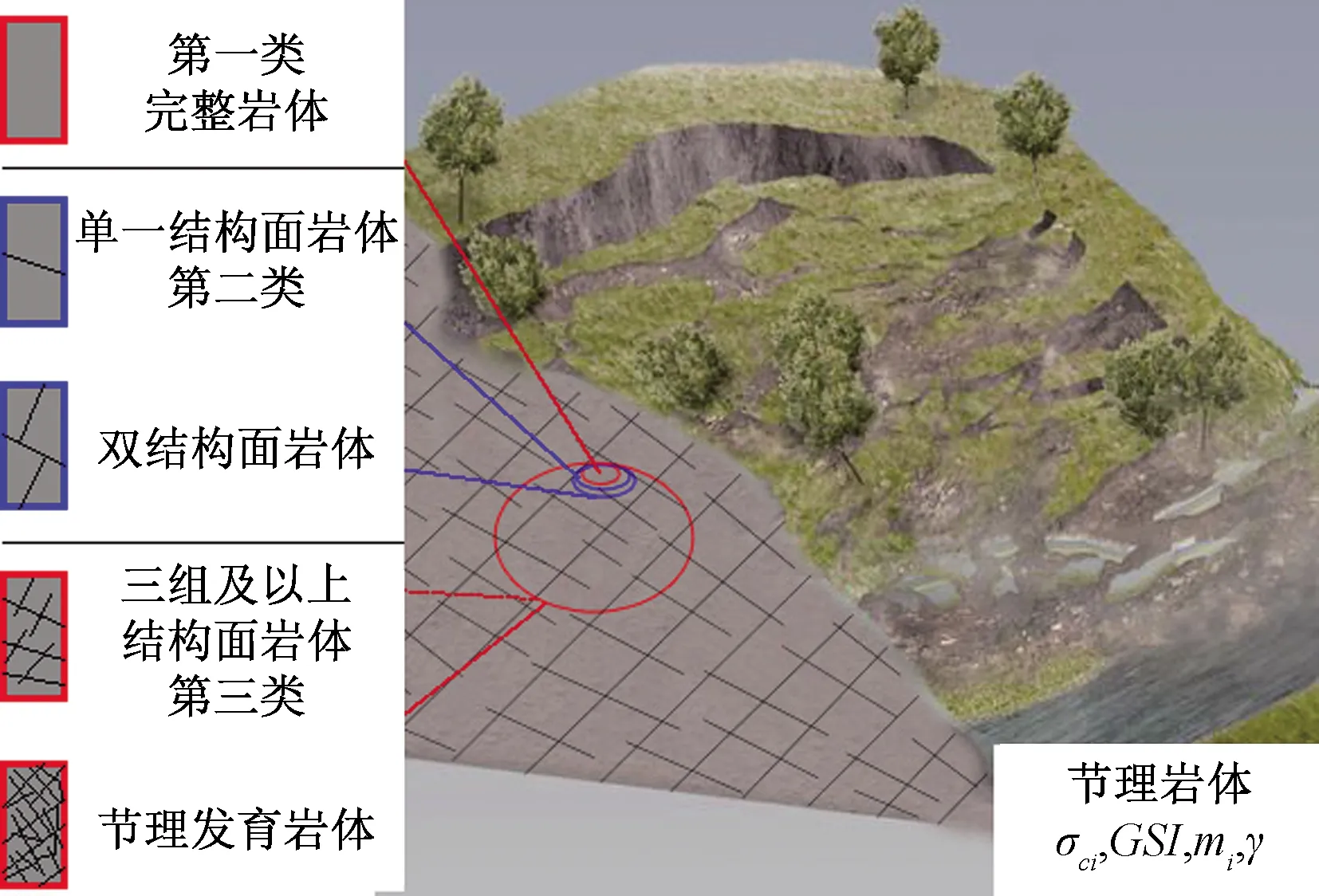
图1 H-B准则的适用性Fig.1 Applicability of the Hoek-Brown criterion
考虑反映岩体特性的H-B准则参数与边坡的坡高(H)、坡角(β)、岩体重度(γ)等对边坡稳定性的影响,故本文采用GSI、mi、D、σci、γ、H、β作为输入变量,以边坡安全系数F作为输出变量。LI等[16]对基于H-B准则的Bishop方法与上、下限分析法计算的岩体边坡的安全系数进行比较,表明基于H-B准则的SLIDE软件的解更接近边坡稳定的真实解。因此,以基于H-B准则的Bishop法的GEOSLOPE软件求解的边坡稳定安全系数作为真值。
1.2 变量选择
对于边坡稳定性预测,变量选择是关键。已有研究表明,选择相关性小的变量将导致预测精度显著降低。若选择无关或影响效应低的输入变量,不仅影响输入变量间的相互关系,而且可能增加地质勘察工作的工作量。在地质调查中,若部分边坡参数难以获得,可利用仅有的参数对边坡稳定性进行初步预测。因此,对变量进行优化,确定其相关性和预测误差具有重要的现实意义。
BIC[23]是在主观概率估计的基础上,利用贝叶斯公式对概率进行修正,最后利用期望值和修正概率做出最优决策选择后验概率最大的模型。即以BIC值最小化的变量子集为最优,因此,BIC可用于优化边坡输入变量组合,确定不同组合下的误差,从而对边坡稳定性做出可靠的预测。BIC的值可表示为:
BIC=-2lnL+klogn
(5)
式中:L——估计模型似然函数的最大值;
k——模型中估计参数的个数;
n——样本量。
1.3 模型建立
ELM模型是2006年提出的基于随机权重配置的单隐含层模型,后将ELM模型推广到广义单层前馈网络(SLFNs)中,其中隐含层神经元不必相同[24]。ELM模型的单隐层前馈神经网络如图2所示。
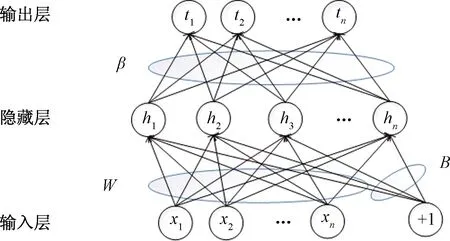
图2 ELM模型的单隐层前馈神经网络图Fig.2 The network of classical ELM
给定一个包含N个不同样本的训练集,Γ={(xj,tj) |xj∈Rn,|tj∈Rm,j=1,…,N},其中x为n维的输入变量,t为m维的目标变量。具有M个隐藏神经元SLFN的数学模型的激励函数G(·)可表示为:
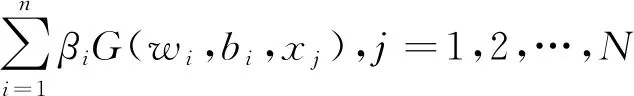
(6)
式中:wi——连接第i个隐藏节点和输出节点的随机分配的输入权向量;
bi——第i个隐藏节点的任意分配偏差;
G(wi,bi,xj)——xj输入样本的第i个隐藏节点的输出结果,其作用是将输入层的数据由其原本的空间映射到ELM的特征空间。
当SLFN模型完全逼近样本数据,即当输出值与真值之间的误差为零,之间对应关系可表示为:
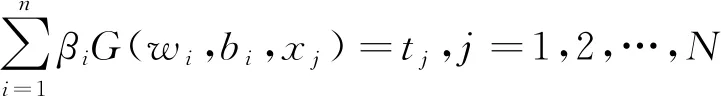
(7)
式(7)可写成矩阵式:
Hβ=T
(8)
其中,

(9)

(10)
输出权值可利用式(8)通过寻找SLFNs最小二乘解得到,其表达式为:
β=H†T
(11)
其中H†为矩阵H的Moore-Penrose广义逆,若HTH为非奇异矩阵,那么式(11)可表示为:
β=H†T=(HTH)-1HTT
(12)
ELM算法的核心是求解输出权重使得误差函数最小,因此我们在ELM的loss函数中引入l-2正则化约束提高模型的泛化能力和稳定性。式(12)可转化为:
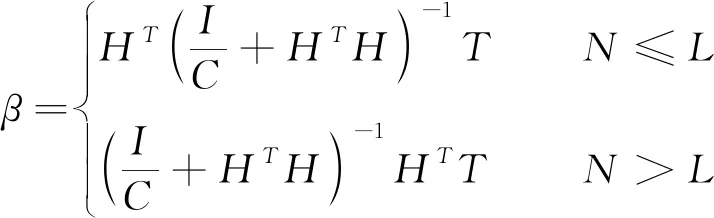
(13)
式中:C——正则化系数;
I——单位矩阵;
N——样本个数;
L——隐层神经元个数。
但传统的人工智能算法,如人工神经网络、支持向量机、极限学习模型等,在获取大量边坡新数据时,需要同时收集新旧数据进行重新训练[25]。因此,传统的人工智能算法很难解决大数据、非平稳、数变、时变等预测问题。为了有效地解决数据流的非平稳和数变问题,开发了在线顺序极值学习机模型(OS-ELM)。OS-ELM的学习包括一个初始的ELM批量学习过程和一个连续的逐块学习过程。但当学习过程中隐含层输出矩阵的自相关矩阵是奇异的或病态的,OS-ELM的泛化能力急剧退化。BOU-RABEE[26]为克服OS-ELM的这一缺点将Tikhonov正则化与OS-ELM相结合,提出了一种正则化的OS-ELM,以提高算法的稳定性和泛化能力。为解决样本增加在线学习过程中的时变性和量变性问题,故将遗忘因子(Forgetting Factor)[27]引入到OS-ELM当中。R-ELM-FF算法在理论等价于最小化下列基于FF和l-2正则化的最小二乘误差函数:

(14)
式中:λ——新旧样本权重的FF参数;
δ——提高算法稳定性和泛化能力的正则化参数。
基于递推计算式[28],采用递推最小二乘法求解式(14),βk可推导为:
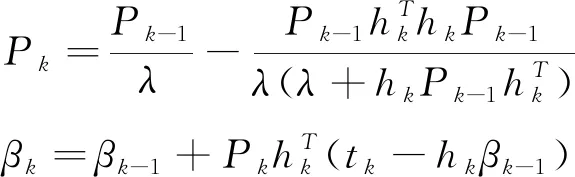
(15)
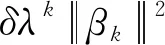

(16)
FOS-ELM的运行如下:
设数据样本为数据流的形式,激励函数为G(w,b,x),隐藏神经元数为n,正则化参数为δ,遗忘因子为λ。
步骤1:初始化。
给定初始训练子集Ωk-1={(xj,tj)|xj∈Rn,|tj∈Rm,j=1,…,k-1},执行下述操作:
(1)随机生成隐藏层神经元参数(wi,bi),i=1,2,…,n;
步骤2:在线学习与预测。
对新样本(xk,tk)执行以下操作:
(1)计算新样本输入xk:hk=[G(a1,b1,xk) …G(an,bn,xk)]的隐含层输出向量;
(3)根据真值tk调整输出权重。
(4)返回步骤2。
1.4 结果评估
采用多种统计指标对FOS-ELM模型和经典的ELM模型在岩质边坡稳定性安全系数F预测结果进行评估,如式(17-19)所示。
(1)相关系数(r)可表示为:
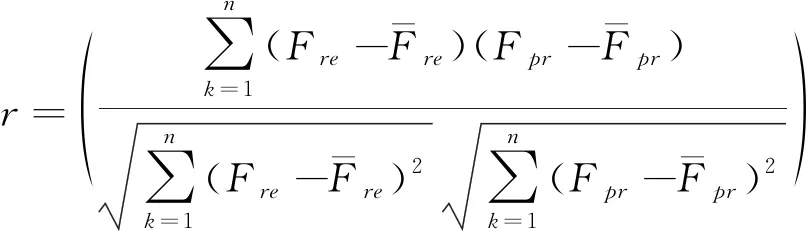
(17)
(2)均方根误差(RMSE)表示为:
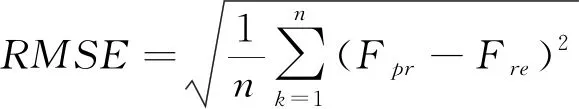
(18)
(3)平均绝对误差(MAE)表示为:
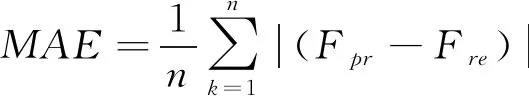
(19)
式中:Fpr、Fre——分别表示岩质边坡稳定性安全系数预测值与真值;
1.5 预测过程
FOS-ELM模型最优输入组合(GSI,mi,σci,D,γ,β,H)的岩质边坡稳定安全系数F的预测及参数反演过程(图3)。
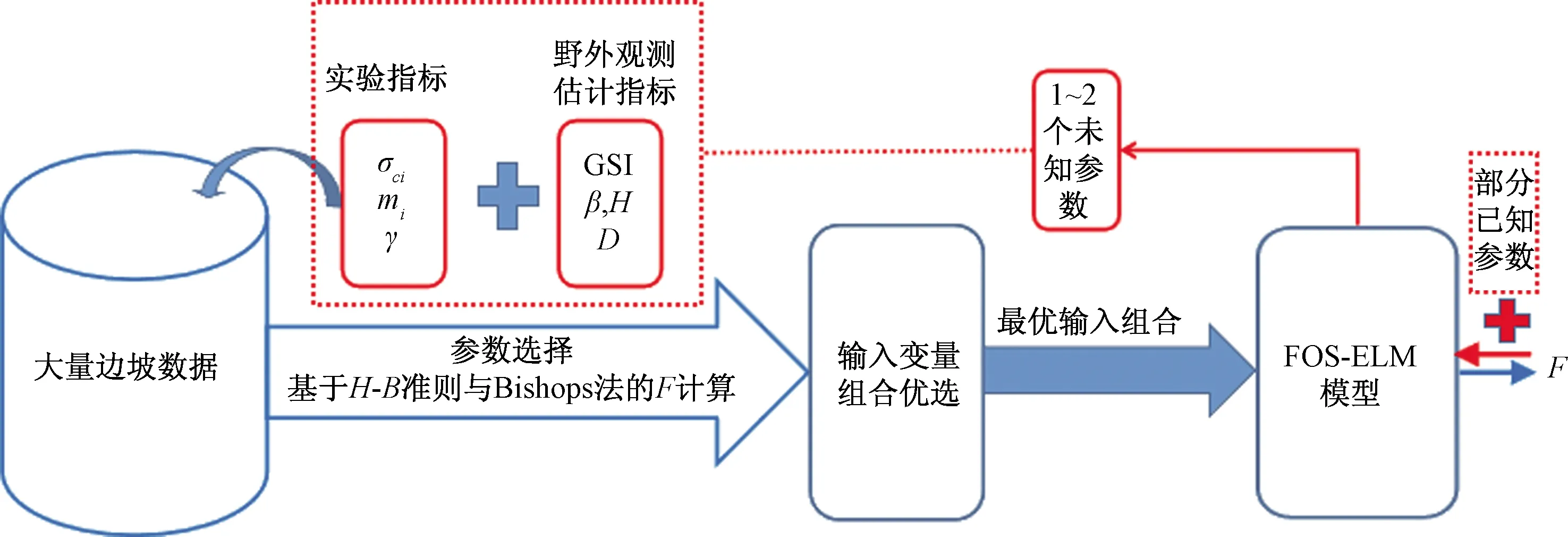
图3 FOS-ELM模型预测F及参数反演过程示意Fig.3 Process diagram of the FOS-ELM model for predicting F and parameter inversion
2 测试结果与分析
如1.1所述,选用岩质边坡的GSI,mi,σci,D,γ,H和β作为FOS-ELM模型的输入变量,安全系数作为输出变量(Fpr)。因此,该模型选择7个输入量和1个输出量。从样本中随机抽取1 085组数据作为训练集,其余150组数据作为验证集。利用BIC值进行变量组合优选,生成输入参数的最佳组合,建立了7种最优组合模型。在Geo-slope软件中基于H-B准则的极限平衡法计算真值(Fre)。利用预测值(Fpr)与真值(Fre)在验证阶段的统计指标与误差分布对比分析FOS-ELM模型与经典的ELM模型。
2.1 BIC值最优模型结果与分析
在Matlab中计算所有输入变量组合的BIC值,其中BIC值最小的变量组合为最优。针对不同数量的输入变量,在最优输入组合的基础上建立了7种不同的模型(M1、M2、M3、M4、M5、M6、M7),包括所有输入变量的模型。基于FOS-ELM与经典ELM的7种模型对岩质边坡稳定性安全系数预测值(Fpr)与真值(Fre)线性关系如图4所示。
若预测值Fpr和真值Fre的相关关系可用线性方程y=kx拟合,且指数系数r2和斜率k接近1,说明该模型的预测性能好,拟合效果优。因此,本文在Origin软件中利用y=kx的线性拟合Fpr和Fre。图4通过散点图分别显示了不同优选输入组合下的FOS-ELM与ELM模型的Fre和Fpr的拟合结果。所有参数作为最优输入组合的模型M7,图4(g)中指数系数r2和斜率k(FOS-ELM:r2=0.991 3,k=1.005 9;ELM:r2=0.967 3,k=1.013 2)表明FOS-ELM模型的预测效果优于经典的ELM模型。同样,以六参数(GSI,σci,mi,D,H,β)最优输入组合的模型M6,FOS-ELM与ELM模型的指数系数r2(FOS-ELM:r2=0.904 5;ELM:r2=0.706 8)和斜率k(FOS-ELM:k=0.990 9;ELM:k=0.981 1)表明本文建立的FOS-ELM模型预测效果优于ELM模型。类似地,最优输入组合M5,M4,M3,M2,M1模型的预测结果亦同上。对比图4(a)~(g)表明基于FOS-ELM模型M7预测效果最优,精度最高。同时,基于FOS-ELM模型的M5预测效果仅次于M7,表明输入参量的个数对预测效果的优劣产生影响,即采用FOS-ELM模型进行岩质边坡稳定性安全系数预测时并不是确定的输入参量越多预测效果更优。
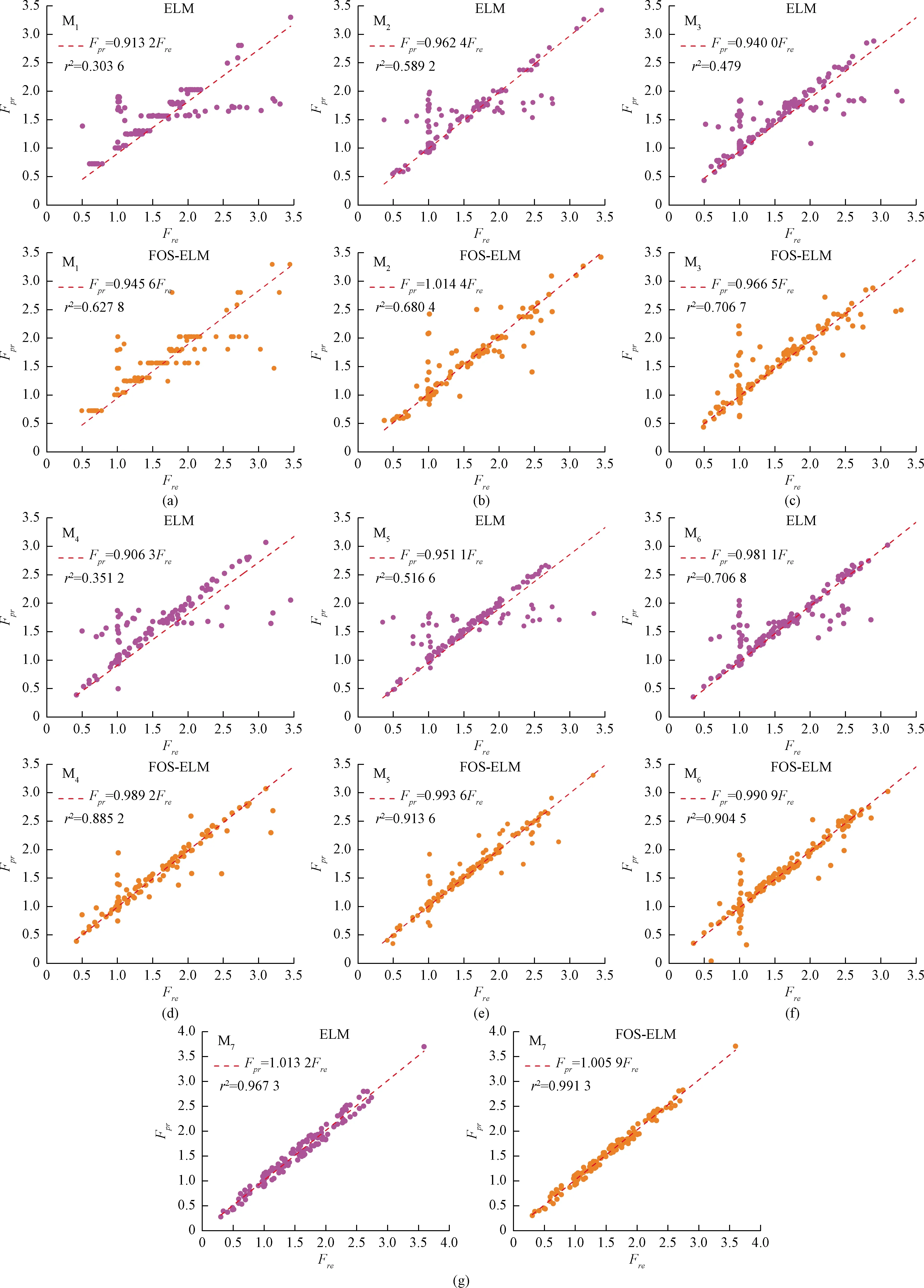
图4 基于FOS-ELM与ELM的7种输入组合模型对岩质边坡稳定性安全系数预测值(Fpr)与真值(Fre)关系Fig.4 The relationship between predicted Fpr and Freof rock slope stability by seven models,FOS-ELM vs. ELM
基于大数据智能计算预测是未来应用的方向之一,但LI A J[16]等的研究表明ELM模型训练岩质边坡参量并预测稳定数Nr,这一过程需耗时数小时。同时,智能计算需要大量的数据以提高模型预测能力,工程实践的开展使得岩质边坡工程数据不断增加,新数据组增加的同时计算工作量也将增加,且须重新训练,这将大大降低预测工作的效率。而基于FOS-ELM模型的无需重新训练这一优点,将一定程度上提高预测效率(图5),训练数据组增加到500时FOS-ELM的训练效果。因此,ELM模型的预测效率较FOS-ELM模型低,且图4表明FOS-ELM预测精度较高,图6验证结果亦表明FOS-ELM的预测精度高这一优点。
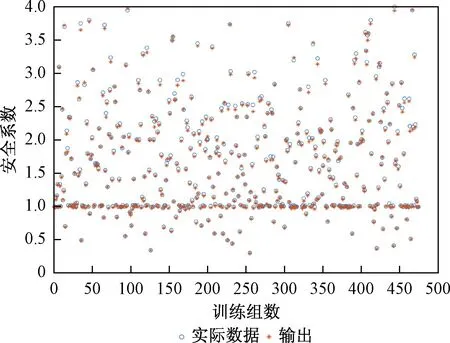
图5 数据增加至500时FOS-ELM模型的训练效果Fig.5 Train performance using FOS-ELM model with data increased to 500
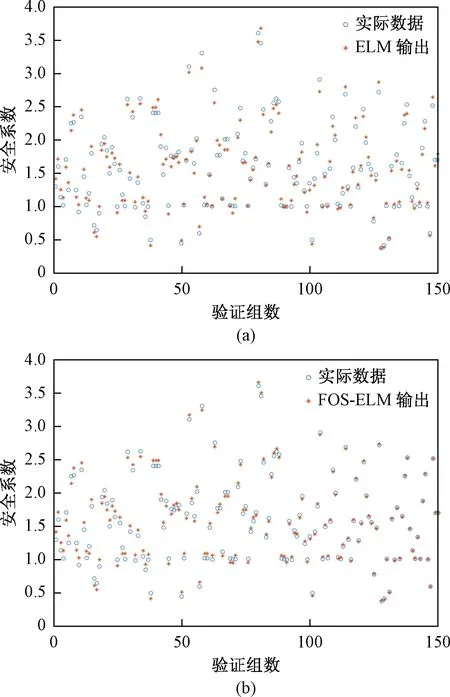
图6 ELM与FOS-ELM模型150组数据验证效果 (训练数据增加至500)Fig.6 Performance of 500 data trained by ELM and FOS-ELM with 150-validation data set
为进一步分析FOS-ELM模型预测的精确性,计算了训练数据从500增加至1 085组时的相关系数(r)、均方误差(RSME)、平均绝对误差(MAE),与每个输入组合的ELM模型比较(表1)。显然,训练集增加至1 085 时七参量最优输入组合的FOS-ELM模型具有最大的相关系数(FOS-ELM:r=0.994;ELM:r=0.987),最小的均方误差(FOS-ELM:RSME=0.069;ELM:RSME=0.100)和平均绝对误差(FOS-ELM:MAE=0.060;ELM:MAE=0.090)。此外,训练集为500或1 085 时,不同输入参量最优组合(M1,M2,M3,M4,M5,M6)的FOS-ELM较ELM模型具有更大的相关系数(r),较小的均方误差(RSME)和平均绝对误差(MAE)(数集增加至1 085时M2除外)。前述表明,提出的FOS-ELM模型是一种较经典的ELM模型更优的岩质边坡稳定性安全系数预测的智能工具。
2.2 参数反演
边坡参数反演法克服了室内实验与现场试验的缺点[20],是获得岩土体参数的一种有效方法。2.1节表明全参数最优输入的FOS-ELM-M7模型具有较好的工作性能,因此基于该模型建立参数反演计算过程(图3)。
针对工程实践中难以客观量化的地质强度指标GSI、边坡扰动因子D、材料常数mi的反演结果分析反演模型的计算精度。在Matlab中实现该计算过程得到岩质边坡单未知参数、双未知参数、三未知参数。反演结果与文献[16,29-30]工程例对比结果见表2。为进一步分析参数反演精度,分别对比反演结果与工程例参数(图7~图9)。
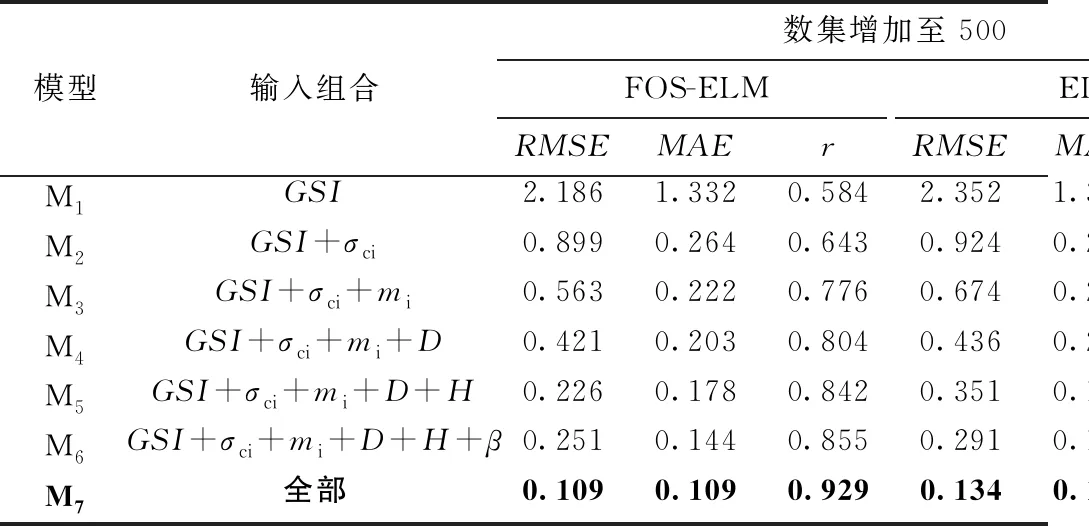
表1 七组输入组合模型下的边坡参量变化影响(三统计指标作为评价依据)
注:加粗行代表最优输入组合。
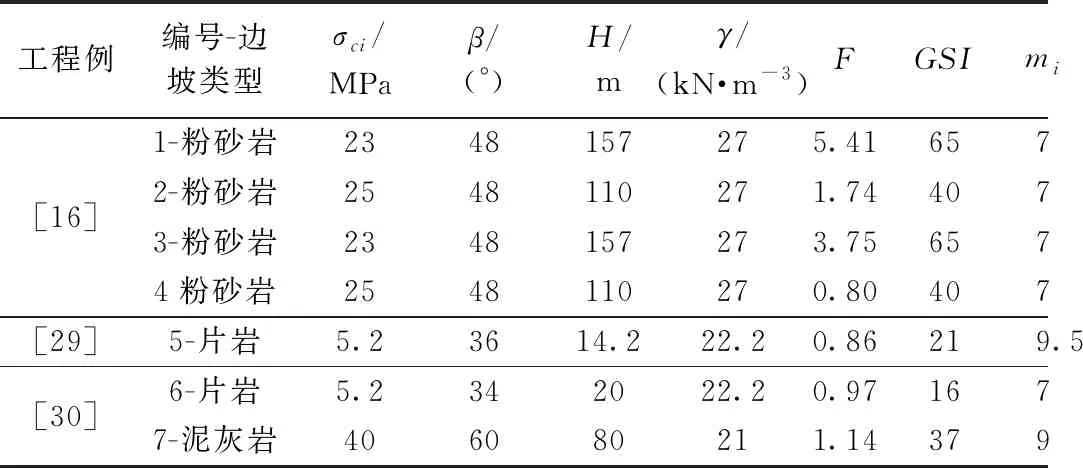
表2 工程例参数(GSI、mi、D)反演结果
注:单参数反演时,即该反演参数未知,其他为已知参量;双参数反演时,即该反演双参数未知,其他为已知参量;三参数反演时,即反演三参数未知,其他为已知参量。
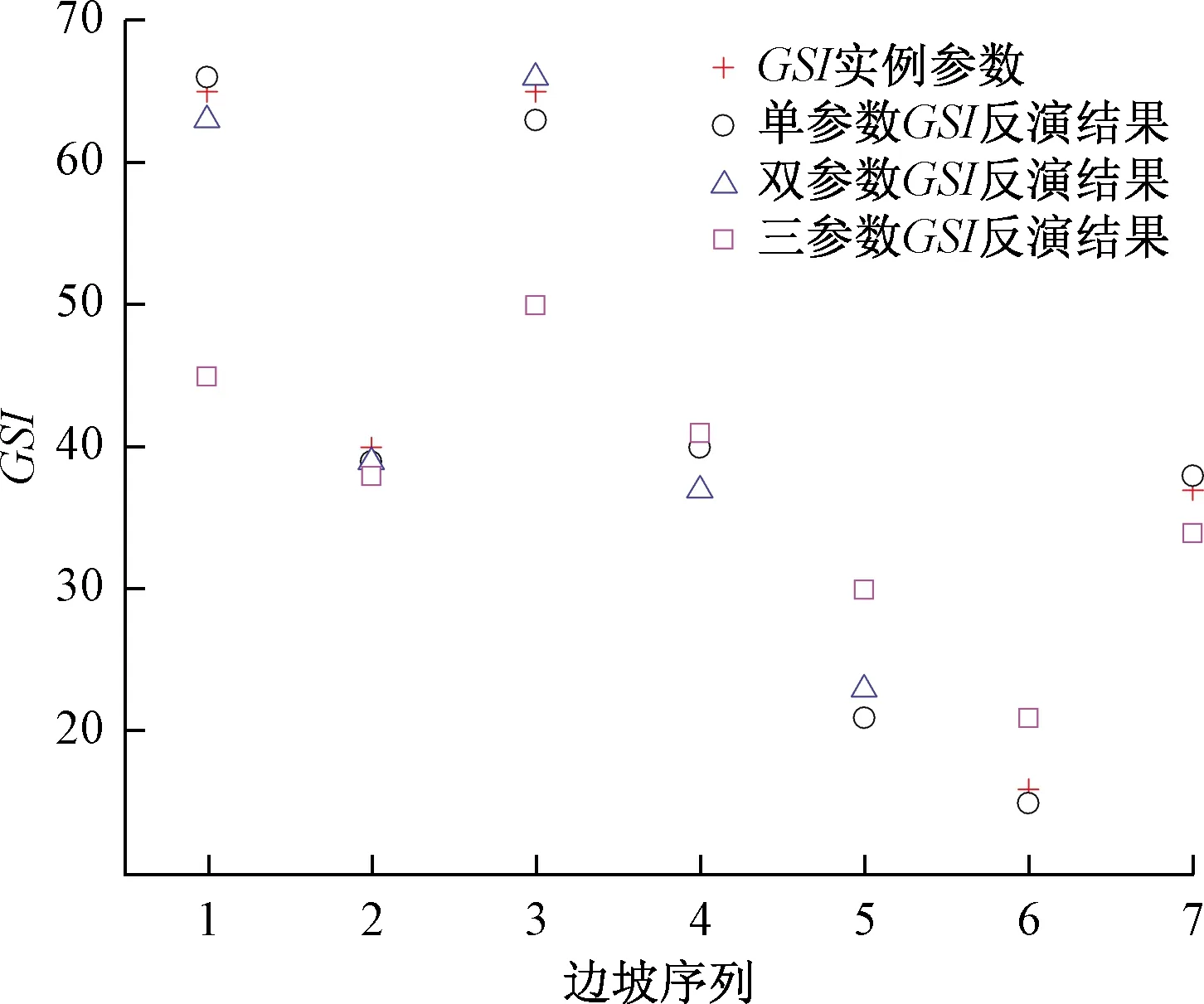
图7 GSI反演结果Fig.7 The inversion results of GSI
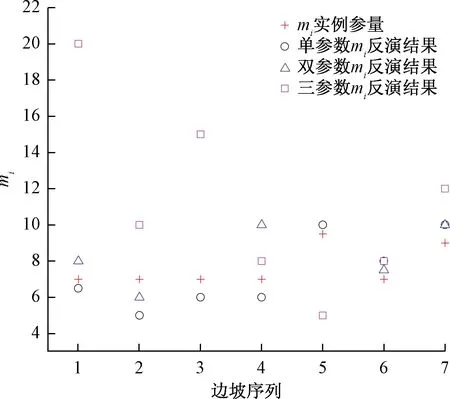
图8 mi反演结果Fig.8 The inversion results of mi
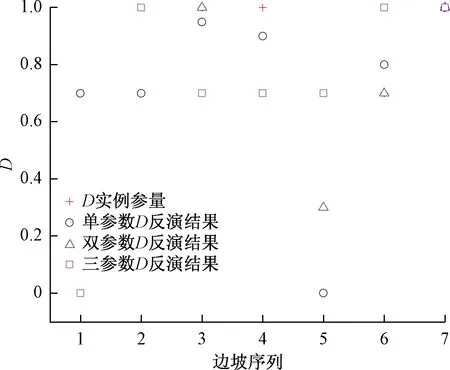
图9 D反演结果Fig.9 The inversion results of D
由图7~9知,该模型对1~2个未知参数反演计算与工程例参数接近,反演精度较高。其中单参数和双参数GSI反演的偏差绝对值分别为0%~6.5%、1.5%~9.5%,反演精度最高。单参数mi反演偏差绝对值为0%~28.5%,单参数D反演偏差绝对值为0%~14.3%,由于mi在取值是通过地质工程师根据岩石种类半经验主观确定参数,同时D值取值根据H-B准则经验取值均为0、0.7、1.0,故在FOS-ELM训练数据中同类岩体mi取值幅度较小及D值取值相对固定,这就导致模型的学习效果欠佳,对于mi、D的个别反演结果偏差分别达28.5%和14.3%。由于模型训练数据有限,三参数的反演计算结果偏差较大。
3 结论
本文拓展了大数据智能计算在岩质稳定性预测及参数反演中的应用,提出了一种结合ELM模型的变量遗忘因子正则化在线序列极值学习机模型(FOS-ELM),并将其应用于岩质边坡稳定性预测和边坡参数的反演。主要结论如下:
(1)采用7变量组合,边坡安全系数的预测精度最高,但预测精度并不随输入变量个数增加成正比。
(2)与经典的ELM模型比较,FOS-ELM模型具有高效和精确的优点。
(3)FOS-ELM模型试图更新网络的输出权值,并随着数据的增加对网络模型进行自“修正”,以达到更高的预测精度,为处理数据增长问题提供了一种新的方法。
(4)基于FOS-ELM模型的参数反演,1~2个未知参数反演精度较高,其中GSI反演精度最高,反演偏差绝对值分别为0%~6.5%、1.5%~9.5%。
