基于迁移学习的可回收生活垃圾图像分类识别研究
2020-06-28郑誉煌戴冰燕熊泽珲陈钊
郑誉煌, 戴冰燕, 熊泽珲, 陈钊
(1. 广东第二师范学院 教务处, 广东 广州 510303;2. 广东第二师范学院 物理与信息工程系, 广东 广州 510303)
0 引言
据世界银行2018年发布的《垃圾何其多2.0》报告显示,全球垃圾2016年大约为20亿吨,到2050年将增至34亿吨,而现在1/3的固体垃圾被公开倾倒或焚烧,垃圾回收处理有着巨大的生态收益. 生活垃圾包括人们在日常生活或为生活提供服务的活动中产生的固体废物. 生活垃圾中的可回收垃圾包括金属、纸类、塑料、玻璃等,占城市生活垃圾40%,是可回收垃圾的主要部分.
可回收垃圾的循环利用对我国经济的可持续发展有着重要意义. 当前的垃圾回收需要人们手动分类垃圾,找到一种自动分类垃圾的方法,提高垃圾回收的效率,不仅会产生显著的社会效益,而且有巨大的经济效益. 为了提高可回收生活垃圾识别的准确率,研究人员尝试利用图像处理、机器学习等方法自动识别玻璃瓶、废纸、纸盒、易拉罐等常见生活废品. 利用图像处理技术获取垃圾图像的特征后,再利用深度学习网络[1]、支持向量机、K 近邻分类器[2]、主成分分析(PCA )方法[3]等方法对垃圾图像特征向量进行分类.
现有基于机器学习的可回收生活垃圾识别,核心是采用卷积神经网络(Convolutional Neural Network,CNN)引入局部连接、权值共享、池化操作、非线性激活等方法,允许网络从数据中自动学习特征,比传统机器学习方法具有更强大的特征学习和特征表达能力. 如YOLO[1]、MobileNet[4]、AlexNet[5]、VGG19[6]、ResNet50[7]等,在相应的数据集领域有较好的效果. 但在可回收生活垃圾图像数据集上,这些深度卷积神经网络模型存在训练耗时长、准确率不高等问题. 为此本文利用迁移学习方法,将ResNet18预训练模型在ImageNet大型图像数据集上学习得到的图像分类共性知识,迁移到可回收生活垃圾图像识别模型中,通过组合试验与对比,分析优选模型的参数,以期提高新分类模型的训练效率与识别准确率,为进一步开发智能垃圾分类系统等机器提供分类模型支持.
1 实验数据集
本研究的图像数据集以Gary Thung和Mindy Yang[5]创建的垃圾图像数据集为基础,该数据集由1 989张图片组成,分为玻璃、纸张、塑料、金属、纸皮5个类别,所有图片的大小调整到512×84. 由于数据集的图像数量较少,从Kaggle网站中的waste_pictures数据集中抽取2 485张相同类型的图像,最终形成4 474张图片的实验数据集. 每个类别的样图如图1所示. 这些图像能较好表达生活垃圾被回收时的状态,例如变形的瓶子、皱褶的纸张等. 每类大约有500~900张图像,每张照片的灯光和姿势都不一样,每个图像都执行了图像增强技术. 这些技术包括图像的随机旋转、随机亮度控制、随机平移、随机缩放和随机剪切. 选择变换的图像是为了考虑回收材料的不同方向,并最大化数据集的规模.

a.纸皮b.玻璃c.废纸d.易拉罐e.塑料瓶
图1 数据集中拉圾类别的样图
2 迁移学习
迁移学习(Transfer Learning)的概念[8]自1995年在NIPS5专题讨论会上被提出后,受到学术界的广泛关注. 考虑到大部分数据或任务存在相关性,通过迁移学习,可以将训练好的模型参数通过某种方式分享给新模型,从而提高并优化模型的学习效率. 本研究基于ResNet18模型进行迁移学习,ResNet18模型在大型图像数据集ImageNet 上获得了充分训练,学习了图像分类识别所需的大量特征,可用于可回收生活垃圾分类识别问题. 采用基于ImageNet数据集的ResNet18预训练模型,就不用重新训练可回收生活垃圾分类的实验数据集,只要把ResNet18预训练模型迁移到实验数据集,即可获取相同的效果,保证识别的精度,提高训练速度.
2.1 ResNet18模型结构
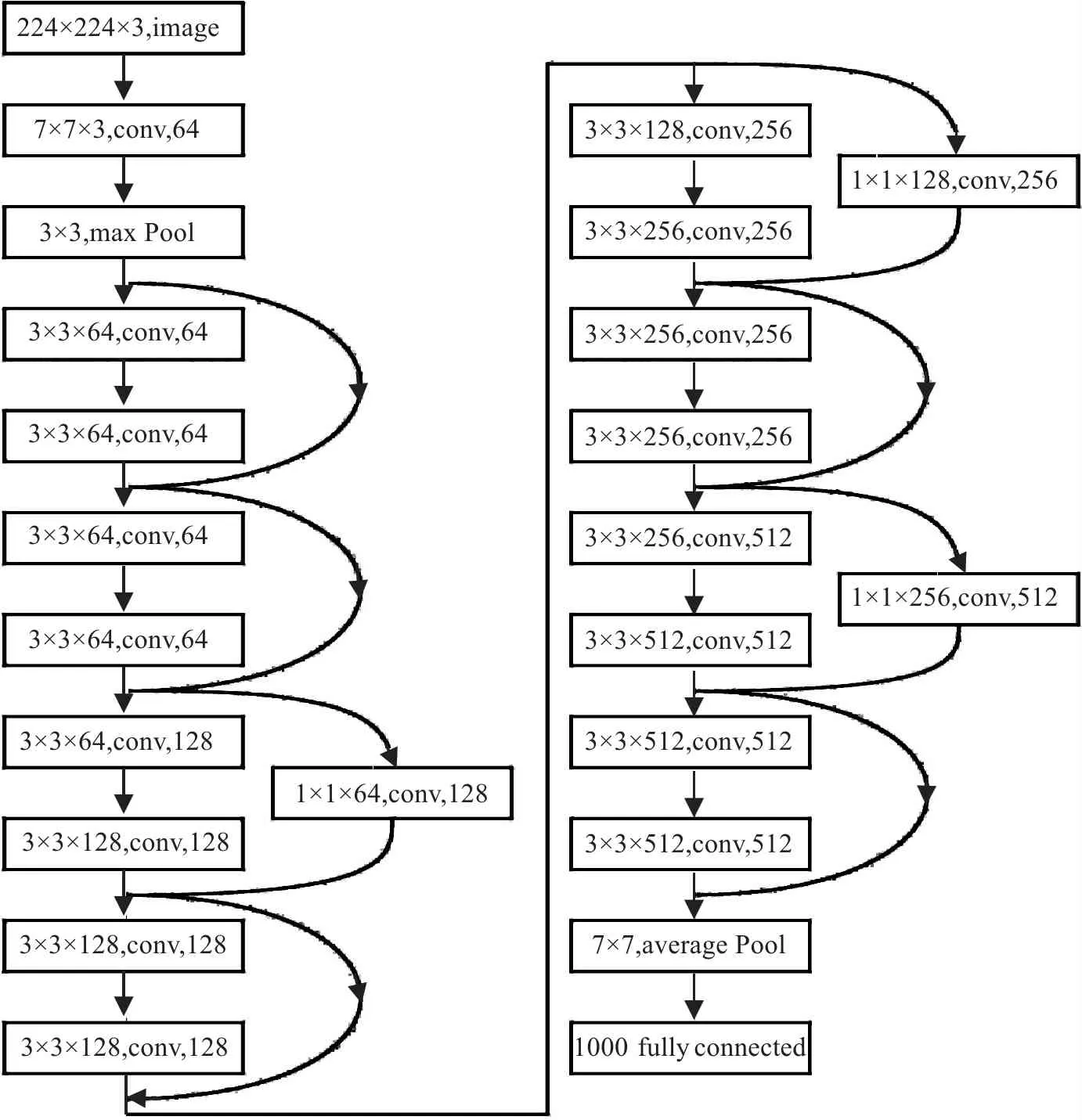
图2 ResNet18模型结构
2.2 迁移学习模型
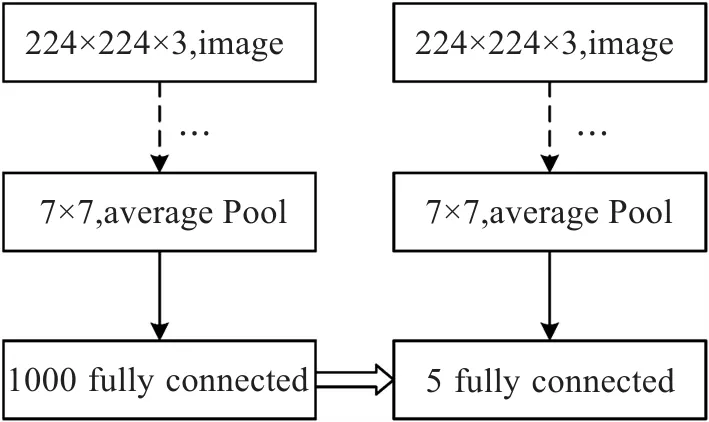
图3 迁移学习模型
3 结果与分析
模型训练与测试均是在Matlab 2019a的深度学习框架下完成的. 硬件环境:Intel i7-8750H @2.20GHz CPU,32GB内存;Nvidia RTX2070 GPU,8GB 显存. 软件环境:CUDA Toolkit 9.0,CUDNN V7.0;Matlab Deep Learning Toolbox;Windows 10 64bit 操作系统. 模型训练与测试均通过GPU 加速. 对于迁移学习模型训练,主要有Epoch、Batch Size和Learning Rate参数.
1)Epoch:一个Epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程,随着Epoch数量的增加,神经网络中权重更新迭代的次数增多.
2)Batch Size:Batch是每次送入网络中训练的一部分数据,而Batch Size就是每个Batch中训练图片样本的数量. 为了在内存效率和内存容量之间寻求最佳平衡,Batch Size应该进行精心设置,优化网络模型的性能及速度.
3)Learning Rate:是深度学习中重要的参数,其决定着训练样本的识别精度,合适的Learning Rate能够使训练样本的识别精度在合适的时间内达到一个理想值.
随机把可回收生活垃圾数据集中每一类别图片的70%分为训练集、另外30%作为测试集. 上述3个参数分别取3个不同值时,共完成27次实验,每次实验中训练模型的耗时和模型的测试精度如表1所示. 为了综合评价每种参数组合的效果,对精度和耗时做归一化处理,作为精度和耗时的得分,将精度得分和耗时得分分别按0.6和0.4加权平均,可得综合得分. 根据综合得分,可见Epoch、Batch Size和Learning Rate参数组合分别取(5,32,10-3)和(10,32,10-3)时,迁移学习效果最好.
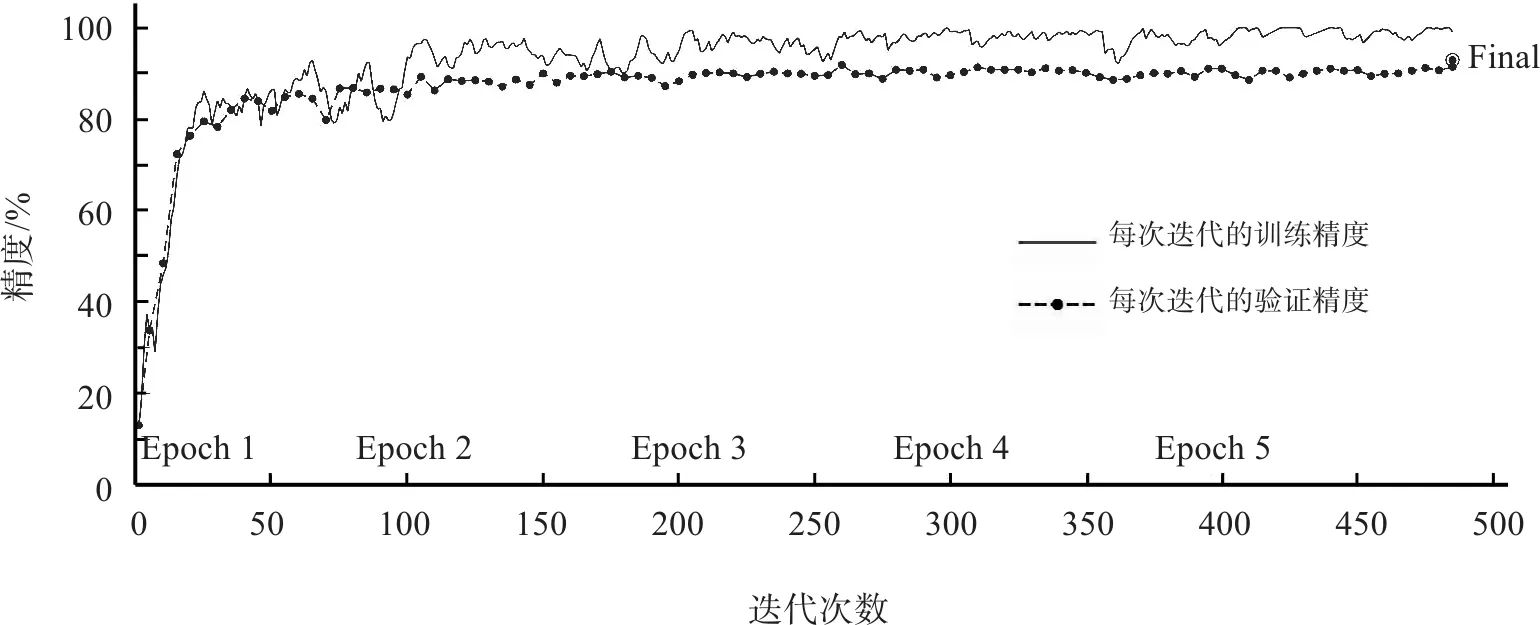
考虑到训练过程中可能存在的随机误差,对(5,32,10-3)和(10,32,10-3)这两个组合,再重复进行4次实验,可得表2的实验数据. 可见这两个参数组合所得的迁移模型精度比较接近,但(5,32,10-3)组合的训练耗时比(10,32,10-3)组合少得多. 图4和图5是两个组合训练时的过程曲线. 可见,在Batch Size和Learning Rate取得合适的值时,Epoch的增加可以提高一定的精度,但是训练耗时会增加很多. 图中迭代次数是由训练集数量和Batch Size相除取整而得.
由于(10,32,10-3) 组合精度较高,而且比较稳定,训练耗时适中,因该对此组合的模型分类结果作进一步分析,形成如表3所示的混淆矩阵.
由表3 的混淆矩阵可知,模型的平均分类准确率为93.76%,预测准确率从高到低依次是纸皮、废纸、塑料瓶、玻璃、易拉罐. 由混淆矩阵可以看出,分类错误主要为玻璃、易拉罐和塑料瓶之间的误判. 由于玻璃外观和塑料比较接近,易拉罐表面有金属反光,在特定的视角有可能被误判. 纸皮和废纸的识别准确率较高,出现错误也主要是对两者直接的相互误判.
针对文献[5]的数据集,文献[5]和[7]所提出分类方法识别准确率分别是63%和87%;采用本文基于文献[5]扩展数据集,文献[5]和[7]的分类方法识别准确率分别是85.9%和92.12%,都小于本文所提出的分类模型精度(93.37%).
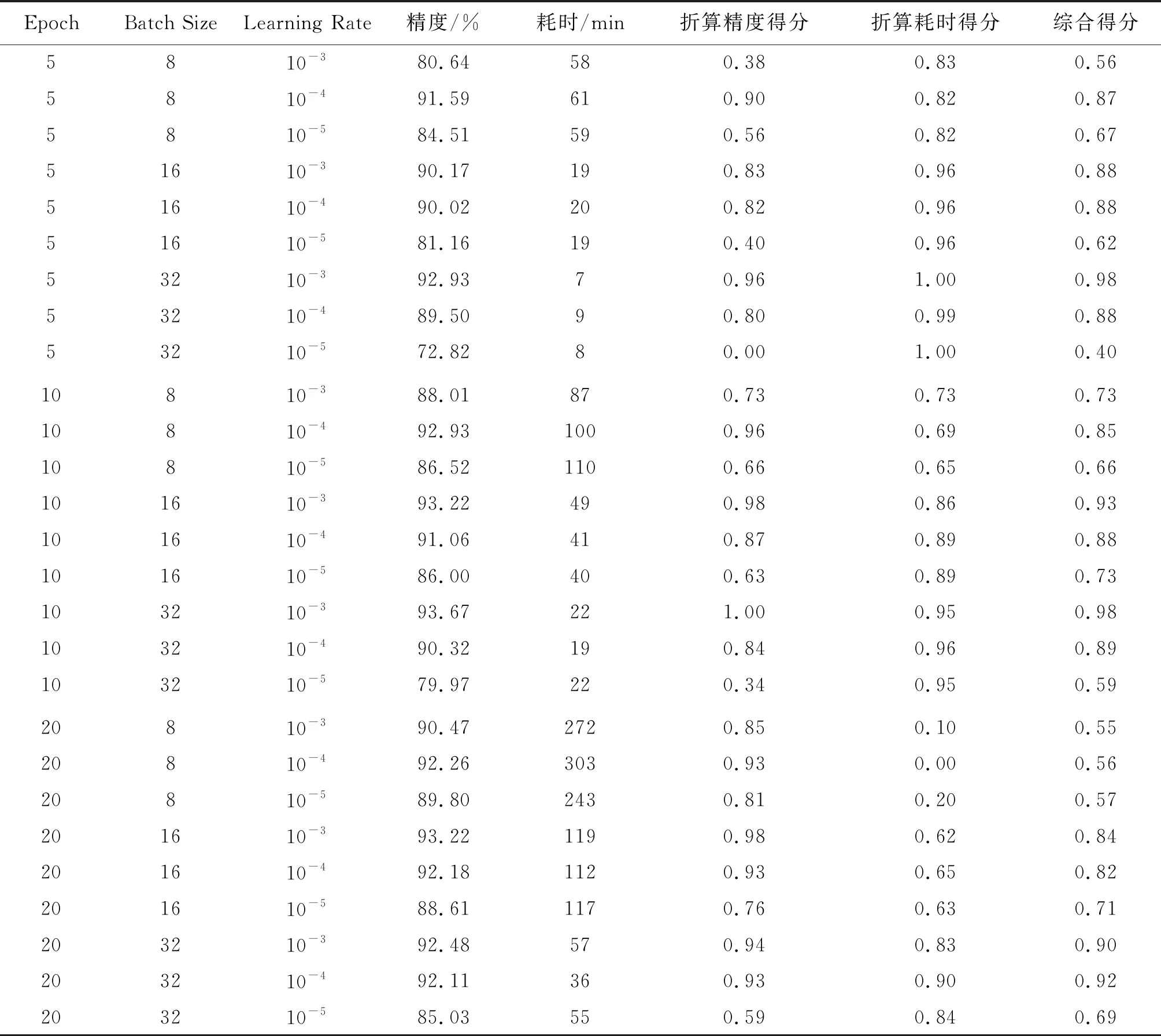
表1 实验数据
精度/%100806040200100150200250300350400450500050Epoch1迭代次数Epoch2Epoch3Epoch4Epoch5每次迭代的训练精度每次迭代的验证精度Final
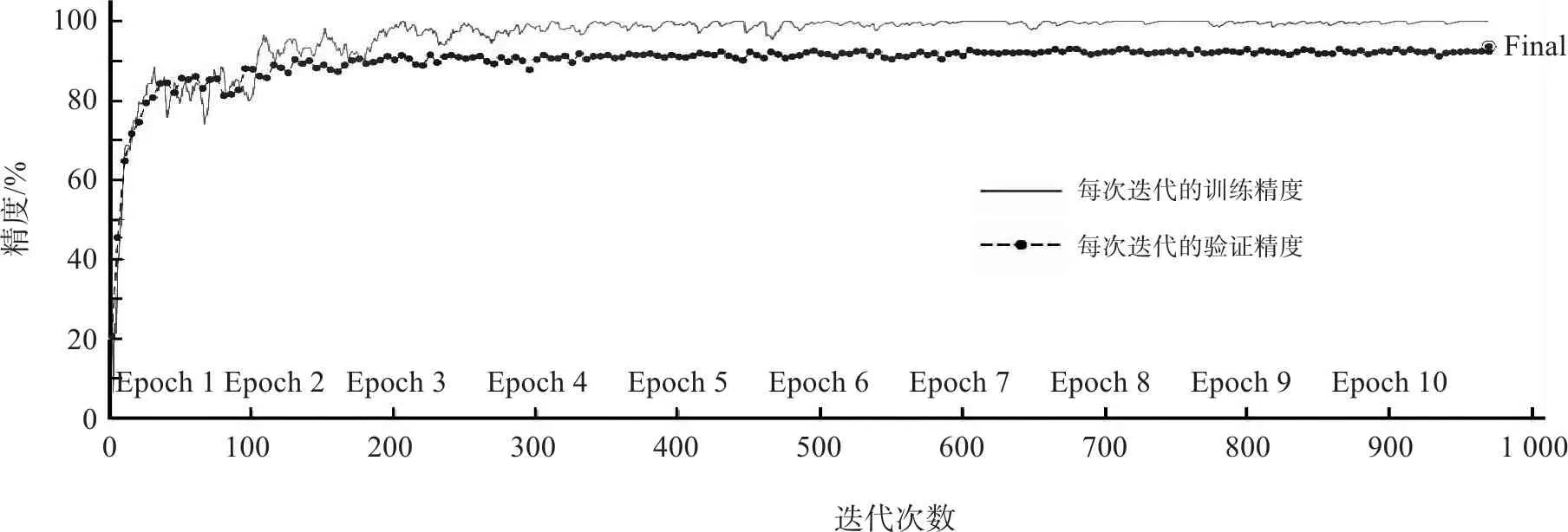
图4 (5,32,10-3)组合训练过程
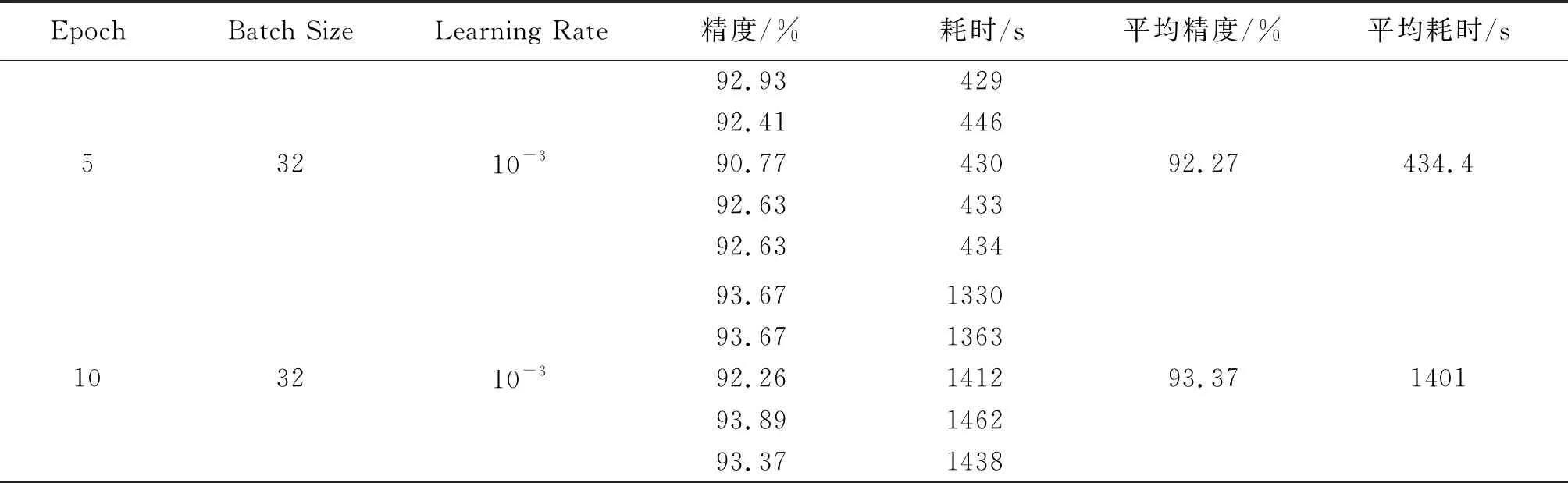
图5 (5,32,10-3)组合训练过程
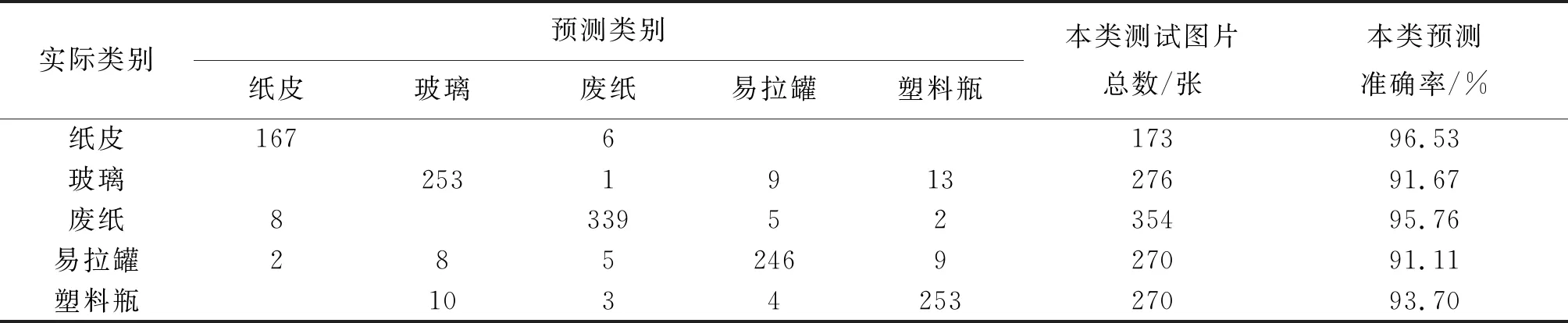
表3 混淆矩阵
4 结论
针对现有的可回收垃圾分类识别方法存在的识别精度不高的问题,本文利用迁移学习方法调整了ResNet18预训练模型的网络结构和参数,并对可回收垃圾图像识别进行了分类实验,对Epoch、Batch Size和Learning Rate参数对模型性能的影响进行了对比分析,得到如下结论:
1)被迁移学习调整后的ResNet18预训练模型,可以较好地自动提取可回收垃圾图像特征,具有较高的分类性能,平均识别准确率达到93.37%.
2)迁移学习可以充分利用在大型ImageNet数据集上学习已得到的分类知识,在保证不少于90%的识别准确率的条件下,训练时间小于10 min.
3)Epoch、Batch Size和Learning Rate参数取(5,32,10-3)和(10,32,10-3)组合时,可取得比较好的训练效果.
目前的模型局限于背景简单的可回收垃圾图像,实际应用可能是多种垃圾混合在一起. 今后应进一步丰富可回收垃圾图像数据集,建立混合垃圾图像的分类与识别模型,以进一步提升可回收垃圾图像模型的识别准确率.
