基于卷积神经网络的钣金件表面缺陷分类识别方法
2020-06-29
(四川大学 机械工程学院,成都 610065)
0 引言
零件表面缺陷检测是制造业的热门课题,亦是重大难题。针对国防军工、电子信息等领域对多批次、小批量钣金零件快速制造的需求,进行钣金件智能化表面缺陷检测识别的关键技术研究具有重要意义。目前钣金件缺陷检测主要有人工检测和机器智能检测两种。其中人工检测方式存在高成本、低效率且高误检率、高漏检率等一系列问题[1]。该类钣金零件在目前实际生产中多采用人工检测,其缺陷类型及缺陷出现位置均由生产线工人标注出,机器智能检测方法的必要性和迫切性凸显。因此,研究并提出一种针对该类钣金零件的缺陷识别分类方法的意义重大。现存的基于工件表面缺陷智能检测的方法已有很多种:李春[2]等提出了一种基于机器视觉的钣金件缺陷在线检测算法;廖延娜[3]等提出了一种利用激光测距检测表面缺陷长度和深度的方法;M.Win[4]等提出对比度调整的Otsu方法和基于中值的Otsu方法,用于检测表面缺陷;M.S.Sayed[5]等提出使用熵滤波和最小误差阈值的表面缺陷检测算法来识别缺陷。
随着计算机的快速发展以及计算能力的极大提高,深度学习在表面缺陷检测中的运用越来越广泛[6]。其中,姚明海[7]等提出来一种基于深度主动学习的磁片表面缺陷检测方法;王理顺[1]等提出了一种基于深度学习的织物缺陷在线检测算法;毛欣翔[8]等提出了一种基于深度学习的连铸板坯表面缺陷检测系统。本研究也运用深度学习中卷积神经网络[9]的知识,提出了一种基于卷积神经网络的钣金件表面缺陷检测的方法,通过卷积神经网络搭建了一个准确率高、时间复杂度[10]低的缺陷分类模型,经过多项参数优化后,以批量测试的方式使用窗口滑移检测方法进行缺陷分类预测并确定缺陷位置。
1 卷积神经网络
卷积神经网络属于深度学习的范畴,其作为一种多层前反馈的人工神经网络,可用来处理二维输入数据。该网络含有多个层,每一层都是由多个二维平面组成,而每一个平面又是由多个独立的神经元[11]组成。其网格结构的网络与大脑神经元的连接相似,层与层的神经元互相连接,同一层的神经元之间没有连接。
本研究中的网络模型为自建的卷积神经网络模型。综合考虑工业生产实时性的要求以及模型的准确合理性的要求,建立的网络模型如图1所示。该网络是由1个图像输入层、2个卷积层、2个最大池化层、2个全连接层和1个输出层组成。

图1 网络模型
图像输入层设置的输入图像大小为80×80×3。卷积层通过卷积操作能提取出输入图像的不同特征,为之后的分类识别做铺垫。本文使用的卷积核为5×5×25,步长为1,padding=‘same’,搭配的激活函数为ReLU[12]。卷积操作过程如式(1)所示,得到输出的结果为80×80×25的图像数据。
(1)
式中,n为卷积核的大小;w为权值,其能将激活函数ReLU上得到的函数值线性映射到另一个维度空间上;b为偏置值,其允许激活函数向左或向右移位,该值很大程度上决定了学习的成功与否;x为对应位置的像素值;y为对应的输出值。将上述式(1)中的输出值y输入激活函数ReLU中,如式(2)所示:
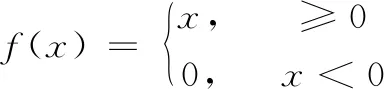
(2)
式中,f(x)为图像对应的像素点的值。
池化层[13]将输入数据划分为矩形池区域并计算每个区域的最大值来执行下采样。该层紧跟在卷积层后,以卷积和激活后的图像数据作为输入数据。本研究使用最大池化层,其卷积核为2×2,步长为2。池化后可得40×40×25的图像数据,并执行归一化操作,该操作能提高学习训练的准确度。全连接层是由许多神经元组合形成的平面二维结构,单个数据均为1×1×3。在卷积神经网络中,全连接层能整合之前几层操作中所有具有类别区分性的局部信息,并将其映射到标本标记空间中。
卷积神经网络的输出层由Softmax和Class组成。Softmax函数的身影几乎出现在所有人工神经网络中,其具有分类和寻址两种用途。而该函数在人工智能领域中最为广泛的应用就是分类。具体方式为:在人为给定一系列分类标签后,Softmax可以给出输入图像数据被划分到各个标签中的概率分布。其计算过程如式(3)所示:
(3)
式中,Ii为输出结果为第i类标签的概率,xi为第i个节点的输出值,n为划分的标签个数。而Class层用于计算具有多标签分类问题的交叉熵损失(Cross Entropy Loss),该层可根据前一层输出数据大小判断出分类的数量。交叉熵表示的是实际输出与期望输出的距离,其式(4)如下:
(4)
式中,yi为标签i的真值。若i为正确的标签时,yi等于1;否则yi等于0。
2 样本数据处理
针对实验对象是少样本的钣金零件,并根据该类型钣金零件缺陷特性和出现原因,本研究重点检测最主要的两种缺陷:磕碰缺陷和划痕缺陷。本文首先提出两个问题:第一,由于一个钣金零件上可能同时出现两类缺陷,并存在多个缺陷在同一零件上的相对位置较为接近的情况,识别与分类的难度增大;第二,样本数据较少,如果以整个零件或一个缺陷作为单个样本集,则训练集过少,无法训练出有意义的参数,建立的模型效果也不好,也就是所谓的欠拟合[6]。
2.1 缺陷分割提取样本
本研究分析了上述问题后,得出以下结论:第一,同类型的缺陷面积大小不一、长度不同;第二,不同类型的缺陷辨识度相对较高。因样本数据的提取方式决定了后续检测方法是否有效,本研究提出了一种缺陷分割提取样本的方法。该方法可分两个步骤进行(为方便展示,本文对所有样本图进行了灰度处理。):
1)将面积小、长度短的缺陷作为单个样本提取。通过改变该缺陷的相对位置的方式截取形成多张样本图。如图2、图3所示,不同的样本图中,同一个缺陷位于不同的位置,以此提高泛化能力。

图2 单个短划痕缺陷
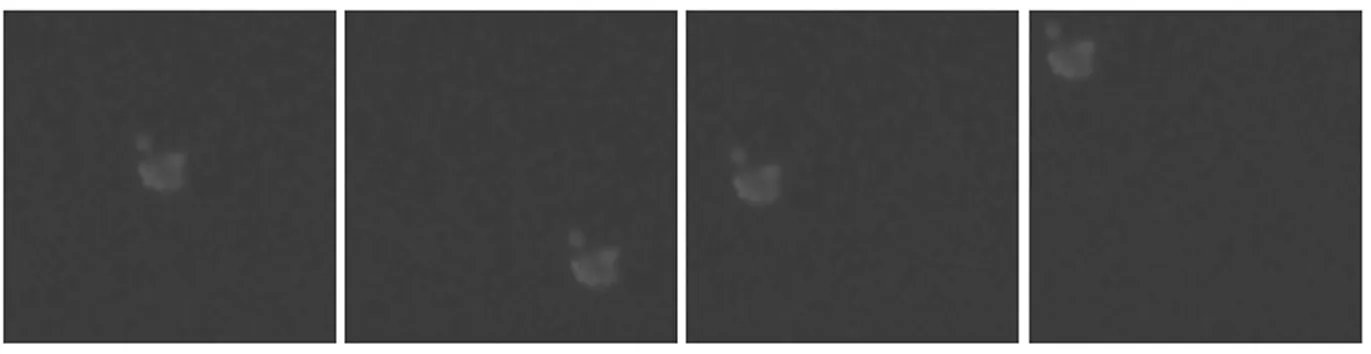
图3 单个小磕碰缺陷
2)将面积大、长度长的缺陷进行分割,可形成多个缺陷分块,并使用步骤(1)中的方式改变缺陷块相对位置,使一个缺陷分块再形成多张样本图,如图4、图5所示。因面积大、长度长的缺陷往往无法在单张大小为80×80的样本图上完整表达,需将其分割形成多个面积小、长度短的缺陷分块;为提高泛化能力的同时又与下文所提及的窗口滑移检测方法契合,截取多张上述缺陷分块位于样本图不同位置的图像作为额外的样本图。

图4 长划痕缺陷分割成多个缺陷分块

图5 大磕碰缺陷分割成多个缺陷分块
该方法能较好地提升数据集的容量,并有效区分缺陷类型。其中,因同类型缺陷分割提取后得到的缺陷分块作为该缺陷的一部分,其对于同缺陷类型的其他缺陷分块具有辅助识别作用。例如,图6为两个不同的磕碰缺陷分割提取后的两张缺陷分块样本图。可以看出,来自两个不同磕碰缺陷的缺陷分块样本图相似性较高。

图6 两个缺陷块的相似对比
2.2 样本数据增强
训练样本规模越大,分类效果就越好[7]。因此,大量的有利数据是必不可少的。本研究的所有缺陷图像均由工业相机高清拍摄获取,并通过相应预处理操作得到卷积神经网络输入层所需要的80×80×3的缺陷样本集。在原有样本数量不多的情况下,需对数据量进行扩充。在样本集中,部分缺陷的面积相对较小,或缺陷位于样本图的角落或边缘位置,若采用缩放和随机遮挡的数据增强方式很可能导致某些缺陷数据的损失。为保证模型的准确度,最终采用适当范围的随机亮度变化、随机左右翻转、随机旋转90°倍数角度的数据增强方式。部分数据增强的效果如图7所示。

图7 数据增强效果
3 窗口滑移检测方法
窗口滑移检测方法的原理是:利用与样本尺寸相同的窗口在待检测零件图像上按从左往右、从上到下的规律遍历滑移;在滑移过程中从零件图像上截取出同样尺寸的区域块,与学习模型进行对比,确定该区域块是否有缺陷,若有缺陷则用外接矩形框出并注明缺陷类型。窗口滑移检测方法具体将进行以下两个步骤:
1)使用大小为80×80的窗口,并以该窗口1/2边长的距离为单次横向滑移量Hx(Sliding Distance)从图像左上角向右滑移,每滑移一个位置就截取一个像素大小为80×80的区域块。当窗口滑移到最右端后,该窗口立即回到图像最左端,并同样以窗口1/2边长的距离为单次纵向滑移量Hy向下滑移一次后再次向右滑移,直到该窗口遍历完整个待检测图像。窗口滑移示意图如图8所示。窗口每滑移一次便将截取的区域块与训练模型对比,并把该区域块的标签值存入位置矩阵M的相应位置。因待检测图像大小为560×960,窗口大小为80×80,选择单次滑移量为1/2窗口边长,总共可得到13×23个区域块和大小为13×23的位置矩阵M。
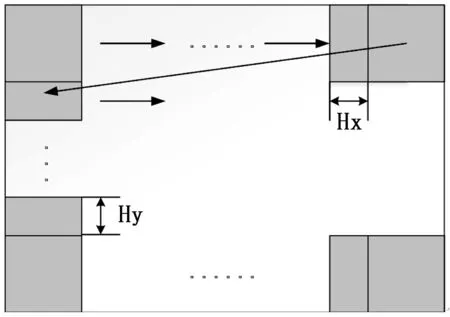
图8 窗口滑移示意图
2)本模型中共有磕碰缺陷、划痕缺陷、无缺陷3种标签,在位置矩阵中分别用数字1、2、3代替。因存在一个缺陷被分割在多个相邻的区域块中的情况,为标记出缺陷的位置并外接带标签的矩形框,需要使用图像处理中连通域原理的算法。在Matlab软件中,算法的具体流程为(以划痕缺陷为例):将13×23的位置矩阵M中代表划痕缺陷的数字2置为1,其他数字置为0,形成只存在0和1的13×23的二值矩阵(该矩阵可表示二值图像);利用连通域regionprops函数,可在位置矩阵M中得到数字1的个数与位置;利用矩阵映射原理可得到零件图像矩阵中缺陷的对应位置并用矩形框标注出。该方法的部分效果展示如图9所示。
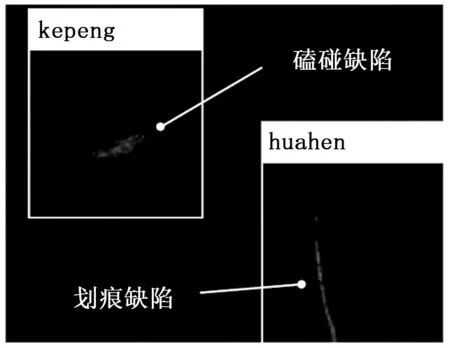
图9 部分效果展示
4 实验及分析
4.1 实验环境
本研究共获取缺陷数据集1 917张,其中磕碰缺陷图683张,划痕缺陷图731张,无缺陷图503张。将该数据集按4∶1的比例随机划分为训练集和测试集。得到的实验数据将用于验证114张大小均为560×960的折弯钣金零件,并统计缺陷识别和分类的结果。本实验环境为Windows10操作系统,Intel Core i7-7700KCPU,16GB内存,NVIDIA GeForce GTX 1060显卡,并使用Matlab软件的深度学习工具箱进行模型训练及调试。
4.2 训练参数的选择
在训练方法上,本研究采用随机梯度下降[14](stochastic gradient descent,SGD)的方式进行采样,该方式是在梯度下降最快的方向上随机选一个数据进行计算,而不是扫描全部训练数据集,有助于提高迭代速度。因学习率控制着参数更新速度,学习率的选择至关重要。学习率过大,将导致损失函数在极小值附近来回变化,无法收敛;学习率过小,会使学习速度变慢。在满足准确率的条件下,为尽可能缩短学习时间,本实验分别设置学习率为0.01、0.001、0.000 1进行训练,获得的准确率对比如图10所示。由数据表明,当学习率为0.000 1时,准确率可达97.02%,且曲线较为平滑,能达到分类模型的准确率要求。
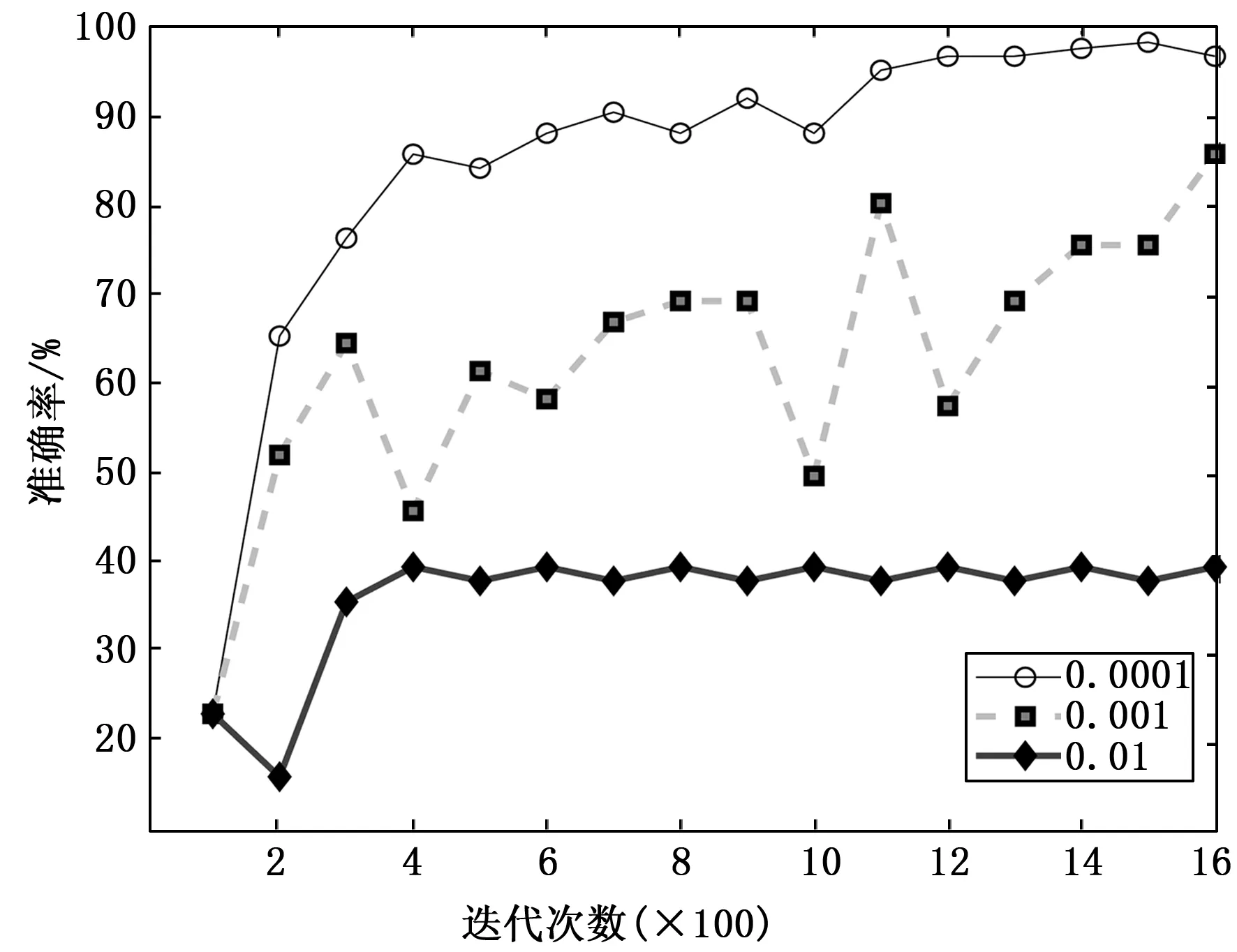
图10 不同学习率的准确率对比
4.3 验证参数的选择
该类钣金零件缺陷检测在实际工业生产中要求准确率应大于95%,平均单件检测时间应小于1 s。根据窗口遍历检测方法的原理,滑移量的大小将直接影响缺陷检测的准确率和检测时间。为获取最优的滑移量,本研究分别选用窗口的1/4边长、1/2边长、3/4边长、边长的滑移量作为四组实验参数,并用于验证114张大小均为560×960的钣金件零件图。该批零件存在磕碰缺陷125处、划痕缺陷154处,共计279处。如表1所示为不同滑移量的实验结果对比。结果表明,滑移量大小为1/4边长的实验尽管检测并标注了所有缺陷,却有28处误检、且耗时较长;滑移量大小为3/4边长的实验出现8处漏检、13处误检;滑移量大小为边长的实验尽管耗时最少,却出现16处漏检、7处误检;而滑移量为1/2边长的实验结果最佳,仅2处漏检、6处误检且耗时满足工业要求。
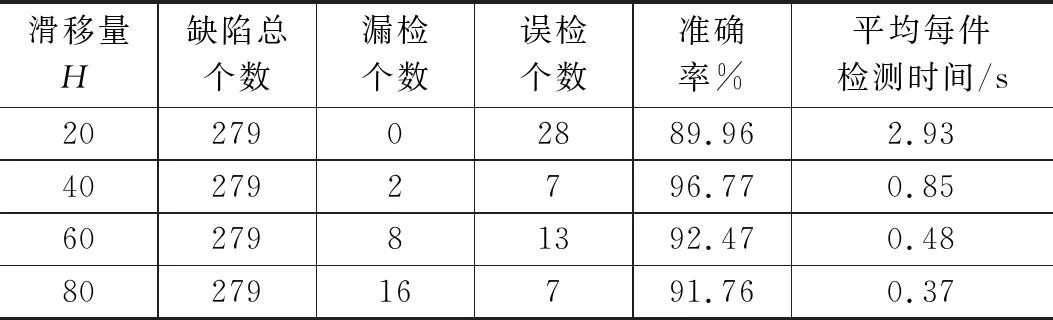
表1 不同滑移量的实验结果对比
实验结果分析:检测结果为误检的原因是存在一个图像块中同时出现两个或多个缺陷,尽管模型能将其识别为缺陷,却无法进行正确分类;检测结果为漏检的原因是存在一个缺陷的面积过小或长度过短,且恰被分割在两个相邻图像块的共同边或4个相邻图像块的交点处,使该缺陷样本与无缺陷样本相似,导致训练模型无法正确分类。
5 结束语
针对样本较少的钣金零件表面缺陷的检测问题,本研究提出了基于卷积神经网络的钣金件表面缺陷识别分类方法。通过缺陷分割提取的方式获取了缺陷样本,对样本和训练模型进行了分析,并多次调试训练参数,获得了准确率为97.02%的神经网络分类模型,该模型具有准确率高、时间复杂度低、泛化能力强等优点。为达到分类缺陷并标注缺陷位置的目的,本研究使用了窗口滑移检测方法,通过窗口滑移遍历整个待检测图像,截取窗口大小的区域块与模型对比,验证该方法得到了96.77%的准确率和0.85 s的平均每件检测时间。实验表明,该方法具有识别准确率高、
识别时间满足工业要求的优点。但对于实验结果中存在的缺陷漏检和误检,暂无法从原理上得到改进。在未来的研究中还可以在方法原理上进一步优化,提高识别运算速度,减小误检率、漏检率。
