融合数据分布特征的保序学习机
2020-06-23刘忠宝张志剑党建飞
刘忠宝,张志剑,党建飞
(中北大学软件学院,太原,030051)
引 言
支持向量机(Support vector machine,SVM)由Vapnik 和Corinna 最早提出[1],已经广泛应用于机器学习、数据挖掘和模式识别等领域,在解决小样本、非线性和高维度的模式识别中表现为速度快、精度高和理论支持清晰等优点[2]。SVM 是基于结构风险最小化理论,通过寻找一个最优的超平面得到全局最优解。在SVM 提出后,众多学者相继提出了SVM 改进算法:范昕炜等提出加权支持向量机(Weighted support vector machine,WSVM)[3],在实际问题中不同样本在训练时权重不同。针对不同的样本选取不同的惩罚因子,从而提高了小样本分类精度[4-5]。Suykens 等[6]提出最小二乘支持向量机(Least squares support vector machine,LSSVM),针对SVM 中约束条件所带来的计算复杂、边界定义不清晰等问题,使用等式约束条件代替不等式约束条件[7]。拉格朗日支持向量机(Lagrangian support vector machine,LSVM)[8]提高了在处理大规模线性数据集和中小型规模非线性数据集时的收敛速度。Tsang 等提出基于最小包含球(Minimum enclosing ball,MEB)的核心向量机(Core vector machine,CVM)[9],解决大规模数据集分类时所消耗大量时间和空间成本的问题。Lin 等提出模糊支持向量机(Fuzzy support vector machine,FSVM),在实际问题中,数据集通常会存在不同程度的噪声,影响分类效果。为解决噪声问题,引入模糊隶属度来降低噪声和异常值对训练结果的影响[10-11],Xu 等提出一种基于马尔科夫采样的增量支持向量机(Markov resampling incremental support vector machines,MRISVM)[12]来提高运算速度和精度;Liu 等提出了一种在线半监督支持向量机(Online semi-supervised support vector machine,OSSVM),提高流数据处理效率[13];Panja 等提出一种最小跨度支持向量机(Minimally Spanned support vector machine,MSSVM)用来减少支持向量的个数,提高训练速度[14]。此外支持向量机的改进算法还有:主从模式下的分布式支持向量机(Master-slave distributed support vector machine,MSDSVM)[15]、Fisher 正 则 化 支 持 向 量 机(Fisher regularized support vector machine,FRSVM)[16]、变系数支持向量机(Varying coefficient support vector machines,VCSVM)[17]、场域支持向量机(Field support vector machines,FSVM)[18]以及双分布支持向量机(Double distribution support vector machine,DDSVM)[19]。
尽管上述几种方法在特定领域中均有良好的分类效果,但仍然面临一些挑战:(1)分类过程未考虑数据样本内部的分布特征,造成了数据资源的浪费,无法进一步提升分类性能。(2)分类结果忽视了各类样本的相对关系。假设特征空间中有3 类样本,样本的先后顺序为m1,m2,m3,分类结果应尽量保证3 类样本的相对顺序不变。如图1 所示,3 类样本投影在W1方向上顺序为m1,m2,m3,投影在W2方向上的顺序为m1,m3,m2,从样本保序性角度看,投影方向W1优于W2。(3)无法解决大规模分类问题。因此,本文提出融合数据分布特征的保序学习机(Rank preservation learning machine based on data distribution fusion,RPLM-DDF),该方法引入线性判别分析(Linear discriminant analysis,LDA)中的类内离散度SW用以表征数据的分布特征;将各类样本中心相对关系考虑到最优化问题中,来确保分类结果依然保持相对顺序不变;引入核心向量机来保证RPLM-DDF 对大型数据集依然可用。
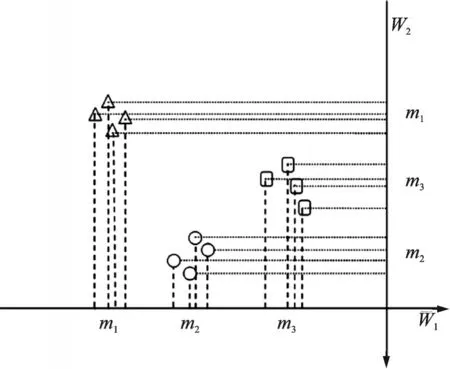
图1 RPLM-DDF 工作示意图Fig.1 RPLM-DDF working diagram
1 相关理论
1.1 最优化问题
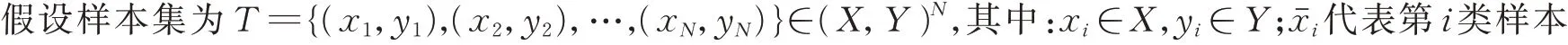




图2 人工数据集及实验结果Fig.2 Artificial data set and experimental results
2.2 中小型数据集
实验所需数据集如表1 所示。选取60%数据作为训练集,剩余40%数据作为测试集。实际问题中经常使用的核函数有:线性核函数,多项式核函数,高斯核函数和Sigmoid 核函数。不同的核函数在不同应用环境下表现各异,实验结果如图3 所示。
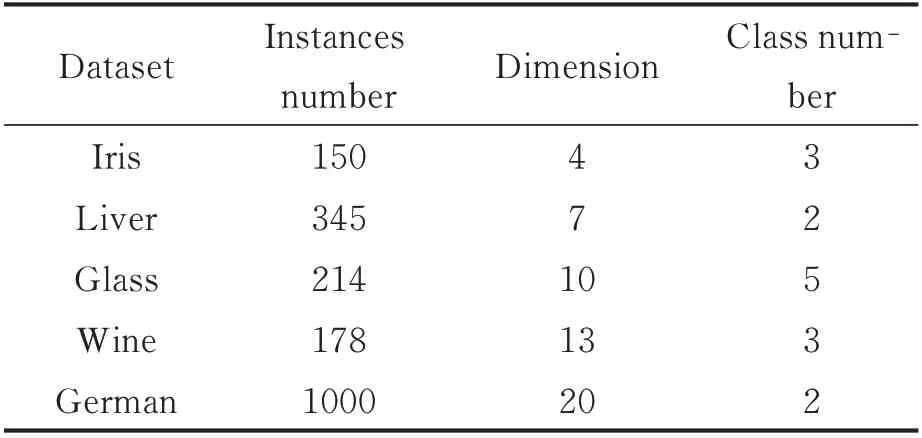
表1 实验数据集Table 1 Experimental data set
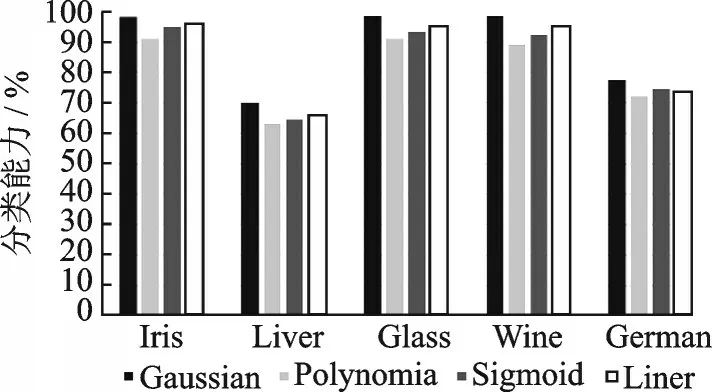
图3 核函数与实验结果Fig.3 Kernel function and experimental results
由图3 可以看出,与线性核函数、多项式核函数和Sigmoid 核函数相比,基于高斯核函数的RPLMDDF 在实验数据集上具有更优的分类能力,因此实验选取高斯核函数。
实验采用交叉验证的方法。将RPLM-DDF 与SVC(Support vectors classification),KNN(K-nearest neighbor)、朴素贝叶斯(Naive Bayes,NB)、决策树(Decision tree,DT)和多层感知器(Multi-layer perceptron,MLP)进行比较实验。使用网格搜索方法,在恰当的范围划分网格并遍历网格内所有点进行取值得到参数。γ在{0.001,0.01,0.1,1 ,5,10}中选择;惩罚参数C在{0.01,0.05,0.1,0.5,1,5,10}中选择;ν在{0.01,0.1,0.5,1,3,5,10}中选择;δ在{-x/2 2,-x/2,-x/ 2,-x2,2-x,2 2-x}中选择;最近邻数K在{1,2,3,5,10,15,20}中选择,-x是训练样本数据的平均范数平方根。MLP 共4层全连接层,每层神经元数量为[128,64,64,Class Number],使用SGD 优化器,学习率为0.001。实验参数如表2 所示,实验结果如表3 所示。

表2 实验参数Table 2 Experimental parameters
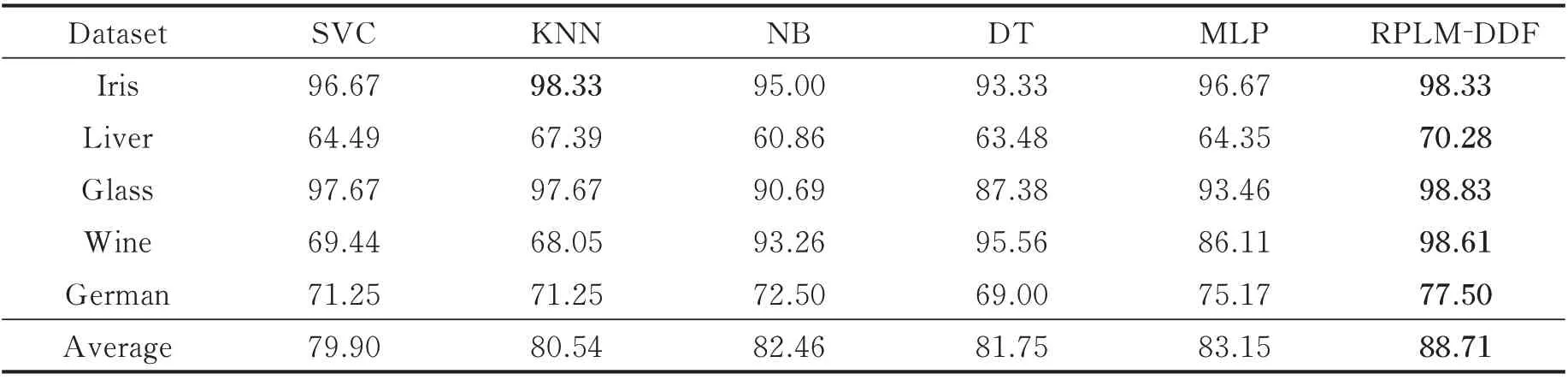
表3 中小规模数据集对比实验结果Table 3 Experimental results of small and medium-sized datasets %
由表3 可以看出,RPLM-DDF 较之SVC,KNN,NB,DT 和MLP,在平均分类性能上精度更高。在Iris 数据集中KNN 和RPLM-DDF 表现相当,在Liver,Glass,Wine 和German 数据集中,与SVC,KNN,NB,DT 和MLP 传统分类方法相比,RPLM-DDF 的分类效果更优。
2.3 大型数据集
2.3.1ε参数对实验的影响
实验采用Bank Marketing DataSet 数据集,共有45 211 个样本,17 维描述信息,共分为两类。60%的数据集作为训练样本,剩余数据集作为测试样本。ε将在{10-1,10-2,10-3,10-4,10-5,10-6,10-7}中选取。ε对实验时间影响如图4(a)所示,ε对实验精度Acc 的影响如图4(b)所示。
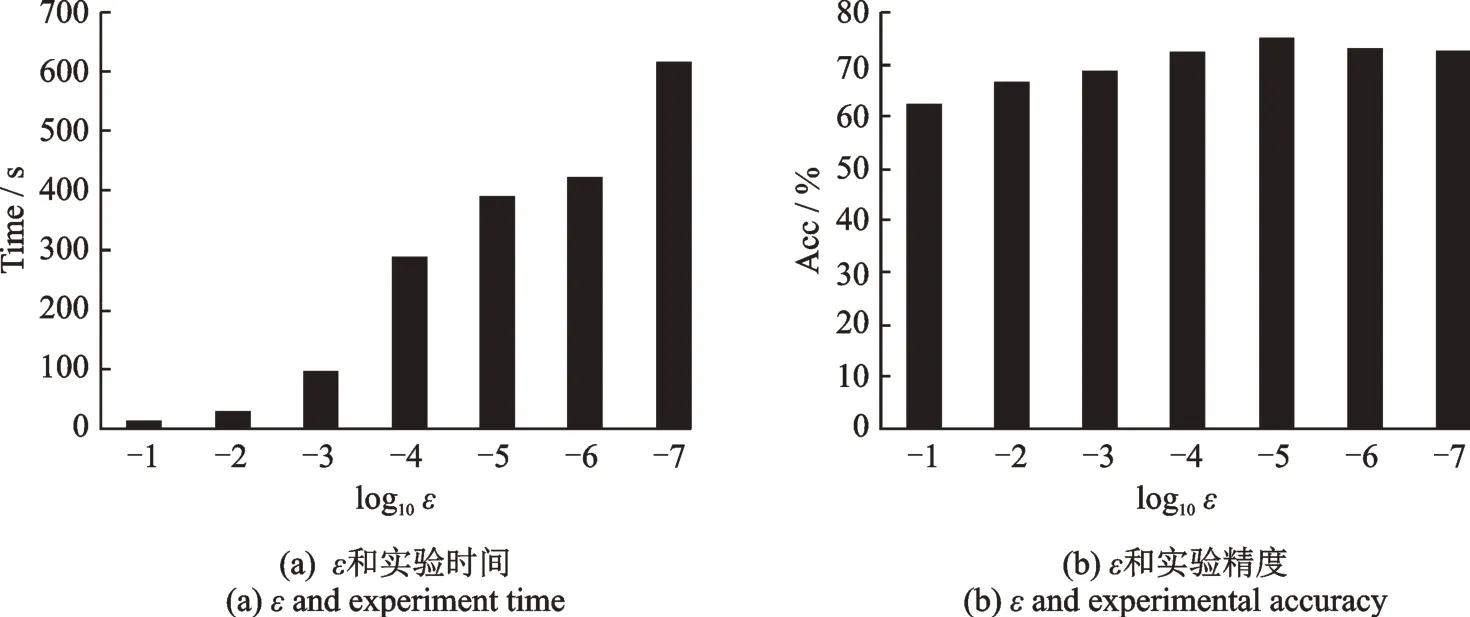
图4 ε 对实验RPLM-DDF 的影响Fig.4 Effect of ε on experiment RPLM-DDF
由图4 可知,ε越小所需训练时间越长,但不是ε越小精度越高。选取合适的ε值可以减少训练时间,并达到最高精度。
2.3.2 性能分析
将数据集的20%,40%,60%和80%作为训练集,并从剩余数据任取500 个作为测试集。实验结果如表4 所示。由表4 可以看出,随着训练样本的增加,RPLM-DDF 分类精度呈上升趋势。训练时间随着训练样本的增加而增加,但是RPLM-DDF 能在有限的时间内高精度地完成分类任务。
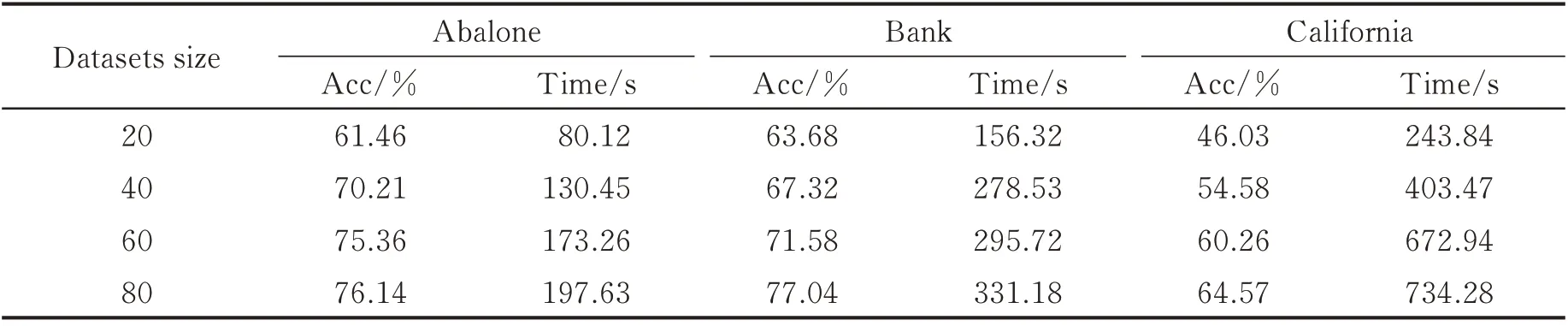
表4 RPLM-DDF 对大规模数据分类结果Table 4 RPLM-DDF classification results of large-scale data
3 结束语
针对SVM 的不足,本文提出RPLM-DDF 方法。RPLM-DDF 主要优势在于:(1)在考虑最优化问题时将类内结构融合起来,合理有效地利用这种信息,提高了算法分类精度;(2)较好地保持了数据的相对关系不变;(3)基于核心向量机使RPLM-DDF 支持大规模分类问题。在人工数据集、中小规模数据集和大规模数据集上实验表明与传统分类方法相比,所提方法具有更优的分类能力。然而,RPLMDDF 的分类结果依赖于实验参数的选取,如何更加高效地选择最优参数是下一步研究的重点。
