基于深度学习的木材缺陷图像的识别与定位
2020-06-23李若尘朱悠翔孙卫民龚思源
李若尘,朱悠翔,孙卫民,龚思源,钱 鑫,业 宁
(1.南京林业大学信息技术学院,南京,210037;2.江苏省住建厅住宅与房地产业促进中心,南京,210009;3.南京市金陵中学,南京,210005)
引 言
天然木材具有易加工,可再生,保护环境等优点,广泛应用于社会生产中。我国对木材的需求量巨大,但人均木材占有量少,因此高效地提高木材的利用率具有十分重要的经济意义。在实际生产中,不同品种的木材,加工方式是不同的。如何最优化加工,一方面需要鉴别木材品种[1],另一方面需要对木材缺陷进行检测。木材缺陷一般包括木材天然缺陷、干燥缺陷和加工缺陷。人工提取木材缺陷不仅消耗大量人力,而且精准度低,经济效益差。传统的木材缺陷检测包括X 射线[2]、超声波[3]、微波[4]、核磁共振[5]等无损检测技术[6]。这些基于物理设备的检测技术由于成本过高,并不适用于大规模木材缺陷识别。近年来,由于计算机技术的快速发展,由物理设备的缺陷检测研究逐渐向计算机图像自动缺陷检测研究方向发展[7],基于计算机图像的木材缺陷识别技术的方法主要有图像块百分位颜色直方图[8]、支持向量机(Support vector machine, SVM)[9-12]、卷积神经网络[13]、灰度共生矩阵[14]、凸优化[15]等,常见方法见表1 。Xie 等[14]针对木材本身特点进行研究,通过对木材的纹理特征,采用灰度共生矩阵方法,对木材缺陷进行定位。Pham 等[15]利用蜜蜂算法优化支持向量机,改进木材缺陷检测技术。Zhang 等[16]利用通过主成分分析(Principal component analysis, PCA)与压缩感知对木材图片进行处理。Qi[17]利用Hu不变矩阵以及BP 神经网络,对木材缺陷进行定位识别。文献[18]利用Ostu 算法对木材数据进行处理。文献[19]通过聚类算法和灰度共生矩阵(Grey-level co-occurence matrix, GLCM),自动找出并正确识别木材表面缺陷位置,比较分析不同木材表面缺陷的识别效率。

表1 不同的木材检测方法Table 1 Different wood detection methods
以上针对木材缺陷定位的研究均取得了较好的结果。但是这些方法都需要有木材知识背景的专家在前期对图片手工设置特征,工作量十分巨大。并且这些方法的模型依赖于算法和已有的木材特征,只能对特定的数据集进行识别和定位。而实际生产中拍摄灯光的不同,木材品种的不同均会对实验结果产生影响。
本文采用基于深度学习的自动缺陷定位模型方法(Automatic defect location model, ADLM):自动提取木材特征并生成热力图,通过聚类缺陷特征,实现对木材单缺陷与多缺陷的定位功能。此方法无须人工定位木材缺陷与范围,只需标注有无缺陷即可,大大减小了前期人工成本,木材缺陷的检测更高效。并且,由于前期使用ImageNet 进行预训练,训练时无须大量数据。实验结果表明,该模型只需要少量数据集进行特征提取,就可以很好地实现对木材缺陷的检测和定位功能。
1 背 景
木材缺陷识别一般包含两部分,一是对木材缺陷特征的学习与提取,二是对木材缺陷的定位。虽然卷积神经网络的学习能力越来越强,但是随着其规模越来越大,耗时也越来越多。复杂的网络并不适用于实际生产,因此,采用轻量级网络MobileNet[21]对木材缺陷特征进行学习与提取。MobileNet 不仅具有精度高、模型小等特点,还可以减少参数数量,提升运算速度。
MobileNet 模型基于深度可分离卷积,是一种分解卷积的形式。它将标准卷积分解为深度卷积和1×1 点态卷积。对于MobileNet,深度卷积对每个输入通道使用一个单独的滤波器。点态卷积通过1×1 卷积将输出和深度卷积结合起来。标准卷积在同一步中过滤并将输入组合为新的输出。而深度可分离卷积将这个步骤分为两层,一层单独用于过滤,另一层单独用于组合输入。这种因子分解的方法大大减少了计算量和模型大小。图1—3 展示了如何将标准卷积(图1)分解为深度卷积(图2)和1×1 点态卷积(图3)。
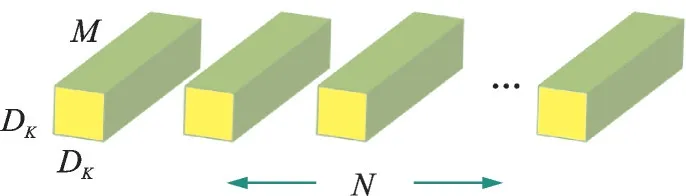
图1 标准卷积过滤器Fig.1 Standard convolution filter
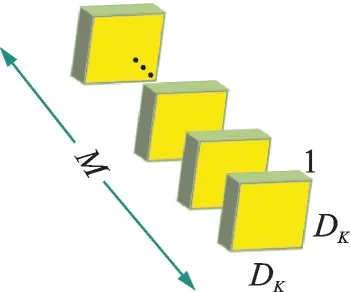
图2 深度卷积过滤器Fig.2 Depthwise convolution filter
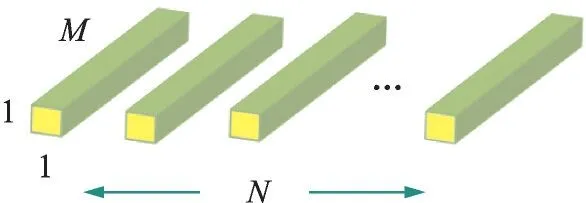
图3 1×1 点态卷积过滤器Fig.3 Pointwise convolution filter
这里简单分析一下深度级可分离卷积在计算量上与标准卷积的差别。假定输入特征图大小是DF×DF×M,而输出特征图大小是DF×DF×N,其中DF是特征图的宽度和高度,这里假定两者是相同的,M为输入通道数(输入深度),N是输出通道的数量(输出深度)。这里也假定输入与输出特征图大小是一致的。采用的卷积核大小尽管是特例,但是不影响下面分析的一般性。标准卷积层由卷积核K参数化,对于标准的卷积DK×DK,其计算量将为

对于深度卷积(Depthwise convolution, DW)其计算量为

点态卷积(Pointwise convolution, PW)计算量为

所以深度级可分离卷积总计算量为
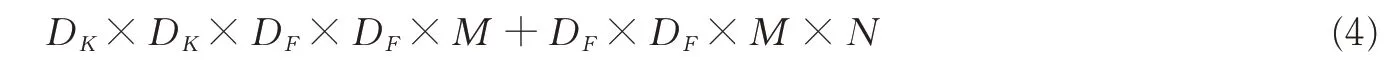
可以比较深度级可分离卷积和标准卷积为
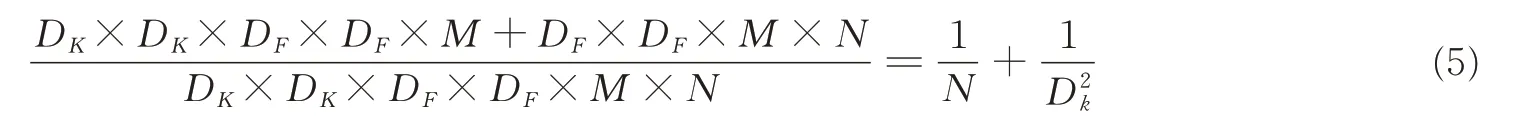
一般情况下N比较大,在一定范围内,如果采用k×k卷积核的话,深度级可分离卷积相较标准卷积可以降低大约k2倍的计算量。
标准卷积和MobileNet 中使用的深度分离卷积结构对比如图4 所示。
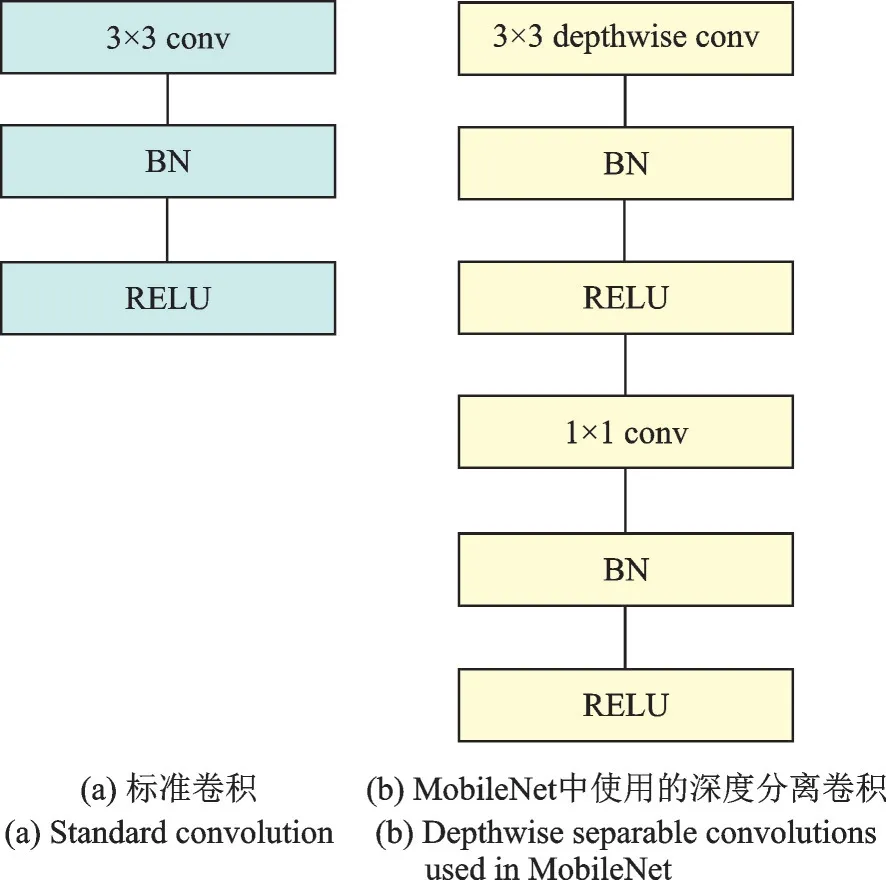
图4 结构对比Fig.4 Structure contrast
2 注意力模型
深度学习里的注意力模型是模拟人脑注意力的模型,当人观赏一幅画时,人的大脑主要关注在某一小块图案上,对整幅图的关注并不均衡,是有一定权重区分的。注意力模型在图像处理领域取得了非常好的效果。因此使用注意力模型对木材图片进行特征处理与提取,生成热力图。处理步骤如下:
(1)预训练(图5)。①建立MobileNet 卷积网络模型,用公开数据集ImageNet 来训练MobileNet,得到其backbone(神经网络中除全连接层外的整个网络骨架)的权值A。②经过backbone 后输出特征图,通过Global Average Pooling(GAP)进行降维。③将特征图输入权值为ω的全连接层,得到预测的分类输出。④将各输出用softmax 函数进行数值处理,得到不同类别之间的相对概率。⑤通过最小化交叉熵loss 函数对MobileNet 不断更新A'与ω',直到收敛为止。记训练好的MobileNet 的backbone 的权值为A,全连接层的权值为ω。
softmax 函数为

式中:Vi为分类器前级输出单元的输出,i表示类别索引,总的类别个数为C(此模型C=1 000);y'i表示的是当前元素的指数与所有元素指数和的比值。
Loss 函数为

式中:yi为当前元素的标签,i表示类别索引,总的类别个数为n(此模型n=1 000);y'i表示的是当前元素的相对概率。

图5 预训练流程图Fig.5 Pre-training flow chart
(2)训练(图6)。①随机初始化预训练完成后的MobileNet 中的ω,使全连接层输出类别个数为2个。②输入已手动标记好有无结疤的图片进行训练,用预训练完成后的MobileNet 模型对训练集进行特征提取,得到特征图。③通过GAP 降维,全连接层由权值ω进行输出分类。④将各输出用softmax 函数进行数值处理,得到不同类别之间的相对概率。⑤用loss 函数(损失函数)进行优化度的评价,最小化loss 函数不断更新A'与ω',直到收敛为止。由于经过预训练的MobileNet 具有高效的特征提取能力,对于二分类问题,其只需要提供少量数据集进行训练,就能很好地对木材图片进行判断与特征提取。
此训练模型的softmax 函数与loss 函数模型同上,但类别数不同。此模型C=2,n=2。

图6 训练流程图Fig.6 Training flow chart
(3)生成热力图(图7)。①对(2)中模型做修改(去除GAP 处理步骤并把全连接层改成1×1 卷积层,保留权值ω')。②输入测试图片,训练好的MobileNet 进行特征提取,通过1×1 卷积生成两张热力图(根据文献[16]提出的卷积网络可视化发现,用1×1 卷积层替代全连接层,生成的热力图可以很好地表示特征),一张是标记为有缺陷的,一张是标记为无缺陷的。此时,经过1×1 卷积层后的特征图分辨率不变,只是深度改变。
(4)分类与取舍。①将(3)得到的热力图进行GAP 降维操作。②用softmax 函数得到有无缺陷的可能性,对上述热力图进行分类与取舍。
此模型的softmax 函数模型同上。
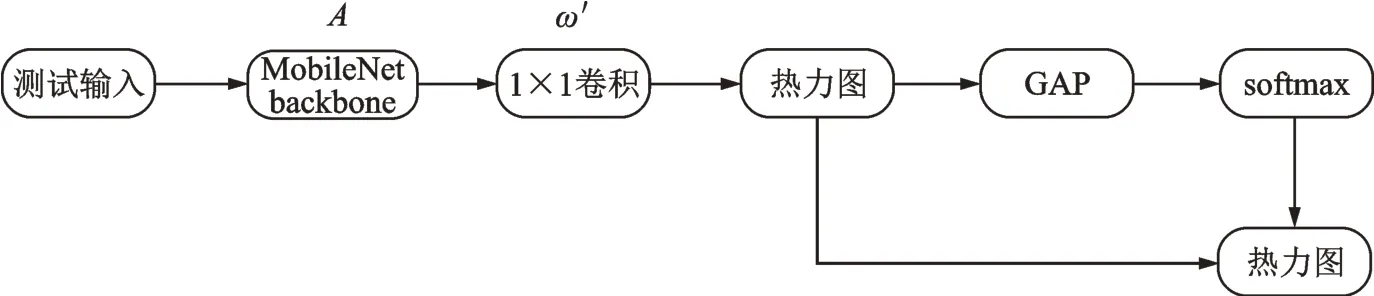
图7 生成热力图与分类取舍步骤Fig.7 Generating thermodynamic diagram and selection steps of classification
3 自动缺陷定位模型
本节主要介绍自动缺陷定位模型的两种模型,单缺陷定位模型与多缺陷定位模型。这两种模型都是基于上述注意力模型所生成的热力图,采用不同的算法对其进行处理,从而精确定位木材缺陷。
3.1 单缺陷定位模型
单缺陷定位模型是基于注意力模型生成的热力图对木材的缺陷进行精准定位(图8)。步骤如下:(1)热力图预处理。①将生成的热力图进行二值化处理。②去除无效数据(降低噪声),例如远离中心,较零碎的点等。③对所有特征点进行聚类。

图8 单缺陷定位模型算法Fig.8 Single defect location model algorithm
(2)定位。经过二值化的热力图只包含0 和255 两个值,其中0 代表提取的特征点(x,y)(特征点为有缺陷特征的点)。①循环遍历热力图各点,判断其是否为特征点,若为特征点且左右相邻两格有特征点,则该点被放入特征集(V)中。由于木材缺陷形状多为规则圆形或椭圆,因此可用矩形框对其描述。根据特征集中的点,采用式(8),对缺陷进行定位(x,y,width,height)。其中,(x,y)为缺陷的中心点,width 表示矩形框的宽度,height 表示矩形框的高度。此模型寻找的缺陷为范围最大的缺陷,即矩形框面积最大的缺陷。
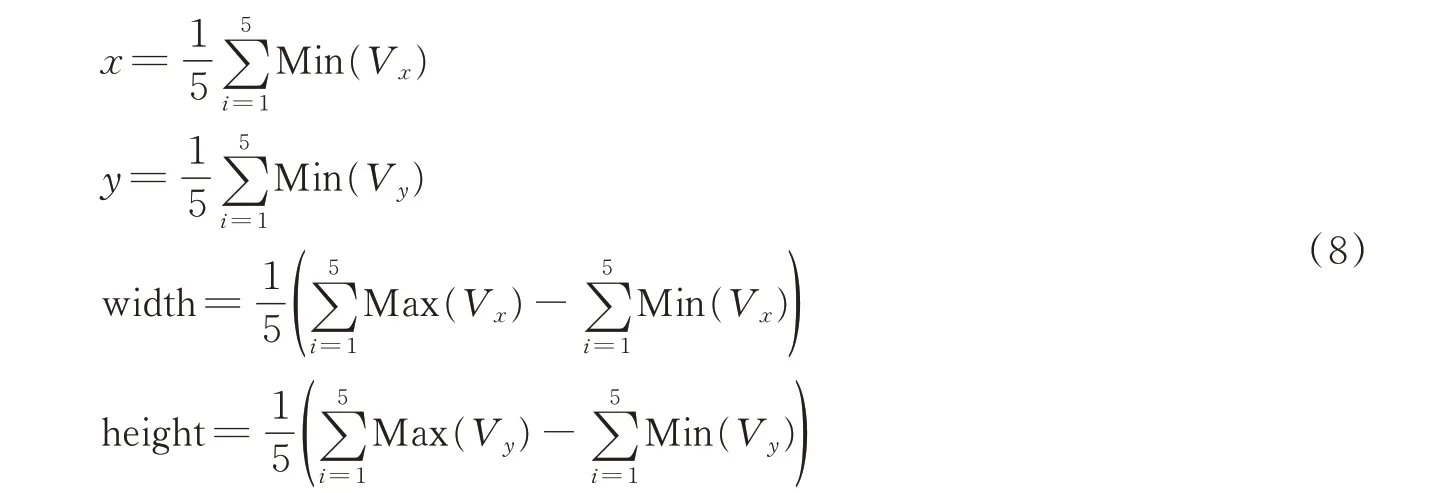
3.2 多缺陷定位模型
单缺陷定位模型只能定位图片中最明显,范围最大的单个缺陷,而真实环境下的木材缺陷往往如图9 所示,一块木板上拥有多个缺陷,因此改进单缺陷定位模型,提出了多缺陷定位模型,该模型可对木材图片中的多个缺陷进行定位。

图9 多缺陷木板Fig.9 Multi-defect wood board
与单缺陷定位模型类似,该模型同样是基于注意力模型生成的热力图并二值化。在单缺陷模型中,所有特征点都是描述同1 个缺陷特征的,但是在多缺陷定位模型中,不同的特征点往往属于不同的缺陷特征。因此,在原有基础上,改进特征点的聚类方法,实现了多缺陷定位。在循环遍历热力图时,对所有点加一个访问判断参数visited,若访问过,则为1,未访问则为0。若当前点为特征点且未被访问,循环遍历该点所有相邻特征点,并加入该缺陷特征栈中,通过不断插入,删除特征栈中的节点,建立完整的缺陷表(相当于滑动框扫描)。当最终遍历结束时,每一个特征表都代表一个缺陷特征。特征表的个数就是该木材图片中缺陷的个数,再根据式(8),求出每一个缺陷的具体位置。具体算法如图10所示。

图10 多缺陷定位模型算法Fig.10 Multi-defect location model algorithm
4 实 验
4.1 实验数据与训练
公开数据集Wood Defect Database 中共包含两组子数据集,第1 组数据集是单木材缺陷图片,共有438 张,第2 组数据集是多缺陷木材图片,共有839 张。由于Mobilenet 网络训练需要提供有缺陷与无缺陷两组数据集,因此从多缺陷木材图片中人工进行切割,共得到20 张无缺陷木材图片与20 张有缺陷木材图片,并手动标记是否有缺陷,如图11 所示。

图11 木材训练集Fig.11 Wood training set
将选取的训练集输入注意力模型中,经过200 轮训练,得到99.7%的判别率,其中训练权重仅占12.5 MB。再将单数据集与多数据集分别输入注意力模型中进行测试,得到86.1%的识别率。
由实验可知,MobileNet 具有强大的特征提取能力,特别是在二分类学习中,仅需少量训练集,就可高效率地判别木材有无缺陷,较为精准地识别缺陷。
4.2 单缺陷定位模型
将438 张单缺陷的木材图片作为输入,由图12 可知,首先对图片进行处理,将图片输入注意力模型中,得到木材缺陷的特征热力图,然后根据热力图,运用SDLM 单缺陷定位模型进行处理,最终可以得到单个缺陷的定位图。
在438 张图片中,427 张缺陷图片能够十分精确地定位,精确率为97.5%,定位效果如图13 所示。在剩下的11 张图片中,有7 张定位了部分缺陷,定位率为99.1%,如图14 所示。还有4 张由于其背景纹路复杂、对比度低,因此定位困难,错误率在0.9%~1.0%。
同时,用不同品种的木材缺陷图作为对照组测试,模拟实际情况下,木材图像的不同色温与不同缺陷种类,均取得了较高的精准率,如图15 所示。其中,活节(a,e)、死节(c,d,f)、裂纹(b)均可以实现较为准确的识别与定位。
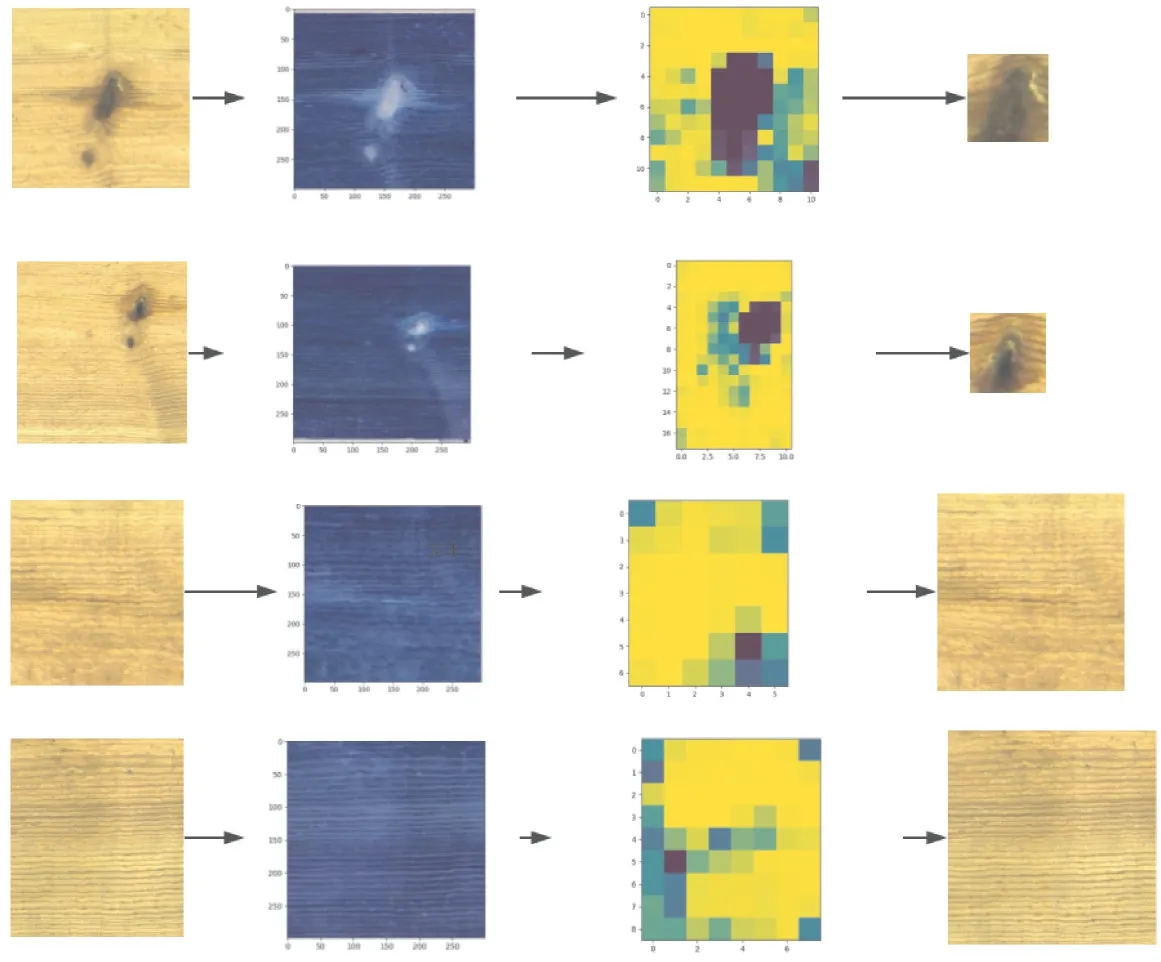
图12 SDLM 训练结果Fig.12 SDLM training results

图13 SDLM 定位结果Fig.13 SDLM localization results
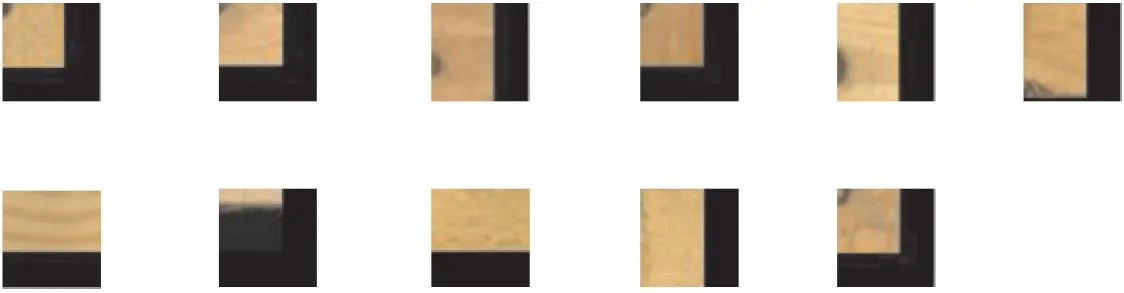
图14 SDLM 定位错误结果Fig.14 SDLM location error results
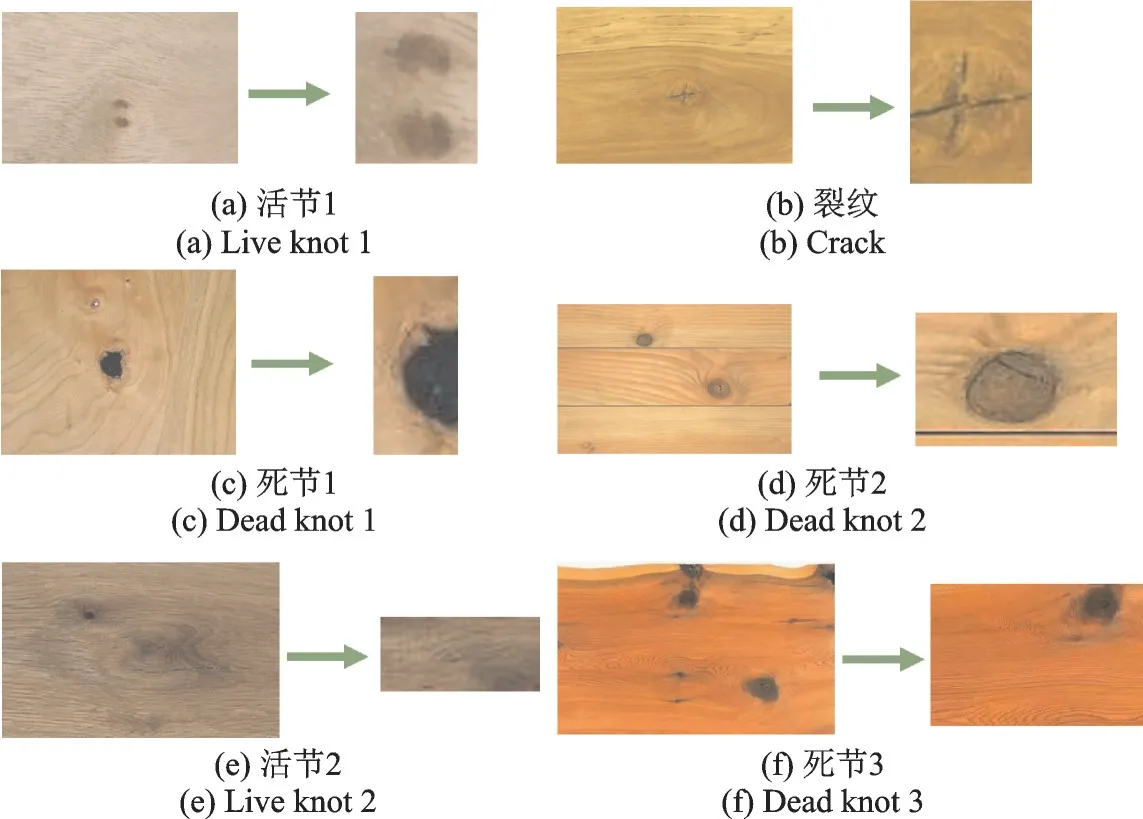
图15 不同品种木材SDLM 定位结果Fig.15 Results of SDLM localization of different wood species
4.3 多缺陷定位
单缺陷在数据集Wood Defect Database 上取得了很好的定位识别率,但是单缺陷模型并不适用于真实生产实践中,因此通过使用多缺陷定位模型对多缺陷图片进行缺陷定位。以图16 为测试集,其中包含若干缺陷。将其代入多缺陷定位模型当中,最终共定位20 张图片,其中18 张是包含缺陷。由于在实验过程中通过覆盖原图,使这18 张缺陷图片互不相同,最终定位率达到90%。实验结果如图17所示。

图16 多缺陷木材图片Fig.16 Picture of multi-defect wood

图17 多缺陷木材实验结果Fig.17 Experimental results of multi-defect wood
5 结束语
本文利用深度学习的方法,运用注意力模型自动提取木材特征,无须人工定位木材缺陷与范围,只需通过少量已标注是否有缺陷的数据集进行训练,就可以高精度、高效率地判别木材有无缺陷并生成对应的热力图。针对木材缺陷的不同特征,提出了单缺陷定位模型(SDLM)与多缺陷定位模型(MDLM),可以满足实际生产中对木材缺陷处理的不同需求。在木材识别问题中,采用MobileNet 对木材特征进行提取,最终可以得到86.1%的正确率,且权重仅占12.5 MB。在单缺陷木材图片中,单缺陷定位模型取得97.5%的精确定位率,定位率在99.1%,错误率为0.9%~1.0%。在多缺陷数据中,定位率为90.0%。因此基于注意力模型的单缺陷定位模型与多缺陷定位模型方法可以很好地适用于生产实践中,具有检测速度快、精度高、适用性更广等优点。下一步,将继续研究如何利用少量数据集,提高木材缺陷的识别率,以及在复杂背景下,如何保持木材缺陷的识别与定位的更高精准度,使木材缺陷定位能够更好地适用于复杂的生产实践过程当中,为木材最优化分割做准备。同时,也将基于木材的自动缺陷定位模型,进行有关木材缺陷分类与最优化木材分割的研究。这有助于“对症下药”地处理木材缺陷,提高珍贵木材的利用率。这项技术不仅可以减小木材加工过程中的损耗,降低成本,提高经济效益,还可以总体上减少木材的砍伐量,有助于森林木材的可持续发展。
