海量数据的一种集合模糊匹配关联算法
2020-06-30娄鑫坡孔玉静
娄鑫坡,孔玉静
(河南城建学院 计算机与数据科学学院,河南 平顶山 467036)
按照数据类型的不同,匹配度关联问题可分为字符串关联、向量关联和集合关联。其中,集合数据的关联操作一般是指利用索引结构对原始数据进行分组,然后对各个分组内的数据进行匹配度关联操作,最后对各个分组的结果进行汇总并得到最终结果。众多学者都对面向集合数据的匹配度关联查询问题进行过研究,并且提出了相关的关联算法[1-3]。其中,比较具有代表性的算法是MRSimJoin[4],是针对集合数据源进行关联,即自关联。该算法从集合中随机选K个数据作为中枢,然后利用中枢数据对集合进行划分,形成k个分区,在k个分区内并行地进行K值匹配度关联操作以加快算法效率。但MRSimJoin对数据的关联是一次性的,即每次操作都是从头开始。另外,由于实际应用中数据的差异性,在划分分区时容易出现数据的倾斜问题,直接导致各Datanode负载不均衡。
本文提出海量数据下的一种集合模糊匹配关联算法,针对数据增加时关联操作效率变低的问题,该算法在Hadoop固有的分块策略基础之上对其分块策略再进一步优化,即在分块后再分阶段处理。针对数据处理过程中失真问题,如同一人名或者地址在不同的集合中会出现一定的差异[5-6],即使匹配了也不可能总是做到精确的匹配,实际上是满足某个匹配阈值的。即给定两个记录文件R和S、度量函数sim和一个模糊匹配度阈值,该值随着情况改变而动态改变,找出两个集合中的所有记录对S.a和R.a,且满足sim(S.a,R.a)≥k(模糊值)[7-8]。针对该问题,FMLASH算法提出了更广泛的适用度模糊匹配计算方法,即使用一定的标准函数度量集合之间的模糊匹配度,对于满足度量标准的数据再进行关联操作。通过与当前存在的较好处理集合数据的匹配关联算法对比,FMLASH算法在集合数据的匹配关联领域表现出了更广阔的应用前景。
1 算法提出
1.1 总体思路
在Hadoop平台下进行集合模糊匹配度关联时,最主要的一个问题是如何对数据进行分区并且复制数据,本文提出的算法思想首先基于关键字通过网络对数据进行哈希分区,拥有相同关键字的数据被分到同一个分组,但对于需要进行关联的属性值不能直接用作关键字来进行分区操作,相反,使用从其他属性值中产生的签名作为分区关键字,只有当关联的属性值具有至少一个公共签名时才有可能匹配。签名可以是一个字符串中各个单词的列表,也可以是匹配字符串长度的变化区间。
本文算法主要分三个阶段,各个阶段对应一个子算法(即FMLASH-x算法,x=1,2,3)。
第一个阶段为标记生成算法(FMLASH-1),主要用来生成全局标记集合,在后续阶段的算法中需要使用这些标记对数据进行分区。
第二个阶段为RID生成算法(FMLASH-2),集合中每一项都对应一个ID,在本阶段将会生成匹配项的ID数据对,在第三个阶段将会使用这些数据对生成匹配项。
第三个阶段主要为匹配项生成算法(FMLASH-3),使用第二个阶段的数据对并通过扫描原始数据,最终输出集合中的匹配项。
1.2 FMLASH-1算法
FMLASH-1算法基本思想是对原始数据进行处理,然后产生全局标记集合,包含两个步骤。
步骤一:map函数的输入为原始数据集合,抽取集合中每一项的关联属性值并进行标记,同时输出(token,1)数据对。为了减轻网络之间数据的流量,使用combine函数计算map所产生标记的次数。
步骤二:map函数交换key和value值,然后使用一个reduce函数在value的基础之上对所有标记进行排序,最后输出整个排过序的全局标记列表。
其中伪代码描述如下:
Step 1:
原始数据D;
Map(Writtable key,Text line){
从line中抽取关联属性(token)并标记;
Output(token,1);
}
Combine(token,iter){
使用iter遍历map阶段输出token对应的集合;
统计token出现的次数(num);
Output(token,num);
}
Reduce(token,iter){
使用iter遍历从不同结点发送token的结果;
对于token进行全局统计;
Output(token,num),将结果输出到多个文件,每个文件包含部分token;
}
Step 2:
Map(Text key,IntWritable num){
Output(num,key),将结果输入到一个reduce节点上;
}
Reduce(IntWrtiable key){
汇总所有token信息,利用框架自带排序功能;
按照key由小到大输出value的值,即token,output(token,NULL);
}
1.3 FMLASH-2算法
FMLASH-2算法主要用来产生匹配的RID对,即匹配的项所对应的标示ID,算法包含一个Hadoop阶段。在执行map函数之前,首先调用DistributedCache函数加载FMLASH-1阶段产生的token标记集合,map函数的输入为原始数据集,然后逐条检索原始数据集,对于每一项抽取标识ID和关联属性值,标记关联属性并按照对应频率进行排序,为了计算每一项之间的模糊匹配度,map函数抽取每一项的前缀并计算其长度,为每一项生成(key,value)数据对(key为前缀值,value为原始数据项)。对于由map函数所产生的数据对,reduce函数应用位置过滤规则进行过滤,对于通过过滤的集合项进行验证并输出(RID1,RID2,SimValue)。算法的伪码描述中:TWritable为一个新定义的数据类型,成员为第一阶段生成的标记,该数据类型compare方法按照标记的频率大小排序,PositionalFilter为位置过滤函数,δ为模糊匹配度阈值,其值根据需要可以动态调整。伪代码描述如下:
Setup(){
使用DistributedCache加载token列表list;
}
Map(TWrittable key,Text line){
If(line中包含集合list中的项K)
Output(K,line);
}
Reduce(token,iter){
List <-NULL;
For line in iter{
func=PositionalFilter;
If(func)
List <-line;
计算line同List中每一条记录RID的模糊匹配度sim;
If(sim >δ)
Output(RID,line,sim);
}
}
算法中的sim用来计算集合数据的模糊匹配度,主要使用的是Jaccard系数,例如:集合S={A,B,C,D,E},R={F,B,C,D,E},S和R的Jaccard计数为| S1∩S2 |/| S1∪S2 | = 4/6= 0.67,当模糊匹配度阈值不同时,所求的结果也不相同,若δ=0.75,由于R和S的Jaccard系数为0.67小于δ,因此判定R和S匹配。
1.4 FMLASH-3算法
FMLASH-3算法利用FMLASH-2阶段产生的RID数据对和原始数据集合产生模糊匹配度关联结果,该算法又包含两个步骤。
步骤一:map函数获得原始数据集合和第二个阶段产生的RID数据对,对于前者,输出(RID,record),对于后者,输出两个(key,value)数据对,分别用两个RID作为key值,value为整个RID对和模糊匹配度,reduce函数根据key值对数据进行聚合。
步骤二:map函数把输入数据传输给reduce函数,进行集合项的模糊匹配度关联操作并输出结果。
其伪代码描述如下:
Step 1:
Setup(){
使用DistributedCache加载FMLASH-2算法输出的RID列表(rd1,rd2,sim);
}
Map(LongWritable key,Text line){
Output(RID,line);
Output(rd1,(rd1,rd2),sim);
Output(rd2,(rd1,rd2),sim);
}
Reduce(IntWritable id,iter){
对于相同rd的记录record和(rd1,rd2),sim,Output((rd,rd2),(record,sim));
}
Step 2:
Map(Text key,Text record){
将key相同的记录发送到同一个reduce上;
}
Reduce(Text key,iter){
一个key对应两条记录rd1对应的记录record1和rd2对应的记录record2;
Output(NULL,(rd1,record1,rd2,record2));
}
2 实验及结果分析
2.1 实验环境
实验平台基于Windows7操作系统,硬件环境由9台普通PC组成一个集群,1台为Namenode,8台为Datanode,内存4GB,CPU型号Intel Core24核2.67GHz。软件环境为操作系统CentOS-6.4-x86_64,Hadoop版本为hadoop-2.4.1,采用Myeclipse-8.5.0集成开发环境,JDK为JDK-7u79。
2.2 实验数据
针对本文提出的模糊匹配度关联算法FMLASH,可采用三组实验分析该算法的效率:第一组实验主要测试数据集大小变化以及匹配阈值变化对算法效率的影响;第二组实验主要测试不同节点数对算法效率的影响;第三组主要测试算法的可扩展性。
采用的对比算法为MRSimJoin算法,实验中使用两个数据集,分别为DBLP[9]和CITESEERX[10]。DBLP主要包含3 600多家出版物信息,需要对XML文件进行一定的预处理操作,比如移除标签、输出每一条出版物信息,形式为
2.3 结果分析
(1)第一组实验中使用DBLP数据集,通过改变数据规模以及模糊匹配阈值δ来观察FMLASH算法的计算效率,并与MRSimJoin算法进行比对并加以分析。在DBLP数据集上两个算法的运行时间对比如图1所示,此时匹配阈值δ=3,横坐标表示数据集大小(MB),纵坐标表示运行时间。
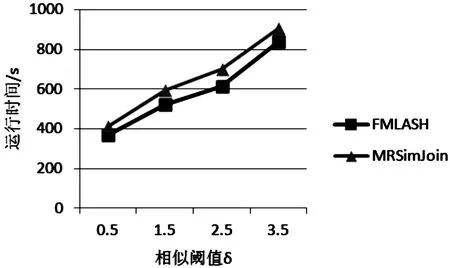
图2 匹配阈值与运行时间
由图1可知:当数据集大小为50 M时,FMLASH算法运行时间为4 198 s,MRSimJoin算法运行时间为5 123 s。由于MRSimJoin算法对数据的模糊匹配度关联操作是一次性的,每次操作均是重新开始,并且算法随机选取聚类中心,对数据集中的数据进行聚类并进行分区划分,然后在各个分区被分配到各个节点进行关联操作,因此运行时间大于前者。此外,随着数据集的增大,两种算法整体的运行时间呈增长趋势。
当数据规模一定时,匹配阈值δ的改变会对运行时间造成影响。匹配阈值变化时两种算法运行时间的对比如图2所示,横坐标表示匹配阈值,纵坐标表示运行时间(s)。
由图2可知:当匹配阈值较小时,匹配对的判定比较严苛,满足匹配条件的数据比较少,但随着匹配阈值的增加,匹配的数据对个数开始增加,两种算法的运行时间也随着增加,表明匹配阈值对算法的效率也有一定的影响。
(2)第二组实验中使用CITESEERX数据集,通过增加节点数来测试算法的性能。两种算法在不同节点数上运行时间的变化情况如图3所示,横坐标表示节点数,纵坐标表示运行时间(s)。
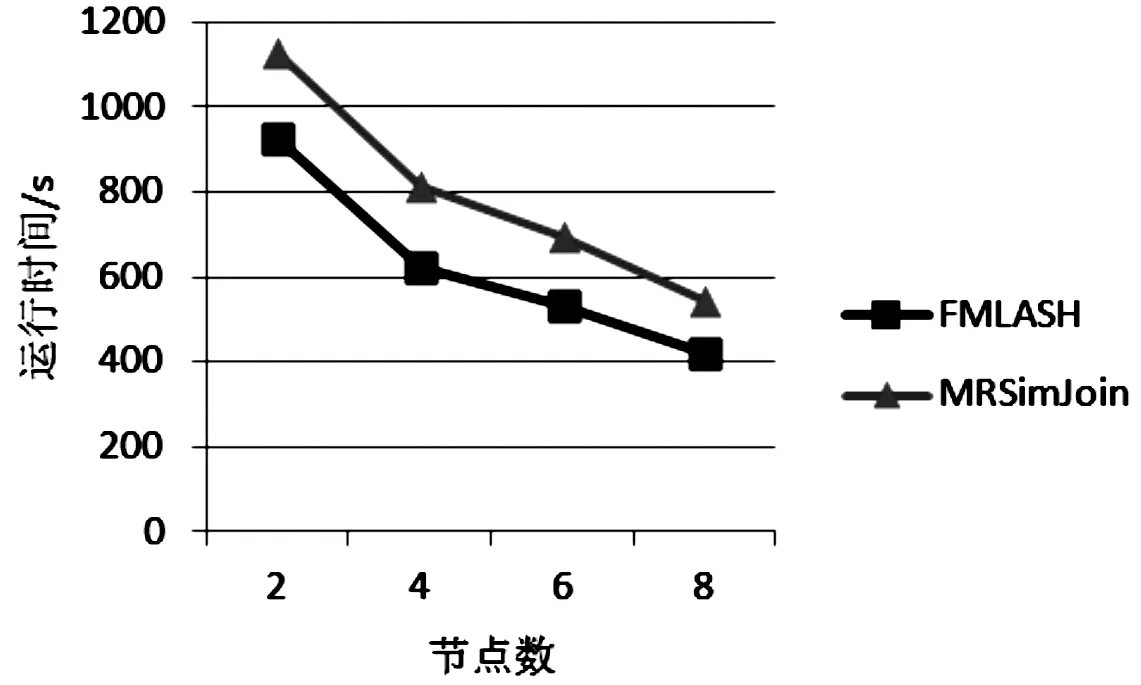
图3 节点数与运行时间
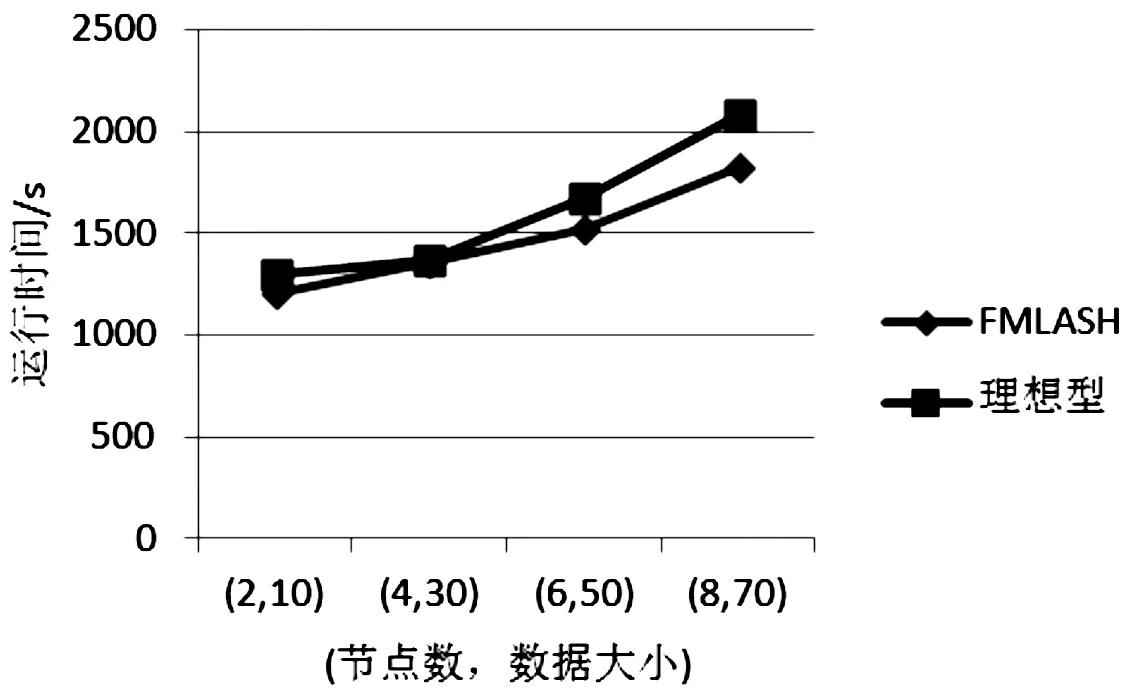
图4 (数据大小,节点数)与运行时间
由图3可知:随着节点数的增加,算法的运行时间都呈下降趋势。因为随着节点数的增多,单个节点负载虽降低,但集群的整体计算能力增加。由于MRSimJoin算法的主要思想是对数据进行划分,而FMLASH算法直接对数据进行处理,所以后者的运行时间明显少于前者。
(3)第三组实验,由于Hadoop具有强大的并行处理能力,希望算法可以具有高效的扩展性,即同步增加节点数和数据集时,算法的运行时间不会受到影响。算法的可扩展性如图4所示,横坐标表示数据集大小和节点数,纵坐标表示运行时间。
由图4可知:理想情况下,当数据集与节点数同步增加时,运行消耗时间基本不变;当节点数不变而数据集增大时,运行时间增加。但实际结果是数据集与节点数同步增加时,运行时间也增加,只是增加幅度不明显;当节点数不变而数据集增大时,运行时间增加的速度比理想型慢。
3 结论
海量数据条件下集合的模糊匹配度关联技术虽然已经取得了一些创新性成果,但是尚有很多问题有待进一步研究:
(1)在线实时的海量关联技术。Hadoop平台因为其简单、易用以及其容错性,经常用于解决海量数据条件下的模糊匹配度关联问题。但另一方面,Hadoop平台属于一种批处理模型,对于需要实时处理的问题并不适用。所以,如何在线实时对海量数据进行模糊匹配度关联有待进一步研究。
(2)支持多种数据类型的海量数据关联技术。本文算法主要针对集合数据,另外相关的研究也主要集中在字符串和向量数据类型。但在现实生活中还有很多其他数据类型,如XML文档、图和直方图等,数据类型的差别可能导致现有的模糊匹配度关联算法并不适用于这些新型数据,如何对现有的算法进行扩展从而支持这些新型数据也需要进一步研究。
