英语文学语料库中实用语言统计法研究
2020-06-27禹琳琳


摘 要:随着语料库在语言研究中的地位越来越重要,WordSmith、Antconc、Editplus等检索工具对文本信息和语言特点的检索分析也更多的使用在信息查询、实际教学、词典编写和翻译领域中。通过在软件中语料检索、词表和主题词表的生成,可以提取一定数量的句子或结构,通过一系列的统计分析可以对检索结果的真正意义加以说明。本文针对语料库分析中常用的频数标准化和卡方检验来解决日常生活中的实际问题,借此来深入研究语料库样本的出现和分布情况以及某种语言项目在文本间表现出来的差异性。
关键词:语料库分析;统计方法;频数标准化;卡方检验
引言
语料库不仅能进行快速准确的分析,同时具有规模大,语域宽和范围广的特点,“既有定量分析,又有定性解释功能,对语言的描写比较全面”(王克非等,2004:4-5)。语料库的这些特点要求我们要采取不同的统计方法来对不同语料进行分析,比如采集样本的分布情况、不同项目在一定语境下的共现概率以及不同变量间的差异性分析。频数标准化及频数差异检验统计法是最常用的语料库语料分析法,但因其定义和应用过于程式化,造成不少研究者在语言项目的分析中对其采取回避的态度,如何采取浅显实用的方法来验证这两种统计方法的有效性将是本文的重点,从而对运用于语料库的统计方法进行实际验证。
一、解析频数标准化
何为“标准化”?为什么在统计分析中使用标准化?我们以WordSmith软件中词表功能提取的标准化类符形符比为例。我们知道,形符数指语篇有多少个词,类符数指语篇有多少个不同的词,用它们的比率我们来判断语料用词的多样性,而标准化类符形符比(standardized TTR)是按一定长度,通常是1000词,分批计算文本的类符形符比,然后求平均值。主要在文本长度不一,词汇密度不均匀的情况下,标准化的比值能更准确的反应不同文本用词的多样性(刘泽权,2010:65)。又如,我们通过语料检索和词表生成后会报告频数,以检索单词“and”为例,and在第一个语料库中出现50次,在第二个语料库中出现89次,我们能得出结论说and在第二个语料库中更常用么?显然不能。只有当我们把and在两个语料库中的出现频率归于一个共同基数时,即得到一种标准化的频率时才能准确的反映语言真实的频率情况。
标准化频率的公式表示为:
上述公式里观测频数即是检索结果实际出现的次数,总体频数则是语料库中总字数。有数据表明:“good”在学生的作业中出现362次,而且欧洲国家母语口语语料中出现568次。两个语料库大小分别为48566次和252468次,我们利用Excel或SPSS工具可直接得出标准化频率即每千次使用“good”为7.45次和2.25次。如图1:
二、解析频数差异检验
频数标准化可以通过共同的基数(如1000)来对不同频数加以比较,但在复杂的语料库统计中,我们要参与比较的数据之间是否有显著性也是我们要重点考察的内容,本文我们将重点放在卡方检验这个方法来检验频数之间的差异性。卡方检验的名称来源于英文Chi-Square Test,在統计学的大数据运行中,多用在证明某个变量和应变量间是否有显著关系。简单来讲,卡方检验就是为了测试两个挑选的变量间有没有关系。
我们生活中有很多具有两面的物体,如扑克牌,硬币等,我们拿扑克牌来做个试验。现在我们手上有一张正常的扑克牌,我们随意丢50次,按照我们的经验来看,最理想的情况会是25个正面,25个反面。但实际操作中发现很难达到这样理想的效果,正常23个正面,27个反面或者24个正面,26个反面,28个正面,22个反面也是可能的,但40个正面,10个反面就是非常低的概率了。我们通过以上的分析和推断,等于是拿已经确定的结果(扑克是没人动过手脚,它是均衡的)来推断会出现的不同现象的次数。而我们要论证的卡方检验恰恰相反,它是用实际看到的现象(例如正面或反面的次数)来判断结果(扑克本身是否是均衡的)。
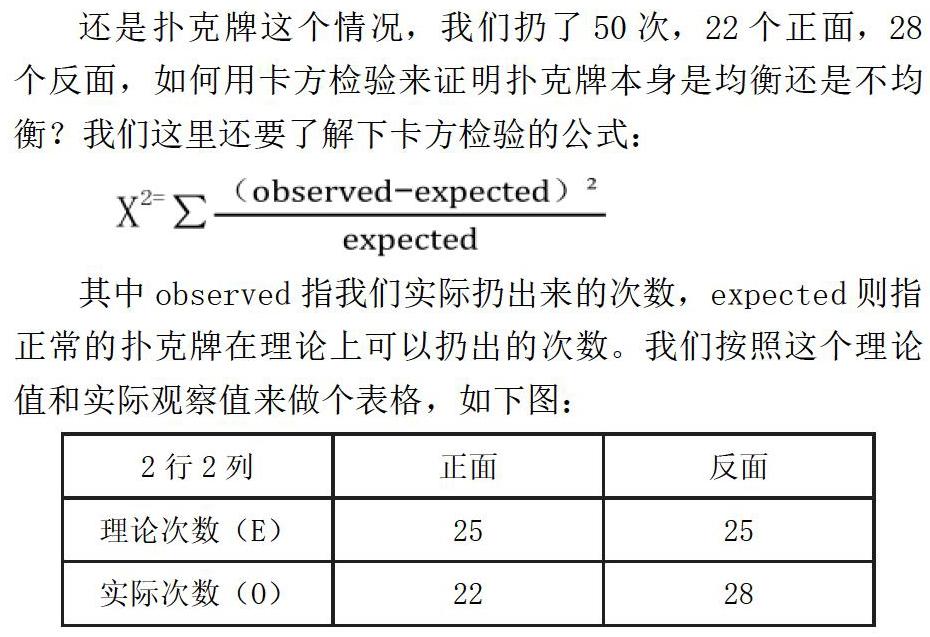
还是扑克牌这个情况,我们扔了50次,22个正面,28个反面,如何用卡方检验来证明扑克牌本身是均衡还是不均衡?我们这里还要了解下卡方检验的公式:
其中observed指我们实际扔出来的次数,expected则指正常的扑克牌在理论上可以扔出的次数。我们按照这个理论值和实际观察值来做个表格,如下图:
代入卡方公式中我们得出第一考察因素卡方值为:
同时第二考察因素自由度我们可以通过公式得出:(行数-1)*(列数-1)=1。
第三考察因素置信度我们则可按照意愿挑选,比如90%或95%,这里我们以95%为例。依据以上三个因素我们来参考卡方实验表格,如下表:
根据自由度1和置信度95%我们从上表查出3.841的数值,此数值大于我们求出的卡方值0.72,所以我们能够得出扑克牌是均衡的结论(置信度为95%)。
扑克牌的卡方检验手段让我们得出牌的本身是均衡的,但生活中的一些物品则未必像我们想象中的一样。我们再拿一个小孩子平时玩的长方体的积木为例,我们把这块随机挑选的积木扔36次,积木的六个面分别掷出来的次数是10次,9次,8次,4次,3次和2次,这里还是需要借助前文用过的表格,如下:
代入卡方公式中我们得出第一考察因素卡方值为:
同时第二考察因素自由度我们可以通过公式得出:(行数-1)*(列数-1)=5。
第三考察因素置信度我们则可按照意愿挑选,比如90%或95%,这里我们以95%为例。依据以上三个因素我们来参考卡方实验表格,如下表:
根据自由度5和置信度95%我们从上表查出11.070的数值,此数值大于我们求出的卡方值9.6,所以我们能够得出这个积木是均衡的结论(置信度为95%)。但当我们把自由度5和置信度90%放在一起考量的时候,从表中我们得出的数值是9.235,是小于卡方值9.6的,这样的话这个积木就不是均衡的(置信度为90%)。所以通过投掷36次的现象我们得出无法判断此积木是否均衡的结论。
三、卡方检验与变量分析
在通过语料库来对搜索结果进行比较和研究时,如果我们选取的某个变量并不显著,我们就可以删除掉这个变量,从而去选取其他显著的变量,但是这个时候一定要搞清楚你判断此变量是否显著所采用的卡方值是多少,置信度选取的多少,只有是显著的变量才能被放入我们做语言研究的模型货或分析中去。
我们上边谈到,通过语料库得出的结论我们是需要进一步统计和分析的,最常见的统计分析就是两个所比较的变量之间到底是否具有显著关系,这将直接决定我们提取的样本是否具有代表性,能否准确代表我们所要研究的目标。
例如,现在社会中网购已经成为极为普遍的现象,各个年龄层都在购物时会考虑到网购,同时各种针对蔬菜水果的公众号或者app都开始推出,那不同性别与在网上买不买蔬菜水果之间有没有显著关系呢?我们对随机采访的不同性别的人群的采购习惯进行统计,具体如下:
根据上表的统计,我们可以计算出66%的人群是不通过网络买菜的(599/907),而剩下的34%则是会在网上购菜,这样的话男性在网络购菜的理论人数就是733*66%=484人,女性的理论购菜人数就是174*66%=115。由此我们得出的理论值表格统计如下:
同时第二考察因素自由度我们可以通过公式得出:(行数-1)*(列数-1)=1。
第三考察因素置信度我们则可按照意愿挑选,这次我们以90%为例。依据以上三个因素我们来参考卡方实验表格,得出不同性别和在网络上购菜是有关系的。
如果用TF-IDF判断选取样本重要性
在语料库的分析统计方法中,我们最常接触到的考察因素就是词频(Term Frequency,缩写为TF),顾名思义,词频就是一个词在文章中重复出现的次数,如果统计出来的词多次出现,那么我们就要考虑这个词在文本中可能起着一定的作用,这种统计方法对我们考量选取的文本样本或关键词样本是否显著作用明显,但在实际对提取的结果做分析时,我们发现统计出来的词频数前几位的都是如“的”,“是”,“在”这样的词,这种词对我们的分析毫无作用,甚至会干扰我们的判断,我们需要利用停用词语料库来过滤掉这种无意思的词语。
当过滤掉所有无意义的词后,文本中剩下的就是有实际意义的词。在所有这些词中,我们会发现有一些词出现的次数一样多,这种结果是不是就说明这些词具有同种重要性?我们举例来说明。比如通过语料库统计,我们得出某文本中,“人民”和“民主制”出现的次数一样多,那么如何来看待这两个词的重要程度?“人民”本身就是很常见的词,相对而言,“民主制”则不那么常见,如果两个词在某文本中出现的词频一样,我们有理由认为,“民主制”的重要程度要大于“人民”,对于研究的重要性上,“人民”很可能反映了所在文本的特性,对于关键词或显著样本的选择上,类似于“民主制”这样的词就会给予较大的权重,这种权重又称为“逆文档频率”(Inverse Document Frequency,缩写为IDF)。IDF和我们之前讨论的TF相乘就得到一个TF-IDF值,这个值越大,就说明所提取的词或样本重要性越高,对我们选取的样本是否显著有重要的参考。
四、文本分类特征选择法
上面我们讨论TF-IDF在有效评估关键词在文本集或者一个语料库中一份文件的重要程度,但在文本分类中单纯用这个TF-IDF数值来判断一个特征是否有区分度是不够的。一方面它没有考虑特征词在类间的分布,也就是说选取的特征应该在某类出现的频率多,在其他类别出现的频率少,即考察各类别文档频率的差异。另一方面没有考虑特征词在类内部文档中的分布情况,如果仅仅出现在几个文档中,而在此类其他文档中不出现,就证明选取的特征词不能够代表这个类特征。我们从文本中往往可观察到的量有两个:词频和文档频率,这两个量是所有统计方法的基础,上述TF-IDF值用于向量空间模型,进行文档相似度计算是有用的,但其选择出来的特征却不具备类别区分度,而此时卡方检验作为最佳特征选择方法的优势就凸显了出来。
我们在列举的实际例子中看到卡方检验最基本的思想是通过观察实际值与理论值的偏差来确定理论的正确性与否,(前文已对卡方检验的实际操作做了具体说明,此处不再赘述。)先假设两个变量是独立的,然后观察理论值和实际值的偏差,如偏差足够小则说明两变量间确实是独立存在的,此时可接受原假设;若偏差大到一定程度,以致于不太可能是偶然产生或测量不精确所致,我们可认为两变量实际是相关的,即否定原假设。在我们对文本分类的特征做出选择时,一般用“词类t和类别c不相干”来做原假设,得出的开方值越大,证明对原假设的偏离越大,则得出原假设的对立面是正确的。
卡方检验对我们在做量变间显著性研究时起了重要作用,但其“低频词缺陷”却只统计文档中是否出现词,并不考虑出现了多少次,在不知不觉中夸大了低频词的作用,最终选择的词并不具有代表性,因为在进行特征选择的时候筛选掉了那些开方数小的词(这些词其实是更具代表性的)。所以我们在进行文档特征选择时要将卡方检验与词频等因素综合考虑,以确保选取样本的代表性。
结论
频率标准化和卡方检验现已具体的运用到大数据运营场景中,对语料库样本选择和变量显著性的特征统计也起到重要作用。在语料库研究逐步向量化发展的趋势下,本文力图通过更为通俗易懂的论证使常用语言统计方法和日常生活更为贴近,将语料库研究方法和我们平时的思维方式联系起来,同时对文本特征的选取方法研究来说明提取结果的真正意义,从而准确描述所得语料库样本的出现和分布情况,对语料库应用中统计方法的深入运用提供新的思路。
参考文献:
[1] 刘泽权.《红楼梦》四个英译本的译者风格初探——基于语料库的统计与分析[J]. 中国翻译,2011(9):3-4.
[2] 韩金龙.语料库间多特征相似性的统计方法研究[J].现代教育技术,2016(8):42-43.
[3] 葛诗利.语料库间词汇差异的统计方法研究[J]. 现代外语, 2010(5):37-39.
[4] 鲁庆云,刘红霞. 关于列联表卡方检验在数学教育研究中的使用方法分析[J].统计与决策, 2008(4):18-19.
[5] 王克非. 双语对应语料库研制与应用[M].北京:外语教学与研究出版社. 2004:45.
[6] 谢益武,郭俊芳,周生宝. 关联规则相关性的度量[J]. 计算机应用,2007(1):12-13.
[7] 陆运清. 用pearsons卡方统计量进行统计检验时应注意的问题[J].统计与决策, 2009(4):19.
[8] 喻国明,李慧娟. 大数据时代传播研究中语料库分析方法的价值[J].传媒, 2014(10):26.
[9] 隋桂岚,孙利望. 语料库、统计学与问题分析[J]. 辽宁工程技术大学学报(社会科学版),2003(4):6-7.
[10] 方称宇,陈小力. 频率统计在语料库中的应用[J]. 现代外语,1992(5):12-13.
[11] 李梅秀,Daniel,S.Worlton. 基于語料库统计的“音-形”激活概率及加工机制[J]. 心理学探新, 2018(4):20-21。
[12] 郭曙纶. 汉语语料库大规模统计与小规模统计的对比[R]. 全国教育教材语言专题学术研讨会, 2008.
[13] 刘泽权. <红楼梦>中英文语料库的创建及应用研究[M]. 北京:光明日报出版社. 2010:145.
[14] 梁茂成. 什么是语料库语言学[M]. 上海:上海外语教育出版社.2016:128.
[15] 胡开宝. 语料库翻译学概论[M]. 上海:上海交通大学出版社.2011:59.
作者简介:禹琳琳(1988-),女,汉族,籍贯:河南郑州,单位:河南牧业经济学院外国语学院,职业:助教,学位:硕士,研究方向:翻译,英美文学。
