信息增益混合邻域粗糙集的肺部肿瘤高维特征选择算法
2020-06-23陆惠玲张飞飞霍兵强
陆惠玲,周 涛,,4,张飞飞,霍兵强
(1. 宁夏医科大学理学院,银川,750004;2. 北方民族大学计算机科学与工程学院,银川,750021;3. 中国电信股份有限公司宁夏分公司,银川,750002;4.宁夏智能信息与大数据处理重点实验室,银川,750021)
引 言
肺癌的发病率及致死率在癌症中均居首位,肺癌的筛查和早期诊断可以有效预防和控制肺部肿瘤的进一步恶化,电子计算机断层扫描(Computed tomography,CT)可以清晰地反映组织器官的解剖结构,对于早期筛查具有重要意义[1]。虽然影像学检查为肺癌的诊断带来直观结构信息,但大量的影像数据也给临床医生带来沉重的工作负担,漏诊率和误诊率居高不下。以医学影像为基础的计算机辅助诊断系统(Computer aided diagnosis,CAD)借助计算机快速准确的智能化分析能力可以大幅度减轻主观因素带来的失误,提高工作效率。特征级融合是CAD 分析过程中非常重要的一部分,可以有效提高辅助诊断的精度,同时从新的角度分析影像数据,与像素级和决策级处理形成互补,共同促进智能化诊断的发展。但是由于特征之间的相关性和冗余性使得“维数灾难”成为高维特征级融合过程中不可避免的问题,有效地特征选择算法可以降低维度和时间复杂度[2]。
信息增益(Information gain,IG)和粗糙集(Rough set,RS)是特征选择是常用的两种算法。IG 是衡量包含或者不包含某个特征时为分类器提供信息量的指标,依次求出每个特征对分类器提供的信息量,然后从大到小进行排序,按照一定的规则取前K个特征,从而达到利用信息增益进行特征选择的目的。IG 进行特征选择计算复杂度较低,只需单次运算,因此运行效率较高,可以有效剔除冗余、不相关以及噪声特征。但IG 作为一种过滤式算法进行特征选择仍然存在问题,它只能衡量某一特征在整个系统中的重要程度,而无法区分该特征属于何种类别,而且并未考虑特征之间的关系,因此,对于不同类别使用相同特征分量的系统而言,采用IG 进行特征选择能够取得较好的效果,而对于不同类别具有不同特征分量的系统而言,IG 则无法进行特征选择。RS 是处理不确定性数据的有效工具,因其无需先验知识的特性,广泛应用于特征选择[3]、模式识别[4]、数据挖掘与知识发现[5]等领域。RS 研究的两个重要概念分别是概念近似和属性约简,其中属性约简是在不影响当前识别任务可辨性的前提下降低属性的维度,但是RS 最初是在一定基础上构建的等价关系,在许多实际应用中都受到了限制。因此为了避免数据对单一方法的依赖以及更好地剔除数据集中的冗余和不相关属性,很多学者将IG 的全局特征选择能力与RS 优越的属性约简能力相结合进行高维特征选择,已经成功应用于情感分析[6]、房地产价目分析[7]、肿瘤诊断分类[8]和渔情预测[9]等。但是Pawlak RS 只能处理名义型变量,实际应用中的数据往往是连续的数值变量,离散化后的数据集虽然可以适应RS 算法等价类的构建,但是也可能会丢失重要信息,并且不同的离散化策略也会影响约简效果[10]。领域粗糙集(Neighborhood rough set,NRS)通过引入领域关系改进了Pawlak RS,可以直接对连续的数值型数据进行处理。IG 和RS 虽然都可以单独进行特征选择,但是存在一定的局限性,因此将两者的优势相结合进行特征选择具有一定的可行性,借助IG结果选出高相关的特征子集,再通过NRS 剔除高冗余的属性,其中,NRS 可以克服RS 只适合处理离散变量而导致原始信息大量丢失的问题。通过两次属性约简得到最优的特征子集,能更好地剔除数据集中的冗余和不相关特征,提高算法的性能,降低时间复杂度,也可以避免数据对单一方法的依赖。
因此,本文综合IG 和NRS 的优势,提出一种混合高维特征选择算法。该算法首先计算所有特征的信息增益,挑选出信息增益值大于平均信息增益值的特征项,初步排除原始特征集合中相关性较小或者噪声特征,降低后续特征选择的时间复杂度。其次,将IG 约简后的特征子集作为NRS 的输入进行二次约简,得到最终的特征子集。最后利用支持向量机(Suppotr vector machines,SVM)作为分类器验证约简前后算法的性能。
1 基本原理
1.1 信息增益
信息增益通过分析增加或者删除某一特征前后系统信息量(熵)的变化多少来衡量特征的重要性,关于期望信息、熵和信息增益等概念的定义如下:
定义1[11]假定S是数据样本,定义了m个不同类Ci(i=1,2,…,m),设Si为Ci的样本数。aj为属性A的值(j=1,2,…,v)。样本分类所需的期望信息为
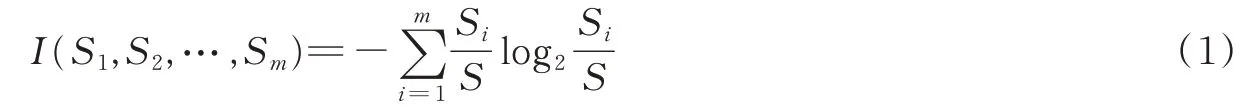
定义2 设用属性A将S划分为v个子集{S1',S2',…,Sv'},根据A划分成子集的期望信息,即熵为
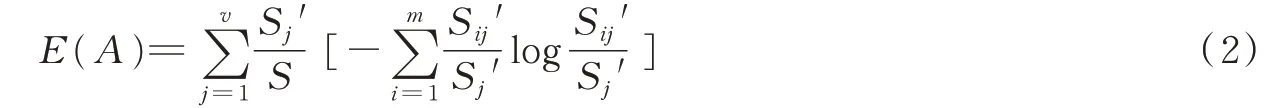
式中:Sij'为子集Sj'中类Ci的样本数。
选择属性A的信息增益为
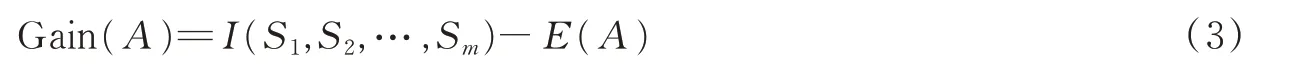
1.2 邻域粗糙集
粗糙集(Rough set,RS)是一种分析具有不确定、不完整和不一致等不完备特性的软计算方法,揭示信息中存在的潜在规律,已经成功应用于近似推理、分析决策和模式识别等领域。为了不断完善RS 的理论基础、拓展应用范围,专家学者们相继提出了很多改进算法,例如粒度RS、NRS、加权RS、覆盖RS、灰色RS、决策RS、模糊RS、优势RS 等[12]。其中NRS 是在Pawlak RS 的基础上引入邻域关系而提出的处理连续型数据的模型,避免了Pawlak RS 离散化过程中对原始信息的丢失[13],相关定义如下:
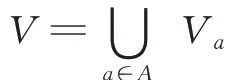
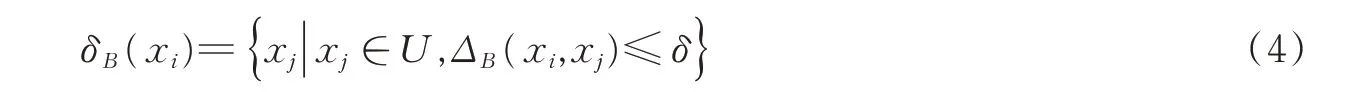
定义4[14]邻域决策系统的上近似和下近似决策属性D将论域U划分为N个等价类X1,X2,…,XN,B⊂A生成U上的邻域关系,则决策属性D关于子集B的上、下近似及边界定义为上近似

下近似亦称为正域,记作PosB(D)

(3)图像分割:为了对肺部肿瘤图像的形状、纹理和灰度等特征进行全面、准确的测量,采用最大类间方差法(OTSU 算法)[17]对预处理后的ROI 区域进行分割,其基本原理是将直方图在某一阈值处分割成两组,一组对应背景,一组对应目标。如图3 所示,给出本文分割前后的5 组实例;图4 给出两例患者的肺部肿瘤CT 图像(图4(a)是恶性肺部肿瘤CT 图像ROI 区域,图4(b)是良性肺部肿瘤CT 图像ROI区域)。
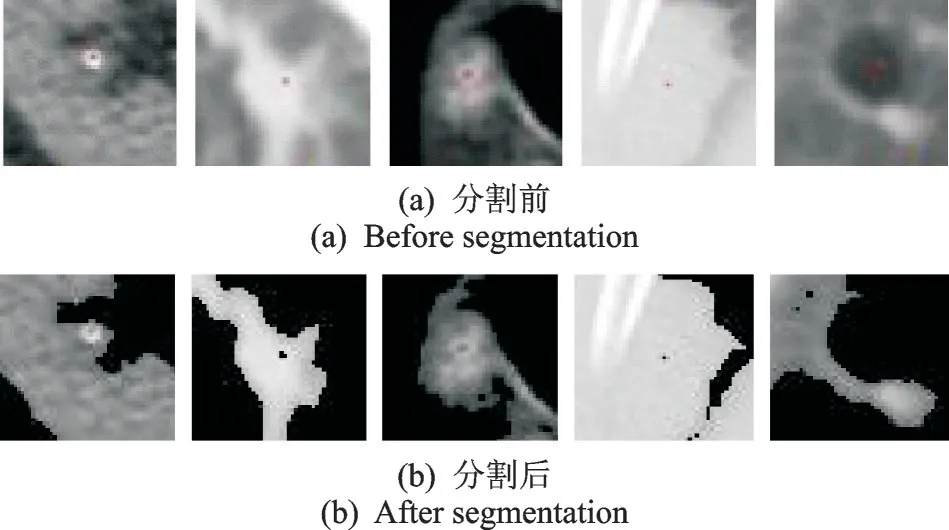
图3 OTSU 算法分割前后肺部肿瘤ROI 区域实例Fig.3 Examples of ROI region of lung tumors before and after OTSU segmentation
(4)特征提取:提取分割后ROI 图像目标区域的特征,包括形状特征、纹理特征和灰度特征共104 维特征,具体特征见文献[18]中表1 所示。构建的决策信息表大小为3 000×105,最后一列为决策属性,代表肿瘤的良恶性(“-1”代表良性肿瘤,“1”代表恶性肿瘤)。表1 给出图4 所示的两例患者的肺部肿瘤ROI 区域的104 维特征。

图4 肺部肿瘤CT 图像ROI 区域示例Fig.4 Examples of ROI regions in CT images of lung tumors
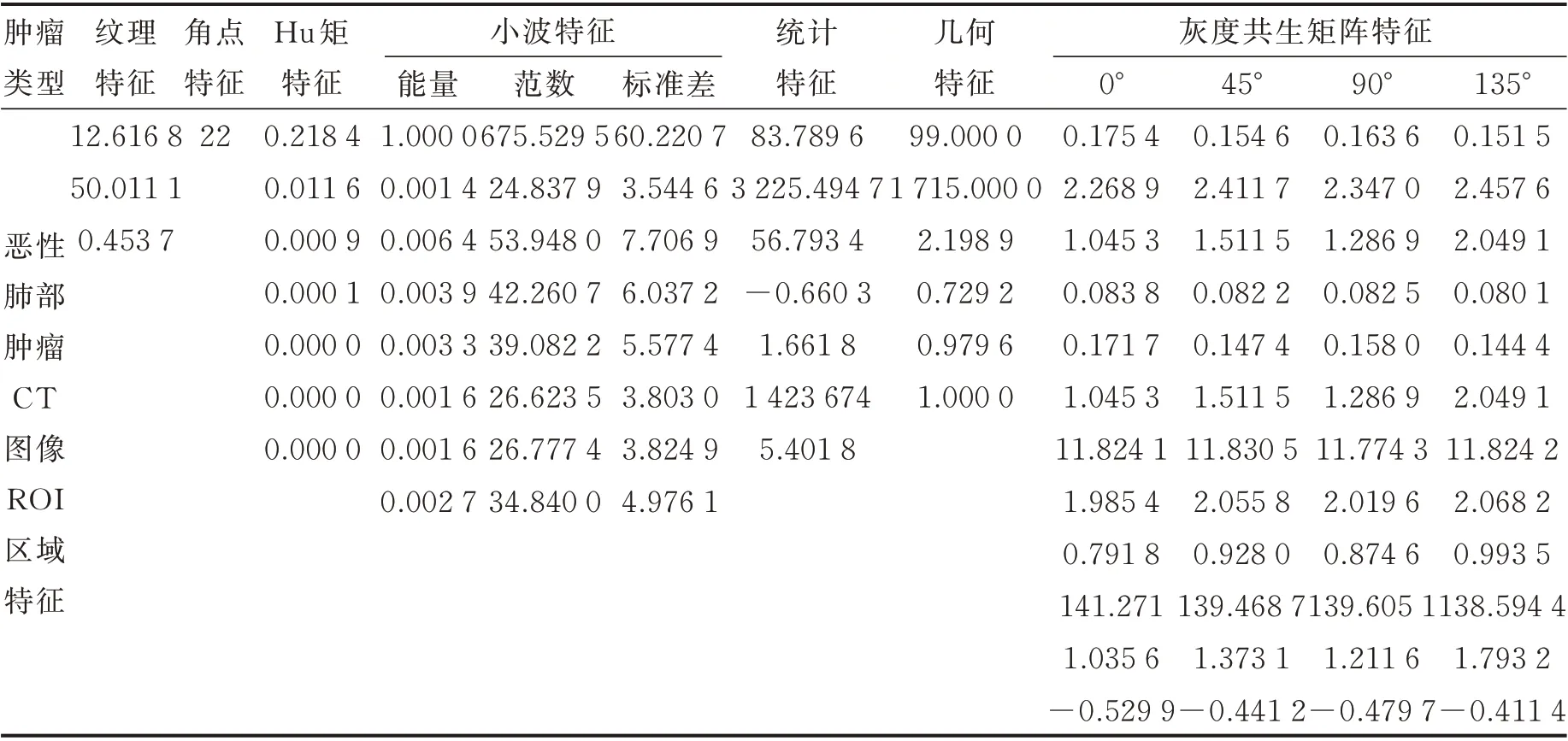
表1 两例患者的肺部肿瘤ROI 区域的104 维特征值Table 1 104-dimensional eigenvalues of ROI region of lung tumors in two patients
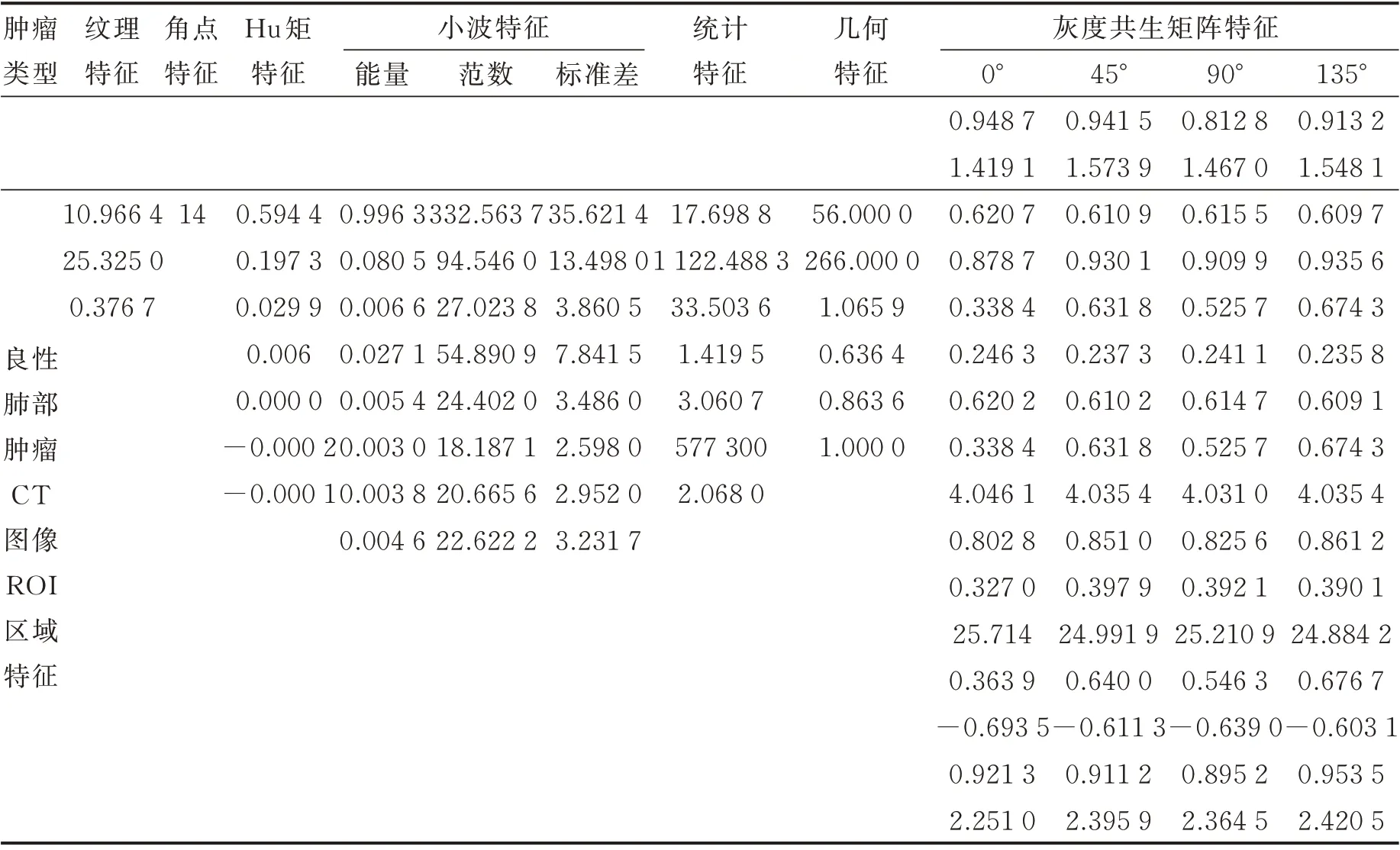
续表
(5)特征归一化:为了得到精确的数据处理结果,对原始数据进行归一化消除数据数量级和量纲的差异,本文采用常用的最大最小值法,使得归一化后的数据均落在[0,1]之间,其公式为
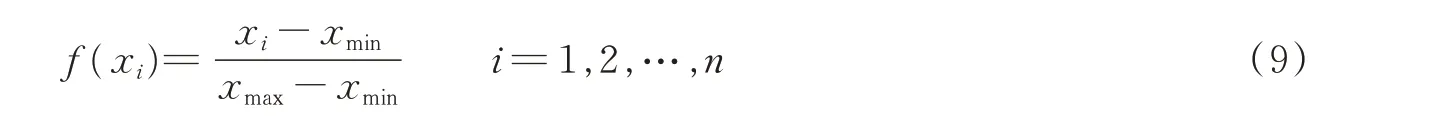
式中xmax和xmin分别为样本数组的最大值和最小值。
(6)基于信息增益的特征选择。
输入:连续型决策信息表S=(U,A,V,f),其中U=(x1,x2,…,xn)称为论域,表示全体样本构成的集合;A=C∪D,C表示条件属性构成的集合(即步骤(5)中经过归一化处理的104 维特征集合),D表示决策属性构成的集合(即肺部肿瘤的良恶性,用数字“1”代表恶性肺部肿瘤,“-1”代表良性肺部肿瘤);V表示属性值域的并集;f表示映射关系的信息函数;
输出:约简后的属性集合red1;
步骤:①初始化集合red1=φ,计算每个条件属性的信息增益Gain(Ci),计算每个条件属性信息增益的平均值average;
②选择信息增益最大的属性ci,red1=red1∪{ci},并在条件属性集C中去掉该属性;
③如果信息增益最大的属性ci的信息增益值小于平均值average,则停止得到red1,否则调至步骤②。
(7)基于邻域粗糙集的特征选择:NRS 属性约简是在不影响决策系统本身决策能力的前提下删除冗余属性,其约简算法使用的是前向贪心算法[19],其主要算法模型见图5,其主要步骤如下:
输入:信息增益约简后的属性集合red1=(U,A',V,f),其中A'=C'∪D,C'表示步骤(6)中信息增益值大于等于平均信息增益值的条件属性的集合,确定邻域半径δ的集合,设置重要度下限为0.001;
输出:两次约简集合red;
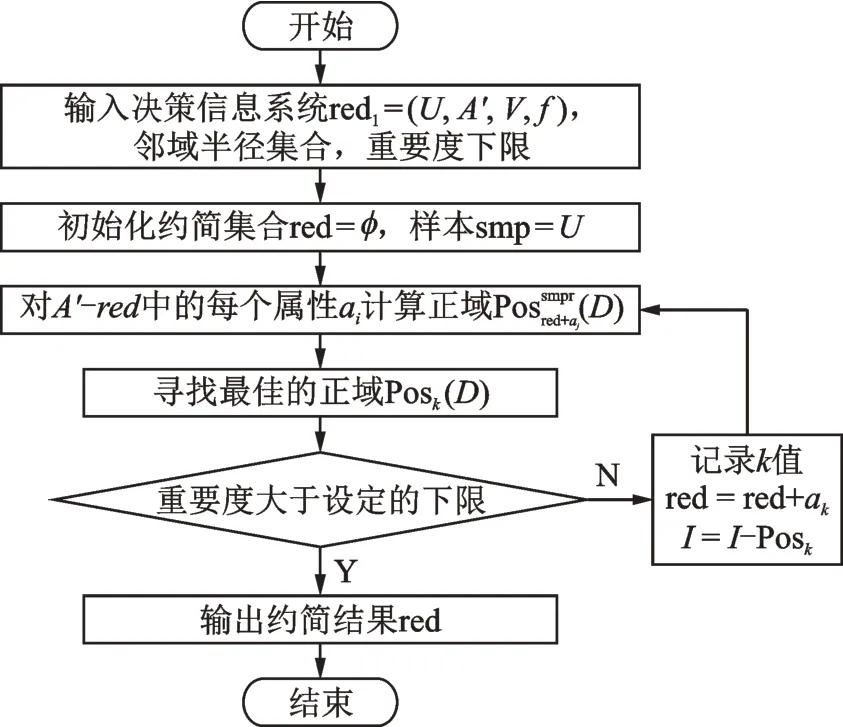
图5 前向贪心算法流程图Fig.5 Flow chart of forward greedy algorithm
步骤:①初始化两次约简集合red=φ,样本smp=U;
②对∀ai∈(C'-red) 利 用 式(6)计 算 正 域(D);
③对于a∈B,选择ak使得正域Posak(D)最大;
④利用式(8)计算属性重要度Sig(ak,red,D);
⑤若Sig(ak,red,D)大于设定的重要度下限值,则输出约简结果red,结束程序,否则,记录k值,令:red=red+ak,I=I-Posak,然后返回步骤②继续计算,直至输出约简结果red。
(8)基于SVM 的分类识别。
SVM 是有监督的数据挖掘算法,其基本思想是使用结构风险最小化原理在属性空间构建最优决策超平面对样本进行分割,使得分类器达到全局最优,可以较好地解决小样本、过学习、高纬度和局部极值等实际应用难题,具有很强的泛化能力与分类识别能力[20],可以有效解决以医学影像为基础的CAD 诊断过程中“非线性、高维度”的难题。因此,本研究采用SVM 对两次约简的结果进行分类识别,其中核函数选择径向基核函数(Radial basis function,RBF),采用网格寻优算法(Grid search,GS)优化SVM 的c和g参数,构建分类识别模型进行肺部肿瘤良恶性的鉴别。
3 仿真实验
3.1 实验环境
(1)硬件环境:处理器是Inter(R) Core(TM)i3-2130 CPU @3.40 GHz,安装内存4.00 GB,500 GB内存。
(2)软件环境:Matlab R2012a,LibSVM,Windows 7 操作系统。
3.2 分类器评价指标
早期诊断准确性的性能评价包括敏感性和特异性2 大指标,但是这2 个指标很难全面描述分类器的整体性能。因此,本文对约简阶段评价指标为约简长度,分类识别阶段的评价指标包括:精确度(Accuracy)、灵敏性(Sensitivity)、特异性(Specificity)、F值(F-score 值)、马修斯相关性系数(Matthews correlation coefficient,MCC)、平衡F分数(BalancedFScore,F1Score)、约登指数(Youden index,YI)和时间(Time),具体介绍如下:
精确度(Accuracy)是最常见的评价指标,精确度越高,分类器性能越好,计算公式为
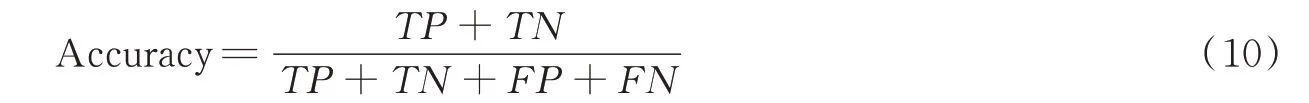
灵敏性(Sensitivity)和特异性(Specificity),分别用来衡量分类器对正例和负例的识别能力,值越大,识别性能越高,计算公式为
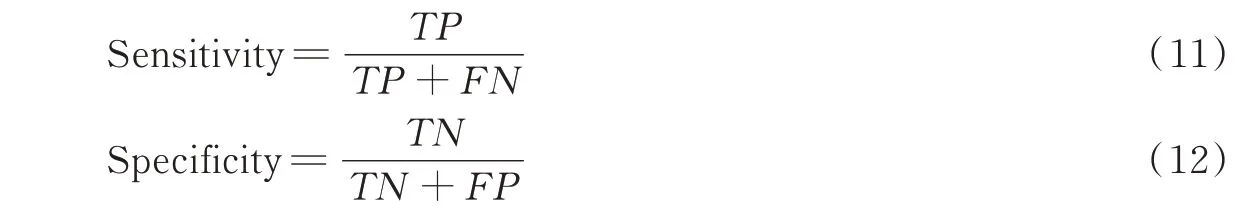
F值是查全率与查准率加权调和平均,用来权衡精确度和召回率,计算公式为

MCC 是描述实际分类与预测分类之间的相关系数,全面考虑了真阳性、真阴性、假阳性和假阴性,是一种更加均衡的指标,它的取值范围是[-1,1],值越接近于1 表示受试对象的预测越准确,计算公式为
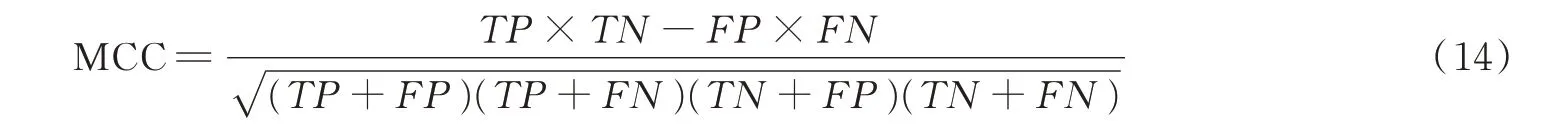
F1Score 是统计学中衡量二分类模型精确度的一种更为全面的评价指标,是准确率和召回率的一种加权平均,它的取值范围为[0,1],值越接近1 代表模型的精确度越高,计算公式为
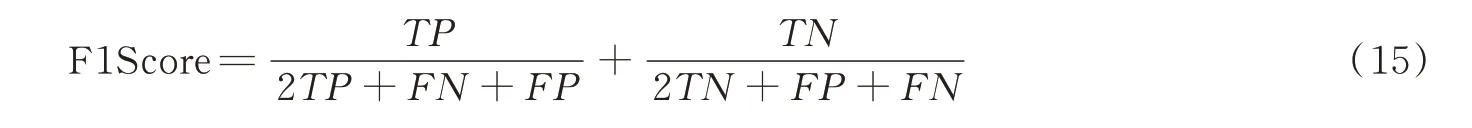
YI 又称正确指数,用灵敏度与特异度之和减1 的值表示,它的取值范围为[0,1],值越接近1,模型预测的真实性越好,计算公式为

式中:TP代表实际为恶性并且被正确预测为恶性的样本数,FP代表实际为良性但是被错误预测为恶性的样本数;TN代表实际为良性并且被正确地划分为良性的样本数;FN代表实际为恶性但是被错误预测为良性的样本数。
3.3 实验结果及分析
经过IG 的和NRS 两阶段约简后的特征子集,从理论层面可以有效降低原始决策信息表的维度,时间复杂度和空间复杂度。通过IG 可以初步筛选降低数据噪声,剔除相关性较小的属性,经过NRS 二次约简可以有效剔除高冗余的属性。为了进一步验证文本提出的两阶段约简高维特征选择算法的可行性和有效性,以3 000 例(1 500 例良性,1 500 例恶性)肺部肿瘤CT 图像为研究对象,获取ROI 区域后分别提取形状、纹理和灰度特征共104 维构造原始特征集合,采用IG 和NRS 进行两阶段约简,约简结果利用SVM 进行分类识别。
实验1 不同约简算法约简过程的比较
利用不同的算法对原始决策信息表进行约简,并采用约简长度比较不同算法的优劣,具体结果见表2 和图6 所示。
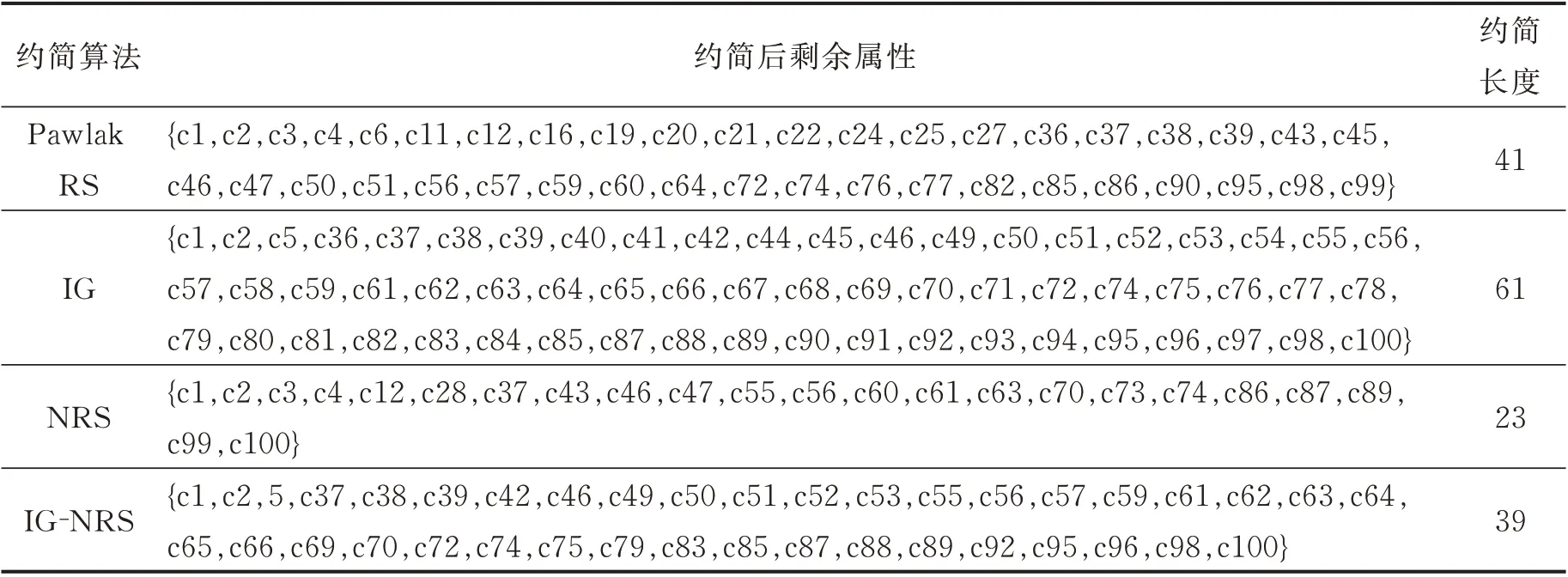
表2 不同约简算法约简过程的比较Table 2 Comparison of reduction processes of different reduction algorithms
从表3 和图6 可见,采用不同算法对原始决策信息表进行约简后相比不约简时,信息表的维度都有较大程度的降低,本文算法的约简长度仅高于NRS 约简算法,相比原始信息表维度降低65 维。
实验2 不同约简算法分类结果的比较
对实验一不同算法的约简结果分别利用SVM 五折交叉(即每次从1 500 例良(恶)性肿瘤图像中选取300 例作为测试集,其余1 200 例作为训练集)进行分类识别,从精确度、敏感度、特异性、F值、MCC、F1Score、Youden 和总时间8 个指标评价算法的优劣。具体结果见表3。
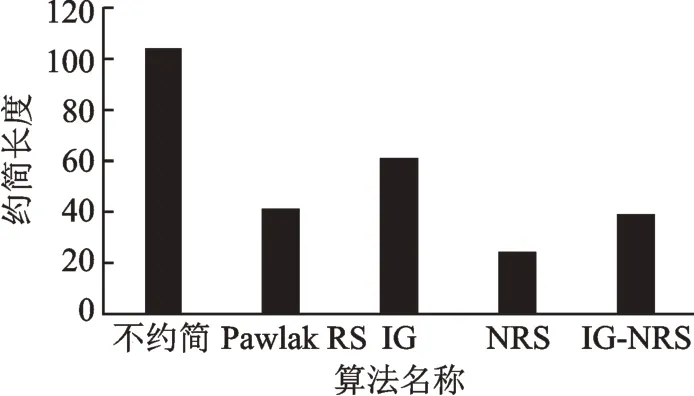
图6 不同约简算法约简结果(约简长度)的对比Fig.6 Comparison of reduction results (reduction length)of different reduction algorithms
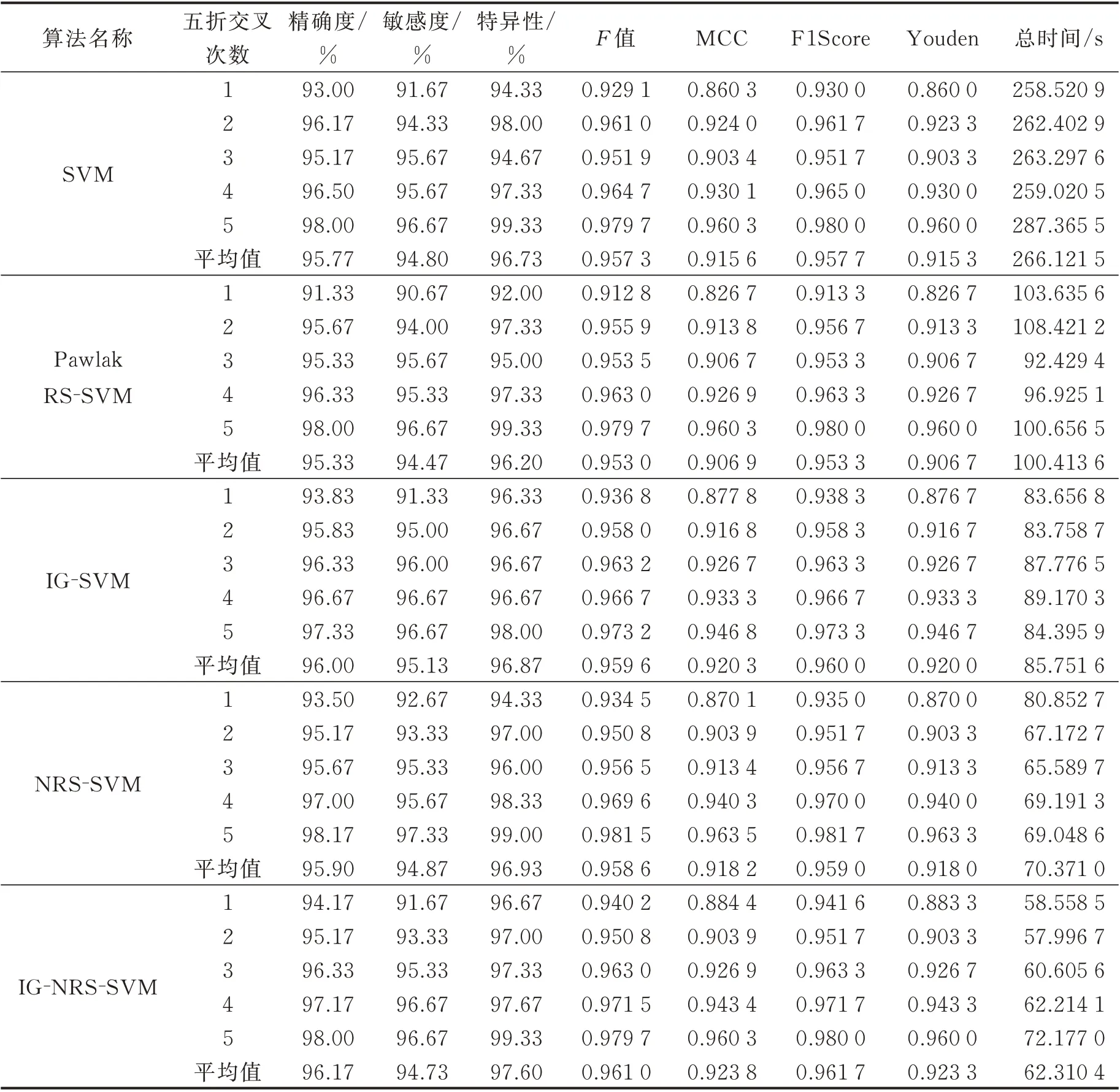
表3 不同算法分类结果的比较Table 3 Comparison of classification results by different algorithms
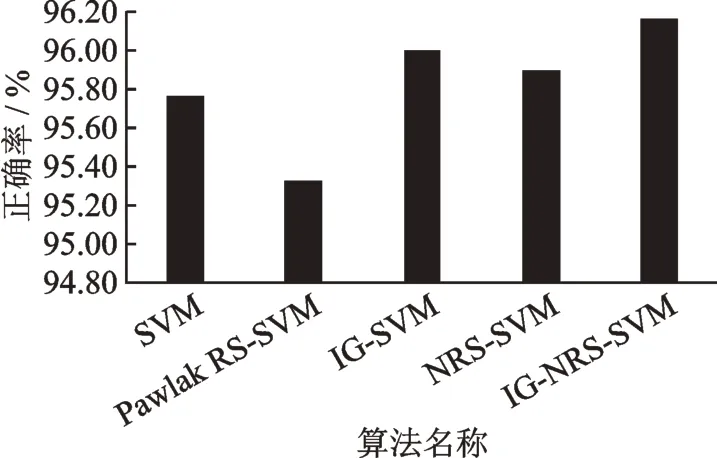
图7 不同算法分类精确度的比较Fig.7 Comparison of classification accuracy of different algorithms
由表4 可见,同种算法不同交叉次数各评价指标存在差异,为了全面衡量算法的性能,采用五折交叉的平均值作为该算法的最终分类结果。除过Pawlak RS-SVM,本文算法敏感度相比其他算法有较小程度的降低,其他指标都优于其他算法,精确度、特异性、F 值、MCC、F1Score 和Youden 分 别 提 高 0.17%~0.83%、0.67%~1.4%、0.001 5~0.008 1、0.003 5~0.016 9、0.001 7~0.008 3 和0.003~0.016 7,时间降低8.06~203.81 s。由于精确度和时间是最常用的评价指标,为了更加清晰地表示不同算法在精确度和时间2 个指标上的差异,将这2 个指标的平均值绘制柱状图,分别见图7,8 所示。
由图7 和图8 可见,本文算法的精确度最高,Pawlak RS-SVM 模型的精确度最低。因为Pawlak RS 的理论基础是等价关系的划分,因此只能分析离散型的数据,无法分析连续型数据。Pawlak RS 在分析连续型数据之前必须进行离散化处理,不仅增加了算法的时间复杂度,也会缩小数据之间的差异性,很大程度会影响最终的约简结果。离散化方法不同,离散化结果也不尽相同,给Pawlak RS 约简带来一定的影响[21],加之离散化后的特征集合无法全面刻画肺部肿瘤ROI 区域。本文算法的时间复杂度相比不约简时降低4.27 倍,也低于其他对比算法,由此可见本文算法可以提高肺部肿瘤高维特征选择算法的精确度,有效降低算法的时间复杂度,具有一定的推广价值。
本文分类阶段采用五折交叉,每折交叉测试集为600例,包括300 例良性,300 例恶性,按照表4 的实验结果可知,不同算法五折交叉结果精确度范围为91.33%~98.17%,则分类错误的样本数范围为11~52 个,由于篇幅限制,只列举每个算法第5 折交叉实验结果中分错的样本示例(对3 000 例实验样本进行编号,其中恶性肿瘤1 500 例,编号为1~1500,良性肿瘤1 500 例,编号为1501~3000。则第5 折交叉的测试集样本编号为:恶性肿瘤样本编号为1201~1500,良性肿瘤样本编号为2701~3000),结果见表4,其中“样本编号”列中的数字代表不同算法中被错误分类的样本编号;“分类错误的肺部肿瘤ROI 区域”是指不同算法中被错误分类的样本,即分割后的肺部肿瘤ROI 区域。
由表3 可见,不同算法第5 折交叉实验结果被错误分类的样本具有以下特点:
(1)恶性肿瘤被错分的样本数量大于良性肿瘤,可能的原因是恶性肿瘤较为复杂,具有不同的分级,不同等级肿瘤的形状、纹理和灰度特征也不尽相同。本文为了增大样本量,并未考虑肿瘤的分级,因此,恶性肿瘤中的不同等级的样本差异性较大,被错分的概率也较大;
(2)被错分的恶性肿瘤病灶部位所占像素普遍小于被错分的良性肿瘤,可能的原因是恶性肺部肿瘤相对良性肿瘤增长较快,表现在CT 图像中就是在ROI 区域中所占像素相对较大,如图4 所示,恶性肿瘤像素占整个ROI 区域的比例超过50%,而良性所占比例较小。图5 中被错分的恶性肿瘤样本ROI区域中病灶部位所占像素几乎都小于50%,而良性肿瘤病灶像素所占比例相对分类正确的较大,因此,被错分的良性肿瘤病灶所占比例普遍大于恶性肿瘤;
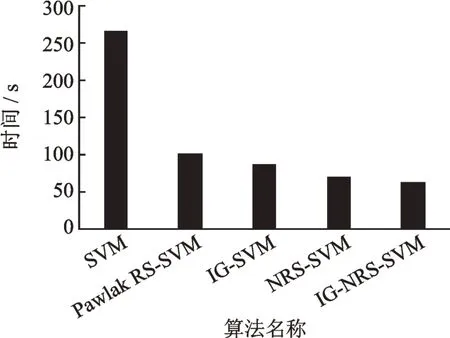
图8 不同算法分类时间的比较Fig.8 Comparison of classification time by different algorithms
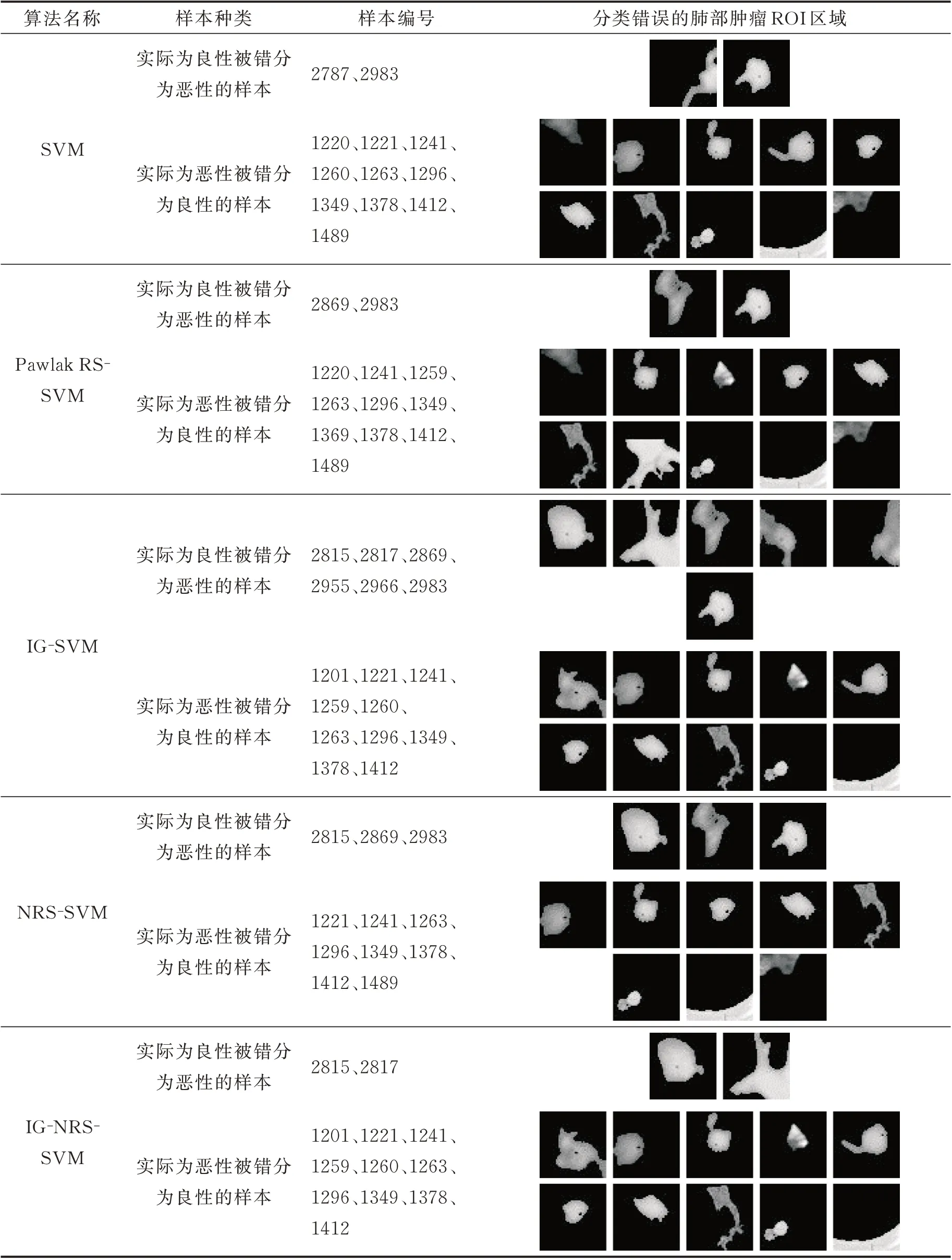
表4 不同算法第五折交叉分类错误的肺部肿瘤ROI 区域Table 4 ROI Regions of pulmonary tumors with fifth-fold cross classification error in different algorithms
(3)不同算法中被错误分类的样本存在交叉,恶性肿瘤样本交叉较多,本文数据处理过程是根据医嘱中临床结论来标记肿瘤良恶性的,存在一定的误差,可能的原因一方面是恶性肿瘤的分级,另一方面是临床医生的判定存在一定的漏诊和误诊,因此,不同算法中多次出现相同的被分类错误的样本。
4 结束语
为了提高肺部肿瘤计算机辅助诊断算法的性能,分析了IG 和NRS 的优缺点,提出一种混合IG 和NRS 的肺部肿瘤高维特征选择算法,从理论层面分析两阶段约简算法的可行性。为了验证算法的有效性,提取3 000 例肺部肿瘤CT 图像的104 维特征构造决策信息表,借助IG 和NRS 两次属性约简得到最优的特征子集,最后采用SVM 进行分类识别。通过与不约简算法、Pawlak RS、IG 和NRS 约简算法进行比较可知,该算法可以提高算法的精确度,有效降低时间复杂度,并且综合对比不同方法构建的肺部肿瘤高维特征选择算法的性能,确保本文方法的优越性,从模型方法的逐步选择上保证结果的科学性,对肺部肿瘤计算机辅助诊断具有一定的参考价值。
本文提出的算法虽然在一定程度上提高了算法的精确度,降低了时间复杂度,但是仍然存在一些不足之处。(1)由于医学图像的病灶部位在整个图像中所占像素比例很小,很有可能就是几个到十几个像素,因此特征级处理之前必须获取ROI 并提取特征才能更好地刻画病灶区域。本文的ROI 区域通过手动获取,可能会存在人为因素导致的误差,因此后期的研究可以考虑结合医嘱,让计算机自动识别ROI 区域;(2)算法的性能有待进一步提高,后期可以改善实验环境,配备高性能的服务器或者利用云平台降低由于客观因素导致的时间复杂度。
